Gaze-Informed Proactive AI Assistance for Children's Picture Exploration
Pith reviewed 2026-07-02 06:51 UTC · model grok-4.3
The pith
Gaze data lets an AI system deliver picture descriptions that hold children's attention longer and guide them to related regions more effectively than random prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
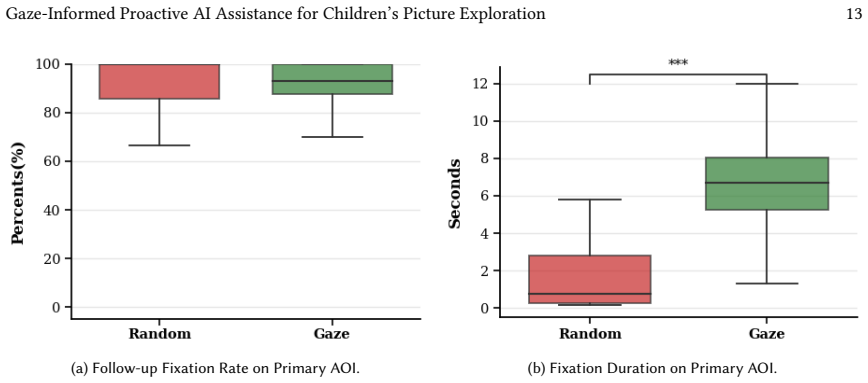
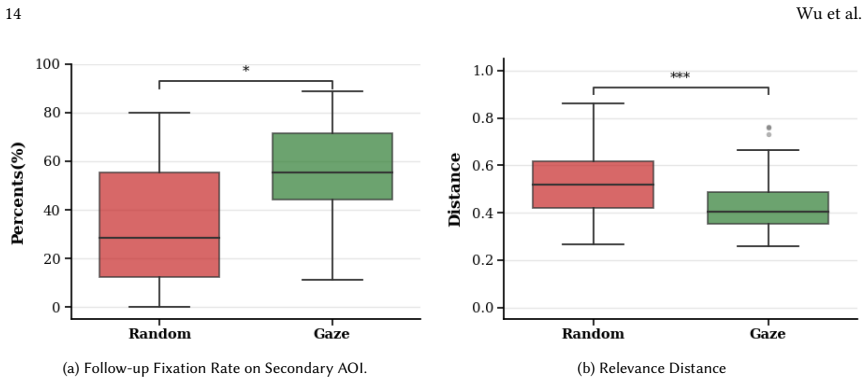
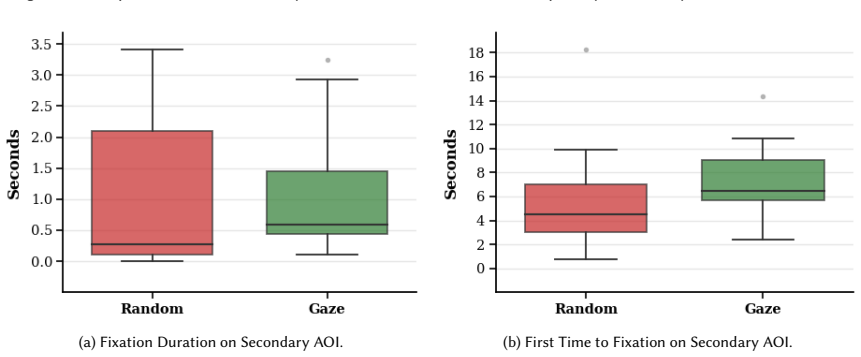
Ollie estimates a child's attention from gaze, identifies the current visual focus, selects a related picture region, and triggers an LLM to generate a short narrative description of that region; when tested against random region selection, the gaze-informed version produced longer sustained attention on the focal area and more effective movement to related regions, with positive reception from children, parents, and teachers.
What carries the argument
The gaze-to-region mapping that selects which picture area an LLM should describe next, using the child's current fixation as the trigger for proactive narrative assistance.
If this is right
- Proactive LLM assistance for children can operate without requiring explicit verbal requests.
- Nonverbal signals such as gaze become sufficient to time and target assistance during open-ended visual tasks.
