Auditing Generalization in AI-Generated Video Detection: A Six-Control Protocol and the VidAudit Toolkit
Pith reviewed 2026-07-01 00:50 UTC · model grok-4.3
The pith
Audited evaluation shows most reported generalization in AI-video detectors is an artifact of uncontrolled confounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
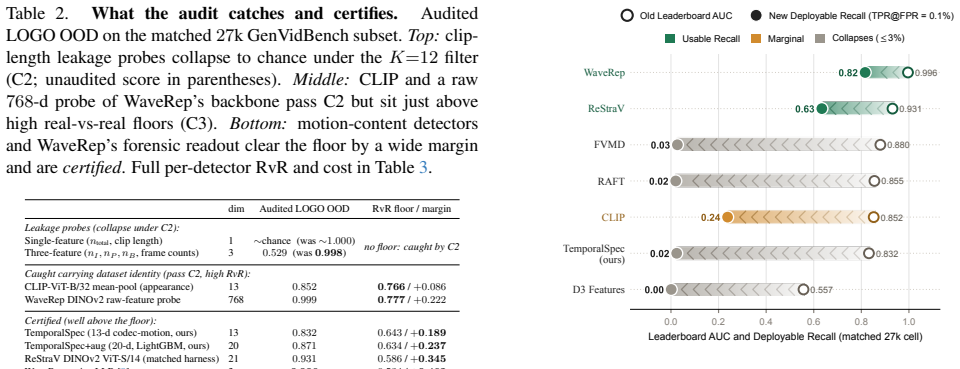
The six-control audited protocol applied to leave-one-generator-out evaluation collapses a three-feature clip-length classifier to 0.529 AUC, exposes a CLIP baseline as carrying dataset identity, certifies the 2025 WaveRep detector at 0.996 out-of-distribution AUC with chance-level real-vs-real coherence, shows that multiple high-AUC methods drop to single-digit recall at 0.1 percent FPR, and demonstrates that cross-substrate fusion of TemporalSpec motion vectors supplies complementarity that survives the audit.
What carries the argument
The six-control protocol assembled from a twenty-paper survey, implemented in the VidAudit toolkit that unifies fourteen detectors behind one API and supplies Croissant metadata for cross-dataset re-evaluation.
If this is right
- Leaderboard order changes once recall at deployable false-positive rate replaces raw AUC.
- Cross-substrate fusion can add genuine signal that survives the audit.
- Any new detector must be accompanied by the four-element audited tuple rather than AUC alone.
- Real-versus-real coherence must be reported to confirm that a method is not merely separating generator families.
- VidAudit provides a single plugin API and leaderboard for consistent audited comparisons.
Where Pith is reading between the lines
- Designers of future detectors can use the six controls as a checklist during method development rather than after the fact.
- The same protocol structure could be adapted to image or audio generation detection tasks that currently rely on similar unaudited leave-one-generator-out splits.
- Deployment pipelines would gain reliability by requiring the operating-point recall and calibration numbers the audit emphasizes.
- Community adoption of the open toolkit could shift the field from ranking papers to verifying that claimed generalization actually measures motion or synthesis artifacts.
Load-bearing premise
That the six controls identified in the survey are both necessary and jointly sufficient to remove every confound capable of producing spurious generalization signals.
What would settle it
A detector that passes all six controls yet is later shown to exploit an uncontrolled artifact such as generator-specific metadata or compression signature not captured by the protocol.
