When to Personalize Household Object Search: A Rigidity-Gated Hybrid Policy
Pith reviewed 2026-07-02 21:47 UTC · model grok-4.3
The pith
A rigidity-gated hybrid policy personalizes robot object search only for low-rigidity household items while retaining population baselines for fixed placements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
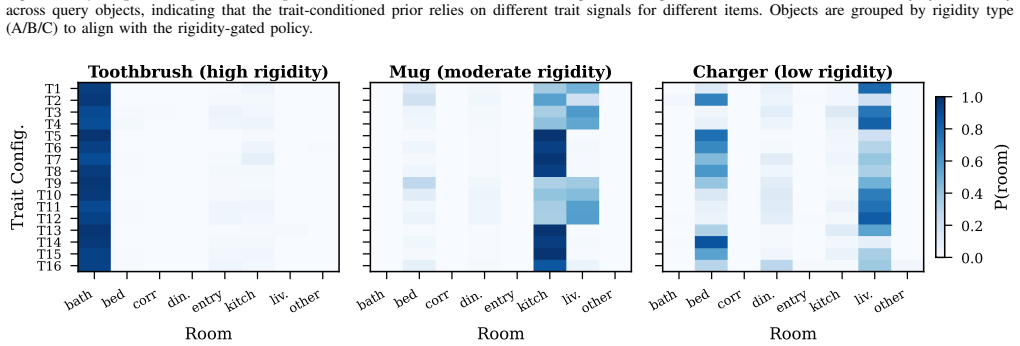
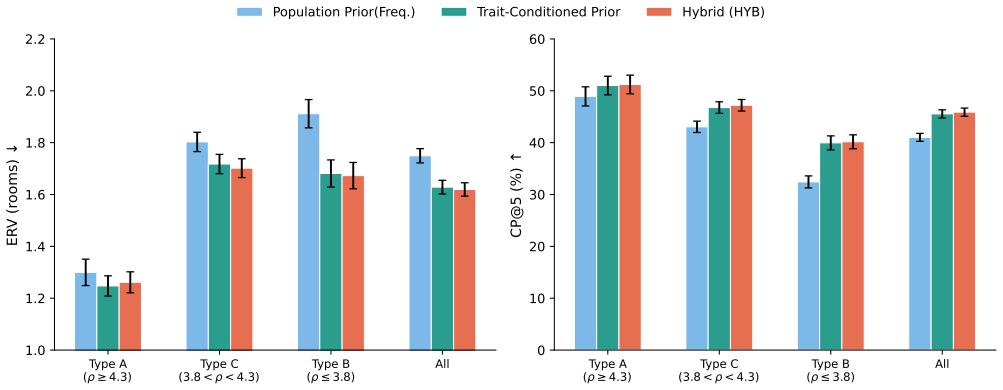
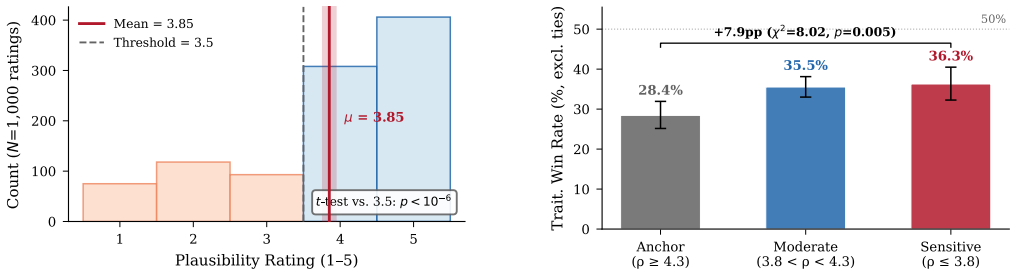
In a blinded A/B comparison personalization is favored primarily for low-rigidity objects while the population-frequency baseline remains strong for universally placed items, yielding a decision rule for when to personalize; the same policy produces a small but significant improvement on unseen continuous trait vectors and reduces expected search cost in a home digital twin by combining room visitation effort with within-room cue checking.
