CADENZA in Action: Breaking the Monolith with Intent-Dependent Plan Spaces for Semantic Queries
Pith reviewed 2026-07-03 01:07 UTC · model grok-4.3
The pith
CADENZA breaks monolithic semantic operators by compiling intents into decomposed steps and selecting tuned physical implementations under quality-latency-cost preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
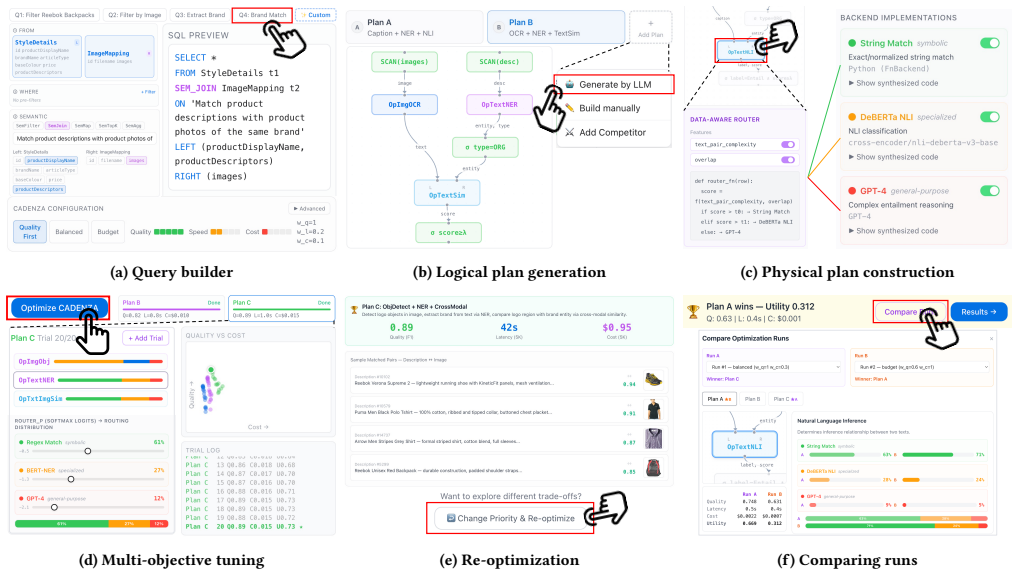
CADENZA compiles an intent into decomposed steps, selects concrete physical implementations for each step, and tunes their parameters under user-specified quality-latency-cost preferences.
What carries the argument
Intent-dependent plan spaces that represent alternative decompositions of a semantic intent along with selectable physical implementations for each step.
If this is right
- Users can supply explicit quality-latency-cost preferences and receive a different winning plan for each setting.
- Optimization occurs at the granularity of individual steps instead of entire models, allowing cheaper implementations where semantics permit.
- The web interface exposes how an intent is broken down and how each plan is scored and chosen.
- Alternative plans are generated from the same intent so the system can compare them directly under the given preferences.
Where Pith is reading between the lines
- The same decomposition approach could be tested on non-multimodal data to check whether the plan-space benefit generalizes beyond images and text together.
- If decomposition overhead stays low, the method might be combined with traditional relational optimizers for mixed semantic and structured queries.
- Repeated use on similar intents could allow caching of high-performing plan templates to reduce compilation time on later runs.
Load-bearing premise
Decomposing an intent into steps must produce plans whose quality, latency, and cost can be estimated and compared without the decomposition itself creating semantic errors or excessive overhead.
What would settle it
Run the same intent through CADENZA and a monolithic baseline on a fixed multimodal dataset and measure whether any selected plan meets the stated quality target while using less latency or cost than the monolithic version.
Figures


read the original abstract
Semantic query processing engines execute semantic operators, whose behavior is specified by natural-language intents, via model inference over multimodal data. Most existing optimizers optimize the operators at the granularity of monolithic implementations -- such as LLMs and embedding models -- forcing a trade-off between expensive model calls and cheaper alternatives that fail to capture intent-dependent semantics. We present CADENZA, a semantic operator optimizer that compiles an intent into decomposed steps, selects concrete physical implementations for each step, and tunes their parameters under user-specified quality-latency-cost preferences. In this demonstration, users interact with CADENZA through a web interface over multimodal databases, exploring how an intent is decomposed into alternative plans, how each plan is optimized, and how different preferences yield different winning plans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present CADENZA, a semantic operator optimizer for semantic query processing engines that execute semantic operators specified by natural-language intents. CADENZA compiles an intent into decomposed steps, selects concrete physical implementations for each step, and tunes their parameters under user-specified quality-latency-cost preferences. The demonstration allows interaction via a web interface to explore how intents are decomposed into alternative plans, how plans are optimized, and how preferences affect winning plans over multimodal databases.
Significance. Should the system function as described, CADENZA would offer a meaningful contribution to the field by moving beyond monolithic optimizations for semantic operators, potentially allowing better trade-offs between quality, latency, and cost in multimodal database queries. The working demonstration through a web interface provides a concrete way to illustrate these concepts, which is a strength of the manuscript.
major comments (1)
- Abstract: the description of the compilation and selection process assumes that intent decomposition produces alternative plans whose quality, latency, and cost can be meaningfully estimated and compared without the decomposition itself introducing semantic errors or prohibitive overhead, but the manuscript supplies no discussion, algorithm details, or evidence addressing this assumption, which is load-bearing for the central claim of effective intent-dependent plan spaces.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive assessment of CADENZA's potential contribution. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: the description of the compilation and selection process assumes that intent decomposition produces alternative plans whose quality, latency, and cost can be meaningfully estimated and compared without the decomposition itself introducing semantic errors or prohibitive overhead, but the manuscript supplies no discussion, algorithm details, or evidence addressing this assumption, which is load-bearing for the central claim of effective intent-dependent plan spaces.
Authors: We agree that the manuscript, which is structured as a demonstration paper, does not supply the requested discussion, algorithm details, or evidence on semantic fidelity or overhead during intent decomposition. This is a substantive gap for the central claim. In the revised manuscript we will add a concise subsection (approximately one page) under System Design that outlines the decomposition procedure, the validation steps used to detect semantic drift, and the pruning heuristics that bound overhead; we will illustrate these with concrete examples drawn from the web-interface scenarios already shown in the demonstration. revision: yes
Circularity Check
No derivation chain present; system description only
full rationale
The paper is a system demonstration of CADENZA. It describes intent compilation into decomposed steps, physical operator selection, and preference-based tuning, but contains no equations, formal derivations, fitted parameters, predictions, or mathematical claims. The reader's assessment correctly notes the absence of any quantities that could reduce to self-referential definitions or self-citations. No load-bearing steps exist that could be evaluated for circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. DeBERTa: Decoding-Enhanced BERT with Disentangled Attention. InInternational Confer- ence on Learning Representations. https://openreview.net/forum?id=XPZIaotutsD
2021
- [2]
-
[3]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[4]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
2025
-
[5]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS. Proceedings of the VLDB Endowment18, 11 (2025), 4171–4184
2025
-
[6]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[7]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[8]
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2016. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition. 779–788
2016
- [9]
- [10]
-
[11]
Jiayi Wang and Jianhua Feng. 2025. Unify: An unstructured data analytics system. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE Computer Society, 4662–4674
2025
-
[12]
Jiayi Wang and Guoliang Li. 2025. Aop: Automated and interactive llm pipeline orchestration for answering complex queries. InProceedings of the Conference on Innovative Database Research (CIDR)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.