Teaching Vision-Language-Action Models What to See and Where to Look
Pith reviewed 2026-07-03 16:40 UTC · model grok-4.3
The pith
DriveTeach-VLA adds driving-specific vision distillation and trajectory prompts to vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
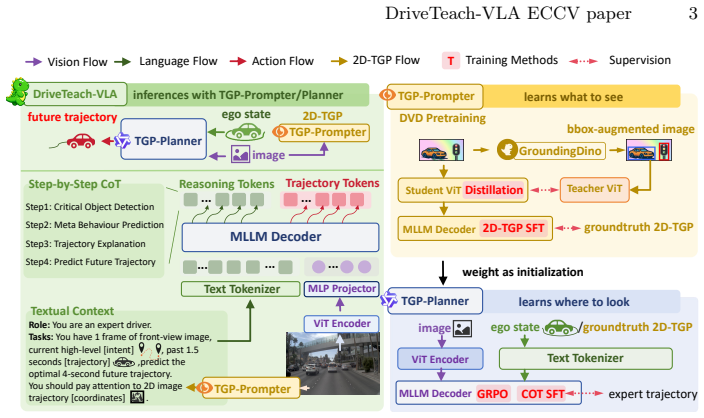
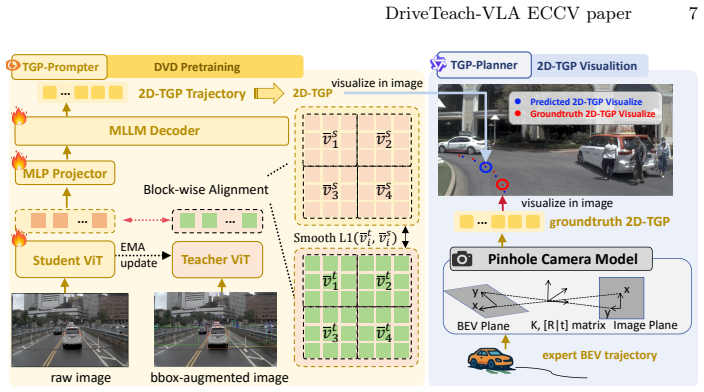
DriveTeach-VLA explicitly teaches VLAs what to see and where to look via Driving-aware Vision Distillation that injects driving-specific perceptual priors into the vision encoder together with 2D Trajectory-Guided Prompts that supply spatial conditioning aligned with feasible driving trajectories, forming the pipeline of DVD pretraining followed by TGP-guided supervised fine-tuning and TGP-guided GRPO.
What carries the argument
Driving-aware Vision Distillation (DVD) and 2D Trajectory-Guided Prompts (2D-TGP) that together supply driving priors and trajectory-aligned spatial conditioning to the VLA training process.
If this is right
- The vision encoder receives driving-specific perceptual priors before any action learning occurs.
- Spatial conditioning is aligned directly with feasible driving trajectories during fine-tuning and reinforcement stages.
- The three-stage pipeline separates perception teaching from action learning.
- Trajectory prediction reliability improves because the model learns both what to see and where to look.
Where Pith is reading between the lines
- The same separation of perceptual priors from action learning may apply to other embodied tasks that combine vision and control.
- Text-centric pretraining alone may prove insufficient for any VLA that must output physical actions rather than language.
- Extending the 2D prompts to incorporate depth or multi-camera geometry could further tighten the spatial alignment.
Load-bearing premise
Existing VLAs trained on text-centric data capture semantic knowledge but miss the spatial dependencies required for reliable trajectory prediction.
What would settle it
A VLA trained without DVD pretraining or 2D-TGP guidance that matches or exceeds DriveTeach-VLA performance on NAVSIM and nuScenes would show the added components are not required.
Figures






read the original abstract
Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing VLAs' training relies heavily on text-centric visual question answering and chain-of-thought reasoning data, which emphasizes linguistic reasoning rather than action-grounded planning. As a result, the learned representations capture semantic knowledge but lack spatial dependencies crucial for reliable trajectory prediction. We propose DriveTeach-VLA, a framework that explicitly teaches VLAs what to see and where to look. Driving-aware Vision Distillation (DVD) injects driving-specific perceptual priors into the vision encoder, while 2D Trajectory-Guided Prompts (2D-TGP) provide spatial conditioning aligned with feasible driving trajectories. Together, they form a vision-guided learning pipeline: what to see (DVD pretraining) - where to look (TGP-guided SFT) - how to act (TGP-guided GRPO). DriveTeach-VLA achieves the state-of-the-art performance on NAVSIM and nuScenes. Our code is available at: https://github.com/ShivaTeam/DriveTeach-VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DriveTeach-VLA, a framework for Vision-Language-Action (VLA) models in autonomous driving. It proposes Driving-aware Vision Distillation (DVD) to inject driving-specific perceptual priors into the vision encoder during pretraining, and 2D Trajectory-Guided Prompts (2D-TGP) to supply spatial conditioning aligned with feasible trajectories during supervised fine-tuning (SFT) and GRPO stages. The pipeline is framed as teaching the model what to see (DVD), where to look (TGP-guided SFT), and how to act (TGP-guided GRPO). The central claim is that this approach reaches state-of-the-art performance on the NAVSIM and nuScenes benchmarks, with code released at the provided GitHub link.
