A Classifier-Agnostic Zero-Shot Adversarial Attack Detection via CLIP
Pith reviewed 2026-06-30 06:33 UTC · model grok-4.3
The pith
CLIP embeddings flag adversarial attacks on any classifier without training or model access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prompt-based similarity scores computed with CLIP serve as a reliable attack indicator: CLIP reacts to imperceptible perturbations, and the resulting embedding displacement follows a pattern that separates clean from adversarial inputs across datasets, attacks, and classifiers.
What carries the argument
A^4D computes prompt-based similarity scores in CLIP embedding space to quantify the non-arbitrary shift caused by adversarial perturbations.
If this is right
- Detection requires neither attack examples nor knowledge of the target model architecture.
- The same detector can be applied unchanged to new attacks and new classifiers.
- Performance holds across standard image datasets and common attack algorithms.
- The approach yields state-of-the-art numbers specifically in the attack-agnostic and classifier-agnostic setting.
Where Pith is reading between the lines
- The same embedding-shift principle could be tested with other vision-language models to see whether the indicator generalizes beyond CLIP.
- If the shift pattern proves stable, one could explore whether it also helps diagnose which semantic regions an attack has altered.
- Combining the zero-shot CLIP signal with lightweight supervised checks on a small set of known attacks might further raise detection rates without losing the agnostic property.
Load-bearing premise
The shift in CLIP embedding space produced by adversarial perturbations is consistent enough to serve as a reliable attack signal rather than random noise.
What would settle it
An adversarial attack that fools a classifier yet produces embedding shifts indistinguishable from those of clean images under the same CLIP prompts would falsify the detection claim.
Figures
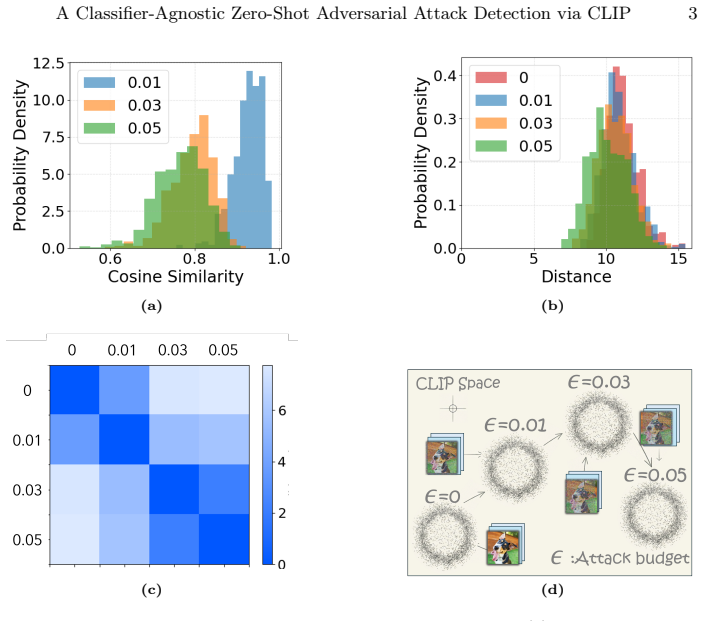
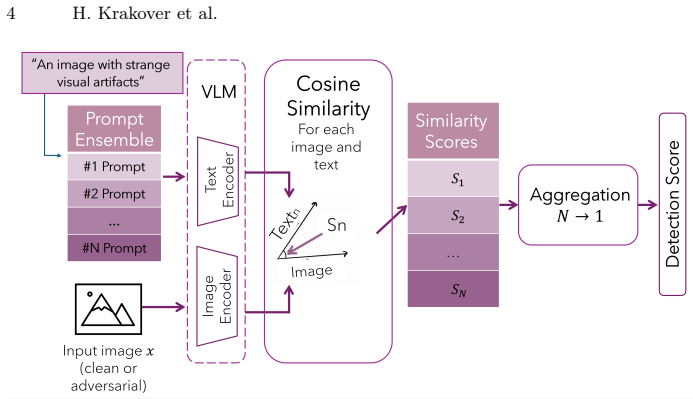

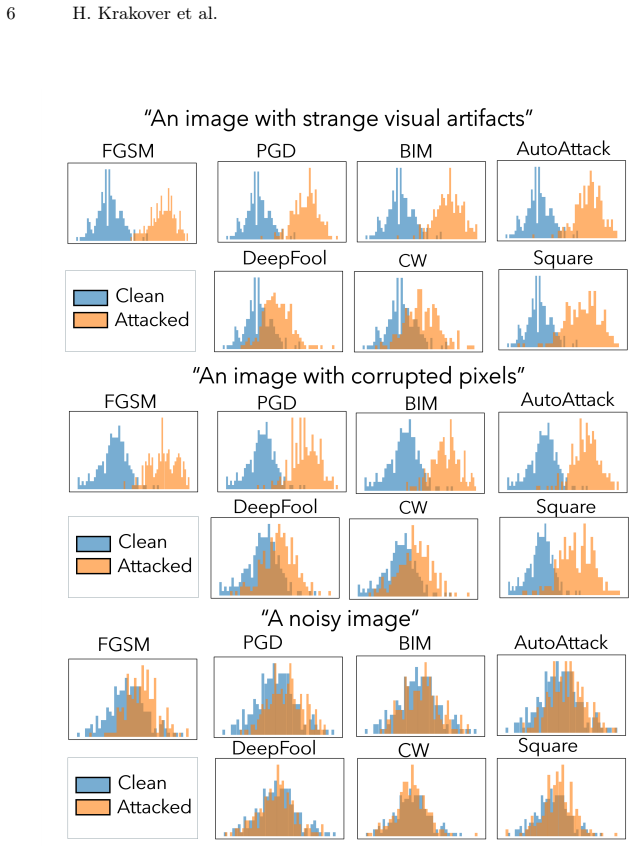
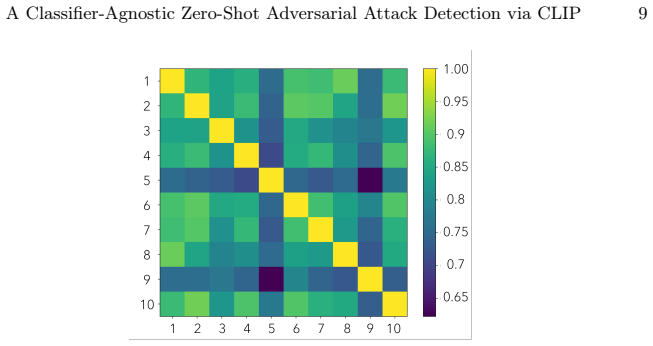

read the original abstract
