A Single Patch Is Not Enough: Deterministic Fusion of Repair Candidates
Pith reviewed 2026-07-03 09:17 UTC · model grok-4.3
The pith
Fusing repeated edit atoms across multiple candidate patches constructs correct repairs that no individual candidate achieves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
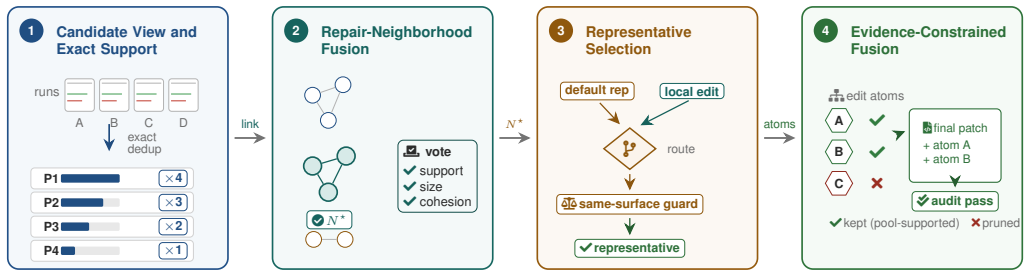
PatchFusion fuses whole-diff agreement into a repair neighborhood, selects an auditable representative, and applies evidence-constrained fusion (ECF) to retain repeated edit atoms while pruning unsupported parts, solving 426 out of 500 bugs on SWE-bench Verified, 236 out of 300 on SWE-bench Multilingual, and 87 out of 371 plausible patches on Defects4J while recovering 41 and 27 bugs that no single source solves.
What carries the argument
Evidence-constrained fusion (ECF), which retains only the edit atoms that appear repeatedly across candidates and removes any parts lacking such cross-candidate support.
Load-bearing premise
Repeated edit atoms across candidates reliably mark the correct repair components that can be safely fused without test outcomes or other external validation.
What would settle it
A controlled run on the same fixed candidate pools where fusing the repeated atoms produces a failing patch on a bug that at least one original candidate would have passed.
Figures


read the original abstract
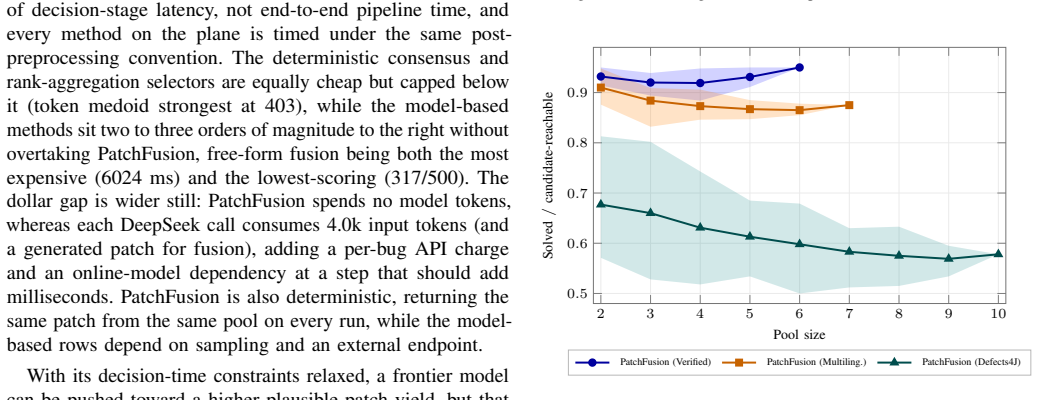
Modern LLM coding agents are commonly evaluated using pass@k, but developers typically apply a single final patch in real-world settings. This pass@k-to-pass@1 gap is a post-generation problem: a candidate patch pool may contain a correct patch, but the system must decide which one to suggest to developers. Existing post-generation approaches mainly rank whole candidates, filter them with tests, or query an LLM judge, but none deterministically reuse shared edit-atom evidence to both select and construct the final patch. Thus, we propose PatchFusion, a deterministic atomic evidence fusion approach for candidate patches that consults no test outcome at decision time. PatchFusion first fuses whole-diff agreement into a repair neighborhood, selects an auditable representative, and then applies evidence-constrained fusion (ECF) to retain repeated edit atoms and prune unsupported parts. To evaluate this setting, we build PatchFuseBench, a fixed-pool benchmark covering SWE-bench Verified, SWE-bench Multilingual, and Defects4J candidate patches. On PatchFuseBench, PatchFusion solves 426/500 bugs on SWE-bench Verified and 236/300 on SWE-bench Multilingual, and reaches 87/371 plausible patches on Defects4J, outperforming every matched candidate-pool selector on all three. PatchFusion recovers 41 and 27 bugs that no single source solves (30 and 18 more over the best single source). Ablation studies show that ECF adds +5/+6/+9 solved bugs by recovering in-pool repairs that selection misses, with no observed regression, and that PatchFusion's gains remain stable as candidate pools are resampled. On these complementary multi-source pools, cross-candidate evidence recovers more correct patches than the test-based and LLM-based selectors we evaluate, at orders-of-magnitude lower cost, reaching within 96.2% and 89.7% of