UniGP: Taming Diffusion Transformer for Prior-Preserved Unified Generation and Perception
Pith reviewed 2026-06-30 06:36 UTC · model grok-4.3
The pith
A single diffusion transformer unifies controllable image generation and dense prediction through simple joint training on mixed datasets while preserving its original priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
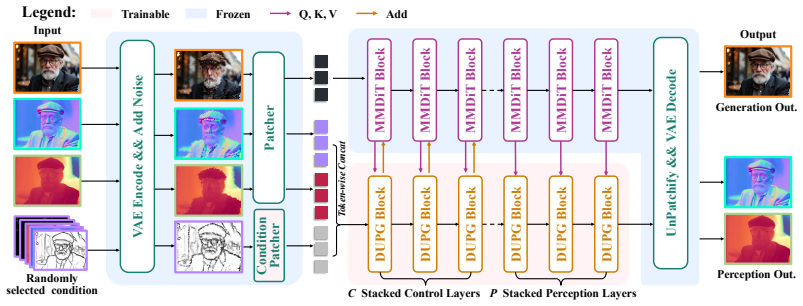
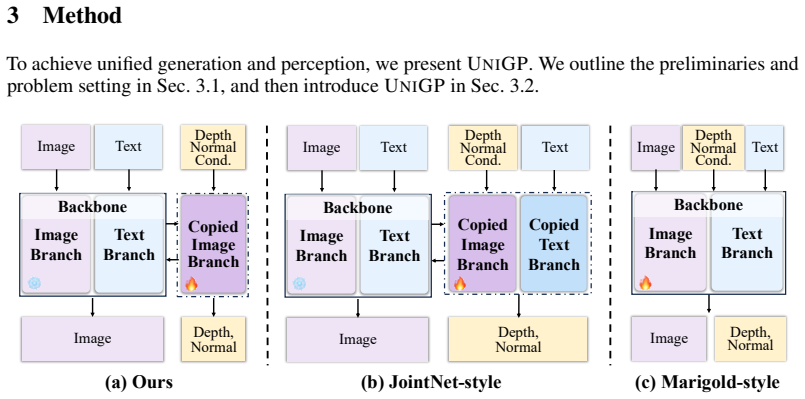
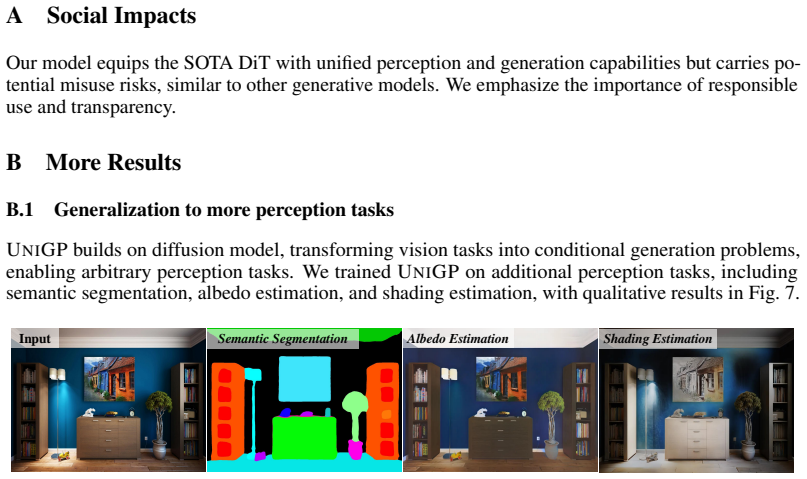
UniGP, built upon MMDiT, unifies controllable generation and dense prediction through simple joint training without complex task-specific designs or losses while preserving the backbone's versatile priors. By learning controllable generation and prediction under different conditions the model captures the joint distribution of image-geometry pairs and supports versatile controllable generation, dense prediction, and joint generation.
What carries the argument
DUGP, a copied image branch of MMDiT used to model dense distributions beyond RGB, paired with a unified dataset training strategy that integrates heterogeneous datasets into one framework.
