Towards Better Linux Kernel Fault Localization: Leveraging Contrastive Reasoning and Hierarchical Context Analysis
Pith reviewed 2026-07-02 08:52 UTC · model grok-4.3
The pith
CoHiKer improves Linux kernel fault localization by analyzing behavioral differences in mutated tests and narrowing code scope hierarchically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
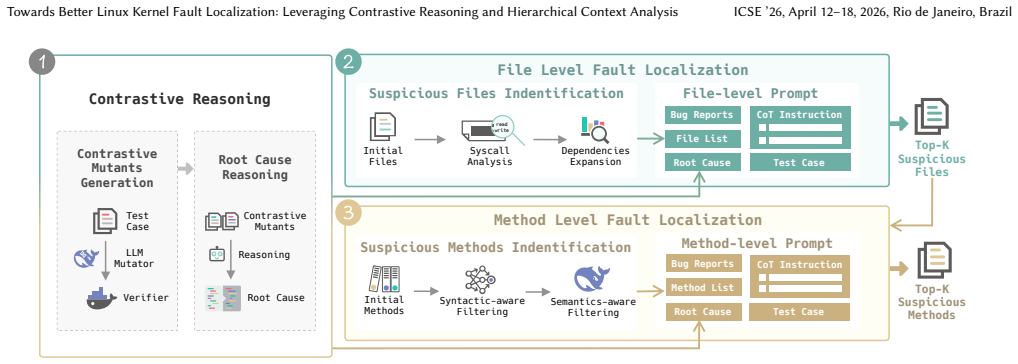
CoHiKer is a novel LLM-based fault localization technique tailored to the Linux kernel. It introduces contrastive reasoning, which identifies root causes by analyzing the behavioral divergence between carefully mutated passing and failing test cases, and hierarchical context analysis, which systematically narrows the localization scope from files to methods by integrating crash reports, syscall semantics, inter-file dependencies, and kernel-specific features. Unlike prior techniques that rely on static understanding and full-code input, CoHiKer decomposes the localization task and enables structured LLM prompting to reason semantically over meaningful contexts. Evaluation on an extended Linu
What carries the argument
contrastive reasoning that identifies root causes from behavioral divergence between mutated passing and failing test cases, paired with hierarchical context analysis that narrows scope from files to methods using crash reports, syscall semantics, inter-file dependencies, and kernel features
If this is right
- Higher Top-1 accuracy at both file and method levels reduces the manual effort needed to inspect candidate locations during kernel debugging.
- Lower token consumption allows the approach to scale to larger kernel modules without exceeding LLM context limits.
- The same two innovations transfer to non-kernel codebases and deliver measurable accuracy gains there as well.
- Decomposing the task into contrastive and hierarchical stages enables more structured prompting that improves semantic reasoning over raw code dumps.
Where Pith is reading between the lines
- If contrastive reasoning on test mutations succeeds, the same pattern could be tested on other large, low-level systems such as device drivers or embedded firmware where test cases are available.
- Hierarchical narrowing might serve as a general guard against context overload in any LLM code task by forcing the model to process only relevant slices at each step.
- The reported gains on a non-kernel dataset suggest the method could be adapted to user-space applications that share similar crash-report structures.
Load-bearing premise
Carefully mutated passing and failing test cases reliably highlight the exact behavioral divergence caused by the root cause without the mutations adding unrelated changes or missing the bug.
What would settle it
A new evaluation set of kernel bugs where the mutated test pairs produce no clear behavioral signal tied to the actual root cause, yet CoHiKer still claims superior accuracy, would falsify the central mechanism.