Figures

read the original abstract
AI-generated video detection benchmarks such as GenVidBench and AIGVDBench are the de facto leaderboards, yet most evaluation protocols leave uncontrolled confounds that can inflate reported generalization. As an existence proof, a three-feature clip-length classifier reaches a leave-one-generator-out (LOGO) AUC of 0.998 on GenVidBench under unaudited evaluation, while measuring nothing about motion. A 20-paper survey finds none applying all six standard controls that would catch this, so we combine them into an audited protocol and apply it to six representative feature sources (three published detectors and three repurposed signal sources), re-running it cross-dataset on AIGVDBench. The audit both debunks and certifies: the trivial classifier collapses to near chance (0.529), a CLIP baseline is caught carrying dataset identity, and the 2025 forensic detector WaveRep clears the floor at out-of-distribution LOGO AUC 0.996 with chance-level real-vs-real coherence. At a deployable FPR of 0.1%, multiple high-AUC methods fall to single-digit recall and the leaderboard order changes, so we recommend an audited tuple (AUC, above-floor margin, operating-point recall, and calibration) over a single number. As a white-box positive control, we add TemporalSpec (codec motion vectors); via cross-substrate feature fusion (XSFF), a second substrate adds genuine complementarity that survives the audit. We release VidAudit, to our knowledge the largest unified and audited detector collection for this task, providing 14 detectors behind one plugin API, a leaderboard, and Croissant metadata, available at https://github.com/KurbanIntelligenceLab/vidaudit. Together, the protocol and toolkit move evaluation from leaderboard rank toward whether a result measures what it claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a six-control auditing protocol for leave-one-generator-out (LOGO) evaluation of AI-generated video detectors to control confounds identified in a 20-paper survey. It shows that a trivial three-feature clip-length classifier reaches 0.998 LOGO AUC without the controls but drops to 0.529 with them, applies the protocol to six feature sources (including published detectors and repurposed signals), certifies the 2025 WaveRep detector at 0.996 out-of-distribution LOGO AUC with chance-level real-vs-real coherence, demonstrates that high-AUC methods drop to single-digit recall at 0.1% FPR (changing leaderboard order), and recommends an audited metric tuple. It also introduces TemporalSpec via cross-substrate feature fusion and releases the VidAudit toolkit with 14 detectors, leaderboard, and Croissant metadata.
Significance. If the protocol holds, the work would strengthen evaluation standards in AI video forensics by moving beyond single-number leaderboards toward controlled, falsifiable claims; the empirical collapse of the clip-length baseline and the certification of WaveRep provide concrete evidence of the protocol's utility. The open release of VidAudit with a unified plugin API and reproducible metadata is a clear strength for the field, enabling future audits and cross-substrate experiments.
major comments (3)
- [§3 and §4] §3 (Protocol Definition) and §4 (Survey): the central claim that the six controls are both necessary and jointly sufficient to eliminate all confounds capable of producing spurious LOGO generalization signals rests on the 20-paper survey showing that no prior work used all six, but provides no general argument, exhaustive enumeration of possible confounds, or proof of completeness beyond the single clip-length classifier example. This is load-bearing for the certification of WaveRep at 0.996 AUC and the debunks of other methods.
- [§5] §5 (Results, cross-dataset evaluation): the exact definitions of the six controls, data exclusion rules, and construction of LOGO splits on both GenVidBench and AIGVDBench are not specified at a level that permits independent verification of absence of post-hoc selection or implementation gaps, undermining confidence in the reported AUC drops and operating-point recalls at 0.1% FPR.
- [§6] §6 (WaveRep certification): the claim that WaveRep 'clears the floor' at LOGO AUC 0.996 with chance-level real-vs-real coherence is presented as the outcome of the audited protocol, yet without a demonstrated completeness argument for the controls this result cannot be distinguished from an artifact of the particular control set chosen.
minor comments (2)
- [§4.3] The introduction of TemporalSpec (codec motion vectors) as a white-box positive control is useful, but its precise feature extraction pipeline and integration via XSFF would benefit from an explicit equation or pseudocode block for reproducibility.
- [Tables 2-4] Figure captions and table headers should explicitly state which controls were active for each reported AUC to avoid ambiguity when readers compare to prior unaudited numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential value of the auditing protocol and VidAudit toolkit. We address each major comment below with honest responses and indicate planned revisions to improve clarity and reproducibility without misrepresenting the manuscript's contributions or claims.
read point-by-point responses
-
Referee: [§3 and §4] the central claim that the six controls are both necessary and jointly sufficient to eliminate all confounds capable of producing spurious LOGO generalization signals rests on the 20-paper survey showing that no prior work used all six, but provides no general argument, exhaustive enumeration of possible confounds, or proof of completeness beyond the single clip-length classifier example. This is load-bearing for the certification of WaveRep at 0.996 AUC and the debunks of other methods.