- Parents and teachers perceive gaze-matched descriptions as better fitting a child's momentary interests than random ones.
- Design of child-centered AI can shift from request-driven to observation-driven interaction patterns.
Where Pith is reading between the lines
- The same gaze-selection logic could be tested in other child activities that involve visual scanning, such as storybook reading or museum exhibits.
- Combining gaze with additional nonverbal cues like head orientation or pointing might further improve selection accuracy.
- If the approach scales, it could lower the amount of adult scaffolding needed during independent picture-based learning sessions.
Load-bearing premise
A child's gaze direction reliably marks their current interest and the LLM description chosen from that gaze will be relevant and engaging enough to extend attention without breaking the flow of exploration.
What would settle it
A controlled comparison in which gaze-selected LLM descriptions produce no measurable increase in attention duration or related-region exploration compared with randomly chosen descriptions.
Figures

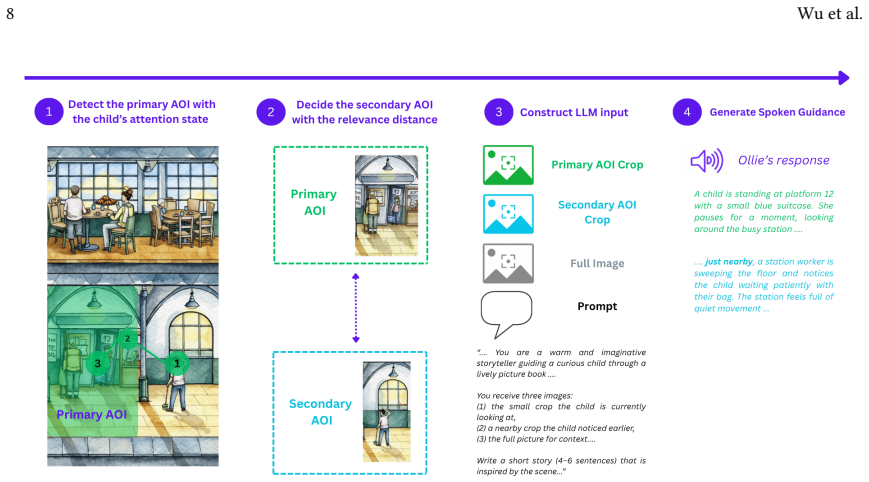

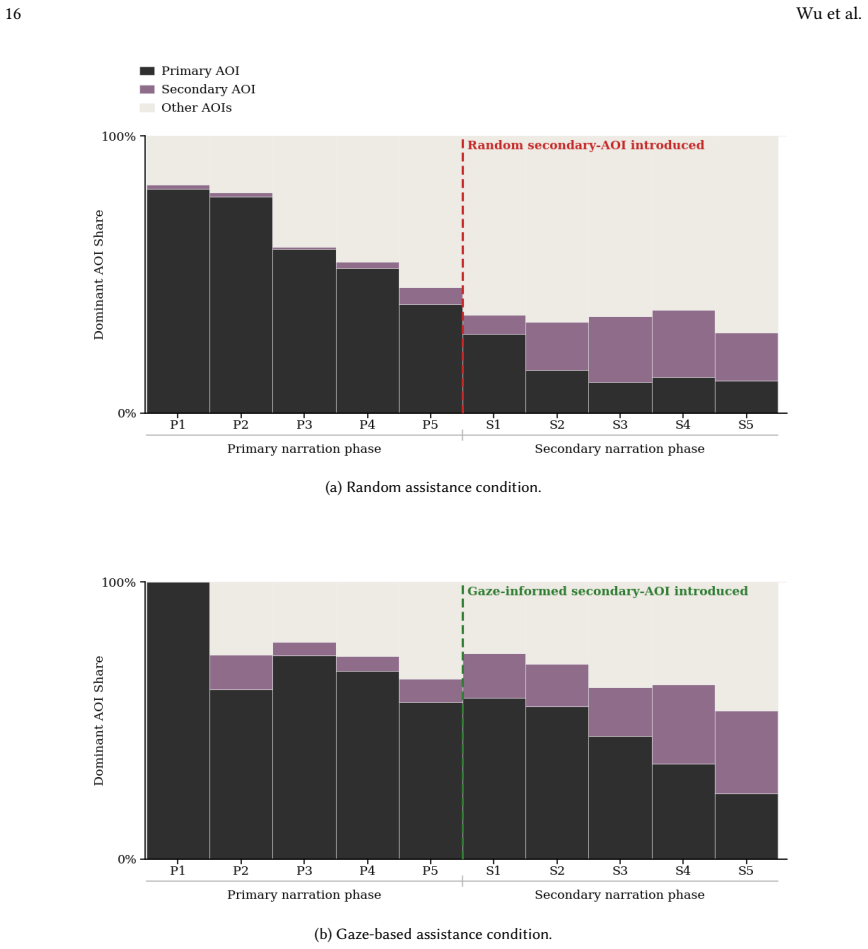
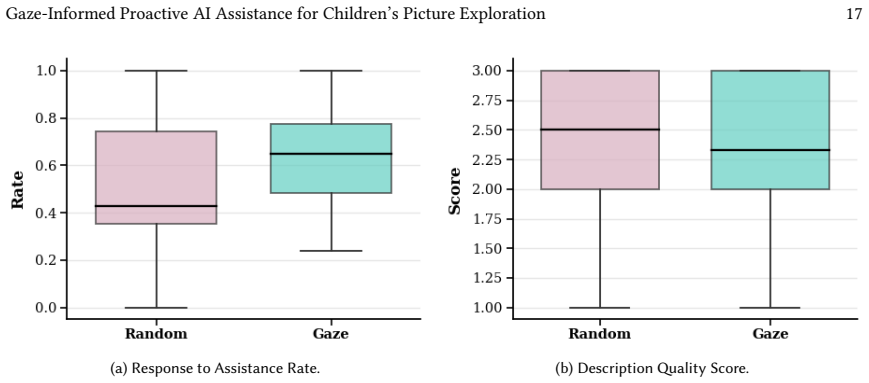
read the original abstract
Proactive assistance with large language models (LLMs) has received growing attention in the human computer interaction (HCI) community. However, most past work on proactive LLMs' assistance has focused on adult users and task-oriented settings, leaving open how such systems could support children, whose interests and needs are often expressed through gaze and other nonverbal behaviors rather than explicit requests. In this study, we focus on two key challenges of proactive assistance in children's picture exploration: when to provide assistance and what assistance to provide based on children's nonverbal behaviors. To address these challenges, we introduce Ollie, a gaze-informed proactive artificial intelligence (AI) assistant that offers short narrative descriptions based on where a child is looking. Ollie uses children's gaze to estimate their attention, identify their current visual focus, and select a related