Significance. If the reported performance gains hold under rigorous evaluation, the work could meaningfully advance end-to-end driving models by improving spatial structure in VLA representations. The explicit separation of perceptual pretraining from trajectory-guided fine-tuning stages offers a clear, modular recipe that other researchers could adapt. Open-sourcing the code is a concrete strength that lowers the barrier to verification and extension.
minor comments (3)
- [Abstract] Abstract: the SOTA claim on NAVSIM and nuScenes is stated without any numerical metrics, baseline names, or ablation summaries; adding one or two key numbers (e.g., success rate or collision rate deltas) would make the abstract self-contained while remaining within length limits.
- [Introduction] The motivation paragraph asserts that existing VLAs lack spatial dependencies, yet no diagnostic experiment or citation to a quantitative study of spatial awareness in prior VLAs is referenced; a short supporting sentence or reference would clarify the premise without altering the central contribution.
- [Method] Terminology for the three-stage pipeline (DVD pretraining, TGP-guided SFT, TGP-guided GRPO) is introduced in the abstract but should be cross-referenced with consistent subsection headings in the method section to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review, including the recognition of our modular pipeline, open-sourced code, and potential impact on end-to-end driving models. The recommendation for minor revision is appreciated. No major comments were provided in the report, so we have no specific points requiring rebuttal or revision at this stage.
Circularity Check
No significant circularity identified
full rationale
The paper introduces DriveTeach-VLA via two proposed components (DVD pretraining and 2D-TGP conditioning) and reports empirical SOTA results on NAVSIM and nuScenes. No equations, parameter-fitting steps, or derivation chains appear in the abstract or description. The central claims rest on the training pipeline stages rather than any self-referential definition, fitted-input prediction, or load-bearing self-citation. The background statement that prior VLAs lack spatial structure is presented as motivation, not a result derived from the method. This is a standard empirical proposal with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ang, S., Chen, Y., Haiyan, L., Mao, X., Bao, J., Xuliang, Sun, B., Wang, Y.: Asscg: Just-right gating over chattering for fast-slow llm planning in autonomous driving (2026),https://arxiv.org/abs/2606.25509
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Transactions on Computational and Scientific Methods5(4) (2025)
Broekman, N.: Toward safe and scalable autonomy: A comprehensive review of technologies, deployments, and challenges in autonomous driving. Transactions on Computational and Scientific Methods5(4) (2025)
2025
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, C., Yang, Y., Tan, Z., Wang, Y., Zhan, R., Liu, H., Mao, X., Bao, J., Tang, X., Yang, L., et al.: Devil is in narrow policy: Unleashing exploration in driving vla models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1062–1072 (2026)
2026
-
[6]
In: European Conference on Computer Vision
Chen, Y., Ding, Z.h., Wang, Z., Wang, Y., Zhang, L., Liu, S.: Asynchronous large language model enhanced planner for autonomous driving. In: European Conference on Computer Vision. pp. 22–38. Springer (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[8]
Impromptu VLA: Open weights and open data for driving vision-language-action models
Chi, H., Gao, H.a., Liu, Z., Liu, J., Liu, C., Li, J., Yang, K., Yu, Y., Wang, Z., Li, W., et al.: Impromptu vla: Open weights and open data for driving vision-language- action models. arXiv preprint arXiv:2505.23757 (2025)
-
[9]
IEEE transactions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
2022
-
[10]
Advances in Neural Information Processing Systems37, 28706–28719 (2024)
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschen- ski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive au- tonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2024)
2024
-
[11]
arXiv preprint arXiv:2504.19580 (2025)
Feng, R., Xi, N., Chu, D., Wang, R., Deng, Z., Wang, A., Lu, L., Wang, J., Huang, Y.: Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving. arXiv preprint arXiv:2504.19580 (2025)
-
[12]