Authors: We agree that the manuscript does not offer a formal proof or exhaustive enumeration establishing that the six controls are jointly sufficient against every conceivable confound. The controls are derived directly from confounds documented in the 20-paper survey, with the clip-length classifier serving as an existence proof of their practical effect. We do not claim the set is complete or eliminates all possible spurious signals. In revision we will update §3 to state explicitly that the protocol is a standardized auditing framework addressing observed confounds from the literature, rather than asserting completeness, and will add a limitations paragraph on this point. revision: yes
-
Referee: [§5] the exact definitions of the six controls, data exclusion rules, and construction of LOGO splits on both GenVidBench and AIGVDBench are not specified at a level that permits independent verification of absence of post-hoc selection or implementation gaps, undermining confidence in the reported AUC drops and operating-point recalls at 0.1% FPR.
Authors: We accept that the current level of detail in §5 is insufficient for full independent verification. Although the controls are defined in §3, we will expand §5 with explicit pseudocode for each control, precise data exclusion criteria, and step-by-step descriptions of LOGO split construction on both datasets. These additions will be included in the revised manuscript to support reproducibility. revision: yes
-
Referee: [§6] the claim that WaveRep 'clears the floor' at LOGO AUC 0.996 with chance-level real-vs-real coherence is presented as the outcome of the audited protocol, yet without a demonstrated completeness argument for the controls this result cannot be distinguished from an artifact of the particular control set chosen.
Authors: The certification of WaveRep is presented as its performance under the defined audited protocol, not as unconditional proof of generalization. We will revise §6 to clarify the conditional nature of the result, emphasize that it shows absence of the specific spurious signals addressed by the controls, and note that future identification of additional confounds could require protocol updates. This framing avoids overclaiming while preserving the empirical observation. revision: yes
Circularity Check
No circularity; purely empirical protocol with independent controls
full rationale
The manuscript is an empirical audit: it surveys 20 prior papers to identify six controls, applies those controls to re-evaluate six feature sources on two benchmarks, and reports measured AUC, recall, and coherence values. No equations, fitted parameters, or derivations appear; the central claims are experimental outcomes under the stated protocol rather than reductions of outputs to inputs by construction. The survey finding that no prior work used all six controls is a factual count, not a self-referential premise. Self-citations, if present, are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math AUC and operating-point recall at fixed FPR are appropriate primary metrics for detection generalization
- domain assumption The six controls identified in the 20-paper survey are the complete set required to remove confounds
invented entities (1)
-
TemporalSpec (codec motion vectors)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croissant: A metadata format for ml- ready datasets
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Pieter Gijsbers, Joan Giner-Miguelez, Su- jata Goswami, Nitisha Jain, Michalis Karamousadakis, Satyapriya Krishna, Michael Kuchnik, Sylvain Lesage, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Hamidah Oderinwale, Pierre Ruyssen, Tim Santos, Rajat Shinde, Elena...
-
[2]
Ai-generated video detection via spatial-temporal anomaly learning
Jianfa Bai, Man Lin, Gang Cao, and Zijie Lou. Ai-generated video detection via spatial-temporal anomaly learning. In Pattern Recognition and Computer Vision, pages 460–470, Singapore, 2025. Springer Nature Singapore. 27
2025
-
[3]
Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023. 1, 2
2023
-
[4]
Deepfakes Are Coming for the Finan- cial Sector.The Wall Street Journal, 2024
Isabelle Bousquette. Deepfakes Are Coming for the Finan- cial Sector.The Wall Street Journal, 2024. 1
2024
-
[5]
Deepfake-eval-2024: A multi-modal in-the-wild benchmark of deepfakes circulated in 2024
Nuria Alina Chandra, Hannah Lee, Ryan Murtfeldt, Lin Qiu, Arnab Karmakar, Emmanuel Tanumihardja, Kevin Farhat, Ben Caffee, Changyeon Lee, Jongwook Choi, Sejin Paik, Aerin Kim, and Oren Etzioni. Deepfake-eval-2024: A multi-modal in-the-wild benchmark of deepfakes circulated in 2024. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Re...