picture region for the LLM to verbally describe. In a within-subject experiment, we compared gaze-informed assistance with random assistance. Results show that gaze-informed assistance kept children's attention on their current focus for a longer period of time, and guided them more effectively to related picture regions. Children, parents, and a participating kindergarten teacher viewed Ollie positively and consider that it better matched children's interests when compared with the random assistance. This work shows the feasibility of using gaze as an implicit input for proactive AI assistance for children and provides design implications for future child-centered AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ollie, a gaze-informed proactive AI assistant for children's picture exploration. It uses children's gaze to estimate attention, identify visual focus, and select related picture regions for short LLM-generated narrative descriptions. A within-subject experiment compares gaze-informed assistance against random assistance, claiming that the gaze-informed version maintains children's attention on their current focus longer, guides them more effectively to related regions, and receives positive feedback from children, parents, and a kindergarten teacher as better matching interests.
Significance. If the empirical results hold with adequate statistical support, this work is significant for extending proactive LLM assistance beyond adult task-oriented settings to children, where interests are expressed nonverbally. The within-subject design with a random baseline directly tests the core assumption that gaze indicates interest, and the positive qualitative feedback provides initial evidence for feasibility and design implications in child-centered AI systems.
major comments (2)
- [Abstract and Results] Abstract and Results: The positive within-subject outcomes (longer attention maintenance and better guidance) are stated without participant numbers, statistical tests, p-values, effect sizes, error bars, or exclusion criteria. This information is load-bearing for assessing whether the data support the central claims about effectiveness over the random baseline.