What carries the argument
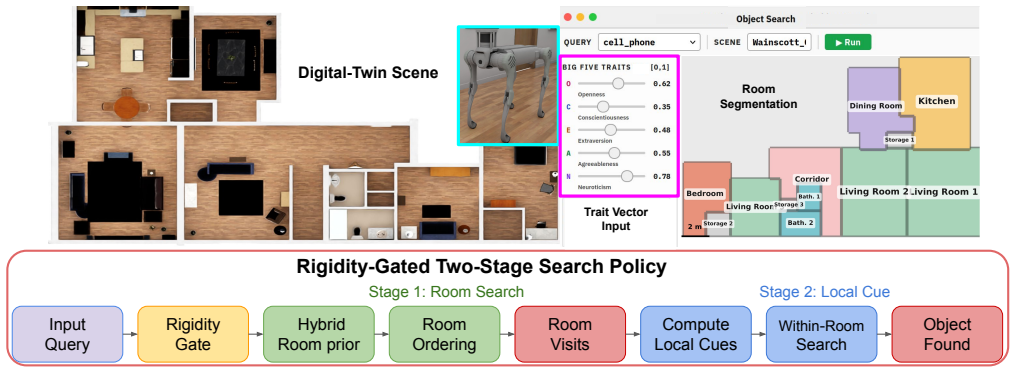
The rigidity-gated hybrid policy PerSim that injects continuous Big Five trait vectors into a predictor for room-level priors and within-room co-occurrence cues, switching to personalization only when placement behavior is variable.
If this is right
- Personalization should be applied selectively according to measured object rigidity rather than uniformly.
- Population-frequency priors remain effective for items with low placement variability.
- Continuous trait vectors enable modest interpolation gains over discrete configuration matching.
- End-to-end search cost decreases when room visitation and cue checking are combined under the gated policy.
Where Pith is reading between the lines
- The decision rule could be applied online by observing placement consistency over a short period rather than requiring full personality profiles upfront.
- The same gating logic might transfer to other variable human-preference tasks such as meal planning or activity scheduling.
- If simulation plausibility ratings hold in longitudinal real-home data, the approach would allow scaling without invasive trajectory collection.
Load-bearing premise
The human-calibrated simulation pipeline produces object-placement transitions that are sufficiently behaviorally plausible to support the personalization decision rule and end-to-end cost reductions.
What would settle it
A real-home deployment in which PerSim yields no measurable reduction in expected search cost compared with the population baseline on the same set of residents and objects.
Figures


read the original abstract
Service robots searching for household objects rely on spatial priors to reduce search cost, yet object locations can vary with resident traits. Collecting longitudinal, trait-specific in-home trajectories is invasive and hard to scale. We study when personalization helps and propose PerSim, a rigidity-gated hybrid policy that combines a trait-conditioned prior with a population-frequency baseline, personalizing only when placement behavior is variable. To scale resident-conditioned dynamics, we employ a human-calibrated simulation pipeline to generate and validate object-placement transitions in diverse home layouts, and train a predictor that injects continuous Big Five vectors to output room-level priors and within-room co-occurrence cues. In a unified human study (N=200), dual-layer validation shows that (i) synthetic transitions are judged behaviorally plausible (mean 3.85/5, p < 1e-6), and (ii) in a blinded A/B comparison, personalization is favored primarily for low-rigidity objects (p=0.005), while the population-frequency baseline remains strong for universally placed items, yielding a decision rule for when to personalize. In an offline objective test, we observe a small but significant improvement on unseen continuous trait vectors over nearest discrete configuration matching (p=0.035), supporting interpolation in five-dimensional trait space. Finally, in a home digital twin we show that PerSim reduces expected search cost by combining room visitation effort with within-room cue checking, demonstrating end-to-end gains beyond isolated prediction metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PerSim, a rigidity-gated hybrid policy for household object search that personalizes only when placement behavior is variable according to resident traits. It introduces a human-calibrated simulation pipeline to generate trait-conditioned room-level priors and co-occurrence cues using continuous Big Five personality vectors. Validation includes a human study (N=200) demonstrating synthetic transition plausibility (mean 3.85/5) and preference for personalization on low-rigidity objects in blinded A/B tests (p=0.005), a small improvement on unseen trait vectors (p=0.035), and reduced expected search cost in a home digital twin.