the candidate-reachable ceiling on the two SWE-bench benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PatchFusion, a deterministic post-generation method for fusing candidate patches from LLM coding agents. It constructs a repair neighborhood from whole-diff agreement, selects an auditable representative, and applies evidence-constrained fusion (ECF) to retain repeated edit atoms while pruning unsupported parts, without consulting test outcomes at decision time. On the introduced PatchFuseBench, it reports solving 426/500 bugs on SWE-bench Verified, 236/300 on SWE-bench Multilingual, and 87/371 plausible patches on Defects4J, outperforming matched selectors and recovering 41 and 27 bugs unreachable by any single source, with ablations attributing +5/+6/+9 gains to ECF.
Significance. If the performance claims and the underlying assumption hold, the work offers a low-cost, deterministic alternative to ranking, test-filtering, or LLM judging for closing the pass@k-to-pass@1 gap in automated repair. The deterministic, evidence-based fusion and the recovery of bugs missed by all individual sources would be a notable contribution to the field, especially given the reported stability under pool resampling and the orders-of-magnitude cost advantage.
major comments (2)
- [Evaluation / Ablation studies] The central performance advantage (recovery of 41/27 bugs unreachable by any single source, plus the +5/+6/+9 ECF gains) rests on the untested premise that repeated edit atoms across candidates reliably signal correctness rather than shared incorrect repairs. No section quantifies the rate at which repeated atoms are incorrect or provides provenance analysis for the 41 recovered cases; this assumption is load-bearing for attributing gains to ECF rather than pool quality.
- [§4 (PatchFuseBench results)] The reported numbers (426/500, 236/300, 87/371) are measured after fusion using test outcomes, yet the method itself makes no use of tests or oracles at decision time. Without a direct analysis of cases where ECF produces a fused patch that passes tests coincidentally or fails silently due to repeated incorrect atoms, the claim that cross-candidate evidence outperforms test-based and LLM-based selectors remains incompletely supported.
minor comments (2)
- [Abstract / Methods] The abstract and evaluation sections would benefit from explicit definitions or pseudocode for 'edit atom' and 'repair neighborhood' to make the ECF procedure fully reproducible from the text alone.
- [Evaluation setup] Clarify how 'plausible patches' are defined on Defects4J versus 'solved bugs' on SWE-bench, and whether the same test-based oracle is used for all three benchmarks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Evaluation / Ablation studies] The central performance advantage (recovery of 41/27 bugs unreachable by any single source, plus the +5/+6/+9 ECF gains) rests on the untested premise that repeated edit atoms across candidates reliably signal correctness rather than shared incorrect repairs. No section quantifies the rate at which repeated atoms are incorrect or provides provenance analysis for the 41 recovered cases; this assumption is load-bearing for attributing gains to ECF rather than pool quality.