- [Methods] Methods: The mapping from gaze data to picture regions and the criteria for selecting LLM descriptions are described at a high level but lack sufficient technical detail (e.g., thresholds, algorithms, or examples) to evaluate reliability or enable replication of the proactive assistance mechanism.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative outcome or participant count to better summarize the empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional detail will strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The positive within-subject outcomes (longer attention maintenance and better guidance) are stated without participant numbers, statistical tests, p-values, effect sizes, error bars, or exclusion criteria. This information is load-bearing for assessing whether the data support the central claims about effectiveness over the random baseline.
Authors: We agree that the abstract and results would be clearer with these details included. In the revised manuscript we will report the participant count, statistical tests, p-values, effect sizes, error bars, and exclusion criteria both in the abstract and results section. revision: yes
-
Referee: [Methods] Methods: The mapping from gaze data to picture regions and the criteria for selecting LLM descriptions are described at a high level but lack sufficient technical detail (e.g., thresholds, algorithms, or examples) to evaluate reliability or enable replication of the proactive assistance mechanism.
Authors: We agree that more technical specificity is needed. The revised methods section will include the precise gaze-to-region mapping algorithm, thresholds, selection criteria, and concrete examples of region selection and LLM prompt construction to support replication. revision: yes
Circularity Check
Empirical study with no derivation chain or self-referential reductions
full rationale
The paper reports a within-subject user study comparing gaze-informed vs. random assistance in a children's picture exploration task. Central claims rest on observed behavioral differences (attention duration, region guidance) and qualitative feedback, not on any equations, parameter fits, or predictions derived from prior inputs. No self-citations, ansatzes, or uniqueness theorems appear in the provided text as load-bearing elements. The design directly tests the gaze-as-interest assumption via the random baseline, so the result is not forced by construction. This is a standard empirical HCI evaluation with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gaze tracking can be used to estimate children's attention and identify their current visual focus for selecting picture regions
Reference graph
Works this paper leans on
-
[1]
Basak Alper, Nathalie Henry Riche, Fanny Chevalier, Jeremy Boy, and Metin Sezgin. 2017. Visualization literacy at elementary school. InProceedings of the 2017 CHI conference on human factors in computing systems. 5485–5497
2017
-
[2]
Goun Bae and Jinkyung Katie Park. 2026. When LLMs See Where You Struggle: A Gaze-to-Context Approach for Reader-Driven Reading Assistance. InProceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems. 1–7
2026
-
[3]
Ilene R Berson, Michael J Berson, and Wenwei Luo. 2025. Innovating responsibly: Ethical considerations for AI in early childhood education.AI, Brain and Child1, 1 (2025), 2
2025
-
[4]
Conrad Borchers, Olga Viberg, and René F Kizilcec. 2026. Who Decides in AI-Mediated Learning? The Agency Allocation Framework.arXiv preprint arXiv:2604.13534(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Garvin Brod. 2026. Agency does not equal choice–conceptualizing agency for learning in the age of AI.Learning and Individual Differences125 (2026), 102841
2026
-
[6]
Jerome Bruner. 1991. The narrative construction of reality.Critical inquiry18, 1 (1991), 1–21
1991
-
[7]
Adriana Bus, Natalia Kucirkova, Dieuwer Ten Braak, and Marta Ciesielska. 2025. Which Interactive Features in Children’s Digital Picture Books Promote Reading Comprehension? A Meta-Analysis.Early Education and Development(2025), 1–20
2025
-
[8]
Valerie Chen, Alan Zhu, Sebastian Zhao, Hussein Mozannar, David Sontag, and Ameet Talwalkar. 2025. Need help? designing proactive ai assistants for programming. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–18
2025
-
[9]
