C2E: Boosting Ego-Only 3D Object Detection via Multi-Teacher Contrastive Knowledge Distillation
Pith reviewed 2026-07-03 16:03 UTC · model grok-4.3
The pith
The M2S framework distills collaborative perception knowledge into ego-only 3D detectors to raise accuracy without communication or pose errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
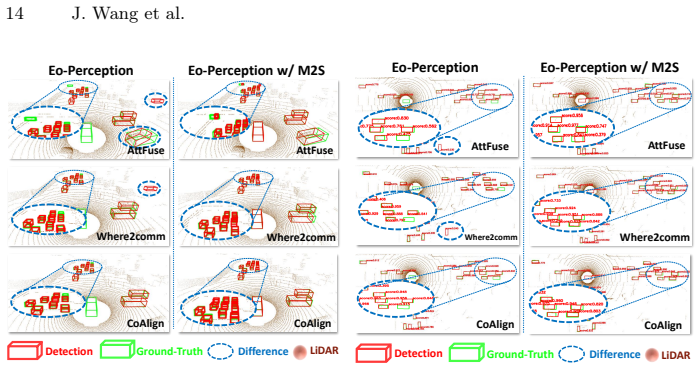
The M2S framework enables ego-only 3D object detectors to retain the performance benefits of collaborative perception by distilling from multiple teachers using contrastive methods and auxiliary reconstruction, closing the distribution gaps in point clouds and features without incurring communication delays or positioning errors.
What carries the argument
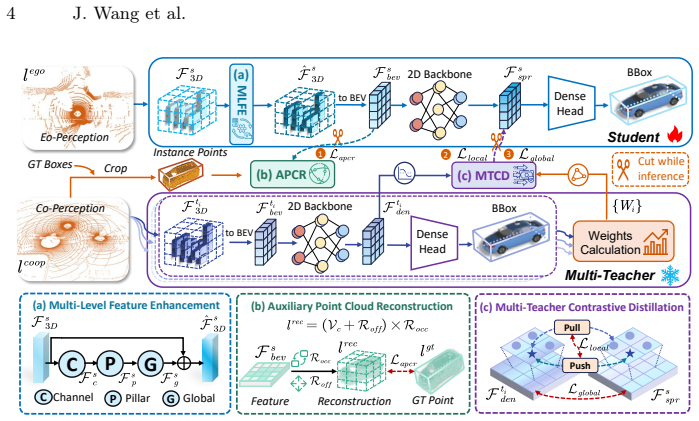
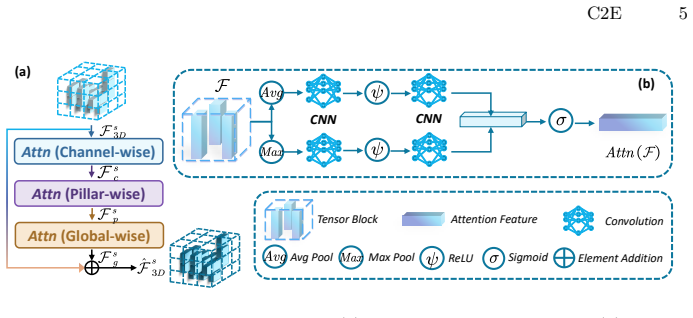
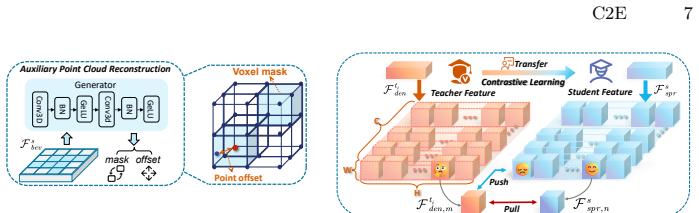
The Multi-to-Single (M2S) agent contrastive knowledge distillation framework, which includes Multi-Level Feature Enhancement, Auxiliary Point Cloud Reconstruction, and Multi-Teacher Contrastive Distillation modules to transfer collaborative knowledge to ego-only models.
