DroneFINE: Domain-Aware Parameter-Efficient Fine-Tuning of Vision-Language Detectors for Drone Images
Pith reviewed 2026-07-02 15:21 UTC · model grok-4.3
The pith
DroneFINE matches full fine-tuning performance on drone images using far fewer trainable parameters
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
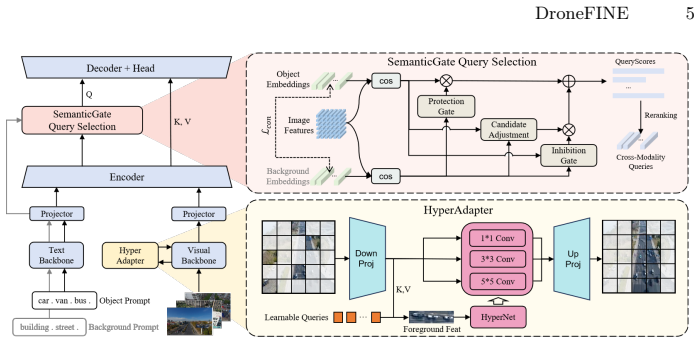
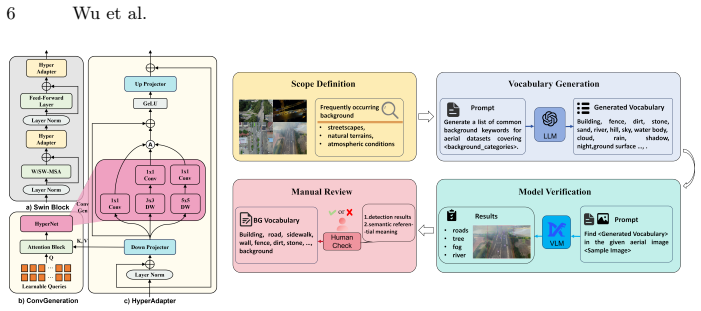
DroneFINE introduces HyperAdapter, a data-dependent foreground-aware multi-path adaptation mechanism that relaxes the static constraints of conventional PEFT, together with SemanticGate, a text-conditioned background suppression strategy that uses background vocabulary to steer the model away from irrelevant regions. Together these modules enable VLMs to handle the domain shift in UAV imagery, delivering detection performance on VisDrone and UAVDT that surpasses existing PEFT baselines and approaches the accuracy of full fine-tuning while training far fewer parameters.
What carries the argument
HyperAdapter and SemanticGate modules that supply dynamic, foreground-aware adaptation and text-guided background suppression inside VLM-based detectors.
If this is right
- UAV object detection becomes practical without retraining every parameter in a large VLM.
- Text-conditioned background suppression can reduce false positives in open aerial scenes.
- Data-dependent multi-path adaptation can extend the reach of PEFT beyond its usual limits.
- Detection systems for dynamic environments can maintain high accuracy at lower training cost.
Where Pith is reading between the lines
- The same domain-aware modules could be tested on other overhead imaging tasks such as satellite or medical aerial views.
- Reduced parameter counts may allow on-device adaptation of detectors directly aboard UAVs.
- Combining the modules with quantization or pruning could push efficiency gains further in resource-limited settings.
Load-bearing premise
The natural-scene priors in VLMs create a mismatch with drone imagery that static PEFT structures cannot resolve, but the proposed modules can.
What would settle it
If side-by-side experiments on VisDrone and UAVDT show DroneFINE failing to exceed other PEFT methods or to reach parity with full fine-tuning, the central claim would not hold.
