OntoLearner: A Modular Python Library for Ontology Learning with Large Language Models
Pith reviewed 2026-07-03 13:54 UTC · model grok-4.3
The pith
A library of 180 ontologies reveals that ontology learning failures scale with structural complexity rather than model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
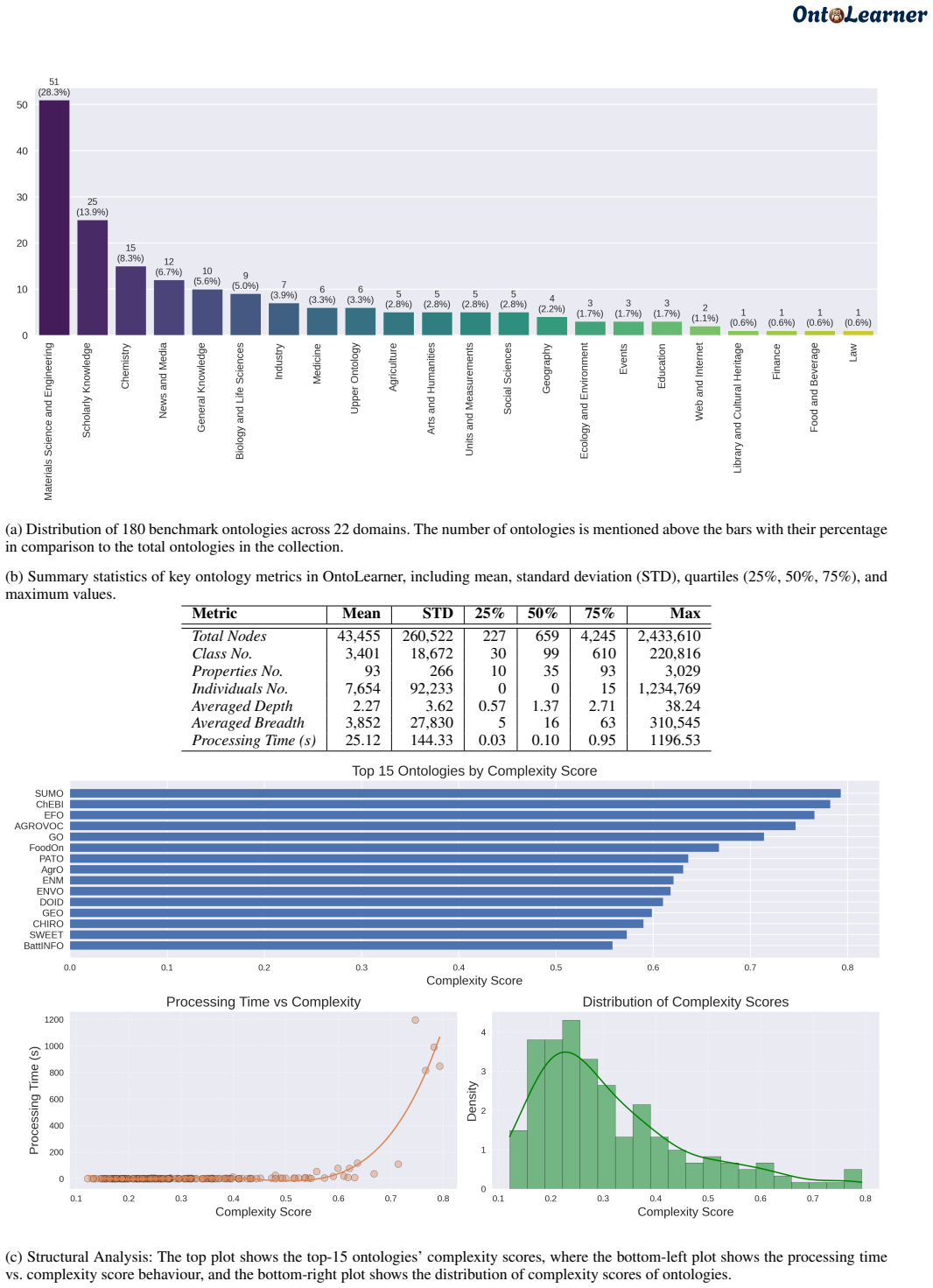
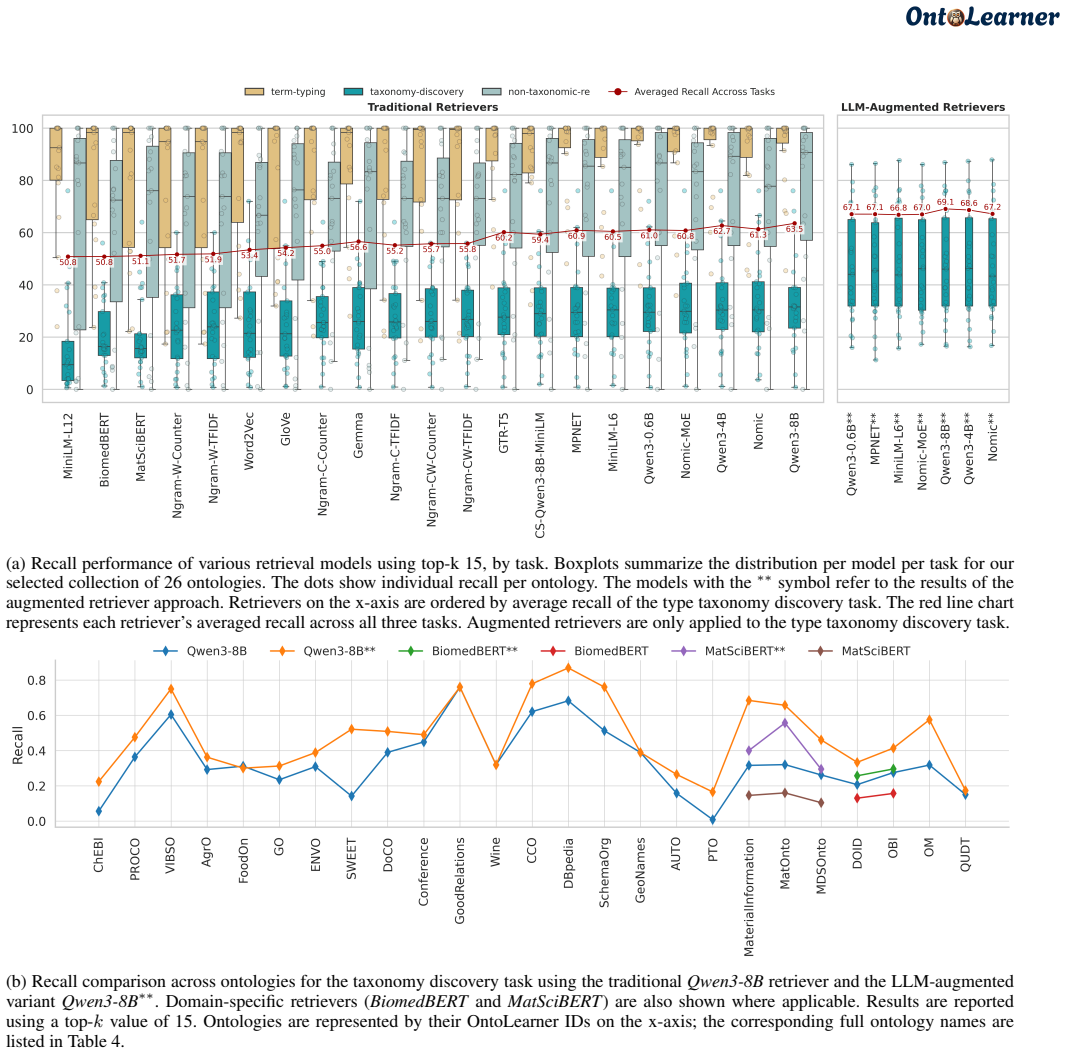
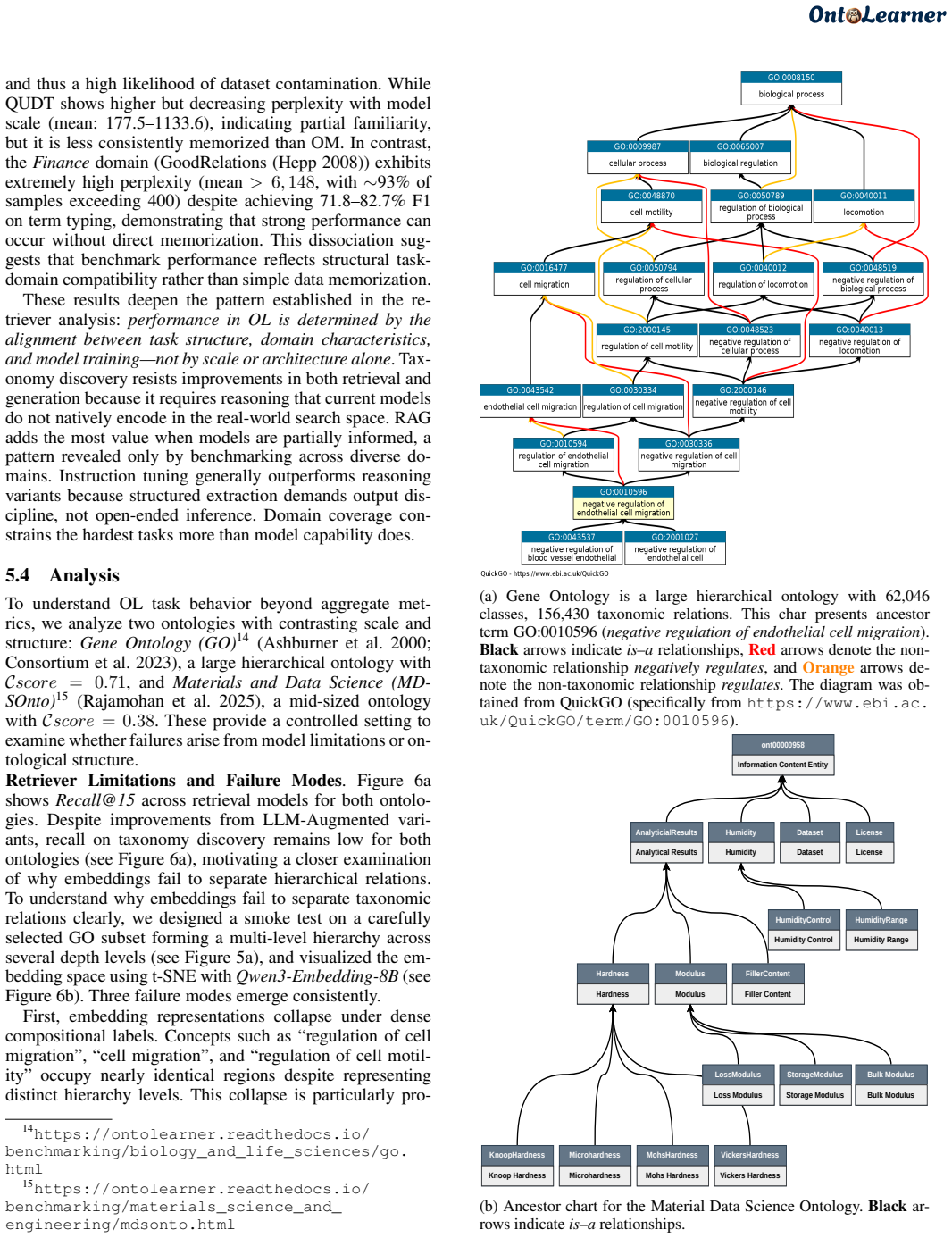