Authors: We agree that quantifying the rate of incorrect repeated atoms and providing provenance for the recovered cases would strengthen attribution of gains specifically to ECF. The existing ablations demonstrate that ECF contributes additional solved bugs with no observed regressions, and the recovery of bugs missed by all individual sources offers supporting evidence. In revision we will add a sample-based manual provenance analysis of the recovered cases and report the observed rate of incorrect repeated atoms where identifiable from the available patches. revision: yes
-
Referee: [§4 (PatchFuseBench results)] The reported numbers (426/500, 236/300, 87/371) are measured after fusion using test outcomes, yet the method itself makes no use of tests or oracles at decision time. Without a direct analysis of cases where ECF produces a fused patch that passes tests coincidentally or fails silently due to repeated incorrect atoms, the claim that cross-candidate evidence outperforms test-based and LLM-based selectors remains incompletely supported.
Authors: The reported success counts are necessarily determined by test outcomes because that is the established ground truth for correctness on these benchmarks. The fusion decision itself remains strictly test-agnostic, which is the central methodological distinction. We will revise the presentation in §4 to separate the test-free decision procedure more explicitly from the post-hoc evaluation and will add discussion of possible coincidental correctness. A comprehensive analysis of silent failures due to repeated incorrect atoms would require oracles beyond those provided by the benchmarks and is therefore outside the scope of the current evaluation. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents PatchFusion as a deterministic, test-independent fusion of repeated edit atoms across candidate patches, with success measured post-hoc on fixed benchmarks (PatchFuseBench). No equations, parameters, or claims reduce by construction to fitted inputs, self-citations, or renamed empirical patterns. The central premise (repetition signals correctness) is an explicit modeling assumption evaluated empirically rather than derived tautologically. Ablations and comparisons to selectors are reported as independent measurements. This is the common honest case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated repair of programs from large language models,
Z. Fan, X. Gaoet al., “Automated repair of programs from large language models,” inProceedings of the 45th International Conference on Software Engineering. Piscataway, NJ, USA: IEEE, 2023, pp. 1469–1481
2023
-
[2]
Automated program repair in the era of large pre-trained language models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” inProceedings of the 45th International Conference on Software Engineering. Piscataway, NJ, USA: IEEE, 2023, pp. 1482–1494
2023
-
[3]
RepairAgent: An autonomous, LLM-based agent for program repair,
I. Bouzenia, P. T. Devanbu, and M. Pradel, “RepairAgent: An autonomous, LLM-based agent for program repair,” inProceedings of the 47th International Conference on Software Engineering, 2025, pp. 2188–2200
2025
-
[4]
MORepair: Teaching LLMs to repair code via multi-objective fine-tuning,
B. Yang, H. Tianet al., “MORepair: Teaching LLMs to repair code via multi-objective fine-tuning,”ACM Trans. Softw. Eng. Methodol., vol. 35, no. 2, pp. 38:1–38:38, 2026
2026
-
[5]
Modern code reviews in open-source projects: which problems do they fix?
M. Beller, A. Bacchelliet al., “Modern code reviews in open-source projects: which problems do they fix?” inProceedings of the 11th Working Conference on Mining Software Repositories. New York, NY , USA: ACM, 2014, pp. 202–211
2014
-
[6]
An empirical study of the impact of modern code review practices on software quality,
S. McIntosh, Y . Kameiet al., “An empirical study of the impact of modern code review practices on software quality,”Empir. Softw. Eng., vol. 21, no. 5, pp. 2146–2189, 2016
2016
-
[7]
Review4repair: Code review aided automatic program repairing,
F. Huq, M. Hasanet al., “Review4repair: Code review aided automatic program repairing,”Inf. Softw. Technol., vol. 143, p. 106765, 2022
2022
-
[8]
On the introduction of automatic program repair in bloomberg,
S. Kirbas, E. Windelset al., “On the introduction of automatic program repair in bloomberg,”IEEE Softw., vol. 38, no. 4, pp. 43–51, 2021
2021
-
[9]
CREF: An LLM-based conversational software repair framework for programming tutors,
B. Yang, H. Tianet al., “CREF: An LLM-based conversational software repair framework for programming tutors,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2024, pp. 882–894
