Thinking Before Retrieving: Robust Zero-Shot Composed Image Retrieval via Strategic Planning and Self-Criticism
Pith reviewed 2026-07-01 05:50 UTC · model grok-4.3
The pith
A Planner-Executor-Critic pipeline improves zero-shot composed image retrieval by evaluating multiple candidate queries before retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
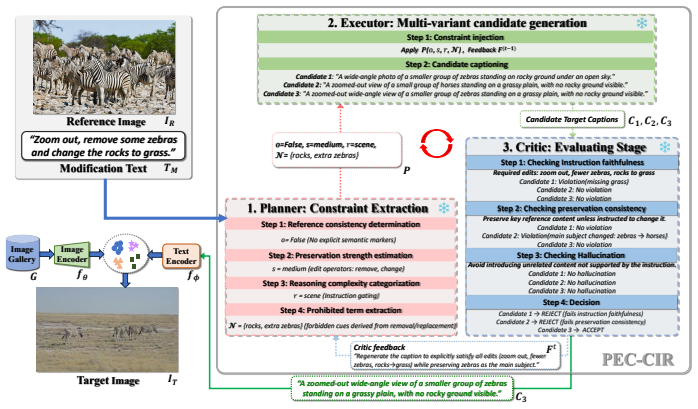
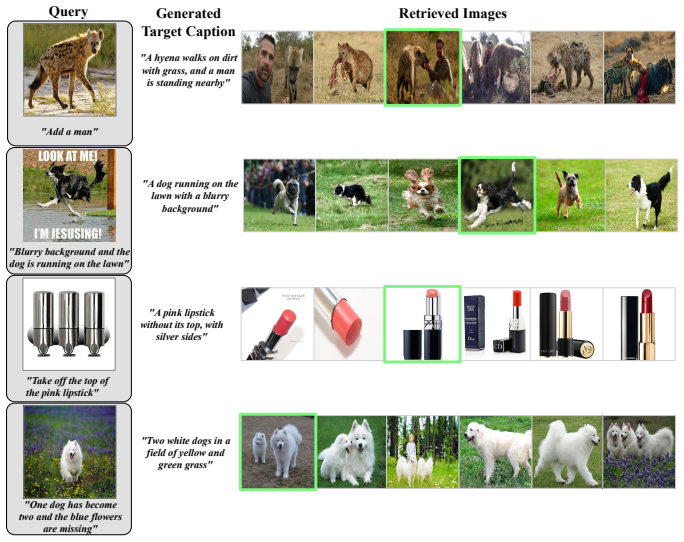
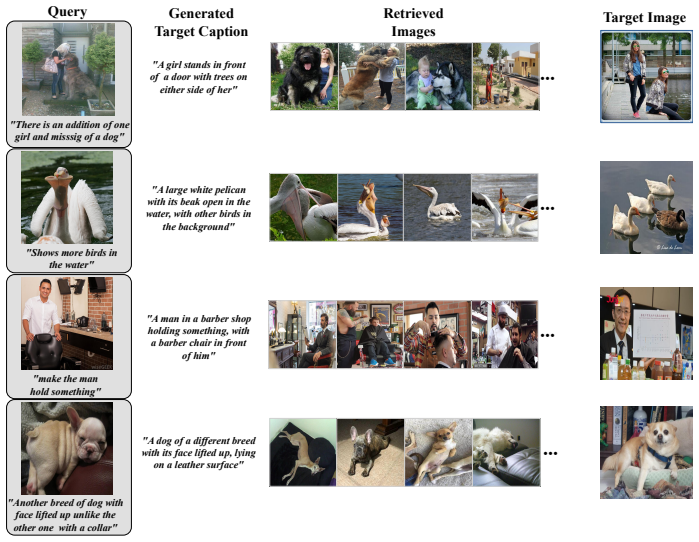
PEC-CIR reframes query construction for composed image retrieval as a Planner-Executor-Critic pipeline. The Planner extracts explicit constraints from the reference image and modification text. The Executor produces multiple candidate target descriptions. The Critic evaluates these candidates for constraint compliance and selects the best one for retrieval, thereby reducing the propagation of generative errors compared to single-pass methods.
What carries the argument
The Planner-Executor-Critic architecture, which turns query construction into a multi-stage reasoning pipeline that evaluates candidates before retrieval.
If this is right
- Semantic distortions and omissions during generation are detected before they reach the retrieval stage.
- Preservation of reference attributes and integration of textual requirements interfere less with each other.
- Retrieval stability increases in training-free zero-shot settings without any model updates.