If this is right
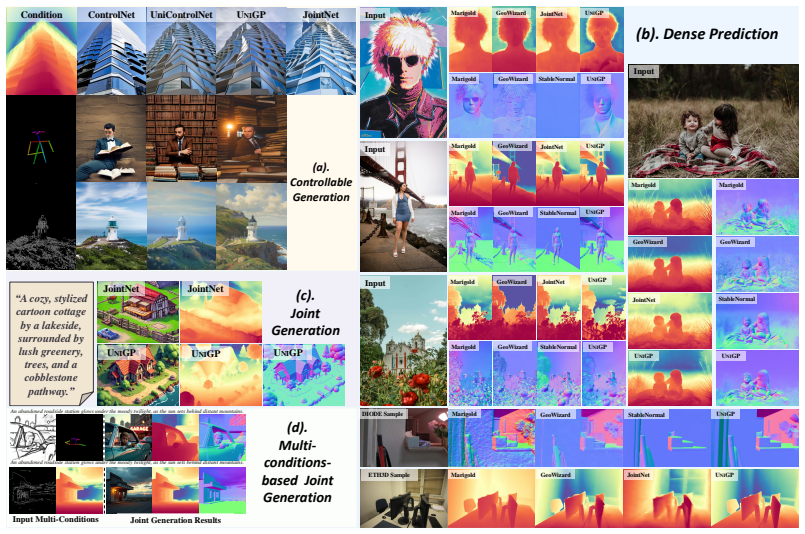
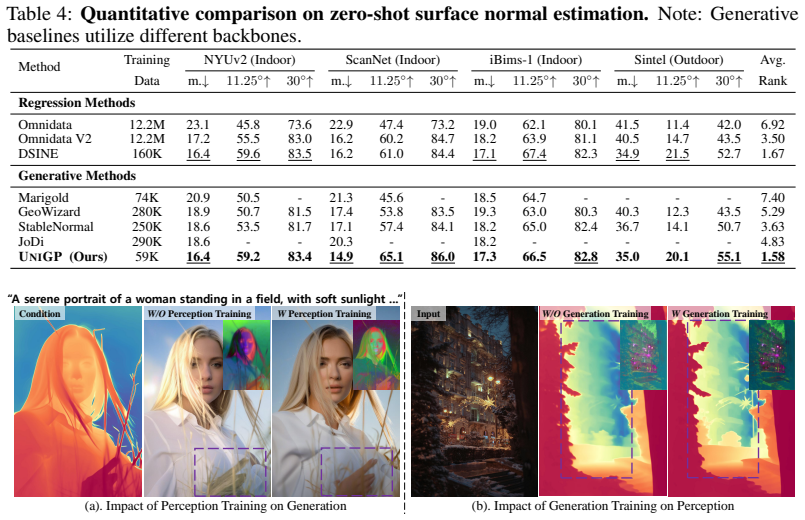
- The unified model surpasses prior unified approaches and performs on par with specialized methods for both generation and perception.
- Multi-task joint training yields complementary benefits: generative priors enrich perceptual details and perceptual learning improves structural alignment during generation.
- The model supports versatile controllable generation, dense prediction, and joint generation-perception outputs from the same backbone.
- Simple mixing of datasets is sufficient to model the joint distribution of image-geometry pairs.
Where Pith is reading between the lines
- Extending the copied-branch pattern to additional output modalities could let one backbone cover an even wider range of vision tasks without retraining separate systems.
- The observed complementarity between generation and perception suggests that structural information learned in one direction transfers to the other, which may generalize to other paired vision problems.
- If the joint-training benefit scales, the approach could lower the total compute needed for deploying multiple vision capabilities by replacing several fine-tuned models with one.
Load-bearing premise
Heterogeneous datasets from generation and perception tasks can be combined in a single training run without task-specific losses or designs yet still learn the shared image-geometry distribution and keep the backbone priors intact.
What would settle it
If the unified model scores substantially below specialized single-task models on standard generation metrics such as FID or perception metrics such as mIoU across multiple benchmarks, the claim that simple joint training suffices would be refuted.
Figures




read the original abstract
Recent advances in diffusion models have shown impressive performance in controllable image generation and dense prediction tasks. However, existing approaches typically treat diffusion-based controllable generation and dense prediction as separate tasks, overlooking the potential benefits of jointly modeling the heterogeneous distributions. In this work, we introduce UniGP, a framework built upon MMDiT, which unifies controllable generation and dense prediction through simple joint training, without the need for complex task-specific designs or losses, while preserving the backbone's versatile priors. By learning controllable generation and prediction under different conditions, our model effectively captures the joint distribution of image-geometry pairs. UniGP is capable of versatile controllable generation, dense prediction, and joint generation. Specifically, the proposed UniGP consists of DUGP and a unified dataset training strategy. The former, following the principle of Occam's razor, uses only a copied image branch of MMDiT to model dense distributions beyond RGB, while the latter integrates heterogeneous datasets into a unified training framework to jointly model generation and perception tasks. Extensive experiments demonstrate that our unified model surpasses prior unified approaches and performs on par with specialized methods. Furthermore, we demonstrate that multi-task joint training provides complementary benefits: generative priors enrich perceptual details, while perceptual learning improves structural alignment in generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniGP, a framework built on MMDiT that unifies controllable image generation and dense prediction tasks via simple joint training on heterogeneous datasets. It proposes DUGP, which copies the image branch of MMDiT to model dense distributions beyond RGB following Occam's razor, along with a unified dataset training strategy that integrates tasks without complex task-specific designs or losses. The model is claimed to capture joint image-geometry distributions, enable versatile generation/perception/joint tasks, surpass prior unified approaches, perform on par with specialized methods, and exhibit complementary benefits where generative priors enrich perception and perceptual learning improves generation alignment.