Alan Y Cheng, Carolyn Q Zou, Anthony Xie, Matthew Hsu, Felicia Yan, Felicity Huang, David K Zhang, Arjun Sharma, Rashon Poole, Daniel Wan Rosli, et al. 2025. Oak Story: Improving Learner Outcomes with LLM-Mediated Interactive Narratives. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–17
2025
-
[10]
Edwin S Dalmaijer, Sebastiaan Mathôt, and Stefan Van der Stigchel. 2014. PyGaze: An open-source, cross-platform toolbox for minimal-effort programming of eyetracking experiments.Behavior research methods46 (2014), 913–921
2014
-
[11]
Valdemar Danry, Javier Hernandez, Andrew Wilson, Pattie Maes, and Judith Amores. 2026. From Gaze to Guidance: Interpreting and Adapting to Users’ Cognitive Needs with Multimodal Gaze-Aware AI Assistants.arXiv preprint arXiv:2604.08062(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Yang Deng, Lizi Liao, Wenqiang Lei, Grace Hui Yang, Wai Lam, and Tat-Seng Chua. 2025. Proactive conversational ai: A comprehensive survey of advancements and opportunities.ACM Transactions on Information Systems43, 3 (2025), 1–45
2025
-
[13]
Maria K Eckstein, Belén Guerra-Carrillo, Alison T Miller Singley, and Silvia A Bunge. 2017. Beyond eye gaze: What else can eyetracking reveal about cognition and cognitive development?Developmental cognitive neuroscience25 (2017), 69–91
2017
-
[14]
CM Eng, KE Godwin, and AV Fisher. 2020. Keep it simple: Streamlining book illustrations improves attention and comprehension in beginning readers. NPJ Science of Learning, 5 (1), Article 14
2020
-
[15]
Anna Maria Feit, Shane Williams, Arturo Toledo, Ann Paradiso, Harish Kulkarni, Shaun Kane, and Meredith Ringel Morris. 2017. Toward everyday gaze input: Accuracy and precision of eye tracking and implications for design. InProceedings of the 2017 Chi conference on human factors in computing systems. 1118–1130
2017
-
[16]
Dedre Gentner. 1983. Structure-mapping: A theoretical framework for analogy.Cognitive science7, 2 (1983), 155–170
1983
-
[17]
Dedre Gentner and Linsey A Smith. 2013. Analogical learning and reasoning. (2013)
2013
-
[18]
Andrea Follmer Greenhoot, Alisa M Beyer, and Jennifer Curtis. 2014. More than pretty pictures? How illustrations affect parent-child story reading and children’s story recall.Frontiers in psychology5 (2014), 76510
2014
-
[19]
Marilyn E Greenlee-Moore and Lawrence L Smith. 1996. Interactive computer software: The effects on young children’s reading achievement. Reading Psychology: An International Quarterly17, 1 (1996), 43–64
1996
-
[20]
Kunlei He, Aria Gastón-Panthaki, Dongni Zhuo, Joshua Munsey, Maggie Zhang, and Mark Warschauer. 2025. StoryPal: Supporting Young Children’s Dialogic Reading with Large Language Models. InProceedings of the 24th Interaction Design and Children. 494–511
2025
-
[21]
Roy S Hessels, Chantal Kemner, Carlijn van den Boomen, and Ignace TC Hooge. 2016. The area-of-interest problem in eyetracking research: A noise-robust solution for face and sparse stimuli.Behavior research methods48, 4 (2016), 1694–1712
2016
-
[22]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems. 159–166
1999
-
[23]
Eric J Horvitz, John S Breese, David Heckerman, David Hovel, and Koos Rommelse. 2013. The Lumiere project: Bayesian user modeling for inferring the goals and needs of software users.arXiv preprint arXiv:1301.7385(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Junfeng Jiao, Saleh Afroogh, Kevin Chen, Abhejay Murali, David Atkinson, and Amit Dhurandhar. 2025. LLMs and childhood safety: Identifying risks and proposing a protection framework for safe child-LLM interaction.arXiv preprint arXiv:2502.11242(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Minji Kim, Jeewon Jeon, Gerardo Ramirez, and Daeun Park. 2026. Choosing the One Who Sees You: Emotional Responsiveness as a Cue in Children’s Help-Seeking.Developmental Science29, 1 (2026), e70095
2026
-
[26]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. 2023. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision. 4015–4026
2023
- [27]
-
[28]
2005.Before writing: Rethinking the paths to literacy
Gunther Kress. 2005.Before writing: Rethinking the paths to literacy. Routledge. Manuscript submitted to ACM Gaze-Informed Proactive AI Assistance for Children’s Picture Exploration 23
2005
-
[29]
Nomisha Kurian. 2025. AI’s empathy gap: The risks of conversational Artificial Intelligence for young children’s well-being and key ethical considerations for early childhood education and care.Contemporary Issues in Early Childhood26, 1 (2025), 132–139