- The same staged structure can be applied to other tasks that rely on generating retrieval-oriented text from multimodal inputs.
Where Pith is reading between the lines
- The approach may extend to other multimodal generation tasks where single-pass outputs frequently violate constraints.
- Self-criticism with frozen models could serve as a general substitute for task-specific fine-tuning in retrieval pipelines.
- Explicit constraint lists produced by the Planner offer a transparent way to audit and debug query failures.
Load-bearing premise
The Critic stage using only frozen models can reliably detect and select candidate descriptions that better preserve reference attributes and satisfy textual constraints than a single-pass generation would.
What would settle it
A direct comparison on standard composed image retrieval benchmarks measuring whether retrieval accuracy rises when replacing single-pass generation with the full Planner-Executor-Critic selection process.
Figures


read the original abstract
Composed image retrieval requires identifying a target image from a gallery by integrating a reference image with a textual modification instruction. In a training-free zero-shot setting, this task relies on constructing a retrieval-oriented textual query within a frozen vision--language embedding space at inference time. Existing approaches predominantly rely on a single-pass generation strategy that fuses the reference context and modification text into a unified description. This strategy makes it difficult to detect or correct semantic distortions and omissions during generation. Consequently, the preservation of reference attributes and the integration of textual requirements interfere with each other, which degrades retrieval precision. To address these challenges, we introduce PEC-CIR, a training-free framework that structures query construction as a multi-stage reasoning pipeline. The framework operates through a Planner--Executor--Critic architecture where the Planner extracts explicit constraints, the Executor generates multiple candidate target descriptions, and the Critic evaluates these candidates based on constraint compliance. By reframing query construction as a staged inference process instead of a single-pass output, PEC-CIR reduces the propagation of generative errors by explicitly evaluating candidate queries before retrieval, thereby improving retrieval stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-pass generation in training-free zero-shot composed image retrieval (CIR) leads to semantic distortions and omissions because reference attributes and textual modifications interfere; it proposes PEC-CIR, a Planner–Executor–Critic pipeline that extracts constraints, generates multiple candidate descriptions, and evaluates them for compliance before retrieval, thereby reducing error propagation and improving stability.
Significance. If the Critic stage can reliably select superior candidates using only frozen VLMs, the staged pipeline would address a genuine limitation of single-pass methods in zero-shot CIR and provide a general template for error mitigation in generative retrieval pipelines. The training-free nature is a strength, but the absence of any reported results, ablations, or implementation details prevents assessment of whether the architecture delivers the claimed stability gains.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that the Critic 'evaluates these candidates based on constraint compliance' and thereby reduces generative errors is load-bearing, yet the manuscript supplies no scoring function, prompt template, or decision rule for the Critic; without an explicit mechanism it is impossible to determine why a frozen model would succeed at meta-evaluation where the Executor failed at generation.
- [§4] §4 (experiments): no quantitative retrieval metrics, ablation studies, or baseline comparisons are reported, so the stability improvement asserted in the abstract cannot be verified and the contribution of the Planner–Executor–Critic decomposition remains untested.
minor comments (1)
- [§3] Notation for the three stages is introduced without a compact diagram or pseudocode listing the exact sequence of calls to the frozen VLM, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit implementation details and empirical validation. We will revise the manuscript to incorporate the requested clarifications and results while preserving the core contribution of the PEC-CIR framework.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that the Critic 'evaluates these candidates based on constraint compliance' and thereby reduces generative errors is load-bearing, yet the manuscript supplies no scoring function, prompt template, or decision rule for the Critic; without an explicit mechanism it is impossible to determine why a frozen model would succeed at meta-evaluation where the Executor failed at generation.
Authors: We agree that the absence of explicit prompt templates and the Critic's decision rule limits reproducibility. In the revised manuscript we will add the full prompt templates for the Planner, Executor, and Critic stages along with the precise scoring function (constraint-compliance verification via the frozen VLM) and the selection rule. This will clarify how the Critic performs reliable meta-evaluation. revision: yes
-
Referee: [§4] §4 (experiments): no quantitative retrieval metrics, ablation studies, or baseline comparisons are reported, so the stability improvement asserted in the abstract cannot be verified and the contribution of the Planner–Executor–Critic decomposition remains untested.