Adversarial attacks pose a challenge to the reliability of deep learning models, motivating effective detection methods. Existing techniques often rely on attack-specific assumptions, access to adversarial samples, or knowledge of the underlying classifier (white-box). We propose \textit{$A^4D$ (\textbf{A}ttack- and \textbf{A}rchitecture-\textbf{A}gnostic \textbf{A}dversarial \textbf{D}etector)}, a completely black-box, zero-shot adversarial attack detection framework that utilizes prompt-based similarity scores derived from CLIP. To the best of our knowledge this is the first attempt to utilize CLIP for such a task. The method is based on two key observations: (i) CLIP is sensitive even to small imperceptible non-semantic perturbations; (ii) The shift in CLIP embedding space is not arbitrary and can be used as a robust attack indicator. Experiments across multiple attacks, datasets and classifiers validate that $A^4D$ achieves SOTA detection results in the attack-agnostic and classifier-agnostic setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes A^4D, a black-box zero-shot adversarial attack detector that computes prompt-based similarity scores from CLIP. It rests on two observations: (i) CLIP is sensitive to small non-semantic perturbations and (ii) embedding-space shifts are non-arbitrary and therefore usable as a robust attack indicator. Experiments across multiple attacks, datasets and classifiers are reported to establish SOTA detection performance in the attack-agnostic and classifier-agnostic regime.
Significance. If the central empirical claim holds, the work would constitute the first demonstration that a pre-trained multimodal model can serve as a training-free, classifier-agnostic detector, removing the need for white-box access or attack-specific training data.
major comments (2)
- [Abstract] Abstract, observation (ii): the claim that 'the shift in CLIP embedding space is not arbitrary and can be used as a robust attack indicator' is presented without any reported measurement of directional consistency, magnitude stability, or invariance to image semantics or perturbation type. Because the detection rule relies on this property, the absence of such analysis leaves the generalization argument unsupported.
