Amplifying Membership Signal Through Chained Regeneration
Pith reviewed 2026-07-01 06:19 UTC · model grok-4.3
The pith
Chained regeneration makes training samples stay coherent longer than non-members in generative models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
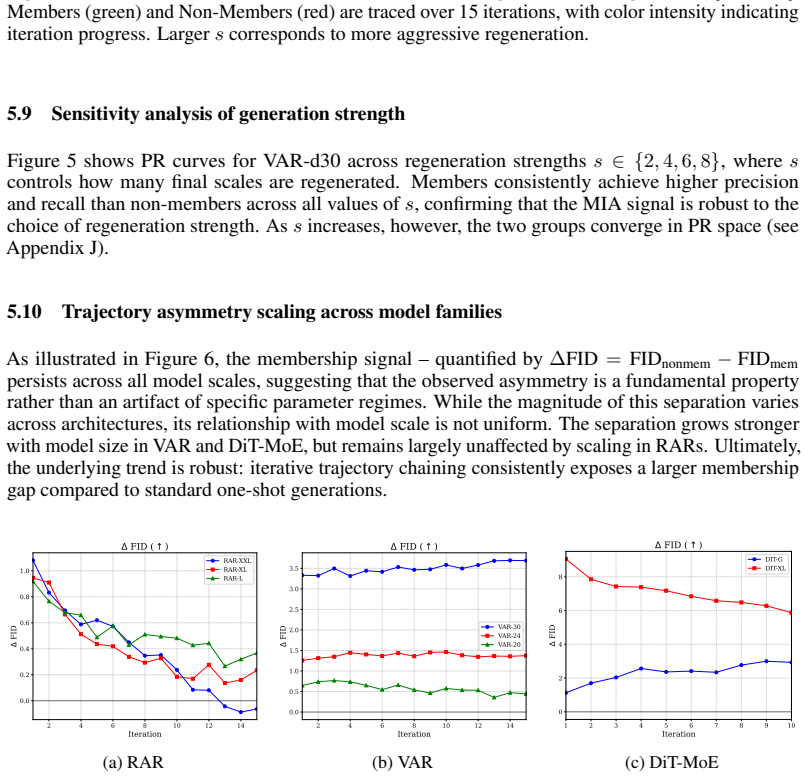
Core claim
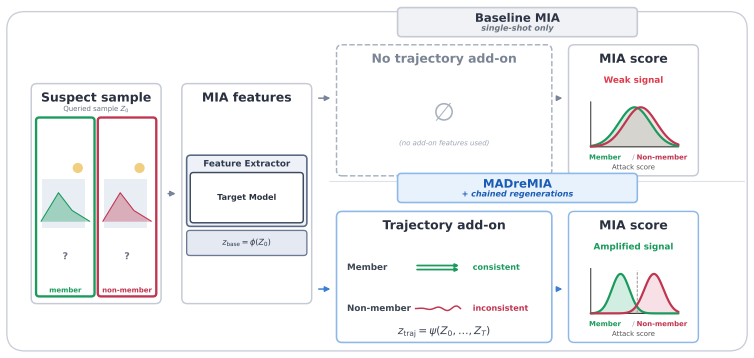
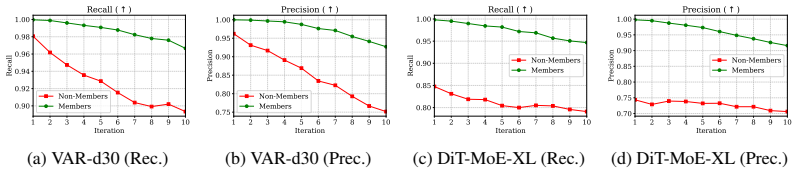
Memorized training samples exhibit significantly higher coherence and slower degradation during iterative regeneration than non-member generations. This difference supplies a usable signal for membership inference and dataset inference that scales without shadow-model training and works in white-box, gray-box, and black-box settings across modalities.
What carries the argument
Chained regeneration, in which each model output is fed back as the next input to produce an iterative trajectory that amplifies coherence differences.