Authors: The current manuscript presents the conceptual architecture; we acknowledge that quantitative evidence is required to substantiate the claimed stability gains. The revised version will include standard zero-shot CIR metrics (Recall@K, mAP), comparisons against single-pass baselines, and ablations isolating each stage of the pipeline. revision: yes
Circularity Check
No circularity: procedural pipeline with no equations or self-referential reductions
full rationale
The paper presents PEC-CIR as a training-free, multi-stage procedural framework (Planner extracts constraints, Executor generates candidates, Critic evaluates compliance) for zero-shot composed image retrieval. The provided text contains no equations, fitted parameters, uniqueness theorems, or derivations. The central claim—that staging reduces generative error propagation—is an architectural assertion about inference ordering, not a quantity that reduces to its own inputs by construction. No self-citation load-bearing or ansatz smuggling is identifiable in the abstract or description. The method is self-contained as an empirical pipeline choice evaluated against single-pass baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen vision-language models can perform effective constraint extraction, multi-candidate generation, and constraint-compliance evaluation for image retrieval queries
Reference graph
Works this paper leans on
-
[1]
N. V o, L. Jiang, C. Sun, K. Murphy, L.-J. Li, L. Fei-Fei, J. Hays, Composing text and image for image retrieval - an empirical odyssey, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 6439–6448. 30
2019
-
[2]
Philbin, O
J. Philbin, O. Chum, M. Isard, J. Sivic, A. Zisserman, Object retrieval with large vocabularies and fast spatial matching, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2007, pp. 1–8
2007
-
[3]
Gordo, J
A. Gordo, J. Almazán, J. Revaud, D. Larlus, Deep image retrieval: Learning global representations for image search, in: European Conference on Computer Vision (ECCV), Springer, 2016, pp. 241–257
2016
-
[4]
Y .-B. Lee, U. Park, A. K. Jain, S.-W. Lee, Pill-id: Matching and retrieval of drug pill images, Pattern Recognition Letters 33 (7) (2012) 904–910
2012
-
[5]
S. Sun, Q. Li, S. Gong, W. Cai, P. Torr, J. Gu, Benchcir: Benchmarking robust- ness in composed image retrieval across modalities, Pattern Recognition (2026) 113724
2026
-
[6]
L. Wang, W. Ao, V . N. Boddeti, S.-N. Lim, Generative zero-shot composed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 29690–29700
2025
-
[7]
E. Xing, P. Kolouju, R. Pless, A. Stylianou, N. Jacobs, Context-cir: Learning from concepts in text for composed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 19638–19648
2025
-
[8]
D. Kang, H. Han, A. K. Jain, S.-W. Lee, Nighttime face recognition at large standoff: Cross-distance and cross-spectral matching, Pattern Recognition 47 (12) (2014) 3750–3766
2014
-
[9]
Delmas, R
G. Delmas, R. S. de Rezende, G. Csurka, D. Larlus, Artemis: Attention-based retrieval with text-explicit matching and implicit similarity, 2022
2022
-
[10]
Ju, H.-J
Y .-J. Ju, H.-J. Kim, S.-W. Lee, Mire: Enhancing multimodal queries representa- tion via fusion-free modality interaction for multimodal retrieval, in: Findings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 5350–5363
2025
-
[11]
Baldrati, M
A. Baldrati, M. Bertini, T. Uricchio, A. Del Bimbo, Effective conditioned and composed image retrieval combining clip-based features, in: Proc. IEEE Con- 31 ference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 21466– 21474
2022
-
[12]
Zhang, Y
K. Zhang, Y . Luan, H. Hu, K. Lee, S. Qiao, W. Chen, Y . Su, M.-W. Chang, Magiclens: Self-supervised image retrieval with open-ended instructions, in: In- ternational Conference on Machine Learning (ICML), PMLR, 2024, pp. 59403– 59420
2024
-
[13]
Agnolucci, A
L. Agnolucci, A. Baldrati, A. Del Bimbo, M. Bertini, isearle: Improving textual inversion for zero-shot composed image retrieval, IEEE Trans. on Pattern Analy- sis and Machine Intelligence (2025)
2025
-
[14]
Z. Chen, Z. Zhao, F. Su, S. Lu, Data-efficient generalization for zero-shot com- posed image retrieval, Pattern Recognition (2026) 113187
2026
-
[15]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International Conference on Machine Learning (ICML), PmLR, 2021, pp. 8748–8763
2021
-
[16]
Park, S.-W