2024
-
[6]
How far are ai-generated videos from simulating the 3d visual world: A learned 3d evaluation approach, 2025
Chirui Chang, Jiahui Liu, Zhengzhe Liu, Xiaoyang Lyu, Yi- Hua Huang, Xin Tao, Pengfei Wan, Di Zhang, and Xiaojuan Qi. How far are ai-generated videos from simulating the 3d visual world: A learned 3d evaluation approach, 2025. 27
2025
-
[7]
Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7310–7320, 2024. 1, 2
2024
-
[8]
Demamba: Ai- generated video detection on million-scale genvideo bench- mark.Science China Information Sciences, 69(6):162103,
Haoxing Chen, Yan Hong, Zizheng Huang, Zhuoer Xu, Zhangxuan Gu, Yaohui Li, Jun Lan, Huijia Zhu, Jianfu Zhang, Weiqiang Wang, and Huaxiong Li. Demamba: Ai- generated video detection on million-scale genvideo bench- mark.Science China Information Sciences, 69(6):162103,
-
[9]
Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation
Riccardo Corvi, Davide Cozzolino, Ekta Prashnani, Shalini De Mello, Koki Nagano, and Luisa Verdoliva. Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation. InAdvances in Neural In- formation Processing Systems, pages 26418–26446. Curran Associates, Inc., 2025. 2, 6, 7, 18, 26, 27
2025
-
[10]
You can ground earlier than see: An effective and efficient pipeline for temporal sentence grounding in compressed videos
Xiang Fang, Daizong Liu, Pan Zhou, and Guoshun Nan. You can ground earlier than see: An effective and efficient pipeline for temporal sentence grounding in compressed videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2448–2460, 2023. 3
2023
-
[11]
Leveraging fre- quency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Sch ¨onherr, Asja Fis- cher, Dorothea Kolossa, and Thorsten Holz. Leveraging fre- quency analysis for deep fake image recognition. InPro- ceedings of the 37th International Conference on Machine Learning, pages 3247–3258. PMLR, 2020. 4, 22
2020
-
[12]
On the content bias in frechet video distance
Songwei Ge, Aniruddha Mahapatra, Gaurav Parmar, Jun- Yan Zhu, and Jia-Bin Huang. On the content bias in frechet video distance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7277–7288, 2024. 3
2024
-
[13]
Exposing ai-generated videos: A benchmark dataset and a local-and-global temporal defect based detec- tion method, 2024
Peisong He, Leyao Zhu, Jiaxing Li, Shiqi Wang, and Hao- liang Li. Exposing ai-generated videos: A benchmark dataset and a local-and-global temporal defect based detec- tion method, 2024. 27
2024
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2017. 3
2017
-
[15]
Cogvideo: Large-scale pretraining for text-to-video generation via transformers, 2022
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers, 2022. 1, 2
2022
-
[16]
Vbench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
-
[17]
Ai-generated video detection via perceptual straightening
Christian Intern `o, Robert Geirhos, Markus Olhofer, Sunny Liu, Barbara Hammer, and David Klindt. Ai-generated video detection via perceptual straightening. InAdvances in Neural Information Processing Systems, pages 20672–20705. Cur- ran Associates, Inc., 2025. 2, 3, 4, 5, 6, 7, 8, 18, 27, 29
2025
-
[18]
Text2video-zero: Text-to- image diffusion models are zero-shot video generators, 2023
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to- image diffusion models are zero-shot video generators, 2023. 1, 2
2023
-
[19]
Roy-Chowdhury
Rohit Kundu, Hao Xiong, Vishal Mohanty, Athula Balachan- dran, and Amit K. Roy-Chowdhury. Towards a universal synthetic video detector: From face or background manip- ulations to fully ai-generated content. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28050–28060, 2025. 27
2025
-
[20]
Preserving forgery artifacts: Ai- generated video detection at native scale, 2026