Significance. If the experimental claims hold with proper validation, this would represent a meaningful contribution by showing that minimal architectural extensions to diffusion transformers (via branch copying) combined with straightforward multi-task training can unify generation and perception while preserving versatile priors and yielding mutual benefits, potentially reducing the need for separate specialized models in computer vision.
major comments (2)
- [Abstract] Abstract: The central claims of surpassing prior unified approaches and performing on par with specialized methods are asserted without any quantitative metrics, dataset details, baselines, ablation results, or error analysis, making it impossible to evaluate whether the data supports the superiority and complementary benefits assertions.
- [§3] The unified dataset training strategy (described in the abstract and §3) is presented as integrating heterogeneous datasets without complex task-specific designs or losses, but no concrete mechanism, loss formulations, or conditioning details are provided to confirm that the joint distribution modeling occurs without hidden adaptations that would undermine the 'simple joint training' claim.
minor comments (1)
- [Abstract] The acronym DUGP is introduced without an explicit expansion or definition in the abstract, which could be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of our claims and the training strategy. We address each point below and will incorporate revisions to improve clarity while preserving the core contributions of UniGP.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of surpassing prior unified approaches and performing on par with specialized methods are asserted without any quantitative metrics, dataset details, baselines, ablation results, or error analysis, making it impossible to evaluate whether the data supports the superiority and complementary benefits assertions.
Authors: Abstracts are intentionally concise high-level summaries and do not typically contain full quantitative details, which are instead provided in Sections 4 and 5 (including tables with metrics, dataset descriptions, baselines, and ablations). We agree that a brief reference to representative results could aid readers and will revise the abstract to include one or two key quantitative highlights from the main experiments. revision: yes
-
Referee: [§3] The unified dataset training strategy (described in the abstract and §3) is presented as integrating heterogeneous datasets without complex task-specific designs or losses, but no concrete mechanism, loss formulations, or conditioning details are provided to confirm that the joint distribution modeling occurs without hidden adaptations that would undermine the 'simple joint training' claim.
Authors: The mechanism relies on applying the standard diffusion denoising objective jointly across tasks on the unified dataset, with no additional task-specific losses or architectural adaptations beyond the copied branch in DUGP. Conditioning follows the existing MMDiT text and image pathways. To address the request for explicit details, we will expand §3 with the precise loss formulation, dataset sampling procedure, and conditioning inputs in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents UniGP as an empirical framework extending MMDiT via a copied branch (DUGP) and joint training on heterogeneous datasets, with claims of unification, prior preservation, and complementary benefits supported by experimental results rather than any mathematical derivation. No load-bearing step reduces by construction to fitted inputs, self-definitions, or self-citation chains; the abstract and description contain no equations, uniqueness theorems, or ansatzes that collapse to prior work by the same authors. The central assertions rest on reported performance comparisons, which are externally falsifiable via replication and do not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rethinking inductive biases for surface normal estima- tion
Gwangbin Bae and Andrew J Davison. Rethinking inductive biases for surface normal estima- tion. InCVPR, 2024
2024
-
[2]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans
Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans. InICCV, 2021
2021
-
[4]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. InECCV, 2024
2024
-
[6]
Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan de Geus, Alexander Hermans, and Bastian Leibe. Fine-tuning image-conditional diffusion models is easier than you think.arXiv preprint arXiv:2409.11355, 2024
-
[7]
Controlnetplus, 2024
Github. Controlnetplus, 2024
2024
-
[8]
Depthfm: Fast monocular depth estimation with flow matching.arXiv preprint arXiv:2403.13788, 2024
Ming Gui, Johannes S Fischer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, and Bj¨orn Ommer. Depthfm: Fast monocular depth estimation with flow matching.arXiv preprint arXiv:2403.13788, 2024
