Simple Supervision Is Hard to Beat: A Bitter Lesson from Sparse Target Labels in Domain-Adaptive Object Detection
Pith reviewed 2026-07-01 06:19 UTC · model grok-4.3
The pith
Simple mixing of sparse target labels improves source-free domain-adaptive object detection by 1.7-18.3 AP50 while complex plugins add little
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
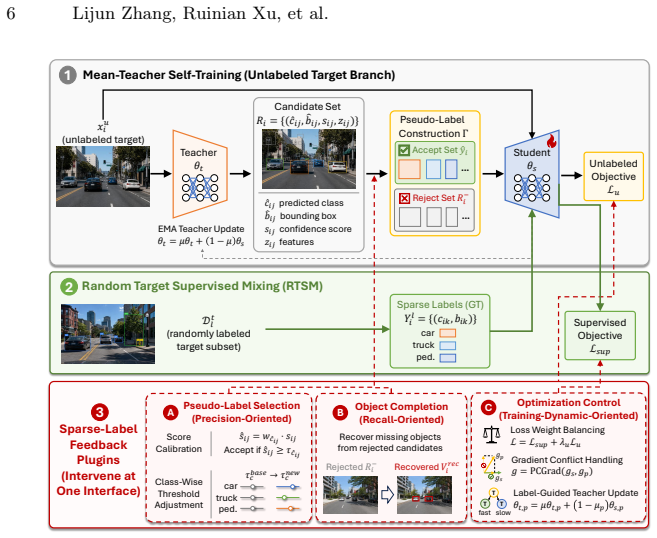
RTSM incorporates annotations from a small subset of target images through a supervised detection loss while leaving the original unlabeled adaptation branch unchanged. Across evaluations spanning four SFDA-OD methods, two object detectors, multiple adaptation tasks, and target-label budgets from 1% to 10%, RTSM consistently improves pure SFDA by 1.7 to 18.3 AP50. Ten sparse-label feedback plugins covering pseudo-label selection, object completion, and optimization control yield limited and method-dependent gains over RTSM.
What carries the argument
Random-Target Supervised Mixing (RTSM), which mixes a supervised detection loss on the sparse labeled target images with the unchanged self-training process on the remaining unlabeled targets.
If this is right
- RTSM can be inserted into existing SFDA-OD pipelines without modifying their core adaptation logic.
- The performance lift holds across label budgets of 1 percent to 10 percent.
- Complex mechanisms for steering self-training with the same labels do not reliably exceed the simple mixing baseline.
- Simple supervised loss on sparse targets functions as a strong, method-agnostic anchor for future sparse-label SFDA-OD work.
Where Pith is reading between the lines
- The result may indicate that, in low-label regimes, engineering elaborate feedback loops around a few annotations is often less efficient than applying direct supervision.
- Similar mixing strategies could be examined in other domain-adaptation tasks that rely on self-training, such as semantic segmentation.
- If the labeled subset deviates from uniform sampling, the relative value of RTSM versus feedback plugins might shift and would require separate measurement.
- The pattern suggests prioritizing minimal, high-fidelity supervision signals before investing in sophisticated label-propagation heuristics.
Load-bearing premise
The small labeled subset is uniformly sampled and the gains from RTSM plus the limited plugin benefits generalize across the four methods, two detectors, tasks, and label budgets tested.
What would settle it
A new experiment in which one of the ten feedback plugins produces consistent, large gains over RTSM on an unseen adaptation task, detector, or non-uniform label sampling would falsify the central lesson.
Figures

read the original abstract
Source-free domain adaptive object detection adapts a source-trained detector to an unlabeled target domain, typically through teacher-student self-training with pseudo-labels. We revisit this setting when a small, uniformly sampled subset of target images is labeled. We introduce Random-Target Supervised Mixing (RTSM), a simple anchor that incorporates these annotations through a supervised detection loss while leaving the original unlabeled adaptation branch unchanged. Across evaluations spanning four SFDA-OD methods, two object detectors, multiple adaptation tasks, and target-label budgets from 1% to 10%, RTSM consistently improves pure SFDA by 1.7 to 18.3 AP50. We then examine whether the same annotations can provide further gains by steering unlabeled self-training. To this end, we evaluate ten sparse-label feedback plugins covering pseudo-label selection, object completion, and optimization control, which yield limited and method-dependent gains over RTSM. These results reveal a bitter lesson for sparse-label SFDA-OD: simple supervision is hard to beat. RTSM therefore provides a simple yet effective anchor for sparse-label SFDA-OD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in source-free domain adaptive object detection (SFDA-OD), incorporating a small uniformly sampled subset of labeled target images (1-10% budgets) via Random-Target Supervised Mixing (RTSM)—which adds a supervised detection loss on the labeled images while retaining the original unlabeled self-training branch—consistently improves over pure SFDA by 1.7 to 18.3 AP50. This holds across four SFDA-OD methods, two detectors, and multiple adaptation tasks. Ten additional sparse-label feedback plugins (for pseudo-label selection, object completion, and optimization control) yield only limited and method-dependent extra gains, supporting the conclusion that simple supervision is hard to beat.