J.-W. Park, S.-W. Lee, Mcot-re: Multi-faceted chain-of-thought and re-ranking for training-free zero-shot composed image retrieval, in: 2025 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, 2025, pp. 984–989
2025
-
[17]
Y . Tang, J. Zhang, X. Qin, J. Yu, G. Gou, G. Xiong, Q. Lin, S. Rajmohan, D. Zhang, Q. Wu, Reason-before-retrieve: One-stage reflective chain-of-thoughts for training-free zero-shot composed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 14400–14410
2025
-
[18]
Z. Yang, D. Xue, S. Qian, W. Dong, C. Xu, Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image retrieval, in: Proc. ACM SIGIR Con- ference on Research and Development in Information Retrieval (SIGIR), 2024, pp. 80–90. 32
2024
- [19]
-
[20]
Cheng, Y
Z. Cheng, Y . Ma, J. Lang, K. Zhang, T. Zhong, Y . Wang, F. Zhou, Generative thinking, corrective action: User-friendly composed image retrieval via automatic multi-agent collaboration, in: Proc. 31st ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining V . 2, 2025, pp. 334–344
2025
-
[21]
H. Wu, Y . Gao, X. Guo, Z. Al-Halah, S. Rennie, K. Grauman, R. Feris, Fashion iq: A new dataset towards retrieving images by natural language feedback, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 11307–11317
2021
-
[22]
Z. Liu, C. Rodriguez-Opazo, D. Teney, S. Gould, Image retrieval on real-life images with pre-trained vision-and-language models, in: Proc. IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021, pp. 2125–2134
2021
-
[23]
Park, Y .-E
J.-W. Park, Y .-E. Kim, S.-W. Lee, Far-net: Multi-stage fusion network with en- hanced semantic alignment and adaptive reconciliation for composed image re- trieval, in: 2025 IEEE International Conference on Systems, Man, and Cybernet- ics (SMC), IEEE, 2025, pp. 990–995
2025
-
[24]
Yun, W.-J
M.-S. Yun, W.-J. Nam, S.-W. Lee, Coarse-to-fine deep metric learning for remote sensing image retrieval, Remote Sensing 12 (2) (2020) 219
2020
-
[25]
H. Wen, X. Song, J. Yin, J. Wu, W. Guan, L. Nie, Self-training boosted multi- factor matching network for composed image retrieval, IEEE Trans. on Pattern Analysis and Machine Intelligence 46 (5) (2023) 3665–3678
2023
-
[26]
Q. Yang, M. Ye, Z. Cai, K. Su, B. Du, Composed image retrieval via cross re- lation network with hierarchical aggregation transformer, IEEE Trans. on Image Processing 32 (2023) 4543–4554. 33
2023
-
[27]
S. Qian, D. Xue, Q. Fang, C. Xu, Integrating multi-label contrastive learning with dual adversarial graph neural networks for cross-modal retrieval, IEEE Transac- tions on Pattern Analysis and Machine Intelligence 45 (4) (2022) 4794–4811
2022
-
[28]
S. Qian, D. Xue, H. Zhang, Q. Fang, C. Xu, Dual adversarial graph neural net- works for multi-label cross-modal retrieval, in: Proceedings of the AAAI Confer- ence on Artificial Intelligence, V ol. 35, 2021, pp. 2440–2448
2021
-
[29]
S. Qian, D. Xue, Q. Fang, C. Xu, Adaptive label-aware graph convolutional net- works for cross-modal retrieval, IEEE Transactions on Multimedia 24 (2021) 3520–3532
2021
-
[30]
Lee, Multilayer cluster neural network for totally unconstrained handwrit- ten numeral recognition, Neural Networks 8 (5) (1995) 783–792
S.-W. Lee, Multilayer cluster neural network for totally unconstrained handwrit- ten numeral recognition, Neural Networks 8 (5) (1995) 783–792
1995
-
[31]
Roh, H.-K
M.-C. Roh, H.-K. Shin, S.-W. Lee, View-independent human action recognition with volume motion template on single stereo camera, Pattern Recognition Let- ters 31 (7) (2010) 639–647
2010
-
[32]
S.-W. Lee, J. H. Kim, F. C. Groen, Translation-, rotation-and scale-invariant recognition of hand-drawn symbols in schematic diagrams, International Journal of Pattern Recognition and Artificial Intelligence 4 (01) (1990) 1–25
1990
-
[33]
Y . Liu, J. Du, X. Gao, J. Han, L. Shao, Relation-aware meta-learning for zero- shot sketch-based image retrieval, IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[34]
J. Du, Y . Liu, X. Gao, J. Han, L. Zhang, Zero-shot sketch-based image retrieval with teacher-guided and student-centered cross-modal bidirectional knowledge distillation, Pattern Recognition 164 (2025) 111529
2025
-
[35]
Y . Liu, J. Du, X. Gao, J. Han, L. Shao, Zero-shot sketch-based image retrieval via mixed species augmentation and bidirectional mining, IEEE Transactions on Circuits and Systems for Video Technology (2026). 34