Significance. If the central claims hold, the work offers a practical framework for deciding when personalization is beneficial in service robotics, potentially reducing search costs without requiring extensive real-world data collection. The combination of simulation with human validation and the hybrid policy is a notable contribution. The blinded A/B comparison and digital-twin evaluation provide direct evidence for the decision rule and end-to-end gains.
major comments (3)
- [Abstract] Abstract: The p-values (p=0.005 for A/B comparison, p=0.035 for offline test) are reported without accompanying methods details, error bars, sample sizes per condition, or data exclusion criteria, which undermines assessment of the statistical claims central to the 'when to personalize' decision rule.
- [Human study / simulation pipeline] Human study and simulation pipeline: Validation of synthetic transitions rests solely on aggregate plausibility ratings (mean 3.85/5, p<1e-6) without per-object or per-trait quantitative metrics, comparison to longitudinal real-home data, or ablation showing that rating differences translate into policy performance differences; this assumption is load-bearing for both the rigidity-gated rule and the digital-twin cost reductions.
- [Offline objective test] Offline objective test: The reported improvement on unseen continuous trait vectors is presented without equations, fitting details, or predictor architecture, making it impossible to determine whether the gain is independent of simulation parameters or reduces to quantities defined by the trait vectors themselves.
minor comments (2)
- [Abstract] The abstract does not reference specific sections, tables, or figures supporting the reported p-values and ratings.
- Notation for the continuous Big Five trait vectors and the rigidity gate is introduced without an explicit equation or definition in the provided summary.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications and commit to revisions for improved statistical and methodological transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The p-values (p=0.005 for A/B comparison, p=0.035 for offline test) are reported without accompanying methods details, error bars, sample sizes per condition, or data exclusion criteria, which undermines assessment of the statistical claims central to the 'when to personalize' decision rule.
Authors: We agree that additional statistical details are required. In the revised manuscript we will expand the methods and results sections to specify the exact tests used, sample sizes per condition (from the N=200 study), error bars or confidence intervals, and any data exclusion criteria applied. These elements will be moved from supplementary material into the main text where appropriate. revision: yes
-
Referee: [Human study / simulation pipeline] Human study and simulation pipeline: Validation of synthetic transitions rests solely on aggregate plausibility ratings (mean 3.85/5, p<1e-6) without per-object or per-trait quantitative metrics, comparison to longitudinal real-home data, or ablation showing that rating differences translate into policy performance differences; this assumption is load-bearing for both the rigidity-gated rule and the digital-twin cost reductions.
Authors: We will add per-object and per-trait rating breakdowns in the revision. An ablation correlating plausibility ratings with downstream policy performance in the digital twin will also be included. Longitudinal real-home data collection was not performed due to privacy and scalability constraints; the human-calibrated simulation is presented as a practical proxy, and we will clarify this limitation explicitly. revision: partial
-
Referee: [Offline objective test] Offline objective test: The reported improvement on unseen continuous trait vectors is presented without equations, fitting details, or predictor architecture, making it impossible to determine whether the gain is independent of simulation parameters or reduces to quantities defined by the trait vectors themselves.
Authors: We will add the predictor equations, architecture description (trait-vector input to room-level and co-occurrence outputs), fitting procedure, and offline evaluation protocol to the revised manuscript. This will make clear that the reported gain reflects interpolation over continuous trait space rather than simulation artifacts. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's central claims rest on an external human study (N=200) providing blinded A/B preference data and aggregate plausibility ratings for the simulation outputs, plus an offline comparison against a discrete matching baseline on unseen trait vectors. These elements are independent of the simulation parameters themselves and do not reduce by construction to fitted inputs or self-definitions; the digital-twin cost evaluation compares policy variants within the calibrated environment but reports relative gains rather than tautological equivalence. No equations, self-citations, or ansatzes are shown to create load-bearing circular reductions.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.