- [Experiments] Experiments section: the SOTA claim in the fully agnostic setting is asserted on the basis of 'experiments across multiple attacks, datasets and classifiers,' yet no quantitative comparison tables, baseline implementations, or statistical significance tests are referenced in the provided description. Without these, it is impossible to verify that reported gains are not due to post-hoc threshold selection or dataset-specific effects.
minor comments (1)
- [Abstract] Abstract: the phrase 'to the best of our knowledge this is the first attempt' would be strengthened by a short related-work paragraph that explicitly contrasts the proposed method with prior CLIP-based robustness or detection papers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract, observation (ii): the claim that 'the shift in CLIP embedding space is not arbitrary and can be used as a robust attack indicator' is presented without any reported measurement of directional consistency, magnitude stability, or invariance to image semantics or perturbation type. Because the detection rule relies on this property, the absence of such analysis leaves the generalization argument unsupported.
Authors: We agree that the abstract states the observation without direct supporting measurements, which weakens the generalization argument as noted. The full manuscript's experiments demonstrate consistent detection performance across attacks and datasets, providing indirect evidence. To address this directly, we will add a dedicated analysis subsection (e.g., in Section 4) quantifying directional consistency (via cosine similarity of shift vectors), magnitude stability, and invariance to semantics/perturbation types on representative samples. revision: yes
-
Referee: [Experiments] Experiments section: the SOTA claim in the fully agnostic setting is asserted on the basis of 'experiments across multiple attacks, datasets and classifiers,' yet no quantitative comparison tables, baseline implementations, or statistical significance tests are referenced in the provided description. Without these, it is impossible to verify that reported gains are not due to post-hoc threshold selection or dataset-specific effects.
Authors: The full manuscript contains quantitative comparison tables (Tables 1-4 in the Experiments section) reporting AUROC, F1, and accuracy for A^4D versus multiple baselines (including attack-specific and classifier-dependent detectors) across CIFAR-10, ImageNet, and additional datasets, with results for 5+ attacks and 3+ classifiers. Baseline implementations are described in Section 3.3 with code references. Statistical significance is reported via paired t-tests in the supplementary material. The detection threshold is derived from clean-data statistics (mean + k*std of similarity scores) and held fixed across all test conditions, avoiding per-attack tuning. If the description provided to the referee omitted these tables, we will ensure they are explicitly cross-referenced in the revised abstract and introduction. revision: partial
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper introduces A^4D as a black-box detector based on two explicit empirical observations about CLIP sensitivity and embedding shifts, followed by experimental validation across attacks, datasets, and classifiers. No equations, parameter fitting, or derivation steps are described that reduce a claimed prediction or result to its own inputs by construction. The method does not invoke self-citations for uniqueness theorems, ansatzes, or load-bearing premises, nor does it rename known results. Claims rest on external experimental outcomes rather than internal self-reference, making the approach non-circular by the defined criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP is sensitive even to small imperceptible non-semantic perturbations
- domain assumption The shift in CLIP embedding space is not arbitrary and can be used as a robust attack indicator
Reference graph
Works this paper leans on
-
[1]
In: European conference on computer vision
Andriushchenko, M., Croce, F., Flammarion, N., Hein, M.: Square attack: a query- efficient black-box adversarial attack via random search. In: European conference on computer vision. pp. 484–501. Springer (2020)
2020
-
[2]
In: 42nd International conference on machine learning (2025)
Betser, R., Levi, M.Y., Gilboa, G.: Whitened clip as a likelihood surrogate of images and captions. In: 42nd International conference on machine learning (2025)