2025
-
[30]
Jieon Lee, Daeho Lee, and Jae-gil Lee. 2022. Can robots help working parents with childcare? Optimizing childcare functions for different parenting characteristics.International Journal of Social Robotics14, 1 (2022), 193–211
2022
- [31]
-
[32]
Sina Lenski and Jörg Großschedl. 2023. Emotional design pictures: Pleasant but too weak to evoke arousal and attract attention?Frontiers in Psychology13 (2023), 966287
2023
-
[33]
Chia-Ning Liao, Kuo-En Chang, Yu-Ching Huang, and Yao-Ting Sung. 2020. Electronic storybook design, kindergartners’ visual attention, and print awareness: An eye-tracking investigation.Computers & Education144 (2020), 103703
2020
-
[34]
Grace C Lin, Ilana Schoenfeld, Meredith Thompson, Yiting Xia, Cigdem Uz-Bilgin, and Kathryn Leech. 2022. ” What color are the fish’s scales?” Exploring parents’ and children’s natural interactions with a child-friendly virtual agent during storybook reading. InProceedings of the 21st Annual ACM Interaction Design and Children Conference. 185–195
2022
-
[35]
Dongtao Liu, Ying Zhang, and Yinghong Zhang. 2024. The potential of interactive design in children’s picture books and its impact on user experience. InInternational Conference on Human-Computer Interaction. Springer, 365–382
2024
-
[36]
Nina Liu, Chen Chen, Yingying Liu, Shan Jiang, QianCheng Gao, and Ruihan Wu. 2024. The interference effect of low-relevant animated elements on digital picture-book comprehension in preschoolers: An eye-movement study.Journal of Eye Movement Research17, 4 (2024), 19
2024
-
[37]
Shi Liu, Martin Feick, Linus Bierhoff, and Alexander Maedche. 2026. AttentiveLearn: Personalized Post-Lecture Support for Gaze-Aware Immersive Learning. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–18
2026
-
[38]
Xiaoxiao Liu and Ying Cui. 2025. Eye tracking technology for examining cognitive processes in education: A systematic review.Computers & Education(2025), 105263
2025
-
[39]
Xingyu Bruce Liu, Shitao Fang, Weiyan Shi, Chien-Sheng Wu, Takeo Igarashi, and Xiang’Anthony’ Chen. 2025. Proactive conversational agents with inner thoughts. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19
2025
-
[40]
Jason M Lodge, Gregor Kennedy, Lori Lockyer, Amael Arguel, and Mariya Pachman. 2018. Understanding difficulties and resulting confusion in learning: An integrative review. InFrontiers in Education, Vol. 3. Frontiers Media SA, 49
2018
-
[41]
Yue Lyu, Di Liu, Pengcheng An, Xin Tong, Huan Zhang, KEIKO Katsuragawa, and JIAN Zhao. 2024. EMooly: Supporting Autistic Children in Collaborative Social-Emotional Learning with Caregiver Participation through Interactive AI-infused and AR Activities.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.8, 4 (2024), 203–1
2024
-
[42]
Fiona Maine and Beci McCaughran. 2021. Using wordless picturebooks as stimuli for dialogic engagement. InDialogue for intercultural understanding: Placing cultural literacy at the heart of learning. Springer International Publishing Cham, 59–72
2021
-
[43]
Ewa Maslowska, Claire M Segijn, Khadija Ali Vakeel, and Vijay Viswanathan. 2020. How consumers attend to online reviews: an eye-tracking and network analysis approach.International Journal of Advertising39, 2 (2020), 282–306
2020
-
[44]
Joseph E Michaelis and Bilge Mutlu. 2017. Someone to read with: Design of and experiences with an in-home learning companion robot for reading. InProceedings of the 2017 CHI conference on human factors in computing systems. 301–312
2017
-
[45]
Inge Molenaar. 2022. The concept of hybrid human-AI regulation: Exemplifying how to support young learners’ self-regulated learning.Computers and Education: Artificial Intelligence3 (2022), 100070
2022
-
[46]
Inge Molenaar. 2022. Towards hybrid human-AI learning technologies.European Journal of Education57, 4 (2022), 632–645
2022
-
[47]
Behnaz Nojavanasghari, Tadas Baltrusaitis, Charles E Hughes, and Louis-Philippe Morency. 2016. The Future Belongs to the Curious: Towards Automatic Understanding and Recognition of Curiosity in Children.. InWOCCI. 16–22
2016
-
[48]
Ayumi Ohnishi, Sayo Kosaka, Yasukazu Hama, Kaoru Saito, and Tsutomu Terada. 2024. A Curiosity Estimation in Storytelling with Picture Books for Children Using Wearable Sensors.Sensors24, 13 (2024), 4043
2024
-
[49]
Madeline Pelz, Laura Schulz, and Julian Jara-Ettinger. [n. d.]. The signature of all things: Children infer knowledge states from static images. ([n. d.])