If this is right
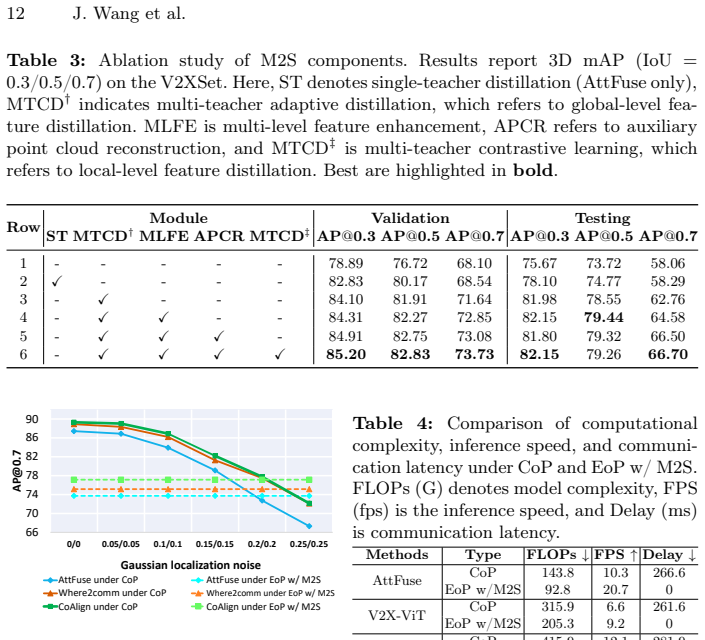
- Ego-only detectors combined with M2S reach up to 8.64 percent higher 3D mAP than the same detectors without distillation on V2XSet, V2V4Real, and DAIR-V2X.
- Collaborative perception advantages become available in single-agent systems that cannot exchange data.
- Occlusion and limited-field-of-view problems in outdoor LiDAR detection are partially alleviated without multi-agent infrastructure.
- The same distillation recipe applies to multiple existing collaborative and ego-only 3D detectors.
Where Pith is reading between the lines
- Real-world fleets could adopt the approach to improve perception on vehicles that lack V2X radios.
- The contrastive loss structure might extend to distilling from simulated collaborative data when real multi-agent recordings are scarce.
- Robustness checks under varying agent counts or sensor calibration drift would clarify deployment limits.
Load-bearing premise
The domain gaps between collaborative and ego-only point-cloud and feature distributions can be sufficiently closed by the auxiliary reconstruction and multi-teacher contrastive distillation modules so that the distilled student retains most of the teachers' accuracy.
What would settle it
Running the trained M2S student on a held-out sequence from V2XSet or DAIR-V2X where the collaborative teachers are available at inference time and measuring whether mAP falls below the undistilled ego-only baseline would falsify the transfer claim.
Figures

read the original abstract
LiDAR-based 3D object detection is essential for autonomous driving systems. However, traditional Ego-only Perception (Eo-Perception) suffers from limited perspective and occlusions in a complex outdoor environment, leading to performance bottlenecks. Recently, research on multi-agent Collaborative Perception (Co-Perception) has demonstrated excellent performance, but high communication costs and accumulated pose error hinder its application. To address this, we explore a novel C2E (Co-Perception to Eo-Perception) paradigm through the Multi-to-Single (M2S) agent contrastive knowledge distillation framework. Our M2S framework first designs Multi-Level Feature Enhancement module to provide more stable features, and introduces Auxiliary Point Cloud Reconstruction and Multi-Teacher Contrastive Distillation mechanisms to mitigate domain gaps in point cloud and feature distributions within the C2E paradigm. Benefiting from this, our M2S can retain the excellent performance of collaborative perception while effectively avoiding the drawbacks, such as communication delays and positioning errors. Extensive experiments on the V2XSet, V2V4Real and DAIR-V2X datasets show the effectiveness and generalizability of our M2S framework when combined with the state-of-the-art CoSDH model and other excellent 3D detectors. Our M2S framework can deliver up to a 8.64% improvement in 3D mAP performance without introducing any communication costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a C2E (Co-Perception to Ego-Perception) paradigm via the M2S multi-to-single agent contrastive knowledge distillation framework. It introduces a Multi-Level Feature Enhancement module, Auxiliary Point Cloud Reconstruction, and Multi-Teacher Contrastive Distillation to transfer performance from collaborative perception teachers to ego-only 3D detectors while avoiding communication costs and pose errors. Experiments on V2XSet, V2V4Real, and DAIR-V2X with CoSDH and other detectors report up to 8.64% 3D mAP gains.