Figures






read the original abstract
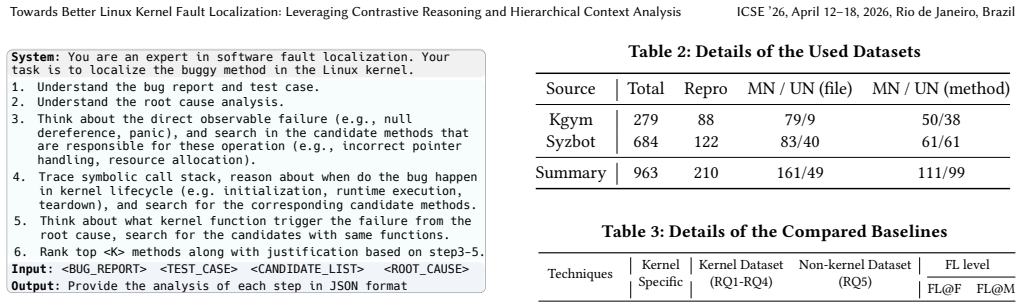
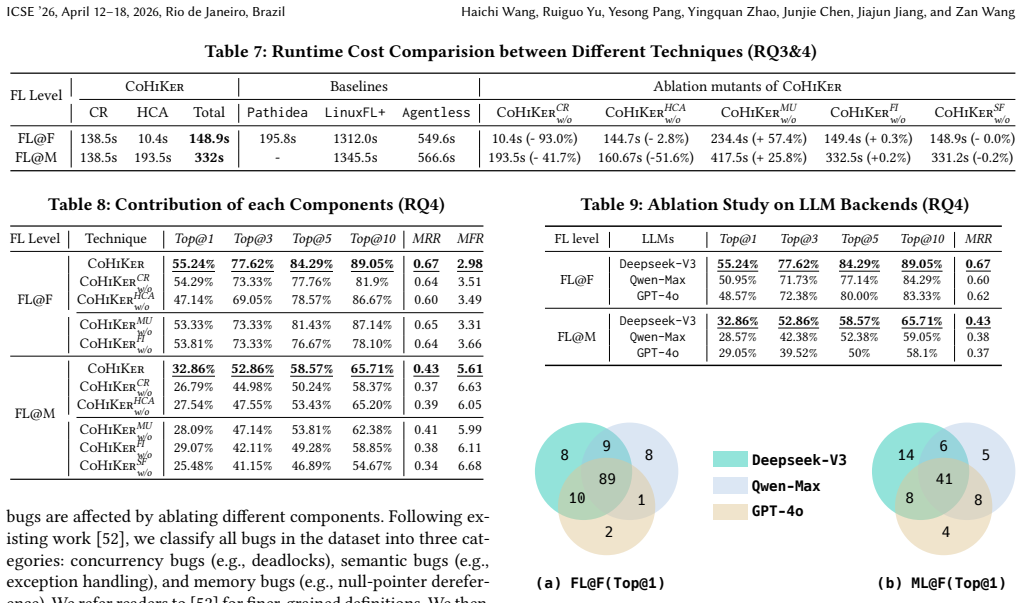
Debugging the Linux kernel remains a formidable challenge due to its vast codebase, complex architecture, and low-level programming intricacies. Effective fault localization (FL) is thus essential for efficient kernel debugging and maintenance. While existing FL techniques (both traditional and LLM-based) have shown promise in general-purpose software, they are ill-suited for the kernel context. In particular, recent LLM-based techniques often treat bug reports and source code as plain text, lacking deep integration of kernel-specific knowledge, which limits their ability to identify root causes and achieve fine-grained localization. We present CoHiKer, a novel LLM-based FL technique tailored to the Linux kernel. CoHiKer introduces two key innovations: (1) contrastive reasoning, which identifies root causes by analyzing the behavioral divergence between carefully mutated passing and failing test cases, and (2) hierarchical context analysis, which systematically narrows the localization scope from files to methods by integrating crash reports, syscall semantics, inter-file dependencies, and kernel-specific features. Unlike prior techniques that rely on static understanding and full-code input, CoHiKer decomposes the localization task and enables structured LLM prompting to reason semantically over meaningful contexts. We evaluate CoHiKer on an extended Linux kernel bug dataset against five state-of-the-art baselines. CoHiKer consistently outperforms all competitors, improving Top-1 localization accuracy by up to 26.07% at the file level and 56.85% at the method level over state-of-the-art LLM-based baselines, while achieving up to 8.84% and 28.9% reductions in token consumption, respectively. Furthermore, CoHiKer demonstrates strong generalizability on the non-kernel dataset, with comparable gains (15.5% and 5.3% in Top-1 at file and method levels).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoHiKer, an LLM-based fault localization technique for the Linux kernel. It introduces contrastive reasoning to identify root causes via behavioral divergence between mutated passing and failing test cases, and hierarchical context analysis to narrow scope from files to methods using crash reports, syscall semantics, inter-file dependencies, and kernel features. Evaluated on an extended Linux kernel bug dataset against five SOTA baselines, it claims consistent outperformance with Top-1 accuracy gains of up to 26.07% (file level) and 56.85% (method level), plus token consumption reductions of up to 8.84% and 28.9%, respectively, along with some generalizability to non-kernel data.