If this is right
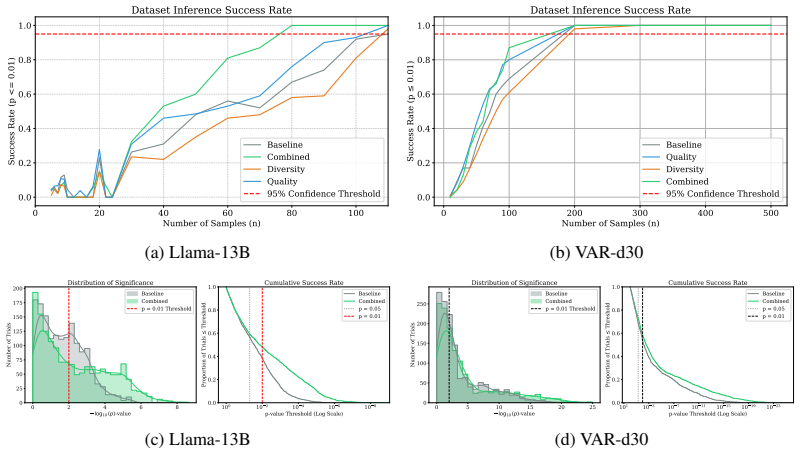
- The approach supplies richer membership signals at low false-positive rates than one-shot generation methods.
- It enables scalable inference for large generative models where shadow-model training is impractical.
- The same chained process improves both membership inference attacks and dataset inference across image, text, and audio modalities.
- It works for a range of model families without requiring access to internal weights in every case.
Where Pith is reading between the lines
- If the coherence gap persists at scale, organizations could audit deployed models for training-data leakage using only query access and repeated sampling.
- The method might also surface other memorized properties such as specific styles or sources beyond simple membership.
- Limits could appear when regeneration noise eventually swamps the membership signal after many iterations.
Load-bearing premise
The coherence and degradation differences observed in chained generations are caused by membership status rather than other sample properties or generation artifacts.
What would settle it
A controlled test in which non-member samples, when regenerated in the same chained manner, show coherence and degradation curves statistically indistinguishable from those of member samples.
Figures
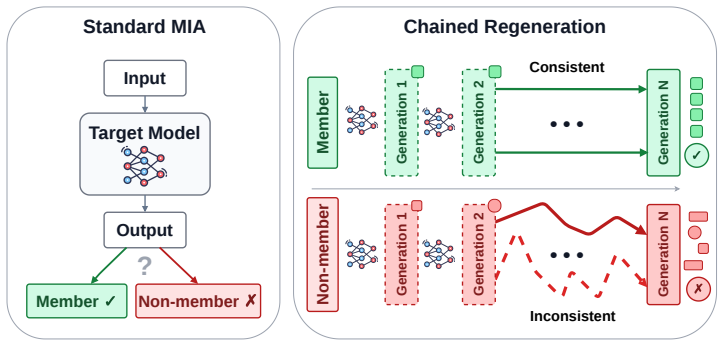
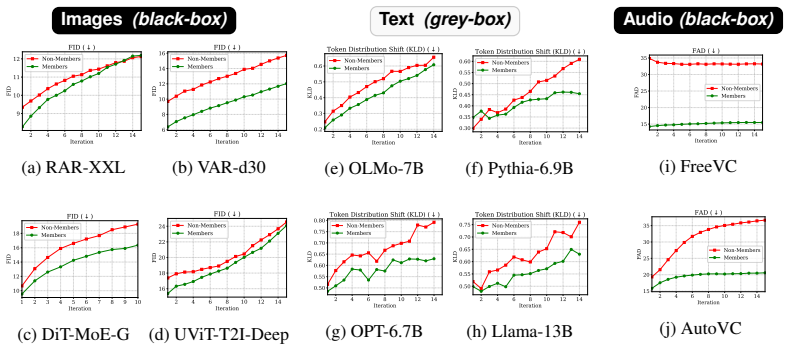

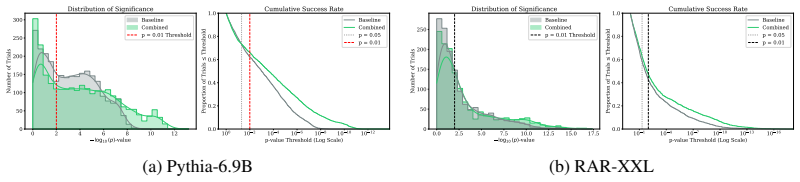
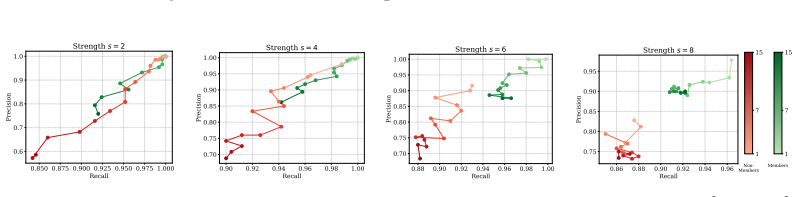
read the original abstract
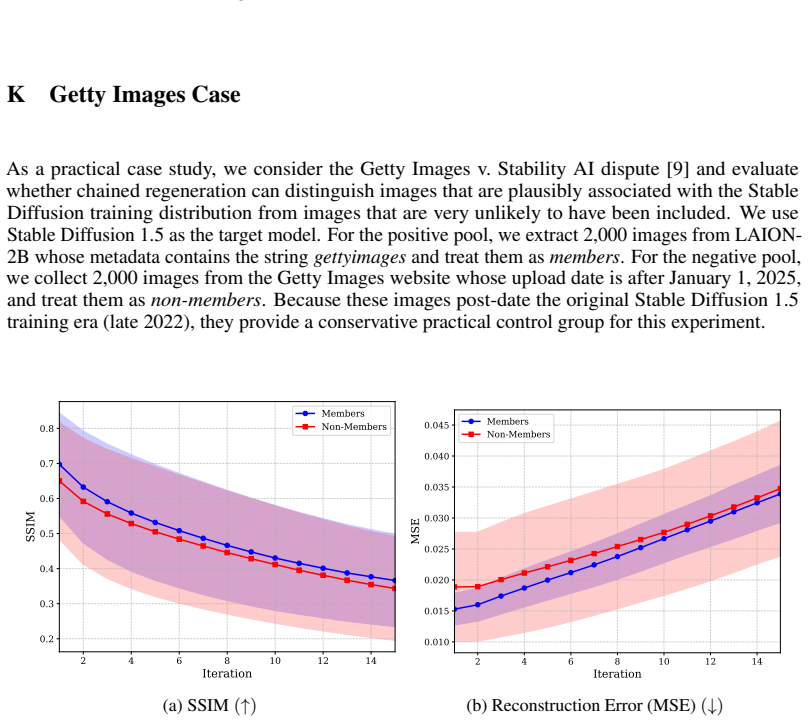
The tendency of large generative models to memorize training data makes sample verification critical for privacy auditing and copyright enforcement. Current membership (MIA) and dataset inference (DI) attacks often rely on one-shot generations, which yield weak signals and limited sensitivity across modalities. Inspired by Model Autophagy Disorder (MAD), we introduce MADreMIA, a model-agnostic framework that enhances white-, gray-, and black-box MIA and DI. Rather than relying on shadow model training -- often infeasible for large generative models -- our framework facilitates scalable inference by leveraging inherent signals through iterative trajectories. This process utilizes chained generations across diverse modalities, where each output serves as the subsequent