Significance. If the domain-gap closure holds, the work offers a practical route to high-accuracy ego-only LiDAR detection by distilling from collaborative teachers, which could reduce communication overhead in autonomous driving fleets. The multi-teacher contrastive and reconstruction components are a plausible technical contribution, and the reported cross-dataset generalizability strengthens the case if properly controlled.
major comments (3)
- [§5] §5 (Experiments): the central 8.64% mAP claim is presented without reported ablation controls that isolate the contribution of the auxiliary reconstruction and multi-teacher contrastive modules versus the Multi-Level Feature Enhancement module alone; without these controls the attribution to domain-gap closure cannot be assessed.
- [§4 and §5] §4 (Method) and §5: no quantitative distribution-distance metrics (MMD, Wasserstein, or feature KL) are supplied comparing ego-only vs. collaborative point-cloud/feature distributions before and after distillation on V2XSet or V2V4Real; this leaves the weakest assumption untested and makes it possible that gains arise from regularization rather than successful gap closure.
- [Table 1] Table 1 (or equivalent results table): baseline comparisons, error bars, and statistical significance tests for the reported mAP deltas are not described, undermining confidence that the observed improvements exceed dataset-specific variance.
minor comments (2)
- [§4] Notation for the contrastive loss and reconstruction loss should be unified across equations and text to avoid ambiguity in the multi-teacher setting.
- [Abstract and §5] The abstract states gains 'when combined with the state-of-the-art CoSDH model and other excellent 3D detectors' but does not list the exact detector variants or training protocols used; this detail belongs in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our C2E paradigm and M2S framework. We address each major comment point by point below, indicating planned revisions where the manuscript can be strengthened without misrepresenting the existing results.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): the central 8.64% mAP claim is presented without reported ablation controls that isolate the contribution of the auxiliary reconstruction and multi-teacher contrastive modules versus the Multi-Level Feature Enhancement module alone; without these controls the attribution to domain-gap closure cannot be assessed.
Authors: We agree that isolating the incremental contributions of Auxiliary Point Cloud Reconstruction and Multi-Teacher Contrastive Distillation beyond the Multi-Level Feature Enhancement module would strengthen attribution of the reported gains. The current manuscript includes component-wise ablations, but not in the exact incremental form requested. In the revision we will add a dedicated ablation table that evaluates the Multi-Level Feature Enhancement module in isolation and then cumulatively incorporates the other two modules on V2XSet and V2V4Real. revision: yes
-
Referee: [§4 and §5] §4 (Method) and §5: no quantitative distribution-distance metrics (MMD, Wasserstein, or feature KL) are supplied comparing ego-only vs. collaborative point-cloud/feature distributions before and after distillation on V2XSet or V2V4Real; this leaves the weakest assumption untested and makes it possible that gains arise from regularization rather than successful gap closure.