Significance. If the results hold under rigorous validation, this would constitute a practical advance in applying LLMs to fault localization in large, low-level systems like the Linux kernel by decomposing the task with domain-specific structure rather than treating inputs as plain text. The reported accuracy and efficiency gains could inform future LLM-assisted debugging work in systems software if the evaluation details are supplied.
major comments (2)
- [Abstract and §3] Abstract and §3: The contrastive reasoning premise assumes that mutations of passing and failing test cases reliably isolate only the root-cause behavioral divergence without injecting extraneous changes or omitting the fault. The manuscript provides no explicit validation of this isolation (e.g., differential execution traces, mutation-impact metrics, or manual inspection results) on the Linux kernel dataset. This is load-bearing for the central claim because the reported Top-1 improvements (26.07% file-level, 56.85% method-level) are directly attributed to this mechanism.
- [Evaluation section] Evaluation section: The abstract and claims report quantitative improvements, but the manuscript lacks details on dataset construction, baseline implementations, statistical significance testing, and error bars. These omissions prevent assessment of whether the data supports the stated gains in localization accuracy and token reductions.
minor comments (1)
- [Abstract] Abstract: The phrase 'an extended Linux kernel bug dataset' should include a brief description of the original source and the nature of the extension to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and committing to revisions where appropriate to enhance the paper's rigor and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The contrastive reasoning premise assumes that mutations of passing and failing test cases reliably isolate only the root-cause behavioral divergence without injecting extraneous changes or omitting the fault. The manuscript provides no explicit validation of this isolation (e.g., differential execution traces, mutation-impact metrics, or manual inspection results) on the Linux kernel dataset. This is load-bearing for the central claim because the reported Top-1 improvements (26.07% file-level, 56.85% method-level) are directly attributed to this mechanism.
Authors: We appreciate the referee's emphasis on validating the core assumption of contrastive reasoning. Our mutation strategy is guided by kernel-specific information from crash reports and syscall semantics to target relevant behavioral changes, aiming to avoid extraneous modifications. Nevertheless, we recognize that the original submission did not include explicit empirical validation of this isolation property. In the revised version, we will add a new analysis subsection under §3 that includes mutation-impact metrics (e.g., percentage of changed statements) and manual inspection results on a sample of 30 bugs from the dataset. This will provide direct evidence supporting the mechanism's effectiveness and better justify the reported accuracy gains. revision: yes
-
Referee: [Evaluation section] Evaluation section: The abstract and claims report quantitative improvements, but the manuscript lacks details on dataset construction, baseline implementations, statistical significance testing, and error bars. These omissions prevent assessment of whether the data supports the stated gains in localization accuracy and token reductions.
Authors: We agree that these details are essential for a thorough evaluation of the results. The manuscript was condensed for space, leading to these omissions. We will substantially expand the Evaluation section to include: a complete account of the dataset construction process and its extension from prior work; detailed descriptions of baseline implementations and any kernel-specific adaptations; application of statistical significance tests (e.g., paired t-tests or Wilcoxon tests) with p-values; and error bars or confidence intervals on all reported metrics including Top-1 accuracies and token consumptions. These additions will allow readers to better assess the reliability of the improvements. revision: yes
