Selective Test-Time Debiasing for CLIP via Reward Gating
Pith reviewed 2026-07-02 13:34 UTC · model grok-4.3
The pith
RG-TTA uses an RL policy during test-time adaptation to gate fairness regularization only on bias-sensitive inputs to CLIP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
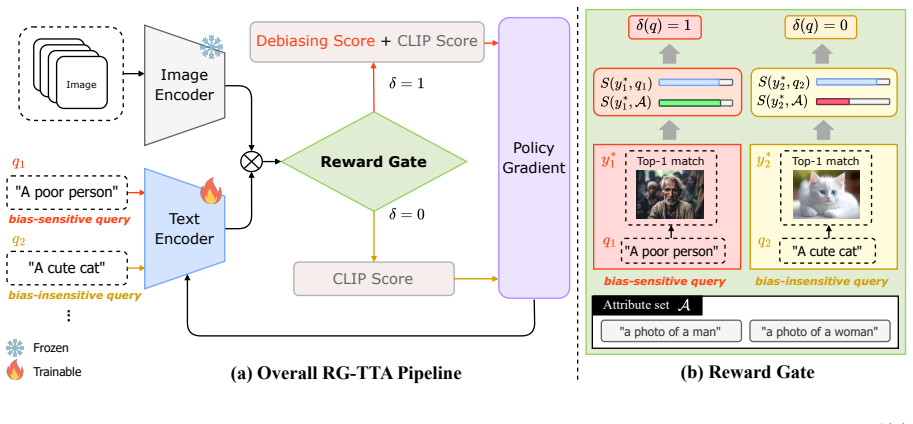
RG-TTA is a reinforcement learning-based test-time adaptation method that adaptively triggers fairness regularization according to the bias sensitivity of each input, while restricting itself to cross-modal alignment optimization on bias-insensitive inputs, thereby reducing social stereotypes without the utility penalty imposed by uniform debiasing.
What carries the argument
Reward-Gated Test-Time Adaptation (RG-TTA), an RL policy trained at test time that outputs a gating decision to apply or withhold fairness regularization per input.
If this is right
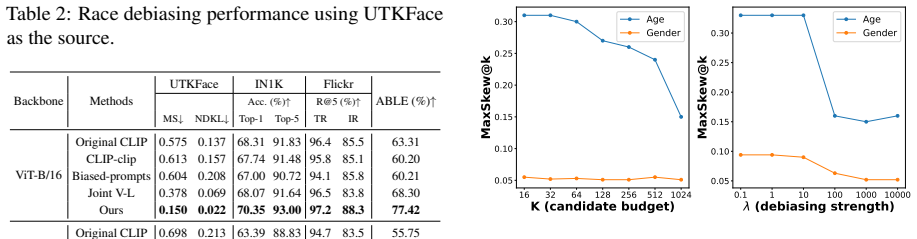
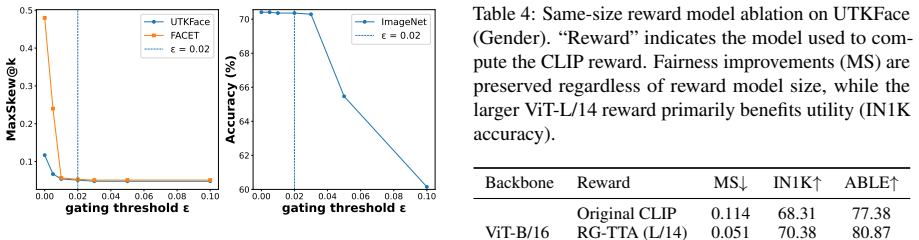
- Bias metrics drop on FairFace and UTKFace while zero-shot classification accuracy rises.
- Semantically meaningful information in bias-insensitive queries remains undistorted.
- The fairness-utility trade-off of uniform debiasing is avoided by per-input selection.
- The same test-time policy can be reused across multiple queries without retraining the base VLM.
Where Pith is reading between the lines
- The gating idea could be transferred to other test-time adaptation methods that currently use fixed regularization strength.
- If the policy learns a general notion of sensitivity, the same weights might work on new face datasets or related tasks without further fine-tuning.
- An extension worth checking is whether the approach reduces bias on non-face person-centric queries such as occupation or activity descriptions.
Load-bearing premise
The RL policy can reliably estimate whether a given input is bias-sensitive so that the gating decision correctly separates the two regimes.
What would settle it
A controlled test in which the learned policy misclassifies bias-sensitive inputs as insensitive, after which bias metrics remain high while utility gains disappear.