Significance. If the empirical results hold under the stated conditions, this work provides a valuable anchor and bitter lesson for the SFDA-OD community by demonstrating that direct supervised mixing on sparse uniform target labels is effective and difficult to surpass with more elaborate feedback mechanisms. The broad coverage across methods, detectors, tasks, and budgets strengthens the finding and offers a reproducible baseline that future sparse-label methods must exceed.
major comments (1)
- [Experimental setup (description of labeled subset and RTSM)] The central empirical claim that RTSM gains (and limited plugin benefits) generalize across the four SFDA-OD methods, two detectors, multiple tasks, and 1-10% budgets depends on the labeled target subset being uniformly sampled and representative. The manuscript states that the subset is uniformly sampled but does not detail the exact sampling procedure or provide verification of class/scene balance in the experimental setup; any non-uniformity would directly affect the reported AP50 deltas and the 'simple supervision is hard to beat' conclusion.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment on experimental details. We address the point below.
read point-by-point responses
-
Referee: [Experimental setup (description of labeled subset and RTSM)] The central empirical claim that RTSM gains (and limited plugin benefits) generalize across the four SFDA-OD methods, two detectors, multiple tasks, and 1-10% budgets depends on the labeled target subset being uniformly sampled and representative. The manuscript states that the subset is uniformly sampled but does not detail the exact sampling procedure or provide verification of class/scene balance in the experimental setup; any non-uniformity would directly affect the reported AP50 deltas and the 'simple supervision is hard to beat' conclusion.
Authors: We agree that additional procedural details and verification would improve reproducibility. The original manuscript describes the subset as uniformly sampled (random selection without replacement to meet the budget) but does not include pseudocode or balance statistics. In revision we will expand the experimental setup (Section 4.1) with: (i) explicit sampling algorithm (random.shuffle of target images followed by prefix selection), (ii) per-dataset tables comparing class frequencies and mean object density between sampled subsets and full target sets, and (iii) confirmation that the same procedure was used for all reported budgets and tasks. These changes directly address the concern without altering any results or conclusions. revision: yes
Circularity Check
No circularity: purely empirical comparisons on held-out data
full rationale
The paper introduces RTSM as a simple supervised mixing baseline and reports direct AP50 gains from controlled experiments across multiple SFDA-OD methods, detectors, tasks, and label budgets. No equations, derivations, fitted parameters, or self-citation chains are present that reduce any central claim to a self-referential quantity by construction. All load-bearing statements are falsifiable empirical observations on held-out target data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 3
2020
-
[2]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, Y., Li, W., Sakaridis, C., Dai, D., Van Gool, L.: Domain adaptive faster r-cnn for object detection in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3339–3348 (2018) 1, 18
2018
-
[3]
In: Proceedings of the 31st ACM International Conference on Multimedia
Chen, Z., Wang, Z., Zhang, Y.: Exploiting low-confidence pseudo-labels for source- free object detection. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 5370–5379 (2023) 1, 2, 10, 18
2023
-
[4]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016) 10
2016
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops
Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.V.: Randaugment: Practical automated data augmentation with a reduced search space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp. 702–703 (2020) 4
2020
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
He, Q., Wu, X., He, J.Y., Li, S.: Dual-rate dynamic teacher for source-free do- main adaptive object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2067–2076 (2025) 1, 2, 4, 10, 11, 18, 26
2067
-
[7]
In: European conference on computer vision
He, Z., Zhang, L.: Domain adaptive object detection via asymmetric tri-way faster- rcnn. In: European conference on computer vision. pp. 309–324. Springer (2020) 18
2020
-
[8]
In: Pro- ceedings of the AAAI conference on artificial intelligence
Li, X., Chen, W., Xie, D., Yang, S., Yuan, P., Pu, S., Zhuang, Y.: A free lunch for unsupervised domain adaptive object detection without source data. In: Pro- ceedings of the AAAI conference on artificial intelligence. vol. 35, pp. 8474–8481 (2021) 1, 18
2021
-
[9]
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection.In:ProceedingsoftheIEEEinternationalconferenceoncomputervision. pp. 2980–2988 (2017) 3
2017
-
[10]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Liu, Q., Lin, L., Shen, Z., Yang, Z.: Periodically exchange teacher-student for source-free object detection. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 6414–6424 (2023) 1, 2, 4, 10, 18
2023
-
[11]
arXiv preprint arXiv:2102.09480 (2021) 4, 8, 19, 24