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper describes an empirical LLM-based fault localization technique (CoHiKer) evaluated via experiments on Linux kernel and non-kernel bug datasets against baselines. No mathematical derivations, equations, parameter fitting, or first-principles claims appear in the provided text. Claims of performance gains (e.g., Top-1 accuracy improvements) rest on reported experimental results rather than any reduction to inputs by construction. No self-citations or ansatzes are invoked as load-bearing premises. This matches the default case of a non-circular empirical SE paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stackscale. 2024. Linux Kernel Surpasses 40 Million Lines of Code. https://www. stackscale.com/blog/linux-kernel-surpasses-40-million-lines-code. Accessed: 2025-07-18
2024
-
[2]
Hao Sun, Yuheng Shen, Cong Wang, Jianzhong Liu, Yu Jiang, Ting Chen, and Aiguo Cui. 2021. Healer: Relation learning guided kernel fuzzing. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 344–358
2021
-
[3]
Bodong Zhao, Zheming Li, Shisong Qin, Zheyu Ma, Ming Yuan, Wenyu Zhu, Zhihong Tian, and Chao Zhang. 2022. {StateFuzz}: System {Call-Based} {State- Aware} linux driver fuzzing. In31st USENIX Security Symposium (USENIX Security 22). 3273–3289
2022
-
[4]
Chenyuan Yang, Zijie Zhao, and Lingming Zhang. 2025. Kernelgpt: Enhanced kernel fuzzing via large language models. InProceedings of the 30th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 560–573
2025
-
[5]
Haichi Wang, Ruiguo Yu, Dong Wang, Yiheng Du, Yingquan Zhao, Junjie Chen, and Zan Wang. 2025. An empirical study of test case prioritization on the Linux Kernel.Automated Software Engineering32, 2 (2025), 49
2025
-
[6]
Donaldson, and Cristian Cadar
Karine Even-Mendoza, Arindam Sharma, Alastair F. Donaldson, and Cristian Cadar. 2023. GrayC: Greybox Fuzzing of Compilers and Analysers for C. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, W A, USA, July 17-21, 2023, René Just and Gordon Fraser (Eds.). ACM, 1219–1231
2023
-
[7]
W Eric Wong, Ruizhi Gao, Yihao Li, Rui Abreu, and Franz Wotawa. 2016. A survey on software fault localization.IEEE Transactions on Software Engineering 42, 8 (2016), 707–740
2016
-
[8]
Daming Zou, Jingjing Liang, Yingfei Xiong, Michael D Ernst, and Lu Zhang. 2019. An empirical study of fault localization families and their combinations.IEEE Transactions on Software Engineering47, 2 (2019), 332–347
2019
-
[9]
Ming Wen, Junjie Chen, Yongqiang Tian, Rongxin Wu, Dan Hao, Shi Han, and Shing-Chi Cheung. 2019. Historical spectrum based fault localization.IEEE Transactions on Software Engineering47, 11 (2019), 2348–2368
2019
-
[10]
Yue Jia and Mark Harman. 2010. An analysis and survey of the development of mutation testing.IEEE transactions on software engineering37, 5 (2010), 649–678
2010
-
[11]
James H Andrews, Lionel C Briand, Yvan Labiche, and Akbar Siami Namin. 2006. Using mutation analysis for assessing and comparing testing coverage criteria. IEEE Transactions on Software Engineering32, 8 (2006), 608–624
2006
-
[12]
Xin Xia and David Lo. 2023. Information Retrieval-Based Techniques for Software Fault Localization.Handbook of Software Fault Localization: Foundations and Advances(2023), 365–391
2023
-
[13]
Wen Zhang, Ziqiang Li, Qing Wang, and Juan Li. 2019. FineLocator: A novel approach to method-level fine-grained bug localization by query expansion. Information and Software Technology110 (2019), 121–135
2019
-
[14]
An Ran Chen, Tse-Hsun Chen, and Shaowei Wang. 2021. Pathidea: Improving information retrieval-based bug localization by re-constructing execution paths using logs.IEEE Transactions on Software Engineering48, 8 (2021), 2905–2919
2021
-
[15]
Sanan Hasanov, Stefan Nagy, and Paul Gazzillo. 2024. A Little Goes a Long Way: Tuning Configuration Selection for Continuous Kernel Fuzzing. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 521–533
2024
-
[16]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
- [17]
-
[18]
Zhang, H