input, to improve membership evidence at low FPR. We demonstrate that memorized training samples exhibit significantly higher coherence and slower degradation during iterative regeneration than non-member generations. Our results show that MADreMIA provides richer signals across diverse model families and modalities; we present comprehensive evaluations for IARs, diffusion, and language models, alongside preliminary results demonstrating its potential for audio models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MADreMIA, a model-agnostic framework that amplifies membership inference (MIA) and dataset inference (DI) signals in generative models by performing chained iterative regeneration across modalities. It claims that training-set (member) samples produce generations with significantly higher coherence and slower degradation than non-members, yielding stronger signals at low false-positive rates without requiring shadow models. Evaluations are presented for image autoregressive models, diffusion models, language models, and preliminary audio results.
Significance. If the central empirical claim holds after proper controls, the approach would provide a practical, scalable alternative to shadow-model-based MIA for large generative models, addressing a key limitation in privacy auditing and copyright enforcement. The absence of shadow training and the cross-modality scope are notable strengths if the coherence signal is shown to be membership-specific rather than an artifact of sample selection.
major comments (3)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The non-member comparator samples are not described as being matched or controlled for properties such as likelihood under the base data distribution, intrinsic complexity, or alignment with model inductive biases. Without such controls, the reported coherence and degradation gaps cannot be attributed to membership status rather than these confounding factors, directly undermining the central claim that the signal arises from training exposure.
- [§3] §3 (MADreMIA Framework): The definition of 'coherence' and the degradation metric are not formalized with equations or pseudocode; it is unclear whether these quantities are computed in a manner that could be reproduced or whether they inadvertently encode sample-level statistics unrelated to membership.