2024
-
[10]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yanget al., “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2024
2024
-
[11]
Competition-level code generation with AlphaCode,
Y . Li, D. Choiet al., “Competition-level code generation with AlphaCode,” Science, vol. 378, no. 6624, pp. 1092–1097, 2022
2022
-
[12]
R. Ehrlich, B. Brownet al., “CodeMonkeys: Scaling test-time compute for software engineering,”arXiv preprint arXiv:2501.14723, 2025
-
[13]
A. Antoniades, A. ¨Orwallet al., “SWE-Search: Enhancing software agents with monte carlo tree search and iterative refinement,”arXiv preprint arXiv:2410.20285, 2024
-
[14]
An analysis of patch plausibility and correctness for generate-and-validate patch generation systems,
Z. Qi, F. Longet al., “An analysis of patch plausibility and correctness for generate-and-validate patch generation systems,” inProceedings of the 2015 International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2015, pp. 24–36
2015
-
[15]
The patch overfitting problem in automated program repair: Practical magnitude and a baseline for realistic bench- marking,
J. Petke, M. Martinezet al., “The patch overfitting problem in automated program repair: Practical magnitude and a baseline for realistic bench- marking,” inCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. New York, NY , USA: ACM, 2024, pp. 452–456
2024
-
[16]
A survey of LLM-based automated program repair: Taxonomies, design paradigms, and applications,
B. Yang, Z. Caiet al., “A survey of LLM-based automated program repair: Taxonomies, design paradigms, and applications,”arXiv preprint arXiv:2506.23749, 2025
-
[17]
Demystifying LLM-based software engineering agents,
C. S. Xia, Y . Denget al., “Demystifying LLM-based software engineering agents,”Proc. ACM Softw. Eng., vol. 2, no. FSE, pp. 801–824, 2025
2025
-
[18]
Revisiting object similarity-based patch ranking in automated program repair: An extensive study,
A. Ghanbari, “Revisiting object similarity-based patch ranking in automated program repair: An extensive study,” inProceedings of the 3rd IEEE/ACM International Workshop on Automated Program Repair. Piscataway, NJ, USA: IEEE, 2022, pp. 16–23
2022
-
[19]
Rank aggregation methods for the web,
C. Dwork, R. Kumaret al., “Rank aggregation methods for the web,” in Proceedings of the 10th International Conference on World Wide Web. Hong Kong, China: ACM, 2001, pp. 613–622
2001
-
[20]
Patch correctness assessment in automated program repair based on the impact of patches on production and test code,
A. Ghanbari and A. Marcus, “Patch correctness assessment in automated program repair based on the impact of patches on production and test code,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2022, pp. 654–665
2022
-
[21]
Predicting patch correctness based on the similarity of failing test cases,
H. Tian, Y . Liet al., “Predicting patch correctness based on the similarity of failing test cases,”ACM Trans. Softw. Eng. Methodol., vol. 31, no. 4, pp. 77:1–77:30, 2022
2022
-
[22]
Identifying patch correctness in test-based program repair,
Y . Xiong, X. Liuet al., “Identifying patch correctness in test-based program repair,” inProceedings of the 40th International Conference on Software Engineering. New York, NY , USA: ACM, 2018, pp. 789–799
2018
-
[23]
Automated patch assessment for program repair at scale,
H. Ye, M. Martinez, and M. Monperrus, “Automated patch assessment for program repair at scale,”Empir. Softw. Eng., vol. 26, no. 2, p. 20, 2021
2021
-
[24]
Leveraging large language model for automatic patch correctness assessment,
X. Zhou, B. Xuet al., “Leveraging large language model for automatic patch correctness assessment,”IEEE Trans. Software Eng., vol. 50, no. 11, pp. 2865–2883, 2024
2024
-
[25]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Weiet al., “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations. OpenReview.net, 2023
2023
-
[26]
CodeT: Code generation with generated tests,
B. Chen, F. Zhanget al., “CodeT: Code generation with generated tests,” inThe Eleventh International Conference on Learning Representations. OpenReview.net, 2023
2023
-
[27]
Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
X. Chen, R. Aksitovet al., “Universal self-consistency for large language model generation,”arXiv preprint arXiv:2311.17311, 2023
-
[28]
SWE-bench official leaderboards,
SWE-bench Team, “SWE-bench official leaderboards,” https://www. swebench.com/, 2026
2026
-
[29]
Live-SWE-agent: Can software engineering agents self-evolve on the fly?