Y. Zhang, H. Ruan, Z. Fan, and A. Roychoudhury. 2024. Autocoderover: Au- tonomous program improvement. InProceedings of the 33rd ACM SIGSOFT Inter- national Symposium on Software Testing and Analysis (ISSTA 2024), M. Christakis and M. Pradel (Eds.). ACM, Vienna, Austria, 1592–1604
2024
-
[19]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Zhenhao Zhou, Zhuochen Huang, Yike He, Chong Wang, Jiajun Wang, Yijian Wu, Xin Peng, and Yiling Lou. 2025. Benchmarking and Enhancing LLM Agents in Localizing Linux Kernel Bugs.arXiv preprint arXiv:2505.19489(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Aidan ZH Yang, Claire Le Goues, Ruben Martins, and Vincent Hellendoorn. 2024. Large language models for test-free fault localization. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
2024
-
[23]
Alex Mathai, Chenxi Huang, Petros Maniatis, Aleksandr Nogikh, Franjo Ivančić, Junfeng Yang, and Baishakhi Ray. 2024. Kgym: A platform and dataset to bench- mark large language models on linux kernel crash resolution.Advances in Neural Information Processing Systems37 (2024), 78053–78078
2024
-
[24]
Rongxin Wu, Hongyu Zhang, Shing-Chi Cheung, and Sunghun Kim. 2014. Crashlocator: Locating crashing faults based on crash stacks. InProceedings of the 2014 International Symposium on Software Testing and Analysis. 204–214
2014
-
[25]
Yihao Qin, Shangwen Wang, Yiling Lou, Jinhao Dong, Kaixin Wang, Xiaoling Li, and Xiaoguang Mao. 2025. SoapFL: A Standard Operating Procedure for LLM- based Method-Level Fault Localization.IEEE Transactions on Software Engineering (2025)
2025
-
[26]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
2024
-
[27]
Syzbot. 2025. Kernel Crash: WARNING in 𝑢𝑛𝑚𝑎𝑝_𝑝𝑎𝑔𝑒_𝑟𝑎𝑛𝑔𝑒 . https:// syzkaller.appspot.com/bug?extid=7ca4b2719dc742b8d0a4. Accessed: 2025-07-18
2025
-
[28]
DeepSeek. 2025. DeepSeek-v3
2025
-
[29]
Zan Wang, Ming Yan, Junjie Chen, Shuang Liu, and Dongdi Zhang. 2020. Deep learning library testing via effective model generation. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 788–799
2020
-
[30]
Yingquan Zhao, Zan Wang, Junjie Chen, Mengdi Liu, Mingyuan Wu, Yuqun Zhang, and Lingming Zhang. 2022. History-driven test program synthesis for JVM testing. InProceedings of the 44th International Conference on Software Engineering. 1133–1144
2022
-
[31]
Arghavan Moradi Dakhel, Amin Nikanjam, Vahid Majdinasab, Foutse Khomh, and Michel C Desmarais. 2024. Effective test generation using pre-trained large language models and mutation testing.Information and Software Technology171 (2024), 107468
2024
-
[32]
Reinhard Tartler, Christian Dietrich, Julio Sincero, Wolfgang Schröder-Preikschat, and Daniel Lohmann. 2014. Static analysis of variability in system software: The 90,000# ifdefs issue. In2014 USENIX Annual Technical Conference (USENIX ATC 14). 421–432
2014
-
[33]
Nachiappan Nagappan, Thomas Ball, and Andreas Zeller. 2006. Mining metrics to predict component failures. InProceedings of the 28th International Conference on Software Engineering. 452–461
2006
-
[34]
1977.Elements of Software Science (Operating and program- ming systems series)
Maurice H Halstead. 1977.Elements of Software Science (Operating and program- ming systems series). Elsevier Science Inc
1977
-
[35]
Frank Rosenblatt. 1958. The perceptron: a probabilistic model for information storage and organization in the brain.Psychological review65, 6 (1958), 386
1958
-
[36]
Tong Sun, Yao Shao, Xiaoxiao Li, Liang Zhang, Yabo Yang, and Jie Zhou. 2020. Learning Sparse Sharing Architectures for Multiple Tasks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8936–8943
2020
-
[37]
Jeongju Sohn and Shin Yoo. 2017. Fluccs: Using code and change metrics to improve fault localization. InProceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. 273–283
2017
-
[38]
Ritu Kapur and Balwinder Sodhi. 2018. Estimating defectiveness of source code: A predictive model using github content.arXiv preprint arXiv:1803.07764(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Luca Pascarella, Fabio Palomba, and Alberto Bacchelli. 2019. Fine-grained just- in-time defect prediction.Journal of Systems and Software150 (2019), 22–36
2019
-
[40]