Figures



read the original abstract
Vision language models (VLMs) demonstrate strong zero-shot performance, but often perpetuate social stereotypes in person-centric queries, yielding skewed demographic distributions. Current debiasing methods apply uniform bias corrections across all input queries regardless of their bias sensitivity, creating a fundamental fairness--utility trade-off. Strong debiasing distorts semantically meaningful information in bias-insensitive queries, while weak debiasing fails to mitigate stereotypes in bias-sensitive ones. This one-size-fits-all approach hampers simultaneously achieving high utility on bias-insensitive queries and fairness on bias-sensitive queries. We introduce Reward-Gated Test-Time Adaptation (RG-TTA), a reinforcement learning-based test-time adaptation framework that selectively applies debiasing based on input sensitivity. RG-TTA adaptively triggers fairness regularization based on the bias sensitivity of each input during test-time policy adaptation, while focusing exclusively on optimizing cross-modal alignment for bias-insensitive inputs. Experiments on fairness benchmarks (e.g., FairFace, UTKFace) demonstrate substantial bias reduction while simultaneously improving zero-shot utility, resolving the trade-off of uniform debiasing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that uniform debiasing in vision-language models like CLIP creates an unavoidable fairness-utility trade-off because it applies the same correction strength to all inputs. It introduces Reward-Gated Test-Time Adaptation (RG-TTA), an RL-based test-time adaptation method that learns a policy to gate fairness regularization on only bias-sensitive inputs while optimizing pure cross-modal alignment on bias-insensitive inputs. Experiments on FairFace and UTKFace are said to show simultaneous bias reduction and improved zero-shot utility.
Significance. If the adaptive gating mechanism reliably separates inputs by bias sensitivity, the approach would address a practical limitation of existing debiasing methods and allow VLMs to maintain utility on non-stereotyped queries while correcting stereotypes where needed. This selective strategy could influence test-time adaptation techniques more broadly.
major comments (3)
- [Abstract] Abstract: The central claim that 'RG-TTA adaptively triggers fairness regularization based on the bias sensitivity of each input' during test-time policy adaptation rests on an unverified assumption that the RL policy can accurately classify sensitivity from rewards alone. No description is given of the reward function components that would encode bias sensitivity, no sensitivity labels or proxies, and no ablation measuring gating accuracy (e.g., precision/recall on sensitive vs. insensitive queries).
- [Abstract] Abstract / Experiments: The assertion of 'substantial bias reduction while simultaneously improving zero-shot utility' supplies no method details, baselines, statistical tests, ablation results, or quantitative numbers, preventing verification of whether the data support the dual-improvement claim or whether the method collapses to uniform debiasing.
- [Method] Method description: No equations or formal derivation of the reward function, policy objective, or gating decision are provided, making it impossible to determine whether the separation of bias-sensitive and bias-insensitive inputs is achieved by construction or learned reliably at test time.
minor comments (1)
- [Abstract] The abstract refers to 'fairness benchmarks (e.g., FairFace, UTKFace)' without specifying the exact metrics (e.g., demographic parity, equalized odds) or zero-shot utility measures used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the manuscript lacks sufficient detail on the reward function, experimental support, and formal method descriptions. We will revise the paper to incorporate these elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'RG-TTA adaptively triggers fairness regularization based on the bias sensitivity of each input' during test-time policy adaptation rests on an unverified assumption that the RL policy can accurately classify sensitivity from rewards alone. No description is given of the reward function components that would encode bias sensitivity, no sensitivity labels or proxies, and no ablation measuring gating accuracy (e.g., precision/recall on sensitive vs. insensitive queries).
Authors: We agree the current version does not sufficiently detail the reward components or provide verification. In revision we will explicitly define the reward function as a weighted sum of a fairness term (demographic parity violation on predicted attributes) and an alignment term (CLIP similarity), with bias sensitivity emerging from the magnitude of the fairness component during test-time RL. We will add an ablation reporting gating precision/recall using dataset-provided demographic annotations as sensitivity proxies. revision: yes
-
Referee: [Abstract] Abstract / Experiments: The assertion of 'substantial bias reduction while simultaneously improving zero-shot utility' supplies no method details, baselines, statistical tests, ablation results, or quantitative numbers, preventing verification of whether the data support the dual-improvement claim or whether the method collapses to uniform debiasing.
Authors: The full experiments section reports results on FairFace and UTKFace against uniform debiasing baselines, but the abstract is too terse. We will expand the abstract with key quantitative deltas and add statistical tests plus an ablation comparing selective vs. uniform gating to confirm the dual improvement is not an artifact of uniform behavior. revision: yes
-
Referee: [Method] Method description: No equations or formal derivation of the reward function, policy objective, or gating decision are provided, making it impossible to determine whether the separation of bias-sensitive and bias-insensitive inputs is achieved by construction or learned reliably at test time.