2025
-
[3]
In: Euro- pean Conference on Computer Vision
Cao, Y., Zhang, J., Frittoli, L., Cheng, Y., Shen, W., Boracchi, G.: Adaclip: Adapt- ing clip with hybrid learnable prompts for zero-shot anomaly detection. In: Euro- pean Conference on Computer Vision. pp. 55–72. Springer (2024) A Classifier-Agnostic Zero-Shot Adversarial Attack Detection via CLIP 15
2024
-
[4]
In: 2017 ieee symposium on security and privacy (sp)
Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: 2017 ieee symposium on security and privacy (sp). pp. 39–57. Ieee (2017)
2017
-
[5]
In: international conference on machine learning
Cohen, J., Rosenfeld, E., Kolter, Z.: Certified adversarial robustness via random- ized smoothing. In: international conference on machine learning. pp. 1310–1320. PMLR (2019)
2019
-
[6]
In: International conference on machine learning
Croce, F., Hein, M.: Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In: International conference on machine learning. pp. 2206–2216. PMLR (2020)
2020
-
[7]
In: European conference on computer vision
Crowson, K., Biderman, S., Kornis, D., Stander, D., Hallahan, E., Castricato, L., Raff, E.: Vqgan-clip: Open domain image generation and editing with natural lan- guage guidance. In: European conference on computer vision. pp. 88–105. Springer (2022)
2022
-
[8]
Electronics 14(15), 3015 (2025)
Danesh, W., Sapireddy, S.R., Rahman, M.: Understanding and detecting adversar- ial examples in iot networks: A white-box analysis with autoencoders. Electronics 14(15), 3015 (2025)
2025
-
[9]
Detecting Adversarial Samples from Artifacts
Feinman, R., Curtin, R.R., Shintre, S., Gardner, A.B.: Detecting adversarial sam- ples from artifacts. arXiv preprint arXiv:1703.00410 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Explaining and Harnessing Adversarial Examples
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., Song, D.: Natural adversarial examples. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15262–15271 (2021)
2021
-
[13]
Kapp, A., Hoffmann, E., Weigmann, E., Mihaljević, H.: StreetSurfaceVis: a dataset of crowdsourced street-level imagery annotated by road surface type and quality. Scientific Data12(1), 92 (2025).https://doi.org/10.1038/s41597-024-04295- 9,https://doi.org/10.1038/s41597-024-04295-9
-
[14]
arXiv preprint arXiv:2010.01950 (2020)
Kim, H.: Torchattacks: A pytorch repository for adversarial attacks. arXiv preprint arXiv:2010.01950 (2020)
-
[15]
In: Artificial intelligence safety and security, pp
Kurakin, A., Goodfellow, I.J., Bengio, S.: Adversarial examples in the physical world. In: Artificial intelligence safety and security, pp. 99–112. Chapman and Hall/CRC (2018)
2018
-
[16]
Advances in neural information processing systems31(2018)
Lee, K., Lee, K., Lee, H., Shin, J.: A simple unified framework for detecting out- of-distribution samples and adversarial attacks. Advances in neural information processing systems31(2018)
2018
-
[17]
In: Proceedings of the 42nd International Conference on Machine Learning
Levi, M.Y., Gilboa, G.: The double ellipsoid geometry of clip. In: Proceedings of the 42nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 267. PMLR, Vancouver, Canada (2025)
2025
-
[18]
IEEE Transactions on Information Forensics and Security (2025)
Li, Q., Wu, C., Chen, J., Zhang, Z., He, K., Du, R., Wang, X., Zhao, Q., Liu, Y.: Privacy-preserving universal adversarial defense for black-box models. IEEE Transactions on Information Forensics and Security (2025)
2025
-
[19]
Electronics11(8), 1283 (2022)
Liang, H., He, E., Zhao, Y., Jia, Z., Li, H.: Adversarial attack and defense: A survey. Electronics11(8), 1283 (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11976–11986 (2022)
2022
-
[21]
Neuro- computing508, 293–304 (2022) 16 H
Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., Li, T.: Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neuro- computing508, 293–304 (2022) 16 H. Krakover et al
2022
-
[22]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Ma,W.,Zhang,X.,Yao,Q.,Tang,F.,Wu,C.,Li,Y.,Yan,R.,Jiang,Z.,Zhou,S.K.: Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 4744– 4754 (2025)
2025
-
[23]
Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality
Ma, X., Li, B., Wang, Y., Erfani, S.M., Wijewickrema, S., Schoenebeck, G., Song, D., Houle, M.E., Bailey, J.: Characterizing adversarial subspaces using local intrin- sic dimensionality. arXiv preprint arXiv:1801.02613 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Towards Deep Learning Models Resistant to Adversarial Attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