Zhengcen Li, Chenyang Jiang, Hang Zhao, Shiyang Zhou, Yunyang Mo, Feng Gao, Fan Yang, Qiben Shan, Shaocong Wu, and Jingyong Su. Preserving forgery artifacts: Ai- generated video detection at native scale, 2026. 27
2026
-
[21]
Fr ´echet video motion distance: A metric for evaluating motion consistency in videos, 2024
Jiahe Liu, Youran Qu, Qi Yan, Xiaohui Zeng, Lele Wang, and Renjie Liao. Fr ´echet video motion distance: A metric for evaluating motion consistency in videos, 2024. 2, 3, 6, 7, 26, 27 9
2024
-
[22]
Detecting ai-generated video via frame consistency
Long Ma, Zhiyuan Yan, Qinglang Guo, Yong Liao, Haiyang Yu, and Pengyuan Zhou. Detecting ai-generated video via frame consistency. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2025. 3, 8, 27
2025
-
[23]
Your one-stop solution for ai-generated video detection, 2026
Long Ma, Zihao Xue, Yan Wang, Zhiyuan Yan, Jin Xu, Xi- aorui Jiang, Haiyang Yu, Yong Liao, and Zhen Bi. Your one-stop solution for ai-generated video detection, 2026. 1, 2, 3, 8, 26, 27, 29
2026
-
[24]
William J. McGill. Multivariate information transmission. Psychometrika, 19(2):97–116, 1954. 24
1954
-
[25]
Video diffusion models: A survey, 2024
Andrew Melnik, Michal Ljubljanac, Cong Lu, Qi Yan, Weiming Ren, and Helge Ritter. Video diffusion models: A survey, 2024. 1
2024
-
[26]
Genvidbench: A challenging benchmark for detecting ai-generated video, 2025
Zhenliang Ni, Qiangyu Yan, Mouxiao Huang, Tianning Yuan, Yehui Tang, Hailin Hu, Xinghao Chen, and Yunhe Wang. Genvidbench: A challenging benchmark for detecting ai-generated video, 2025. 1, 5, 27
2025
-
[27]
Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl, 2026
Kyoungjun Park, Yifan Yang, Juheon Yi, Shicheng Zheng, Yifei Shen, Dongqi Han, Caihua Shan, Muhammad Muaz, and Lili Qiu. Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl, 2026. 3, 8, 27
2026
-
[28]
Pika 2.0: Integrating custom characters and scenes in ai video generation.https://venturebeat
Pika Labs. Pika 2.0: Integrating custom characters and scenes in ai video generation.https://venturebeat. com / ai / pika - 2 - 0 - launches - in - wake - of - sora - integrating - your - own - characters - objects-scenes-in-new-ai-videos/, 2024. Ac- cessed: 2025-06-07. 2
2024
-
[29]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InProceedings of the 36th International Conference on Ma- chine Learning, pages 5301–5310. PMLR, 2019. 4, 21
2019
-
[30]
AI Deepfakes Are Getting Weirder and Harder to Spot in the Midterms.The Wall Street Journal,
Amrith Ramkumar. AI Deepfakes Are Getting Weirder and Harder to Spot in the Midterms.The Wall Street Journal,
-
[31]
Richardson.The H.264 Advanced Video Compression Standard
Iain E. Richardson.The H.264 Advanced Video Compression Standard. Wiley Publishing, 2nd edition, 2010. 3, 4
2010
-
[32]
Dmc-net: Generating discriminative motion cues for fast compressed video action recognition
Zheng Shou, Xudong Lin, Yannis Kalantidis, Laura Sevilla- Lara, Marcus Rohrbach, Shih-Fu Chang, and Zhicheng Yan. Dmc-net: Generating discriminative motion cues for fast compressed video action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 3
2019
-
[33]
Solana-Cipres, G
C. Solana-Cipres, G. Fernandez-Escribano, L. Rodriguez- Benitez, J. Moreno-Garcia, and L. Jimenez-Linares. Real- time moving object segmentation in h.264 compressed do- main based on approximate reasoning.International Journal of Approximate Reasoning, 51(1):99–114, 2009. 3
2009
-
[34]
Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand
Gary J. Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the high efficiency video coding (hevc) standard.IEEE Transactions on Circuits and Systems for Video Technology, 22(12):1649–1668, 2012. 3, 4, 5
2012
-
[35]
Videoveritas: Ai-generated video detection via perception pretext reinforcement learning, 2026