Authors: We will insert the missing formalization: the reward r = α·fairness_penalty + (1-α)·alignment_reward, the policy objective as the expected return under PPO-style updates at test time, and the gating rule as a stochastic threshold on the learned policy output. This will show the separation is learned rather than hard-coded. revision: yes
Circularity Check
No circularity; method is algorithmic description without self-referential derivations
full rationale
The paper introduces RG-TTA as an RL-based test-time adaptation procedure that selectively gates debiasing via a learned policy. No equations, derivations, or parameter-fitting steps are described in the provided text that would reduce a claimed prediction or result to the same inputs by construction. The central claim rests on experimental outcomes on external benchmarks (FairFace, UTKFace) rather than any self-definitional or fitted-input mechanism. No load-bearing self-citations or uniqueness theorems are invoked. This is the common case of a self-contained algorithmic proposal whose validity is assessed externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Vision-Language Models Performing Zero-Shot Tasks Exhibit Gender-Based Disparities , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[2]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES) , year =
Identifying Implicit Social Biases in Vision-Language Models , author =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES) , year =
-
[3]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Multi-Modal Bias: Introducing a Framework for Stereotypical Bias Assessment Beyond Gender and Race in Vision--Language Models , author =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Understanding and Evaluating Racial Biases in Image Captioning , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[5]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
ImageNet: A Large-Scale Hierarchical Image Database , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[6]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models , author =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
-
[7]
Proceedings of the 38th International Conference on Machine Learning , series =
Learning Transferable Visual Models from Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , series =. 2021 , publisher =
2021
-
[8]
arXiv preprint arXiv:2110.01963 , year =
Multimodal Datasets: Misogyny, Pornography, and Malignant Stereotypes , author =. arXiv preprint arXiv:2110.01963 , year =. doi:10.48550/arXiv.2110.01963 , archivePrefix =. 2110.01963 , primaryClass =
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhang, Haoyu and Guo, Yangyang and Kankanhalli, Mohan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Bias in Gender Bias Benchmarks: How Spurious Features Distort Evaluation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year =
BendVLM: Test-Time Debiasing of Vision-Language Embeddings , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
CLIP the Bias: How Useful Is Balancing Data in Multimodal Learning? , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[13]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Rethinking Entropy in Test-Time Adaptation: The Missing Piece from Energy Duality , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[15]
Machine Learning , volume =
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =
-
[16]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Test-Time Training with Self-Supervision for Generalization under Distribution Shifts , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[17]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Tent: Fully Test-Time Adaptation by Entropy Minimization , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
TTT++: When Does Self-Supervised Test-Time Training Fail or Thrive? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Train/Test-Time Adaptation with Retrieval , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
arXiv preprint arXiv:2511.18123 , year =
Bias Is a Subspace, Not a Coordinate: A Geometric Rethinking of Post-hoc Debiasing in Vision-Language Models , author =. arXiv preprint arXiv:2511.18123 , year =
-
[22]
arXiv preprint arXiv:2406.11331 , year =
They’re All Doctors: Synthesizing Diverse Counterfactuals to Mitigate Associative Bias , author =. arXiv preprint arXiv:2406.11331 , year =
-
[23]
Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , year =
A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning , author =. Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , year =
-
[24]
International Conference on Learning Representations , year =
FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs , author =. International Conference on Learning Representations , year =
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Model-Agnostic Gender Debiased Image Captioning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
SocialCounterfactuals: Probing and Mitigating Intersectional Social Biases in Vision-Language Models with Counterfactual Examples , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
-
[27]
International Conference on Learning Representations , year =
Debias Your VLM with Counterfactuals: A Unified Approach , author =. International Conference on Learning Representations , year =
-
[28]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year =
CABIN: Debiasing Vision-Language Models Using Backdoor Adjustments , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year =
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
DEAR: Debiasing Vision-Language Models with Additive Residuals , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[30]
arXiv preprint arXiv:2311.07604 (2023)
Finetuning Text-to-Image Diffusion Models for Fairness , author =. arXiv preprint arXiv:2311.07604 , year =
-
[31]
Are Gender-Neutral Queries Really Gender-Neutral? Mitigating Gender Bias in Image Search , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2021.emnlp-main.151 , pages =
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Debiasing Vision-Language Models via Biased Prompts , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[33]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
-
[34]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , year =
Age Progression/Regression by Conditional Adversarial Autoencoder , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , year =
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
FACET: Fairness in Computer Vision Evaluation Benchmark , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[36]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
DEAR: Debiasing Vision-Language Models with Additive Residuals , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[38]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[39]
and Knott, Manuel and Camerer, Colin F
Hausladen, Carina I. and Knott, Manuel and Camerer, Colin F. and Perona, Pietro , title =. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , pages =. 2025 , doi =
2025
-
[40]
Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , pages =
Wolfe, Robert and Yang, Yiwei and Howe, Bill and Caliskan, Aylin , title =. Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , pages =. 2023 , doi =
2023
-
[41]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Hirota, Yusuke and Chen, Min-Hung and Wang, Chien-Yi and Nakashima, Yuta and Wang, Yu-Chiang Frank and Hachiuma, Ryo , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Zhu, Beier and Cui, Jiequan and Zhang, Hanwang and Zhang, Chi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.