- [Table 2 and Figure 3] Table 2 and Figure 3 (Quantitative Results): The reported improvements in MIA AUC and low-FPR TPR are presented without ablation on the choice of regeneration chain length or input diversity, making it impossible to assess whether the gains are robust or sensitive to hyperparameter choices that could correlate with sample properties.
minor comments (2)
- [Abstract] The abstract and introduction use 'MADreMIA' without an explicit expansion on first use; a parenthetical definition would improve readability.
- [Figures 2-4] Several figures lack error bars or statistical significance markers on the coherence curves, which would help readers assess the reliability of the reported gaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The non-member comparator samples are not described as being matched or controlled for properties such as likelihood under the base data distribution, intrinsic complexity, or alignment with model inductive biases. Without such controls, the reported coherence and degradation gaps cannot be attributed to membership status rather than these confounding factors, directly undermining the central claim that the signal arises from training exposure.
Authors: We acknowledge this limitation in the current description. Non-members were sampled from held-out data in the same domain but without explicit matching on likelihood or complexity. In the revision we will add controls by selecting non-member subsets matched on model likelihood and report results on complexity-matched pairs (e.g., via entropy or feature-norm proxies). We will also discuss whether the cross-modality consistency of the gap supports a membership-specific interpretation beyond these factors. revision: yes
-
Referee: [§3] §3 (MADreMIA Framework): The definition of 'coherence' and the degradation metric are not formalized with equations or pseudocode; it is unclear whether these quantities are computed in a manner that could be reproduced or whether they inadvertently encode sample-level statistics unrelated to membership.
Authors: We agree that formal definitions are required. The revised manuscript will include explicit equations: coherence as the average modality-specific similarity (e.g., embedding cosine for images, token overlap for text) between consecutive chain outputs, and degradation as the linear slope of coherence versus iteration count. Pseudocode for the full procedure will be added to the appendix to ensure the metrics depend on the regeneration trajectory. revision: yes
-
Referee: [Table 2 and Figure 3] Table 2 and Figure 3 (Quantitative Results): The reported improvements in MIA AUC and low-FPR TPR are presented without ablation on the choice of regeneration chain length or input diversity, making it impossible to assess whether the gains are robust or sensitive to hyperparameter choices that could correlate with sample properties.
Authors: We will incorporate ablations on chain length (varying 1–20 iterations) and input diversity (temperature and top-p sweeps) as new tables/figures. These will show that AUC and low-FPR TPR gains stabilize for chain lengths ≥4 and remain consistent across moderate diversity settings, addressing sensitivity concerns. revision: yes
Circularity Check
No circularity: empirical observation of regeneration coherence presented without self-referential derivation or fitted predictions
full rationale
The abstract and described method frame MADreMIA as an empirical framework that observes higher coherence and slower degradation in chained generations for memorized samples. No equations, fitted parameters, or self-citations are indicated that would reduce the membership signal to a definition or input by construction. The central claim rests on direct demonstration across modalities rather than any load-bearing self-citation chain or ansatz smuggled via prior work. This is a standard non-finding for an observation-driven attack paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative regeneration trajectories preserve distinguishable coherence signals tied to training membership.
Reference graph
Works this paper leans on
-
[1]
Self-consuming generative models go mad
Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard Baraniuk. Self-consuming generative models go mad. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[2]
Ching-Yuan Bai, Hsuan-Tien Lin, Colin Raffel, and Wendy Chi-wen Kan. On training sample memorization: Lessons from benchmarking generative modeling with a large-scale competition. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, page 2534–2542, New York, NY , USA, 2021. Association for Computing Machinery. ISB...
-
[3]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. InCVPR, 2023
2023
-
[4]
Pythia: a suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: a suite for analyzing large language models across training and scaling. InProceedings of the 40th International Conferen...