-
[50]
David L Rabiner, Jennifer Godwin, and Kenneth A Dodge. 2016. Predicting academic achievement and attainment: The contribution of early academic skills, attention difficulties, and social competence.School Psychology Review45, 2 (2016), 250–267
2016
-
[51]
Jun Rekimoto. 2025. GazeLLM: Multimodal LLMs incorporating human visual attention. InProceedings of the Augmented Humans International Conference 2025. 302–311
2025
-
[52]
The girl who wants to fly
Elisa Rubegni, Rebecca Dore, Monica Landoni, and Ling Kan. 2021. “The girl who wants to fly”: Exploring the role of digital technology in enhancing dialogic reading.International Journal of Child-Computer Interaction30 (2021), 100239
2021
-
[53]
Zeynep Ceren Şimşek and Nesrin Işıkoğlu Erdoğan. 2021. Comparing the effects of different book reading techniques on young children’s language development.Reading and Writing34, 4 (2021), 817–839
2021
-
[54]
Lori E Skibbe, Julie L Thompson, and Joshua B Plavnick. 2018. Preschoolers’ visual attention during electronic storybook reading as related to different types of textual supports.Early Childhood Education Journal46, 4 (2018), 419–426
2018
-
[55]
Seung-Hee Claire Son and Kirsten R Butcher. 2024. Effects of varied multimedia animations in digital storybooks: A randomised controlled trial with preschoolers.Journal of Research in Reading47, 3 (2024), 249–268
2024
-
[56]
Hari Subramonyam, Roy Pea, Christopher Pondoc, Maneesh Agrawala, and Colleen Seifert. 2024. Bridging the Gulf of Envisioning: Cognitive Challenges in Prompt Based Interactions with LLMs. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, Manuscript submitted to ACM 24 Wu et al. HI, USA)(CHI ’24). Association for Compu...
-
[57]
He Sun, Adam Charles Roberts, and Adriana Bus. 2022. Bilingual children’s visual attention while reading digital picture books and story retelling. Journal of Experimental Child Psychology215 (2022), 105327
2022
-
[58]
Shouqian Sun, Zizhen Wang, Jiarong Zhang, Xiaoliang Zhao, and Xianyue Qiao. 2024. StoryChat: An Interactive Storytelling System for Engaging with Agent Characters in a Story. In2024 17th International Symposium on Computational Intelligence and Design (ISCID). IEEE, 213–217
2024
-
[59]
Yuling Sun, Jiaju Chen, Bingsheng Yao, Jiali Liu, Dakuo Wang, Xiaojuan Ma, Yuxuan Lu, Ying Xu, and Liang He. 2024. Exploring Parent’s Needs for Children-Centered AI to Support Preschoolers’ Interactive Storytelling and Reading Activities.Proceedings of the ACM on Human-Computer Interaction8, CSCW2 (2024), 1–25
2024
-
[60]
Ercenur Ünal and Anna Papafragou. 2019. How children identify events from visual experience.Language Learning and Development15, 2 (2019), 138–156
2019
-
[61]
Geoffrey Underwood and Jean DM Underwood. 1998. Children’s interactions and learning outcomes with interactive talking books.Computers & Education30, 1-2 (1998), 95–102
1998
-
[62]
Daniel Vargas-Diaz, Jisun Kim, Sulakna Karunaratna, Caroline Byrd Hornburg, Koeun Choi, and Sang Won Lee. 2025. Exploring parent involvement in e-book joint reading with voice agents.International Journal of Human-Computer Studies198 (2025), 103461
2025
-
[63]
Bin Wang, Armstrong Aboah, Zheyuan Zhang, Hongyi Pan, and Ulas Bagci. 2024. Gazesam: Interactive image segmentation with eye gaze and segment anything model. InGaze Meets Machine Learning Workshop. PMLR, 254–265