In: Proceedings of the 2017 ACM SIGSAC conference on computer and communi- cations security
Meng, D., Chen, H.: Magnet: a two-pronged defense against adversarial examples. In: Proceedings of the 2017 ACM SIGSAC conference on computer and communi- cations security. pp. 135–147 (2017)
2017
-
[26]
On Detecting Adversarial Perturbations
Metzen, J.H., Genewein, T., Fischer, V., Bischoff, B.: On detecting adversarial perturbations. arXiv preprint arXiv:1702.04267 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
mnmoustafa, Ali, M.: Tiny imagenet.https://kaggle.com/competitions/tiny- imagenet(2017), kaggle
2017
-
[28]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Moosavi-Dezfooli, S.M., Fawzi, A., Frossard, P.: Deepfool: a simple and accurate method to fool deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2574–2582 (2016)
2016
-
[29]
arXiv preprint arXiv:2508.21715 (2025)
Nazeri, A., Hafez, W.: Entropy-based non-invasive reliability monitoring of convo- lutional neural networks. arXiv preprint arXiv:2508.21715 (2025)
-
[30]
Deep k-Nearest Neighbors: Towards Confident, Interpretable and Robust Deep Learning
Papernot, N., McDaniel, P.: Deep k-nearest neighbors: Towards confident, inter- pretable and robust deep learning. arXiv preprint arXiv:1803.04765 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Peng, Z., Xu, Z., Zeng, Z., Wen, C., Huang, Y., Yang, M., Tang, F., Shen, W.: Understanding fine-tuning clip for open-vocabulary semantic segmentation in hy- perbolic space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4562–4572 (2025)
2025
-
[32]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[33]
In: International conference on machine learning
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International conference on machine learning. pp. 8821–8831. Pmlr (2021)
2021
-
[34]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[35]
Shafahi, A., Najibi, M., Ghiasi, M.A., Xu, Z., Dickerson, J., Studer, C., Davis, L.S., Taylor, G., Goldstein, T.: Adversarial training for free! Advances in neural information processing systems32(2019)
2019
-
[36]
Frontiers in Computer Science7, 1631561 (2025)
Stenhuis, R., Liu, D., Qiao, Y., Conti, M., Panaousis, M., Liang, K.: Meetsafe: en- hancing robustness against white-box adversarial examples. Frontiers in Computer Science7, 1631561 (2025)
2025
-
[37]
In: 2023 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Sultan, M., Jacobs, L., Stylianou, A., Pless, R.: Exploring clip for real world, text-based image retrieval. In: 2023 IEEE Applied Imagery Pattern Recognition Workshop (AIPR). pp. 1–6. IEEE (2023)
2023
-
[38]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021) A Classifier-Agnostic Zero-Shot Adversarial Attack Detection via CLIP 17
2021
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wei, Y., Cao, Y., Zhang, Z., Peng, H., Yao, Z., Xie, Z., Hu, H., Guo, B.: iclip: Bridgingimageclassificationandcontrastivelanguage-imagepre-trainingforvisual recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2776–2786 (2023)
2023
-
[40]
In: Interna- tional conference on machine learning
Weng, Z., Yang, X., Li, A., Wu, Z., Jiang, Y.G.: Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization. In: Interna- tional conference on machine learning. pp. 36978–36989. PMLR (2023)
2023
-
[41]
arXiv preprint arXiv:2310.01403 (2023)
Wu, S., Zhang, W., Xu, L., Jin, S., Li, X., Liu, W., Loy, C.C.: Clipself: Vision transformer distills itself for open-vocabulary dense prediction. arXiv preprint arXiv:2310.01403 (2023)
-
[42]
Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
Xu, W., Evans, D., Qi, Y.: Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv preprint arXiv:1704.01155 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Zagoruyko, S., Komodakis, N.: Wide residual networks. arXiv preprint arXiv:1605.07146 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
In: The 22nd International Conference on Artificial Intelligence and Statistics
Zhang, Y., Liang, P.: Defending against whitebox adversarial attacks via random- ized discretization. In: The 22nd International Conference on Artificial Intelligence and Statistics. pp. 684–693. PMLR (2019)
2019
-
[45]
arXiv preprint arXiv:2310.18961 (2023)
Zhou, Q., Pang, G., Tian, Y., He, S., Chen, J.: Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. arXiv preprint arXiv:2310.18961 (2023)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.