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. arXiv preprint arXiv:2503.19755 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (2025)
2025
-
[14]
Emerging topics in computer vision3, 45–108 (2005)
Heyden, A., Pollefeys, M.: Multiple view geometry. Emerging topics in computer vision3, 45–108 (2005)
2005
-
[15]
In: European Conference on Computer Vision
Hu, S., Chen, L., Wu, P., Li, H., Yan, J., Tao, D.: St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In: European Conference on Computer Vision. pp. 533–549. Springer (2022) DriveTeach-VLA ECCV paper 17
2022
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853–17862 (2023)
2023
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, Z., Liu, H., Lv, C.: Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3903–3913 (2023)
2023
-
[18]
IEEE transactions on neural networks and learning systems (2023)
Huang, Z., Liu, H., Wu, J., Lv, C.: Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving. IEEE transactions on neural networks and learning systems (2023)
2023
-
[19]
arXiv preprint arXiv:2410.05582 (2024)
Huang, Z., Weng, X., Igl, M., Chen, Y., Cao, Y., Ivanovic, B., Pavone, M., Lv, C.: Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning. arXiv preprint arXiv:2410.05582 (2024)
-
[20]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Hwang, J.J., Xu, R., Lin, H., Hung, W.C., Ji, J., Choi, K., Huang, D., He, T., Cov- ington, P., Sapp, B., et al.: Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang, C., Wang, X.: Vad: Vectorized scene representation for efficient autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8340–8350 (2023)
2023
-
[23]
arXiv preprint arXiv:2508.09158 (2025)
Jiao, S., Qian, K., Ye, H., Zhong, Y., Luo, Z., Jiang, S., Huang, Z., Fang, Y., Miao, J., Fu, Z., et al.: Evadrive: Evolutionary adversarial policy optimization for end-to-end autonomous driving. arXiv preprint arXiv:2508.09158 (2025)
- [24]
-
[25]
arXiv preprint arXiv:2508.11428 (2025)
Li, J., Zhang, B., Jin, X., Deng, J., Zhu, X., Zhang, L.: Imagidrive: A uni- fied imagination-and-planning framework for autonomous driving. arXiv preprint arXiv:2508.11428 (2025)
-
[26]
arXiv preprint arXiv:2503.12820 (2025)
Li, K., Li, Z., Lan, S., Xie, Y., Zhang, Z., Liu, J., Wu, Z., Yu, Z., Alvarez, J.M.: Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation. arXiv preprint arXiv:2503.12820 (2025)
-
[27]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Li, Y., Shang, S., Liu, W., Zhan, B., Wang, H., Wang, Y., Chen, Y., Wang, X., An, Y., Tang, C., et al.: Drivevla-w0: World models amplify data scaling law in autonomous driving. arXiv preprint arXiv:2510.12796 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with online trajectory evaluation via bev world model. arXiv preprint arXiv:2504.01941 (2025)
-
[29]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation. arXiv preprint arXiv:2406.06978 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024) 18 Y
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal trans- formers. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024) 18 Y. Yang et al
2024
-
[32]
Li, Z., Yu, Z., Lan, S., Li, J., Kautz, J., Lu, T., Alvarez, J.M.: Is ego status all you need for open-loop end-to-end autonomous driving? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14864–14873 (2024)
2024
-
[33]
Advances in Neural Information Processing Systems35, 10421–10434 (2022)
Liang, T., Xie, H., Yu, K., Xia, Z., Lin, Z., Wang, Y., Tang, T., Wang, B., Tang, Z.: Bevfusion: A simple and robust lidar-camera fusion framework. Advances in Neural Information Processing Systems35, 10421–10434 (2022)
2022
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end- to-end autonomous driving. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12037–12047 (2025)
2025
-
[35]
In: 2021 IEEE Symposium on Computers and Communications (ISCC)
Liu, C., Yu, S., Yu, M., Wei, B., Li, B., Li, G., Huang, W.: Adaptive smooth l1 loss: A better way to regress scene texts with extreme aspect ratios. In: 2021 IEEE Symposium on Computers and Communications (ISCC). pp. 1–7. IEEE (2021)
2021
-
[36]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Liu, H., Huang, Z., Huang, W., Yang, H., Mo, X., Lv, C.: Hybrid-prediction integrated planning for autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[37]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[38]
arXiv preprint arXiv:2509.05578 (2025)