2026
-
[36]
Baldrati, L
A. Baldrati, L. Agnolucci, M. Bertini, A. Del Bimbo, Zero-shot composed image retrieval with textual inversion, in: Proc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 15338–15347
2023
-
[37]
Karthik, K
S. Karthik, K. Roth, M. Mancini, Z. Akata, Vision-by-language for training- free compositional image retrieval, in: The Twelfth International Conference on Learning Representations, International Conference on Learning Represen- tations, ICLR, 2024
2024
-
[38]
Wu, Y .-Y
R.-D. Wu, Y .-Y . Lin, H.-F. Yang, Training-free zero-shot composed image re- trieval via weighted modality fusion and similarity, in: Proc. International Con- ference on Technologies and Applications of Artificial Intelligence (TAAI), Springer, 2024, pp. 77–90
2024
-
[39]
Kim, Y .-E
Y . Kim, Y .-E. Kim, S.-W. Lee, Enhancing spatio-temporal zero-shot action recog- nition with language-driven description attributes, Pattern Recognition (2025) 112687
2025
-
[40]
J. Byun, S. Jeong, W. Kim, S. Chun, T. Moon, An efficient post-hoc framework for reducing task discrepancy of text encoders for composed image retrieval, in: Proc. IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 3895–3904
2025
-
[41]
Y . K. Jang, D. Huynh, A. Shah, W.-K. Chen, S.-N. Lim, Spherical linear interpo- lation and text-anchoring for zero-shot composed image retrieval, in: European Conference on Computer Vision (ECCV), Springer, 2024, pp. 239–254
2024
-
[42]
Saito, K
K. Saito, K. Sohn, X. Zhang, C.-L. Li, C.-Y . Lee, K. Saenko, T. Pfister, Pic2word: Mapping pictures to words for zero-shot composed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 19305–19314
2023
- [43]
-
[44]
H. Lin, H. Wen, X. Song, M. Liu, Y . Hu, L. Nie, Fine-grained textual inver- sion network for zero-shot composed image retrieval, in: Proc. 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024, pp. 240–250
2024
-
[45]
Y . Suo, F. Ma, L. Zhu, Y . Yang, Knowledge-enhanced dual-stream zero-shot com- posed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 26951–26962
2024
-
[46]
Z. Yang, S. Qian, D. Xue, J. Wu, F. Yang, W. Dong, C. Xu, Semantic editing increment benefits zero-shot composed image retrieval, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1245–1254
2024
-
[47]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, Y . Cao, React: Syn- ergizing reasoning and acting in language models, in: The Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[48]
Kojima, S
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, Y . Iwasawa, Large language mod- els are zero-shot reasoners, Advances in Neural Information Processing Systems (NeurIPS) 35 (2022) 22199–22213
2022
-
[49]
Zubkova, J.-H
H. Zubkova, J.-H. Park, S.-W. Lee, Leveraging contextual confidence for smarter retrieval in large language models, Neural Networks (2026) 108862
2026
-
[50]
D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, et al., Least-to-most prompting enables complex reasoning in large language models, 2023
2023
-
[51]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdh- ery, D. Zhou, Self-consistency improves chain of thought reasoning in language models, in: The Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[52]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, J. Jitsev, Reproducible scaling laws for contrastive 36 language-image learning, in: Proc. IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2023, pp. 2818–2829
2023
-
[53]
Google DeepMind, Introducing gemini 2.0: our new ai model for the agentic era, https://blog.google/technology/ai/google-gemini-2-0/(2024)
2024
-
[54]
G. Gu, S. Chun, W. Kim, Y . Kang, S. Yun, Language-only efficient training of zero-shot composed image retrieval, in: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 13225–13234
2024
-
[55]
Y . Tang, J. Yu, K. Gai, J. Zhuang, G. Xiong, Y . Hu, Q. Wu, Context-i2w: Map- ping images to context-dependent words for accurate zero-shot composed image retrieval, in: Proc. AAAI Conference on Artificial Intelligence, V ol. 38, 2024, pp. 5180–5188
2024
- [56]
-
[57]
this is my unicorn, fluffy
N. Cohen, R. Gal, E. A. Meirom, G. Chechik, Y . Atzmon, “this is my unicorn, fluffy”: Personalizing frozen vision-language representations, in: European Con- ference on Computer Vision (ECCV), Springer, 2022, pp. 558–577. 37
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.