Learning-based control of a single-DOF Aero system
Pith reviewed 2026-07-02 07:40 UTC · model grok-4.3
The pith
A Lyapunov-derived feedback linearization controller augmented with REINFORCE-with-baseline RL for online disturbance compensation, demonstrated in simulation on a single-DOF Aero system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
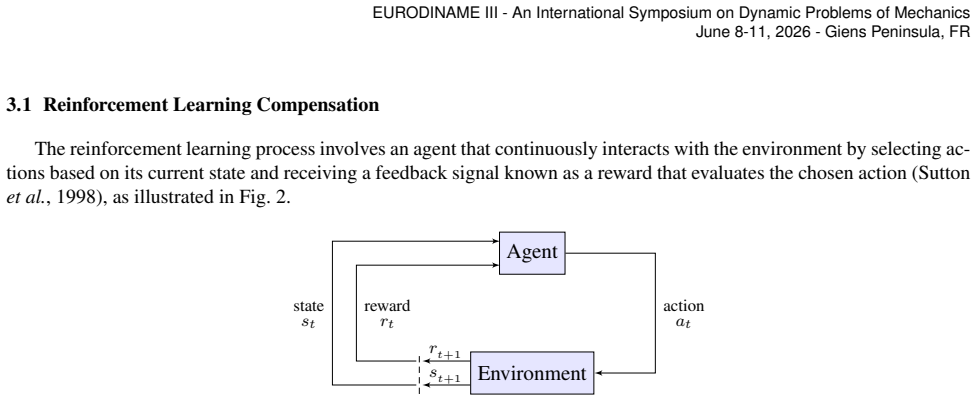
The control law is derived using Lyapunov stability analysis, ensuring closed-loop stability in the presence of modeling uncertainties and external disturbances.
Load-bearing premise
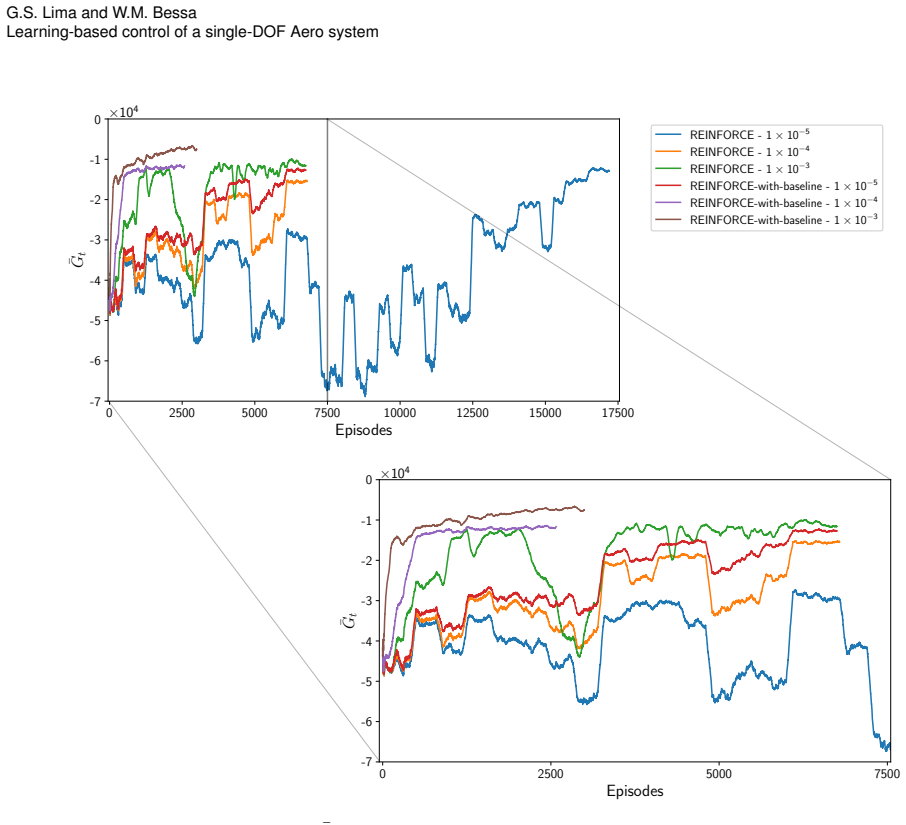
The REINFORCE-with-baseline learning module can estimate and compensate for unmodeled dynamics and disturbances online without violating the closed-loop stability guarantees provided by the Lyapunov analysis.