Figures


read the original abstract
Object detection for Unmanned Aerial Vehicles (UAVs) working in open and dynamic environments is a highly challenging task. While Vision-Language Models (VLMs) have offered a powerful solution for universal object detection, adapting them to UAV scenarios remains non-trivial due to a substantial domain gap between VLM pre-training data and aerial imagery. The prevailing Parameter-Efficient Fine-Tuning (PEFT) methods prove ineffective in bridging this gap, as VLMs' "natural-scene, foreground-dominant" visual priors misalign with the "bird's-eye-view, background-dominant, small-object" characteristics of UAV data. To address this issue, we propose DroneFINE, a novel PEFT paradigm comprising two domain-aware complementary modules tailored for VLM-based drone image detectors. Specifically, a data-dependent, foreground-aware, and multi-path adaptation mechanism named HyperAdapter is designed, which overcomes the static structural constraints of PEFT. In addition, a background suppression algorithm named SemanticGate is developed. It is a text-conditioned guidance strategy that employs background vocabulary to actively guide the model in suppressing responses from irrelevant regions. Extensive experiments on VisDrone and UAVDT demonstrate that DroneFINE significantly outperforms existing PEFT methods and achieves performance comparable to full fine-tuning while substantially reducing the number of trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DroneFINE, a domain-aware PEFT method for adapting vision-language models to UAV object detection. It argues that standard PEFT fails due to misalignment between natural-scene foreground-dominant priors and UAV bird's-eye-view, background-dominant, small-object characteristics. The method introduces HyperAdapter (data-dependent multi-path adaptation) and SemanticGate (text-conditioned background suppression using background vocabulary). Experiments on VisDrone and UAVDT are claimed to show that DroneFINE outperforms existing PEFT baselines, approaches full fine-tuning performance, and uses far fewer trainable parameters.
Significance. If the experimental comparisons hold under fair and reproducible conditions, the work provides a practical, parameter-efficient route for specializing large VLMs to aerial imagery, which is valuable for UAV applications where compute is limited. The explicit targeting of domain-specific visual priors via HyperAdapter and SemanticGate offers a concrete design pattern that could generalize to other domain shifts in detection tasks.
minor comments (2)
- [Abstract] Abstract: the claim of 'significantly outperforms existing PEFT methods' and 'performance comparable to full fine-tuning' is stated without any numerical values, mAP deltas, or parameter counts; adding one or two headline metrics would make the abstract self-contained.
- The description of HyperAdapter as overcoming 'static structural constraints of PEFT' would be strengthened by an explicit side-by-side comparison (text or diagram) of its data-dependent multi-path routing versus a standard adapter block.
Simulated Author's Rebuttal
We thank the referee for their positive summary of DroneFINE and for recommending minor revision. The provided report contains no enumerated major comments, so we have no specific points to rebut or revise at this stage. We remain available to address any minor issues or clarifications the editor may request.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on empirical comparisons of the proposed DroneFINE (with HyperAdapter and SemanticGate) against PEFT baselines and full fine-tuning on the external public datasets VisDrone and UAVDT. No derivation chain, mathematical prediction, or fitted parameter is presented that reduces to its own inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The method design is motivated by stated domain gaps but validated externally through benchmark results rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C., Cheng, T., Zhao, Q., Li, B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C.C., Lin, D.: MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[2]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Zeng, Y., Chen, Z., Gao, H., Chen, L., Liu, J., Zhao, F.: Vfm-adapter: Adapting visual foundation models for dense prediction with dynamic hybrid oper- ation mapping. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2385–2393 (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, T., Song, L., Ge, Y., Liu, W., Wang, X., Shan, Y.: Yolo-world: Real-time open-vocabulary object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16901–16911 (2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Du, B., Huang, Y., Chen, J., Huang, D.: Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 13435–13444 (2023)