2024
-
[64]
Lin Wang, Hana Lee, and Da Young Ju. 2019. Impact of digital content on young children’s reading interest and concentration for books.Behaviour & information technology38, 1 (2019), 1–8
2019
-
[65]
Zhenlin Wang and Yihan Shao. 2025. Picture book reading improves children’s learning understanding.British Journal of Developmental Psychology 43, 1 (2025), 12–35
2025
-
[66]
Zeyu Wang, Yuanchun Shi, Yuntao Wang, Yuchen Yao, Kun Yan, Yuhan Wang, Lei Ji, Xuhai Xu, and Chun Yu. 2024. G-VOILA: gaze-facilitated information querying in daily scenarios.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 2 (2024), 1–33
2024
-
[67]
2013.The power of pictures: The role of picturebooks in the development of young learners
Elaine Weeks. 2013.The power of pictures: The role of picturebooks in the development of young learners. Ph. D. Dissertation. University of Florida
2013
-
[68]
Yang Wu and Laura E Schulz. 2020. Understanding social display rules: Using one person’s emotional expressions to infer the desires of another. Child development91, 5 (2020), 1786–1799
2020
-
[69]
Yang Wu, Jinhong Yu, Jingwei Xiong, Zhimin Tao, and Xiaozhong Liu. 2026. " Excuse me, may I say something... " CoLabScience, A Proactive AI Assistant for Biomedical Discovery and LLM-Expert Collaborations.arXiv preprint arXiv:2604.15588(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
Lei Xing, Yi Tang, Qingke Liu, Haifeng Chen, Jiamin Zeng, and Junyue Su. 2025. The effects of interactive reading on young children’s narrative abilities: a meta-analytic study.Frontiers in Psychology16 (2025), 1653511
2025
-
[71]
Bufang Yang, Yunqi Guo, Lilin Xu, Zhenyu Yan, Hongkai Chen, Guoliang Xing, and Xiaofan Jiang. 2025. Socialmind: Llm-based proactive ar social assistive system with human-like perception for in-situ live interactions.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 1 (2025), 1–30
2025
-
[72]
Lyumanshan Ye, Jiandong Jiang, Danni Chang, and Pengfei Liu. 2024. Storypark: Leveraging large langNeed Help? Designing Proactive AI Assistants for Programminguage models to enhance children story learning through child-ai collaboration storytelling.arXiv preprint arXiv:2405.06495(2024)
-
[73]
Jeffrey M Zacks. 2020. Event perception and memory.Annual review of psychology71, 1 (2020), 165–191
2020
-
[74]
Chao Zhang, Cheng Yao, Jiayi Wu, Weijia Lin, Lijuan Liu, Ge Yan, and Fangtian Ying. 2022. StoryDrawer: a child–AI collaborative drawing system to support children’s creative visual storytelling. InProceedings of the 2022 CHI conference on human factors in computing systems. 1–15
2022
-
[75]
Zheng Zhang, Ying Xu, Yanhao Wang, Bingsheng Yao, Daniel Ritchie, Tongshuang Wu, Mo Yu, Dakuo Wang, and Toby Jia-Jun Li. 2022. Storybuddy: A human-ai collaborative chatbot for parent-child interactive storytelling with flexible parental involvement. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–21
2022
-
[76]
Yuheng Zhao, Xueli Shu, Liwen Fan, Lin Gao, Yu Zhang, and Siming Chen. 2025. ProactiveVA: Proactive Visual Analytics with LLM-Based UI Agent. arXiv preprint arXiv:2507.18165(2025). Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.