2023
-
[5]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[6]
Context-aware membership inference attacks against pre-trained large language models
Hongyan Chang, Ali Shahin Shamsabadi, Kleomenis Katevas, Hamed Haddadi, and Reza Shokri. Context-aware membership inference attacks against pre-trained large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7299–7321, 2025
2025
-
[7]
Enhancing privacy-utility trade-offs to mitigate memorization in diffusion models.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8182–8191, 2025
Chen Chen, Daochang Liu, Mubarak Shah, and Chang Xu. Enhancing privacy-utility trade-offs to mitigate memorization in diffusion models.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8182–8191, 2025. URL https: //api.semanticscholar.org/CorpusID:278129333
2025
-
[8]
Label- only membership inference attacks
Christopher A Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. Label- only membership inference attacks. InInternational conference on machine learning, pages 1964–1974. PMLR, 2021
1964
-
[9]
Aiming for fairness: an exploration into getty images v
Matthew Coulter. Aiming for fairness: an exploration into getty images v. stability ai and its importance in the landscape of modern copyright law.DePaul J. Art Tech. & Intell. Prop. L, 34: 124, 2024
2024
-
[10]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[11]
Do membership inference attacks work on large language models? InConference on Language Modeling (COLM), 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models? InConference on Language Modeling (COLM), 2024
2024
-
[12]
Cdi: Copyrighted data identification in diffusion models
Jan Dubi´nski, Antoni Kowalczuk, Franziska Boenisch, and Adam Dziedzic. Cdi: Copyrighted data identification in diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18674–18684, 2025
2025
-
[13]
Scaling diffusion transformers to 16 billion parameters, 2024
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, and Junshi Huang. Scaling diffusion transformers to 16 billion parameters, 2024. URLhttps://arxiv.org/abs/2407.11633
-
[14]
Olmo: Accelerating the science of language models
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15789–15809, 2024. 11
2024
-
[15]
On memorization in diffusion models
Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. On memorization in diffusion models.arXiv preprint arXiv:2310.02664, 2023
-
[16]
Be like a goldfish, don’t memorize! mitigating memorization in generative llms.Advances in Neural Information Processing Systems, 37:24022–24045, 2024
Abhimanyu Hans, Yuxin Wen, Neel Jain, John Kirchenbauer, Hamid Kazemi, Prajwal Singhania, Siddharth Singh, Gowthami Somepalli, Jonas Geiping, Abhinav Bhatele, et al. Be like a goldfish, don’t memorize! mitigating memorization in generative llms.Advances in Neural Information Processing Systems, 37:24022–24045, 2024
2024
-
[17]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[18]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fr\’echet audio dis- tance: A metric for evaluating music enhancement algorithms.arXiv preprint arXiv:1812.08466, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Privacy attacks on image autoregressive models
Antoni Kowalczuk, Jan Dubi´nski, Franziska Boenisch, and Adam Dziedzic. Privacy attacks on image autoregressive models. InForty-second International Conference on Machine Learning,
-
[20]
URLhttps://openreview.net/forum?id=7SXXczJCWP
-
[21]
Towards black-box membership inference attack for diffusion models.CoRR, abs/2405.20771, 2024
Jingwei Li, Jing Dong, Tianxing He, and Jingzhao Zhang. Towards black-box membership inference attack for diffusion models.CoRR, abs/2405.20771, 2024. doi: 10.48550/arXiv.2405. 20771. URLhttps://doi.org/10.48550/arXiv.2405.20771
-
[22]
Freevc: Towards high-quality text-free one-shot voice conversion
Jingyi Li, Weiping Tu, and Li Xiao. Freevc: Towards high-quality text-free one-shot voice conversion. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[23]
Reassessing emnlp 2024’s best paper: Does divergence- based calibration for mias hold up? InThe Fourth Blogpost Track at ICLR 2025
Pratyush Maini and Anshuman Suri. Reassessing emnlp 2024’s best paper: Does divergence- based calibration for mias hold up? InThe Fourth Blogpost Track at ICLR 2025
2024
-
[24]
Dataset inference: Ownership resolution in machine learning.arXiv preprint arXiv:2104.10706, 2021
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. Dataset inference: Ownership resolution in machine learning.arXiv preprint arXiv:2104.10706, 2021
-
[25]
LLM dataset inference: Did you train on my dataset?CoRR, abs/2406.06443, 2024
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. LLM dataset inference: Did you train on my dataset?CoRR, abs/2406.06443, 2024. doi: 10.48550/arXiv.2406.06443. URLhttps://doi.org/10.48550/arXiv.2406.06443
-
[26]
Autovc: Zero-shot voice style transfer with only autoencoder loss
Kaizhi Qian, Yang Zhang, Shiyu Chang, Xuesong Yang, and Mark Hasegawa-Johnson. Autovc: Zero-shot voice style transfer with only autoencoder loss. InInternational Conference on Machine Learning, pages 5210–5219. PMLR, 2019
2019
-
[27]
Mitigating memorization in language models
Mansi Sakarvadia, Aswathy Ajith, Arham Mushtaq Khan, Nathaniel C Hudson, Caleb Geniesse, Kyle Chard, Yaoqing Yang, Ian Foster, and Michael W Mahoney. Mitigating memorization in language models. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[28]