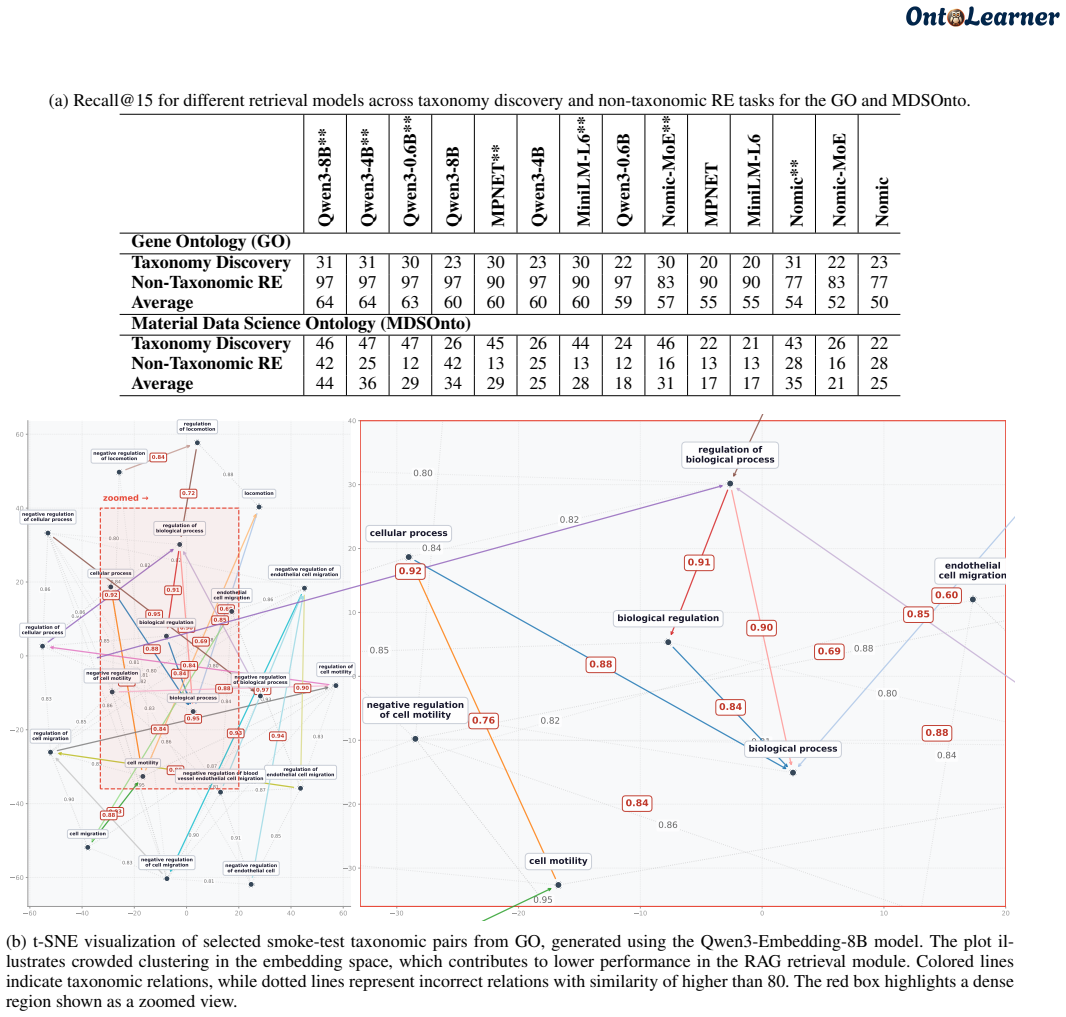
By providing a unified infrastructure with 180 ontologies and task-specific datasets, OntoLearner enables systematic study showing failure modes in ontology learning scale with ontological complexity rather than model size or sophistication. The central bottleneck identified is the structural mismatch between model-encoded knowledge and ontology organization.