Liu, R., Kong, L., Li, D., Zhao, H.: Occvla: Vision-language-action model with implicit 3d occupancy supervision. arXiv preprint arXiv:2509.05578 (2025)
-
[39]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[40]
Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving, 2025
Luo, Y., Li, F., Xu, S., Lai, Z., Yang, L., Chen, Q., Luo, Z., Xie, Z., Jiang, S., Liu, J., et al.: Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving. arXiv preprint arXiv:2509.13769 (2025)
-
[41]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Qian, T., Chen, J., Zhuo, L., Jiao, Y., Jiang, Y.G.: Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. pp. 4542–4550 (2024)
2024
-
[42]
arXiv preprint arXiv:2505.00284 (2025)
Qiao, Z., Li, H., Cao, Z., Liu, H.X.: Lightemma: Lightweight end-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2505.00284 (2025)
-
[43]
arXiv preprint arXiv:2503.09594 (2025)
Renz, K., Chen, L., Arani, E., Sinavski, O.: Simlingo: Vision-only closed-loop au- tonomous driving with language-action alignment. arXiv preprint arXiv:2503.09594 (2025)
-
[44]
arXiv preprint arXiv:2406.10165 (2024)
Renz, K., Chen, L., Marcu, A.M., Hünermann, J., Hanotte, B., Karnsund, A., Shotton, J., Arani, E., Sinavski, O.: Carllava: Vision language models for camera- only closed-loop driving. arXiv preprint arXiv:2406.10165 (2024)
-
[45]
arXiv preprint arXiv:2506.11234 (2025)
Rowe, L., de Schaetzen, R., Girgis, R., Pal, C., Paull, L.: Poutine: Vision-language- trajectory pre-training and reinforcement learning post-training enable robust end-to-end autonomous driving. arXiv preprint arXiv:2506.11234 (2025)
-
[46]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(5), 3955–3971 (2024)
Shi, S., Jiang, L., Dai, D., Schiele, B.: Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying. IEEE Transactions on Pattern Analysis and Machine Intelligence46(5), 3955–3971 (2024)
2024
-
[47]
In: European conference on computer vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European conference on computer vision. pp. 256–274. Springer (2024)
2024
-
[48]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian, X., Gu, J., Li, B., Liu, Y., Wang, Y., Zhao, Z., Zhan, K., Jia, P., Lang, X., Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289 (2024) DriveTeach-VLA ECCV paper 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
arXiv preprint arXiv:2405.01533 (2024)
Wang, S., Yu, Z., Jiang, X., Lan, S., Shi, M., Chang, N., Kautz, J., Li, Y., Alvarez, J.M.: Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning. arXiv preprint arXiv:2405.01533 (2024)
-
[50]
In: Conference on Robot Learning
Wang, Y., Guizilini, V.C., Zhang, T., Wang, Y., Zhao, H., Solomon, J.: Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Conference on Robot Learning. pp. 180–191. PMLR (2022)
2022
-
[51]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y., Wu, C., Wang, B., Xie, Z., Wu, Y., Hu, K., Wang, J., Sun, Y., Li, Y., Piao, Y., Guan, K., Liu, A., Xie, X., You, Y., Dong, K., Yu, X., Zhang, H., Zhao, L., Wang, Y., Ruan, C.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. https://arxiv.o...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
In: Proceedings of the Winter Conference on Applications of Computer Vision
Xing, S., Qian, C., Wang, Y., Hua, H., Tian, K., Zhou, Y., Tu, Z.: Openemma: Open-source multimodal model for end-to-end autonomous driving. In: Proceedings of the Winter Conference on Applications of Computer Vision. pp. 1001–1009 (2025)
2025
-
[53]
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Yang, Z., Chai, Y., Jia, X., Li, Q., Shao, Y., Zhu, X., Su, H., Yan, J.: Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving. arXiv preprint arXiv:2505.16278 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model,
Zhou, X., Han, X., Yang, F., Ma, Y., Knoll, A.C.: Opendrivevla: Towards end-to- end autonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463 (2025)
-
[55]
Zhou, Z., Cai, T., Zhao, S.Z., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. arXiv preprint arXiv:2506.13757 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Zhou, Z., Wen, Z., Wang, J., Li, Y.H., Huang, Y.K.: Qcnext: A next- generation framework for joint multi-agent trajectory prediction. arXiv preprint arXiv:2306.10508 (2023) DriveTeach-VLA ECCV paper 1 A NA VSIM Best-of-N PDMS & EPDMS Autoregressive model often exhibit strong exploration capability. In Table 11, we compare the best-of-N performance. For ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.