Hao Tan, Jun Lan, Senyuan Shi, Zichang Tan, Zijian Yu, Huijia Zhu, Weiqiang Wang, Jun Wan, and Zhen Lei. Videoveritas: Ai-generated video detection via perception pretext reinforcement learning, 2026. 27
2026
-
[36]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InComputer Vision – ECCV 2020, pages 402–419, Cham, 2020. Springer International Publishing. 2, 6, 7
2020
-
[37]
To- wards accurate generative models of video: A new metric & challenges, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges, 2019. 3
2019
-
[38]
Cmta: Leveraging cross-modal tem- poral artifacts for generalizable ai-generated video detection,
Hang Wang, Chao Shen, Chenhao Lin, Minghui Yang, Lei Zhang, and Cong Wang. Cmta: Leveraging cross-modal tem- poral artifacts for generalizable ai-generated video detection,
-
[39]
Atss: Detecting ai-generated videos via anomalous temporal self- similarity, 2026
Hang Wang, Chao Shen, Lei Zhang, and Zhi-Qi Cheng. Atss: Detecting ai-generated videos via anomalous temporal self- similarity, 2026. 3, 8, 27
2026
-
[40]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. Cnn-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 4, 22
2020
-
[41]
Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models
Wenhao Wang and Yi Yang. Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models. Thirty-eighth Conference on Neural Information Processing Systems, 2024. 3
2024
-
[42]
Swap attention in spa- tiotemporal diffusions for text-to-video generation, 2024
Wenjing Wang, Huan Yang, Zixi Tuo, Huiguo He, Junchen Zhu, Jianlong Fu, and Jiaying Liu. Swap attention in spa- tiotemporal diffusions for text-to-video generation, 2024. 3
2024
-
[43]
Compression-aware video super- resolution
Yingwei Wang, Takashi Isobe, Xu Jia, Xin Tao, Huchuan Lu, and Yu-Wing Tai. Compression-aware video super- resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2012–2021, 2023. 3
2012
-
[44]
Robustsora: De- watermarked benchmark for robust ai-generated video detec- tion, 2026
Zhuo Wang, Xiliang Liu, and Ligang Sun. Robustsora: De- watermarked benchmark for robust ai-generated video detec- tion, 2026. 2, 26, 27
2026
-
[45]
P. Welch. The use of fast fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms.IEEE Transactions on Audio and Electroacoustics, 15(2):70–73, 1967. 5
1967
-
[46]
Wiegand, G.J
T. Wiegand, G.J. Sullivan, G. Bjontegaard, and A. Luthra. Overview of the h.264/avc video coding standard.IEEE Transactions on Circuits and Systems for Video Technology, 13(7):560–576, 2003. 4, 23
2003
-
[47]
Manmatha, Alexander J
Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R. Manmatha, Alexander J. Smola, and Philipp Kr ¨ahenb¨uhl. Compressed video action recognition. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[48]
Physics-driven spatiotemporal modeling for ai-generated video detection
Shuhai Zhang, ZiHao Lian, Jiahao Yang, Daiyuan Li, Guox- uan Pang, Feng Liu, Bo Han, Shutao Li, and Mingkui Tan. Physics-driven spatiotemporal modeling for ai-generated video detection. InAdvances in Neural Information Pro- cessing Systems, pages 174683–174730. Curran Associates, Inc., 2025. 26, 27
2025
-
[49]
D3: Training-free ai-generated video detection using 10 second-order features
Chende Zheng, Ruiqi Suo, Chenhao Lin, Zhengyu Zhao, Le Yang, Shuai Liu, Minghui Yang, Cong Wang, and Chao Shen. D3: Training-free ai-generated video detection using 10 second-order features. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 12852–12862, 2025. 2, 3, 4, 6, 7, 17, 27
2025
-
[50]
Qiang Zhu, Jinhua Hao, Yukang Ding, Yu Liu, Qiao Mo, Ming Sun, Chao Zhou, and Shuyuan Zhu. Cpga: Cod- ing priors-guided aggregation network for compressed video quality enhancement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2964–2974, 2024. 3 11 Supplementary Material This supplementary material is g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.