Liu, Y.C., Ma, C.Y., He, Z., Kuo, C.W., Chen, K., Zhang, P., Wu, B., Kira, Z., Vajda, P.: Unbiased teacher for semi-supervised object detection. arXiv preprint arXiv:2102.09480 (2021) 4, 8, 19, 24
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Y.C., Ma, C.Y., Kira, Z.: Unbiased teacher v2: Semi-supervised object detec- tion for anchor-free and anchor-based detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9819–9828 (2022) 19
2022
-
[13]
In: European Conference on Computer Vision
Lyu, M., Hao, T., Xu, X., Chen, H., Lin, Z., Han, J., Ding, G.: Learn from the learnt: Source-free active domain adaptation via contrastive sampling and visual persistence. In: European Conference on Computer Vision. pp. 228–246. Springer (2024) 18
2024
-
[14]
Expert Systems with Applications254, 124403 (2024) 2, 3, 18 16 Lijun Zhang, Ruinian Xu, et al
Menke, M., Wenzel, T., Schwung, A.: Bridging the gap: Active learning for efficient domain adaptation in object detection. Expert Systems with Applications254, 124403 (2024) 2, 3, 18 16 Lijun Zhang, Ruinian Xu, et al
2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nakamura, Y., Ishii, Y., Yamashita, T.: Active domain adaptation with false nega- tive prediction for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28782–28792 (2024) 2, 3, 18
2024
-
[16]
arXiv preprint arXiv:2212.06137 (2022) 10
Ouyang-Zhang, J., Cho, J.H., Zhou, X., Krähenbühl, P.: Nms strikes back. arXiv preprint arXiv:2212.06137 (2022) 10
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Prabhu, V., Chandrasekaran, A., Saenko, K., Hoffman, J.: Active domain adap- tation via clustering uncertainty-weighted embeddings. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8505–8514 (2021) 18
2021
-
[18]
ACM computing surveys (CSUR)54(9), 1–40 (2021) 23
Ren, P., Xiao, Y., Chang, X., Huang, P.Y., Li, Z., Gupta, B.B., Chen, X., Wang, X.: A survey of deep active learning. ACM computing surveys (CSUR)54(9), 1–40 (2021) 23
2021
-
[19]
Advances in neural information processing systems28(2015) 3
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. Advances in neural information processing systems28(2015) 3
2015
-
[20]
In: Proceedings of the IEEE/CVF international conference on computer vision
Saito, K., Kim, D., Sclaroff, S., Darrell, T., Saenko, K.: Semi-supervised domain adaptation via minimax entropy. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8050–8058 (2019) 3
2019
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Saito, K., Ushiku, Y., Harada, T., Saenko, K.: Strong-weak distribution alignment for adaptive object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6956–6965 (2019) 1, 18
2019
-
[22]
International Journal of Computer Vision126(9), 973–992 (2018) 10
Sakaridis, C., Dai, D., Van Gool, L.: Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision126(9), 973–992 (2018) 10
2018
-
[23]
In:Proceedingsofthe30thACMinternationalconferenceonmultimedia.pp.2258– 2266 (2022) 18
Shi, W., Zhang, L., Chen, W., Pu, S.: Universal domain adaptive object detector. In:Proceedingsofthe30thACMinternationalconferenceonmultimedia.pp.2258– 2266 (2022) 18
2022
-
[24]
Advances in neural information processing systems33, 596–608 (2020) 4, 8, 19, 24
Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C., Cubuk, E.D., Kurakin, A., Li, C.L.: Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in neural information processing systems33, 596–608 (2020) 4, 8, 19, 24
2020
-
[25]
Advances in neural information processing systems30(2017) 1, 4, 18
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems30(2017) 1, 4, 18
2017
-
[26]
arXiv preprint arXiv:2205.10711 (2022) 18
Wang, F., Han, Z., Zhang, Z., Yin, Y.: Active source free domain adaptation. arXiv preprint arXiv:2205.10711 (2022) 18
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Xu, M., Zhang, Z., Hu, H., Wang, J., Wang, L., Wei, F., Bai, X., Liu, Z.: End- to-end semi-supervised object detection with soft teacher. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3060–3069 (2021) 19
2021
-
[28]
In: European Conference on Computer Vision
Yoon, I., Kwon, H., Kim, J., Park, J., Jang, H., Sohn, K.: Enhancing source-free domain adaptive object detection with low-confidence pseudo label distillation. In: European Conference on Computer Vision. pp. 337–353. Springer (2024) 1, 2, 10, 18
2024
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 2636–2645 (2020) 10
2020
-
[30]
Advances in neural information processing systems33, 5824–5836 (2020) 9 Random Target Labels for SFDA-OD 17
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., Finn, C.: Gradient surgery for multi-task learning. Advances in neural information processing systems33, 5824–5836 (2020) 9 Random Target Labels for SFDA-OD 17
2020
-
[31]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605 (2022) 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
IEEE transactions on knowl- edge and data engineering34(12), 5586–5609 (2021) 9
Zhang, Y., Yang, Q.: A survey on multi-task learning. IEEE transactions on knowl- edge and data engineering34(12), 5586–5609 (2021) 9
2021
-
[33]
In: European conference on computer vision
Zhou, H., Ge, Z., Liu, S., Mao, W., Li, Z., Yu, H., Sun, J.: Dense teacher: Dense pseudo-labels for semi-supervised object detection. In: European conference on computer vision. pp. 35–50. Springer (2022) 19 18 Lijun Zhang, Ruinian Xu, et al. A Additional Related Work Our study lies at the intersection of domain adaptive object detection, sparse- label ta...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.