C. S. Xia, Z. Wanget al., “Live-SWE-agent: Can software engineering agents self-evolve on the fly?”arXiv preprint arXiv:2511.13646, 2025
-
[30]
Trae Agent: An LLM-based agent for general purpose software engineering tasks,
ByteDance, “Trae Agent: An LLM-based agent for general purpose software engineering tasks,” https://github.com/bytedance/trae-agent, 2025
2025
-
[31]
Rovo Dev: Agentic AI for software teams,
Atlassian, “Rovo Dev: Agentic AI for software teams,” https://www. atlassian.com/software/rovo-dev, 2025
2025
-
[32]
EPAM AI/Run Developer Agent: SWE-bench verified submission,
EPAM Systems, “EPAM AI/Run Developer Agent: SWE-bench verified submission,” https://github.com/SWE-bench/experiments, 2025
2025
-
[33]
ACoder: Achieving state-of-the-art performance on SWE- bench Verified,
ACoder Team, “ACoder: Achieving state-of-the-art performance on SWE- bench Verified,” https://github.com/SWE-bench/experiments, 2025
2025
-
[34]
Defects4J: A database of existing faults to enable controlled testing studies for Java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4J: A database of existing faults to enable controlled testing studies for Java programs,” in Proceedings of the 2014 International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2014, pp. 437–440
2014
-
[35]
Genprog: A generic method for automatic software repair,
C. Le Goues, T. Nguyenet al., “Genprog: A generic method for automatic software repair,”IEEE Trans. Softw. Eng., vol. 38, no. 1, pp. 54–72, 2012
2012
-
[36]
Language models can prioritize patches for practical program patching,
S. Kang and S. Yoo, “Language models can prioritize patches for practical program patching,” inProceedings of the 3rd IEEE/ACM International Workshop on Automated Program Repair. New York, NY , USA: ACM, 2022, pp. 8–15
2022
-
[37]
On the naturalness of software,
A. Hindle, E. T. Barret al., “On the naturalness of software,” inPro- ceedings of the 34th International Conference on Software Engineering. Piscataway, NJ, USA: IEEE, 2012, pp. 837–847
2012
-
[38]
Learning to represent patches,
X. Tang, H. Tianet al., “Learning to represent patches,” inCompanion Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. New York, NY , USA: ACM, 2024, pp. 396–397
2024
-
[39]
Automatic patch generation by learning correct code,
F. Long and M. C. Rinard, “Automatic patch generation by learning correct code,” inProceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. New York, NY , USA: ACM, 2016, pp. 298–312
2016
-
[40]
Context-aware patch generation for better automated program repair,
M. Wen, J. Chenet al., “Context-aware patch generation for better automated program repair,” inProceedings of the 40th International Conference on Software Engineering. New York, NY , USA: ACM, 2018, pp. 1–11
2018
-
[41]
TBar: Revisiting template-based automated program repair,
K. Liu, A. Koyuncuet al., “TBar: Revisiting template-based automated program repair,” inProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2019, pp. 31–42
2019
-
[42]
FixMiner: Mining relevant fix patterns for automated program repair,
A. Koyuncu, K. Liuet al., “FixMiner: Mining relevant fix patterns for automated program repair,”Empirical Software Engineering, vol. 25, no. 3, pp. 1980–2024, 2020
1980
-
[43]
Semfix: program repair via semantic analysis,
H. D. T. Nguyen, D. Qiet al., “Semfix: program repair via semantic analysis,” inProceedings of the 2013 International Conference on Software Engineering. Piscataway, NJ, USA: IEEE Press, 2013, pp. 772–781
2013
-
[44]
Angelix: scalable multiline program patch synthesis via symbolic analysis,
S. Mechtaev, J. Yi, and A. Roychoudhury, “Angelix: scalable multiline program patch synthesis via symbolic analysis,” inProceedings of the 38th International Conference on Software Engineering. New York, NY , USA: ACM, 2016, pp. 691–701
2016
-
[45]
DLFix: Context-based code transformation learning for automated program repair,
Y . Li, S. Wang, and T. N. Nguyen, “DLFix: Context-based code transformation learning for automated program repair,” inProceedings of the 42nd International Conference on Software Engineering. New York, NY , USA: ACM, 2020, pp. 602–614