Authors: We acknowledge that explicit distribution-distance metrics would provide direct evidence for domain-gap closure rather than regularization effects. Computing MMD or KL on raw point clouds and high-dimensional features is feasible but was omitted to keep the main paper focused. In the revised manuscript we will report MMD and feature-wise KL divergence on V2XSet and V2V4Real before and after distillation, either in the main text or as a supplementary table. revision: yes
-
Referee: [Table 1] Table 1 (or equivalent results table): baseline comparisons, error bars, and statistical significance tests for the reported mAP deltas are not described, undermining confidence that the observed improvements exceed dataset-specific variance.
Authors: Our experiments already compare against multiple baselines across three datasets and several detectors, with consistent positive deltas. However, the manuscript does not report error bars or formal significance tests. We will add standard-deviation error bars from multiple training runs (where compute permits) and a brief discussion of statistical significance in the revised results section and Table 1. revision: partial
Circularity Check
No circularity: empirical framework validated on external datasets
full rationale
The paper introduces an M2S distillation framework with auxiliary reconstruction and contrastive modules, then reports mAP gains on V2XSet, V2V4Real and DAIR-V2X. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; performance numbers are presented as experimental outcomes rather than derivations that reduce to their own inputs by construction. The central claim therefore remains self-contained against the cited benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chae, Y., Kim, H., Yoon, K.J.: Towards robust 3d object detection with lidar and 4d radar fusion in various weather conditions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15162– 15172 (June 2024)
2024
-
[2]
In: 2019 IEEE 39th Inter- national Conference on Distributed Computing Systems (ICDCS)
Chen, Q., Tang, S., Yang, Q., Fu, S.: Cooper: Cooperative perception for con- nected autonomous vehicles based on 3d point clouds. In: 2019 IEEE 39th Inter- national Conference on Distributed Computing Systems (ICDCS). pp. 514–524. IEEE (2019)
2019
-
[3]
AAAI35(2021)
Deng, J., Shi, S., Li, P., Zhou, W., Zhang, Y., Li, H.: Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection. AAAI35(2021)
2021
-
[4]
IEEE Transactions on Intelligent Vehicles (2024)
Gao, X., Zhang, X., Lu, Y., Huang, Y., Yang, L., Xiong, Y., Liu, P.: A survey of collaborative perception in intelligent vehicles at intersections. IEEE Transactions on Intelligent Vehicles (2024)
2024
-
[5]
In: 2021 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS)
Glaser, N., Liu, Y.C., Tian, J., Kira, Z.: Overcoming obstructions via bandwidth- limited multi-agent spatial handshaking. In: 2021 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS). pp. 2406–2413. IEEE (2021)
2021
-
[6]
IEEE Intelligent Trans- portation Systems Magazine15(6), 131–151 (2023)
Han, Y., Zhang, H., Li, H., Jin, Y., Lang, C., Li, Y.: Collaborative perception in autonomous driving: Methods, datasets, and challenges. IEEE Intelligent Trans- portation Systems Magazine15(6), 131–151 (2023)
2023
-
[7]
Advances in neural information processing systems35, 4874–4886 (2022)
Hu, Y., Fang, S., Lei, Z., Zhong, Y., Chen, S.: Where2comm: Communication- efficient collaborative perception via spatial confidence maps. Advances in neural information processing systems35, 4874–4886 (2022)
2022