2023
-
[5]
In: Proceedings of the European conference on computer vision (ECCV)
Du, D., Qi, Y., Yu, H., Yang, Y., Duan, K., Li, G., Zhang, W., Huang, Q., Tian, Q.: The unmanned aerial vehicle benchmark: Object detection and tracking. In: Proceedings of the European conference on computer vision (ECCV). pp. 370–386 (2018)
2018
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision workshops
Du, D., Zhu, P., Wen, L., Bian, X., Lin, H., Hu, Q., Peng, T., Zheng, J., Wang, X., Zhang, Y., et al.: Visdrone-det2019: The vision meets drone object detection in image challenge results. In: Proceedings of the IEEE/CVF international conference on computer vision workshops. pp. 0–0 (2019)
2019
-
[7]
Advances in Neural Information Processing Systems38, 95228– 95251 (2026)
Gao, Y., Zhang, Y., Cai, Z., Huang, D.: Test-time adaptive object detection with foundation model. Advances in Neural Information Processing Systems38, 95228– 95251 (2026)
2026
-
[8]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Gao, Y., Zhang, Y., Huang, Z., Liu, N., Huang, D.: Ps-ttl: Prototype-based soft- labels and test-time learning for few-shot object detection. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 8691–8700 (2024)
2024
-
[9]
arXiv preprint arXiv:2302.07937 (2023)
Giannou, A., Rajput, S., Papailiopoulos, D.: The expressive power of tuning only the normalization layers. arXiv preprint arXiv:2302.07937 (2023)
-
[10]
arXiv preprint arXiv:2204.13653 (2022)
Gupta, T., Marten, R., Kembhavi, A., Hoiem, D.: Grit: General robust image task benchmark. arXiv preprint arXiv:2204.13653 (2022)
-
[11]
Ha, D., Dai, A., Le, Q.V.: Hypernetworks. arXiv preprint arXiv:1609.09106 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Neural computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
1997
-
[13]
In: International conference on machine learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International conference on machine learning. pp. 2790–2799. PMLR (2019)
2019
-
[14]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[15]
arXiv preprint arXiv:2505.05741 (2025)
Hu, Z., Wu, P., Chen, J., Zhu, H., Wang, Y., Peng, Y., Li, H., Sun, X.: Dome- detr: Detr with density-oriented feature-query manipulation for efficient tiny object detection. arXiv preprint arXiv:2505.05741 (2025)
-
[16]
In: Proceedings of the AAAI conference on artificial intelligence
Huang, Y., Chen, J., Huang, D.: Ufpmp-det: Toward accurate and efficient object detection on drone imagery. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 1026–1033 (2022) DroneFINE 17
2022
-
[17]
In: European conference on computer vision
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: European conference on computer vision. pp. 709–727. Springer (2022)
2022
-
[18]
arXiv preprint arXiv:2207.07039 (2022)
Jie, S., Deng, Z.H.: Convolutional bypasses are better vision transformer adapters. arXiv preprint arXiv:2207.07039 (2022)
-
[19]
com/ultralytics/ultralytics
Jocher, G., Chaurasia, A., Qiu, J.: Ultralytics yolov8 (2023),https://github. com/ultralytics/ultralytics
2023
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, C., Zhao, R., Wang, Z., Xu, H., Zhu, X.: Remdet: Rethinking efficient model de- sign for uav object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4643–4651 (2025)
2025
-
[21]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10965–10975 (2022)
2022
-
[22]
Li, M., Chen, J., Feng, W., Li, B., Dai, F., Zhao, S., He, Q.: Hyperlora: Parameter- efficientadaptivegenerationforportraitsynthesis.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 13114–13123 (2025)
2025
-
[23]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, N., Ye, M., Zhou, L., Tang, S., Gan, Y., Liang, Z., Zhu, X.: Self-prompting ana- logical reasoning for uav object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 18412–18420 (2025)
2025
-
[24]
In: Proceedings of the European Conference on Computer Vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Proceedings of the European Conference on Computer Vision. pp. 740–755. Springer (2014)
2014
-
[25]
IEEE Transactions on Image Processing (2024)
Liu, K., Fu, Z., Jin, S., Chen, Z., Zhou, F., Jiang, R., Chen, Y., Ye, J.: Esod: efficient small object detection on high-resolution images. IEEE Transactions on Image Processing (2024)
2024
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Liu, L., Wang, N., Chen, C., Liu, D., Yang, X., Gao, X., Liu, T.: Frequency-based comprehensive prompt learning for vision-language models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[27]
In: Forty-second International Conference on Machine Learning (2025)