Detecting Pretraining Data from Large Language Models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[30]
Ai models collapse when trained on recursively generated data.Nature, 631:755–759, 07
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 631:755–759, 07
-
[31]
doi: 10.1038/s41586-024-07566-y
-
[32]
Aaditya K Singh, Muhammed Yusuf Kocyigit, Andrew Poulton, David Esiobu, Maria Lomeli, Gergely Szilvasy, and Dieuwke Hupkes. Evaluation data contamination in llms: how do we measure it and (when) does it matter?arXiv preprint arXiv:2411.03923, 2024. 12
-
[33]
Dolma: An open corpus of three trillion tokens for language model pretraining research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. Dolma: An open corpus of three trillion tokens for language model pretraining research. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2024
-
[34]
CoRRabs/2510.03163(2025).https://doi.org/10.48550/ARXIV.2510
Jiashu Tao and Reza Shokri. (token-level) InfoRMIA: Stronger membership inference and memorization assessment for LLMs.CoRR, abs/2510.05582, 2025. doi: 10.48550/arXiv.2510. 05582. URLhttps://doi.org/10.48550/arXiv.2510.05582
-
[35]
Visual autoregressive modeling: Scalable image generation via next-scale prediction, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction, 2024. URL https://arxiv. org/abs/2404.02905
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
On memorization in probabilistic deep generative models
Gerrit van den Burg and Chris Williams. On memorization in probabilistic deep generative models. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 27916–27928. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/ paper/2021/f...
2021
-
[38]
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images
Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie. Coco-text: Dataset and benchmark for text detection and recognition in natural images.arXiv preprint arXiv:1601.07140, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
2004
-
[40]
Detecting, explaining, and mitigating memorization in diffusion models
Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. Detecting, explaining, and mitigating memorization in diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=84n3UwkH7b
2024
-
[41]
You only query once: An efficient label-only membership inference attack
YUTONG WU, Han Qiu, Shangwei Guo, Jiwei Li, and Tianwei Zhang. You only query once: An efficient label-only membership inference attack. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=7WsivwyHrS
2024
-
[42]
Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92).The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web. ku. edu/˜ idea/readings/rainbow. htm)., 2019
2019
-
[43]
Enhanced membership inference attacks against machine learning models
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Vincent Bindschaedler, and Reza Shokri. Enhanced membership inference attacks against machine learning models. InProceedings of the 2022 ACM SIGSAC conference on computer and communications security, pages 3093–3106, 2022
2022
-
[44]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF), pages 268–282. IEEE, 2018
2018
-
[45]
Randomized autoregressive visual generation, 2024
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, and Liang-Chieh Chen. Randomized autore- gressive visual generation, 2024. URLhttps://arxiv.org/abs/2411.00776
-
[46]
De- tecting data contamination in LLMs via in-context learning
Michał Zawalski, Meriem Boubdir, Klaudia Bałazy, Besmira Nushi, and Pablo Ribalta. De- tecting data contamination in LLMs via in-context learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=YlpaaYxx4t. 13
2026
-
[47]
Heiga Zen, Viet Dang, Robert A. J. Clark, Yu Zhang, Ron J. Weiss, Ye Jia, Z. Chen, and Yonghui Wu. Libritts: A corpus derived from librispeech for text-to-speech. InInterspeech,
-
[48]
URLhttps://api.semanticscholar.org/CorpusID:102352475
-
[49]
arXiv preprint arXiv:2404.02936 , year=
Jingyang Zhang, Jingwei Sun, Eric C. Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Yang, and Hai Helen Li. Min-k%++: Improved baseline for detecting pre-training data from large language models.CoRR, abs/2404.02936, 2024. doi: 10.48550/arXiv.2404.02936. URL https://doi.org/10.48550/arXiv.2404.02936
-
[50]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[51]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Membership inference attacks against synthetic health data.Journal of biomedical informatics, 125:103977, 2022
Ziqi Zhang, Chao Yan, and Bradley A Malin. Membership inference attacks against synthetic health data.Journal of biomedical informatics, 125:103977, 2022. 14 A Impact Statement This work advances methods for auditing generative models by improving membership and dataset inference through chained regeneration. The primary positive impact is stronger accoun...
2022
-
[53]
The benchmarking study [2] demonstrated that standard evaluation metrics fail to surface memorization even in competitive settings
localize this phenomenon through bright-ending cross-attention patterns, while the sharpness- based framework of [38] justifies score-difference memorization metrics and proposes mitigation via sharpness-aware regularization of the initial noise. The benchmarking study [2] demonstrated that standard evaluation metrics fail to surface memorization even in ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.