-
[9]
arXiv preprint arXiv:2409.18124 (2024)
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Liu, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.arXiv preprint arXiv:2409.18124, 2024
-
[10]
3d common corruptions and data augmentation
O˘guzhan Fatih Kar, Teresa Yeo, Andrei Atanov, and Amir Zamir. 3d common corruptions and data augmentation. InCVPR, 2022
2022
-
[11]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Kon- rad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InCVPR, 2024
2024
-
[12]
Flux, 2024
Black Forest Labs. Flux, 2024
2024
-
[13]
One diffusion to generate them all
Duong H Le, Tuan Pham, Sangho Lee, Christopher Clark, Aniruddha Kembhavi, Stephan Mandt, Ranjay Krishna, and Jiasen Lu. One diffusion to generate them all. InCVPR, 2025
2025
-
[14]
Xirui Li, Charles Herrmann, Kelvin CK Chan, Yinxiao Li, Deqing Sun, and Ming-Hsuan Yang. A simple approach to unifying diffusion-based conditional generation.arXiv preprint arxiv:2410.11439, 2024
-
[15]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Midjourney, 2024
Midjourney. Midjourney, 2024
2024
-
[17]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[18]
Unicontrol: A unified diffusion model for controllable visual generation in the wild
Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, et al. Unicontrol: A unified diffusion model for controllable visual generation in the wild. InNeurIPS, 2024
2024
-
[19]
Vision transformers for dense prediction
Ren´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InICCV, 2021
2021
-
[20]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 44(3):1623–1637, 2020
Ren´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 44(3):1623–1637, 2020
2020
-
[21]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021
2021
-
[22]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 12
2022
-
[23]
Ldm3d: Latent diffusion model for 3d.arXiv preprint arXiv:2305.10853, 2023
Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, et al. Ldm3d: Latent diffusion model for 3d.arXiv preprint arXiv:2305.10853, 2023
-
[24]
Yanan Sun, Yanchen Liu, Yinhao Tang, Wenjie Pei, and Kai Chen. Anycontrol: Create your artwork with versatile control on text-to-image generation.arXiv preprint arXiv:2406.18958, 2024
-
[25]
Sd3-medium-controlnet, 2024
InstantX Team. Sd3-medium-controlnet, 2024
2024
-
[26]
Multi-task learning for dense prediction tasks: A survey.TPAMI, 44(7):3614–3633, 2021
Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, and Luc Van Gool. Multi-task learning for dense prediction tasks: A survey.TPAMI, 44(7):3614–3633, 2021
2021
-
[27]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[28]
Guangkai Xu, Yongtao Ge, Mingyu Liu, Chengxiang Fan, Kangyang Xie, Zhiyue Zhao, Hao Chen, and Chunhua Shen. Diffusion models trained with large data are transferable visual models.arXiv preprint arXiv:2403.06090, 2024
-
[29]
Yifeng Xu, Zhenliang He, Meina Kan, Shiguang Shan, and Xilin Chen. Jodi: Unification of visual generation and understanding via joint modeling.arXiv preprint arXiv:2505.19084, 2025
-
[30]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
2024
-
[31]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.arXiv preprint arXiv:2406.09414, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Stablenormal: Reducing diffusion variance for stable and sharp normal.TOG, 2024
Chongjie Ye, Lingteng Qiu, Xiaodong Gu, Qi Zuo, Yushuang Wu, Zilong Dong, Liefeng Bo, Yuliang Xiu, and Xiaoguang Han. Stablenormal: Reducing diffusion variance for stable and sharp normal.TOG, 2024
2024
-
[33]
Diffusionmtl: Learning multi-task denoising diffusion model from partially annotated data
Hanrong Ye and Dan Xu. Diffusionmtl: Learning multi-task denoising diffusion model from partially annotated data. InCVPR, 2024
2024
-
[34]
Jointnet: Extending text-to-image diffusion for dense distribution modeling
Jingyang Zhang, Shiwei Li, Yuanxun Lu, Tian Fang, David Neil McKinnon, Yanghai Tsin, Long Quan, and Yao Yao. Jointnet: Extending text-to-image diffusion for dense distribution modeling. InICLR, 2024
2024
-
[35]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023
2023
-
[36]
Uni-controlnet: All-in-one control to text-to-image diffusion models
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. Uni-controlnet: All-in-one control to text-to-image diffusion models. In NeurIPS, 2024. 13 A Social Impacts Our model equips the SOTA DiT with unified perception and generation capabilities but carries po- tential misuse risks, similar to other generative mo...
2024
-
[37]
11. 12. 13. 14. An elderly watchmaker examining a complex clock mechanism with a… Potted plants on a wooden table by a bright window, cozy atmosphere. A flamenco dancer in a red dress swirling in a sunny courtyard. A mad scientist with wild hair laughing, lightning in the background. A sad clown removing makeup in front of a mirror, dramatic lighting. A f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.