Mijung Kim, Jaechang Nam, Jongwook Yeon, and Sunghun Kim. 2015. REMI: Defect prediction for efficient API testing. (2015), 990–993
2015
-
[41]
2025. Syzbot. https://syzkaller.appspot.com
2025
-
[42]
Sungmin Kang, Gabin An, and Shin Yoo. 2024. A quantitative and qualitative evaluation of LLM-based explainable fault localization.Proceedings of the ACM on Software Engineering1, FSE (2024), 1424–1446
2024
-
[43]
Ellen M Voorhees et al. 1999. The trec-8 question answering track report.. In Trec, Vol. 99. 77–82
1999
-
[44]
Xia Li, Wei Li, Yuqun Zhang, and Lingming Zhang. 2019. DeepFL: Integrating Multiple Fault Diagnosis Dimensions for Deep Fault Localization. (2019), 169– 180
2019
-
[45]
Y. Li, S. Wang, and T. Nguyen. 2021. Fault localization with code coverage representation learning. (2021), 661–673
2021
-
[46]
Chris Parnin and Alessandro Orso. 2011. Are automated debugging techniques actually helping programmers?. InProceedings of the 2011 international symposium on software testing and analysis. 199–209
2011
-
[47]
Junjie Chen, Jiaqi Han, Peiyi Sun, Lingming Zhang, Dan Hao, and Lu Zhang
-
[48]
In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering
Compiler bug isolation via effective witness test program generation. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 223–234
2019
-
[49]
anonymity. 2025. Public repository for CoHIKer. https://doi.org/10.5281/zenodo. 17569818
-
[50]
Janez Demšar. 2006. Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research7 (2006), 1–30
2006
-
[51]
Google. 2015. syzkaller: an unsupervised coverage-guided kernel fuzzer. https: //github.com/google/syzkaller. Accessed: 2025-11-09
2015
-
[52]
Gerard Salton and Christopher Buckley. 1988. Term-weighting approaches in automatic text retrieval.Information processing & management24, 5 (1988), 513–523
1988
-
[53]
Lin Tan, Chen Liu, Zhenmin Li, Xuanhui Wang, Yuanyuan Zhou, and Chengxiang Zhai. 2014. Bug characteristics in open source software.Empirical software Towards Better Linux Kernel Fault Localization: Leveraging Contrastive Reasoning and Hierarchical Context Analysis ICSE ’26, April 12–18, 2026, Rio de Janeiro, Brazil engineering19, 6 (2014), 1665–1705
2014
-
[54]
OpenAI. 2024. Hello GPT-4o
2024
-
[55]
qwenlm. 2024. Qwen-Max
2024
-
[56]
Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2007. On the accuracy of spectrum-based fault localization. InTesting: Academic and industrial conference practice and research techniques-MUTATION (TAICPART-MUTATION 2007). IEEE, 89–98
2007
-
[57]
W Eric Wong, Vidroha Debroy, Ruizhi Gao, and Yihao Li. 2013. The DStar method for effective software fault localization.IEEE Transactions on Reliability63, 1 (2013), 290–308
2013
-
[58]
James A Jones and Mary Jean Harrold. 2005. Empirical evaluation of the taran- tula automatic fault-localization technique. InProceedings of the 20th IEEE/ACM international Conference on Automated software engineering. 273–282
2005
-
[59]
Seokhyeon Moon, Yunho Kim, Moonzoo Kim, and Shin Yoo. 2014. Ask the mutants: Mutating faulty programs for fault localization. In2014 IEEE Seventh International Conference on Software Testing, Verification and Validation. IEEE, 153–162
2014
-
[60]
Mike Papadakis and Yves Le Traon. 2015. Metallaxis-FL: mutation-based fault localization.Software Testing, Verification and Reliability25, 5-7 (2015), 605–628
2015
-
[61]
Tegawendé F Bissyandé, Laurent Réveillère, Julia L Lawall, and Gilles Muller. 2012. Diagnosys: automatic generation of a debugging interface to the linux kernel. In Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. 60–69
2012
-
[62]
Abdul Razzaq, Jim Buckley, James Vincent Patten, Muslim Chochlov, and Ashish Rajendra Sai. 2021. BoostNSift: A query boosting and code sifting tech- nique for method level bug localization. In2021 IEEE 21st International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 81–91
2021
- [63]
-
[64]
Chuyang Xu, Zhongxin Liu, Xiaoxue Ren, Gehao Zhang, Ming Liang, and David Lo. 2025. Flexfl: Flexible and effective fault localization with open-source large language models.IEEE Transactions on Software Engineering(2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.