Liu, L., Wang, N., Yang, X., Gao, X., Liu, T.: Surrogate prompt learning: Towards efficient and diverse prompt learning for vision-language models. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, M., Hayes, T.L., Ricci, E., Csurka, G., Volpi, R.: Shine: Semantic hierarchy nexus for open-vocabulary object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16634–16644 (2024)
2024
-
[29]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[30]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Liu, S., Zhang, H., Qi, Y., Wang, P., Zhang, Y., Wu, Q.: Aerialvln: Vision-and- language navigation for uavs. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 15384–15394 (2023)
2023
-
[31]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Lv, C., Li, L., Zhang, S., Chen, G., Qi, F., Zhang, N., Zheng, H.T.: Hyperlora: Efficient cross-task generalization via constrained low-rank adapters generation. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 16376–16393 (2024)
2024
-
[32]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
sensing community
Pan, J., Liu, Y., Fu, Y., Ma, M., Li, J., Paudel, D.P., Van Gool, L., Huang, X.: Locate anything on earth: Advancing open-vocabulary object detection for remote 18 Wu et al. sensing community. In: Proceedings of the AAAI Conference on Artificial Intelli- gence. vol. 39, pp. 6281–6289 (2025)
2025
-
[34]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[35]
Ren, T., Chen, Y., Jiang, Q., Zeng, Z., Xiong, Y., Liu, W., Ma, Z., Shen, J., Gao, Y., Jiang, X., et al.: Dino-x: A unified vision model for open-world object detection and understanding. arXiv preprint arXiv:2411.14347 (2024)
-
[36]
In: Proceedings of the IEEE/CVF international conference on computer vision
Shao, S., Li, Z., Zhang, T., Peng, C., Yu, G., Zhang, X., Li, J., Sun, J.: Objects365: A large-scale, high-quality dataset for object detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8430–8439 (2019)
2019
-
[37]
Information Fusion122, 103158 (2025)
Tian, Y., Lin, F., Li, Y., Zhang, T., Zhang, Q., Fu, X., Huang, J., Dai, X., Wang, Y., Tian, C., et al.: Uavs meet llms: Overviews and perspectives towards agentic low-altitude mobility. Information Fusion122, 103158 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, J., Zhang, P., Chu, T., Cao, Y., Zhou, Y., Wu, T., Wang, B., He, C., Lin, D.: V3det: Vast vocabulary visual detection dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19844–19854 (2023)
2023
-
[39]
arXiv preprint arXiv:2410.07087 (2024)
Wang, X., Yang, D., Wang, Z., Kwan, H., Chen, J., Wu, W., Li, H., Liao, Y., Liu, S.: Towards realistic uav vision-language navigation: Platform, benchmark, and methodology. arXiv preprint arXiv:2410.07087 (2024)
-
[40]
arXiv preprint arXiv:2408.12246 (2024)
Wei, G., Yuan, X., Liu, Y., Shang, Z., Xue, X., Wang, P., Yao, K., Zhao, C., Zhang, H., Xiao, R.: Rt-ovad: Real-time open-vocabulary aerial object detection via image-text collaboration. arXiv preprint arXiv:2408.12246 (2024)
-
[41]
In: Proceedings of the IEEE/CVF Confer- ence on computer vision and pattern recognition
Yang, C., Huang, Z., Wang, N.: Querydet: Cascaded sparse query for accelerating high-resolution small object detection. In: Proceedings of the IEEE/CVF Confer- ence on computer vision and pattern recognition. pp. 13668–13677 (2022)
2022
-
[42]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, F., Fan, H., Chu, P., Blasch, E., Ling, H.: Clustered object detection in aerial images. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8311–8320 (2019)
2019
-
[43]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Yin, D., Hu, L., Li, B., Zhang, Y., Yang, X.: 5%> 100%: Breaking performance shackles of full fine-tuning on visual recognition tasks. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 20071–20081 (2025)
2025
-
[44]
In: The Eleventh International Conference on Learning Representations
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In: The Eleventh International Conference on Learning Representations
-
[45]
arXiv preprint arXiv:2505.05622 (2025)
Zhang, W., Gao, C., Yu, S., Peng, R., Zhao, B., Zhang, Q., Cui, J., Chen, X., Li, Y.: Citynavagent: Aerial vision-and-language navigation with hierarchical semantic planning and global memory. arXiv preprint arXiv:2505.05622 (2025)
-
[46]
arXiv preprint arXiv:2401.02361 (2024)
Zhao, X., Chen, Y., Xu, S., Li, X., Wang, X., Li, Y., Huang, H.: An open and comprehensive pipeline for unified object grounding and detection. arXiv preprint arXiv:2401.02361 (2024)
-
[47]
International Journal of Computer Vision130(9), 2337–2348 (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision130(9), 2337–2348 (2022)
2022
-
[48]
Drones9(8), 557 (2025)
Zhou, Y., Li, J., Ou, C., Yan, D., Zhang, H., Xue, X.: Open-vocabulary object detection in uav imagery: A review and future perspectives. Drones9(8), 557 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.