2020
-
[46]
Coconut: combining context-aware neural translation models using ensemble for program repair,
T. Lutellier, H. V . Phamet al., “Coconut: combining context-aware neural translation models using ensemble for program repair,” inProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2020, pp. 101–114
2020
-
[47]
Sequencer: Sequence-to-sequence learning for end-to-end program repair,
Z. Chen, S. Kommruschet al., “Sequencer: Sequence-to-sequence learning for end-to-end program repair,”IEEE Trans. Softw. Eng., vol. 47, no. 9, pp. 1943–1959, 2021
1943
-
[48]
Less training, more repairing please: revisiting automated program repair via zero-shot learning,
C. S. Xia and L. Zhang, “Less training, more repairing please: revisiting automated program repair via zero-shot learning,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York, NY , USA: ACM, 2022, pp. 959–971
2022
-
[49]
CCTEST: Testing and repairing code completion systems,
Z. Li, C. Wanget al., “CCTEST: Testing and repairing code completion systems,” inProceedings of the 45th International Conference on Software Engineering. Piscataway, NJ, USA: IEEE, 2023, pp. 1238–1250
2023
-
[50]
Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt,
C. S. Xia and L. Zhang, “Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2024, pp. 819–831
2024
-
[51]
RAP-Gen: Retrieval-augmented patch generation with CodeT5 for automatic program repair,
W. Wang, Y . Wanget al., “RAP-Gen: Retrieval-augmented patch generation with CodeT5 for automatic program repair,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York, NY , USA: ACM, 2023, pp. 146–158
2023
-
[52]
Enhancing repository-level software repair via repository-aware knowledge graphs,
B. Yang, H. Tianet al., “Enhancing repository-level software repair via repository-aware knowledge graphs,”arXiv preprint arXiv:2503.21710, 2025
-
[53]
SWE-agent: Agent-computer interfaces en- able automated software engineering,
J. Yang, C. E. Jimenezet al., “SWE-agent: Agent-computer interfaces en- able automated software engineering,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[54]
AutoCodeRover: Autonomous program improvement,
Y . Zhang, J. Ruanet al., “AutoCodeRover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY , USA: ACM, 2024, pp. 1592–1604
2024
-
[55]
Harnessing evolution for multi- hunk program repair,
S. Saha, R. K. Saha, and M. R. Prasad, “Harnessing evolution for multi- hunk program repair,” inProceedings of the 41st International Conference on Software Engineering. Piscataway, NJ, USA: IEEE / ACM, 2019, pp. 13–24
2019
-
[56]
Varfix: balancing edit expressiveness and search effectiveness in automated program repair,
C.-P. Wong, P. Santiestebanet al., “Varfix: balancing edit expressiveness and search effectiveness in automated program repair,” inProceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York, NY , USA: ACM, 2021, pp. 354–366
2021
-
[57]
ITER: Iterative neural repair for multi-location patches,
H. Ye and M. Monperrus, “ITER: Iterative neural repair for multi-location patches,” inProceedings of the 46th IEEE/ACM International Conference on Software Engineering, 2024, pp. 10:1–10:13
2024
-
[58]
Hybrid automated program repair by com- bining large language models and program analysis,
F. Li, J. Jianget al., “Hybrid automated program repair by com- bining large language models and program analysis,”arXiv preprint arXiv:2406.00992, 2024
-
[59]
SiblingRepair: Sibling-Based Multi-Hunk Repair with Large Language Models
X. Liu, J. Renet al., “Siblingrepair: Sibling-based multi-hunk repair with large language models,”arXiv preprint arXiv:2605.06209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
When large language models confront repository- level automatic program repair: How well they done?
Y . Chen, J. Wuet al., “When large language models confront repository- level automatic program repair: How well they done?” inProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. New York, NY , USA: ACM, 2024, pp. 459–471
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.