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, X., Wang, J., Xia, Q., Chen, S., Yang, B., Li, X., Wang, C., Wen, C.: V2x-r: Cooperative lidar-4d radar fusion with denoising diffusion for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 27390–27400 (June 2025)
2025
-
[9]
In: Proceed- ingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.2409–2416(2024)
Huang, X., Wu, H., Li, X., Fan, X., Wen, C., Wang, C.: Sunshine to rainstorm: Cross-weather knowledge distillation for robust 3d object detection. In: Proceed- ingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.2409–2416(2024)
2024
-
[10]
In: Proceedings of the AAAI conference on artificial intelligence
Huang, X., Xu, Z., Wu, H., Wang, J., Xia, Q., Xia, Y., Li, J., Gao, K., Wen, C., Wang, C.: L4dr: Lidar-4dradar fusion for weather-robust 3d object detection. In: Proceedings of the AAAI conference on artificial intelligence. vol. 39, pp. 3806–3814 (2025)
2025
-
[11]
IEEE Transactions on Intelligent Transportation Systems (2024)
Li, J., Wang, Z., Gong, D., Wang, C.: Scnet3d: Rethinking the feature extrac- tion process of pillar-based 3d object detection. IEEE Transactions on Intelligent Transportation Systems (2024)
2024
-
[12]
In:ProceedingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.3208– 3215 (2024)
Li, X., Yin, J., Li, W., Xu, C., Yang, R., Shen, J.: Di-v2x: Learning domain- invariantrepresentationforvehicle-infrastructurecollaborative3dobjectdetection. In:ProceedingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.3208– 3215 (2024)
2024
-
[13]
Advances in Neural Information Processing Systems34, 29541–29552 (2021)
Li, Y., Ren, S., Wu, P., Chen, S., Feng, C., Zhang, W.: Learning distilled collabora- tion graph for multi-agent perception. Advances in Neural Information Processing Systems34, 29541–29552 (2021)
2021
-
[14]
IEEE Signal Pro- cessing Magazine37(4), 50–61 (2020)
Li, Y., Ibanez-Guzman, J.: Lidar for autonomous driving: The principles, chal- lenges, and trends for automotive lidar and perception systems. IEEE Signal Pro- cessing Magazine37(4), 50–61 (2020)
2020
-
[15]
IEEE Transactions on Intelligent Vehicles9(1), 1490–1500 (2023) 16 J
Li, Z., Liang, H., Wang, H., Zhao, M., Wang, J., Zheng, X.: Mkd-cooper: Coop- erative 3d object detection for autonomous driving via multi-teacher knowledge distillation. IEEE Transactions on Intelligent Vehicles9(1), 1490–1500 (2023) 16 J. Wang et al
2023
-
[16]
arXiv preprint arXiv:2308.16714 (2023)
Liu, S., Gao, C., Chen, Y., Peng, X., Kong, X., Wang, K., Xu, R., Jiang, W., Xiang, H., Ma, J., et al.: Towards vehicle-to-everything autonomous driving: A survey on collaborative perception. arXiv preprint arXiv:2308.16714 (2023)
-
[17]
arXiv preprint arXiv:2211.07214 (2022)
Lu, Y., Li, Q., Liu, B., Dianati, M., Feng, C., Chen, S., Wang, Y.: Robust collabora- tive 3d object detection in presence of pose errors. arXiv preprint arXiv:2211.07214 (2022)
-
[18]
International Journal of Computer Vision131(8), 1909– 1963 (2023)
Mao, J., Shi, S., Wang, X., Li, H.: 3d object detection for autonomous driving: A comprehensive survey. International Journal of Computer Vision131(8), 1909– 1963 (2023)
1909
-
[19]
IEEE Transactions on Intelligent Vehicles pp
Mao,W.,Wang,T.,Zhang,D.,Yan,J.,Yoshie,O.:Pillarnest:Embracingbackbone scaling and pretraining for pillar-based 3d object detection. IEEE Transactions on Intelligent Vehicles pp. 1–10 (2024).https://doi.org/10.1109/TIV.2024. 3386576
-
[20]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Qiao, D., Zulkernine, F.: Adaptive feature fusion for cooperative perception us- ing lidar point clouds. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1186–1195 (2023)
2023
-
[21]
In: Proceedings of the IEEE/CVF international conference on computer vision