Figures


read the original abstract
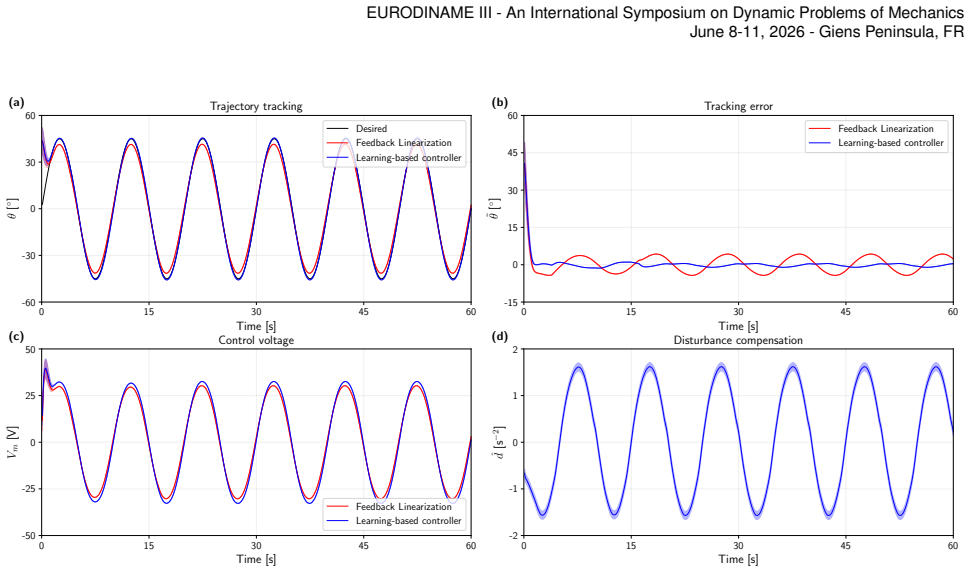
This paper presents a learning-based control framework that integrates feedback linearization with reinforcement learning for the adaptive control of nonlinear mechatronic systems. The control law is derived using Lyapunov stability analysis, ensuring closed-loop stability in the presence of modeling uncertainties and external disturbances. Feedback linearization serves as the main control framework, while a reinforcement learning component estimates and compensates for unmodeled dynamics and disturbances online. The learning module is based on the REINFORCE-with-baseline algorithm, which improves learning efficiency by reducing the variance of policy-gradient estimates and enabling stable policy updates during adaptation. The proposed controller is evaluated on a single-degree-of-freedom rotor-based AERO system. Results from simulations demonstrate accurate trajectory tracking, fast adaptation, and strong robustness against parameter variations and external disturbances. Overall, the proposed approach combines the analytical guarantees of Lyapunov-based control with the adaptability of reinforcement learning, providing an effective solution for controlling nonlinear mechatronic systems.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: Lyapunov derivation and RL adaptation remain independent
full rationale
The paper presents a standard Lyapunov-based feedback linearization controller augmented by a REINFORCE-with-baseline learning module for disturbance compensation. No equations or sections reduce the stability claim or adaptation performance to a fitted parameter renamed as prediction, a self-citation chain, or a self-definitional loop. The central guarantees rest on explicit Lyapunov analysis and the stated properties of the policy-gradient algorithm, both of which are external to the fitted values of the present work. This is the normal non-circular outcome for a control-design manuscript.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1991 , publisher=
Applied nonlinear control , author=. 1991 , publisher=
1991
-
[2]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[3]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[4]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[5]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International Journal of Automation and Computing , volume=
Some remarks on the boundedness and convergence properties of smooth sliding mode controllers , author=. International Journal of Automation and Computing , volume=. 2009 , publisher=
2009
-
[7]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[8]
Journal of Low Frequency Noise, Vibration and Active Control , pages=
Development and implementation of an advanced robust control strategy for quarter-car active suspension systems , author=. Journal of Low Frequency Noise, Vibration and Active Control , pages=. 2025 , publisher=
2025
-
[9]
Journal of the Brazilian Society of Mechanical Sciences and Engineering , volume=
Accurate trajectory tracking control with adaptive neural networks for omnidirectional mobile robots subject to unmodeled dynamics , author=. Journal of the Brazilian Society of Mechanical Sciences and Engineering , volume=. 2023 , publisher=
2023
-
[10]
International Journal of Dynamics and Control , volume=
Robust control of a magnetic levitation system via LESO-based feedback linearization tuned by modified flood algorithm , author=. International Journal of Dynamics and Control , volume=. 2026 , publisher=
2026
-
[11]
Scientific Reports , volume=
Adaptive sliding mode control for chaotic system synchronization using neural networks , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[12]
Advances in neural information processing systems , volume=
Safe model-based reinforcement learning with stability guarantees , author=. Advances in neural information processing systems , volume=
-
[13]
Neurocomputing , pages=
Reinforcement learning-based prescribed performance control for aircraft carrier landing using direct side force , author=. Neurocomputing , pages=. 2025 , publisher=
2025
-
[14]
Advances in neural information processing systems , volume=
A lyapunov-based approach to safe reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[15]
IEEE Transactions on Industrial Electronics , volume=
Model-based safe reinforcement learning with time-varying constraints: Applications to intelligent vehicles , author=. IEEE Transactions on Industrial Electronics , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.