Qin, Y., Wang, C., Kang, Z., Ma, N., Li, Z., Zhang, R.: Supfusion: Supervised lidar-camera fusion for 3d object detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22014–22024 (2023)
2023
-
[22]
IEEE Transactions on Intelligent Vehicles9(4), 4698–4714 (2024)
Ren, S., Lei, Z., Wang, Z., Dianati, M., Wang, Y., Chen, S., Zhang, W.: Interruption-aware cooperative perception for v2x communication-aided au- tonomous driving. IEEE Transactions on Intelligent Vehicles9(4), 4698–4714 (2024)
2024
-
[23]
Green energy and intelligent transportation2(3), 100092 (2023)
Ruan, J., Cui, H., Huang, Y., Li, T., Wu, C., Zhang, K.: A review of occluded objects detection in real complex scenarios for autonomous driving. Green energy and intelligent transportation2(3), 100092 (2023)
2023
-
[24]
In: CVPR (2020)
Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H.: PV-RCNN: Point- Voxel Feature Set Abstraction for 3D Object Detection. In: CVPR (2020)
2020
-
[25]
In: CVPR (2019)
Shi, S., Wang, X., Li, H.: PointRCNN: 3D Object Proposal Generation and De- tection From Point Cloud. In: CVPR (2019)
2019
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, W., Rajkumar, R.: Point-gnn: Graph neural network for 3d object detection in a point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1711–1719 (2020)
2020
-
[27]
Song, Z., Liu, L., Jia, F., Luo, Y., Jia, C., Zhang, G., Yang, L., Wang, L.: Robustness-aware 3d object detection in autonomous driving: A review and out- look. IEEE Transactions on Intelligent Transportation Systems25(11), 15407– 15436 (2024).https://doi.org/10.1109/TITS.2024.3439557
-
[28]
arXiv preprint arXiv:2209.08162 (2022)
Su, S., Li, Y., He, S., Han, S., Feng, C., Ding, C., Miao, F.: Uncertainty quantifi- cation of collaborative detection for self-driving. arXiv preprint arXiv:2209.08162 (2022)
-
[29]
Advances in Neural Information Processing Systems35, 38533–38545 (2022)
Wang, T., Hu, X., Liu, Z., Fu, C.W.: Sparse2dense: Learning to densify 3d features for 3d object detection. Advances in Neural Information Processing Systems35, 38533–38545 (2022)
2022
-
[30]
In: Proceedings of the European conference on computer vision (ECCV)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
2018
-
[31]
In: CVPR (2023)
Wu, H., Wen, C., Shi, S., Li, X., Wang, C.: Virtual Sparse Convolution for Multi- modal 3D Object Detection. In: CVPR (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Xia, Q., Deng, J., Wen, C., Wu, H., Shi, S., Li, X., Wang, C.: Coin: Contrastive instance feature mining for outdoor 3d object detection with very limited anno- C2E 17 tations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 6254–6263 (October 2023)
2023
-
[33]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xia, Q., Lin, W., Xiang, H., Huang, X., Chen, S., Dong, Z., Wang, C., Wen, C.: Learning to detect objects from multi-agent lidar scans without manual labels. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1418–1428 (2025)
2025
-
[34]
In: CVPR
Xia, Q., Ye, W., Wu, H., Zhao, S., Xing, L., Huang, X., Deng, J., Li, X., Wen, C., Wang, C.: Hinted: Hard instance enhanced detector with mixed-density feature fusion for sparsely-supervised 3d object detection. In: CVPR. pp. 15321–15330 (2024)
2024
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, J., Zhang, Y., Cai, Z., Huang, D.: Cosdh: Communication-efficient collabora- tive perception via supply-demand awareness and intermediate-late hybridization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6834–6843 (2025)
2025
-
[36]
arXiv preprint arXiv:2203.13168 (2022)
Xu, R., Chen, W., Xiang, H., Liu, L., Ma, J.: Model-agnostic multi-agent percep- tion framework. arXiv preprint arXiv:2203.13168 (2022)
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, R., Xia, X., Li, J., Li, H., Zhang, S., Tu, Z., Meng, Z., Xiang, H., Dong, X., Song, R., et al.: V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13712–13722 (2023)
2023
-
[38]
In: European confer- ence on computer vision
Xu, R., Xiang, H., Tu, Z., Xia, X., Yang, M.H., Ma, J.: V2x-vit: Vehicle-to- everything cooperative perception with vision transformer. In: European confer- ence on computer vision. pp. 107–124. Springer (2022)
2022
-
[39]
In: 2022 International Conference on Robotics and Automation (ICRA)
Xu, R., Xiang, H., Xia, X., Han, X., Li, J., Ma, J.: Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 2583–
2022
-
[40]
In: European conference on computer vision
Yan, X., Gao, J., Zheng, C., Zheng, C., Zhang, R., Cui, S., Li, Z.: 2dpass: 2d priors assisted semantic segmentation on lidar point clouds. In: European conference on computer vision. pp. 677–695. Springer (2022)
2022
-
[41]
Sensors18(2018)
Yan, Y., Mao, Y., Li, B.: SECOND: Sparsely Embedded Convolutional Detection. Sensors18(2018)
2018
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, C., Zhou, H., An, Z., Jiang, X., Xu, Y., Zhang, Q.: Cross-image rela- tional knowledge distillation for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12319– 12328 (2022)
2022
-
[43]
Advances in Neural Information Processing Systems36, 25151–25164 (2023)
Yang, D., Yang, K., Wang, Y., Liu, J., Xu, Z., Yin, R., Zhai, P., Zhang, L.: How2comm: Communication-efficient and collaboration-pragmatic multi-agent perception. Advances in Neural Information Processing Systems36, 25151–25164 (2023)
2023
-
[44]
In: Pro- ceedings of the 31st ACM international conference on multimedia
Yang, K., Yang, D., Zhang, J., Wang, H., Sun, P., Song, L.: What2comm: Towards communication-efficient collaborative perception via feature decoupling. In: Pro- ceedings of the 31st ACM international conference on multimedia. pp. 7686–7695 (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11784–11793 (June 2021)
2021
-
[46]
arXiv preprint arXiv:2410.02646 (2024) 18 J
Yoo, J., Feng, Z., Pan, T.Y., Sun, Y., Phoo, C.P., Chen, X., Campbell, M., Wein- berger, K.Q., Hariharan, B., Chao, W.L.: Learning 3d perception from others’ predictions. arXiv preprint arXiv:2410.02646 (2024) 18 J. Wang et al
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H., Luo, Y., Shu, M., Huo, Y., Yang, Z., Shi, Y., Guo, Z., Li, H., Hu, X., Yuan, J., Nie, Z.: Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21361–21370 (2022)
2022
-
[48]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, J., Wang, Y., Qian, L., Sun, P., Li, Z., Jiang, S., Liu, M., Song, L.: Dsrc: Learning density-insensitive and semantic-aware collaborative representa- tion against corruptions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9942–9950 (2025)
2025
-
[49]
arXiv preprint arXiv:2310.14702 (2023)
Zhao, B., Zhang, W., Zou, Z.: Bm2cp: Efficient collaborative perception with lidar- camera modalities. arXiv preprint arXiv:2310.14702 (2023)
-
[50]
arXiv preprint arXiv:2503.17097 (2025)
Zheng, B., Lu, S., Huang, R., Huang, M., Lu, F., Tian, W., Zhuo, G., Xiong, L.: R2ldm: An efficient 4d radar super-resolution framework leveraging diffusion model. arXiv preprint arXiv:2503.17097 (2025)
-
[51]
In: CVPR (2022)
Zheng, W., Hong, M., Jiang, L., Fu, C.W.: Boosting 3D Object Detection by Simulating Multimodality on Point Clouds. In: CVPR (2022)
2022
-
[52]
In: ACMMM (2022)
Zheng, W., Jiang, L., Lu, F., Ye, Y., Fu, C.W.: Boosting Single-Frame 3D Object Detection by Simulating Multi-Frame Point Clouds. In: ACMMM (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.