What carries the argument
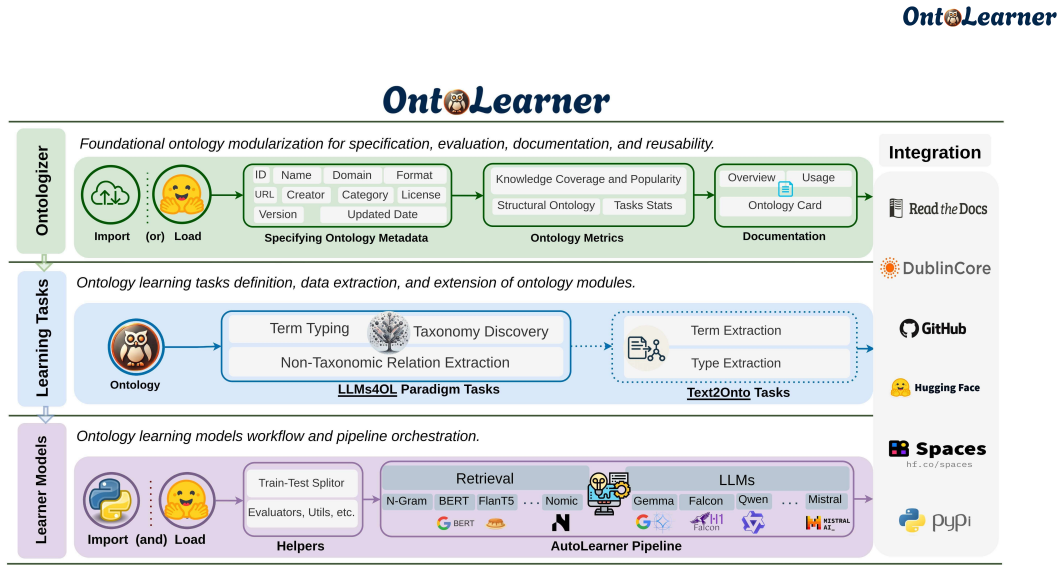
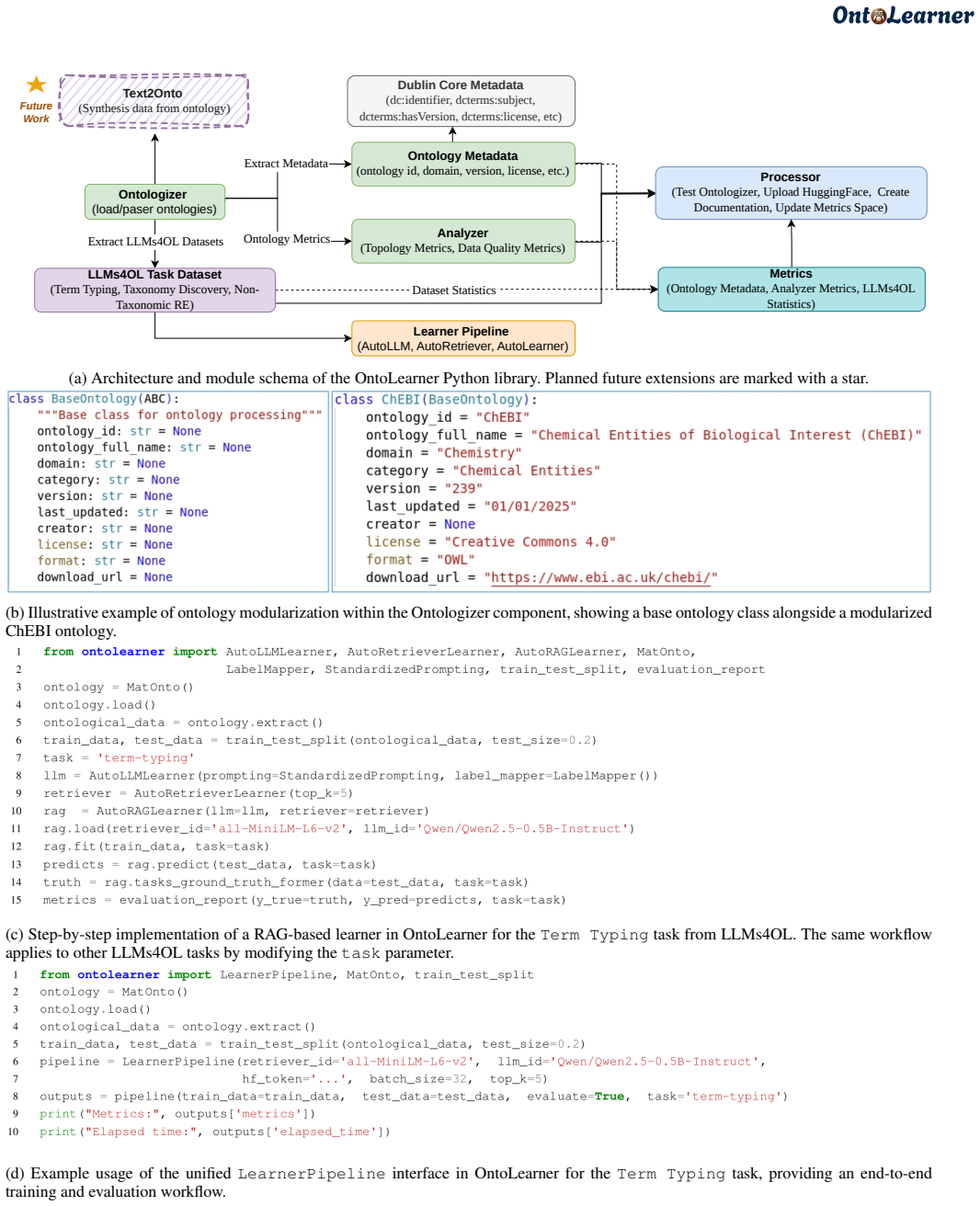
OntoLearner, the modular Python library that unifies access to ontologies, LLM-driven pipelines, and benchmarking across three core tasks.
If this is right
- Progress in ontology learning requires frameworks for systematic, cross-domain evaluation.
- Improving ontology construction depends on resolving mismatches in how knowledge is structured.
- Model improvements alone are insufficient without addressing ontological complexity.
- Multi-task and multi-domain testing exposes the true limits of current approaches.
Where Pith is reading between the lines
- Architectures that align more closely with hierarchical and relational structures could improve performance on complex ontologies.
- Expanding the library to include more ontologies from underrepresented domains would test the robustness of the complexity finding.
- Applying similar benchmarking to other structured knowledge tasks might uncover parallel mismatches.
Load-bearing premise
The 180 ontologies and three tasks sufficiently represent the general challenges of ontology learning across domains.
What would settle it
A study where model performance on high-complexity ontologies improves substantially with increased model size or new architectures, without corresponding changes to address structural mismatch.
Figures

read the original abstract
Ontology learning (OL) aims to automatically construct structured knowledge models from text, yet progress remains fragmented across methods, domains, and evaluation practices. Despite decades of research, OL lacks a shared infrastructure for systematic evaluation and ontology access. This absence has hindered progress and fragmented research, leaving the central challenges of OL largely unaddressed. We introduce OntoLearner, a modular, cross-domain, and first-of-its-kind framework that unifies ontology access, large language model (LLM)-driven learning pipelines, and standardized benchmarking. OntoLearner releases 180 machine-readable ontologies spanning 22 domains and provides pipeline-ready datasets with train/dev/test splits for three core OL tasks: term typing, taxonomy discovery, and non-taxonomic relation extraction. Using this infrastructure, we conduct a large-scale empirical study of OL, evaluating 22 retrieval models and 12 LLMs across domains and tasks. The results converge on a finding that reframes the central challenge of OL: failure modes scale with ontological complexity rather than model size or architectural sophistication. The primary bottleneck is not model capability, but a structural mismatch between how models encode knowledge and how ontologies organize it. These findings establish that effective OL is reachable through the cross-domain, multi-task benchmarking enabled by OntoLearner. OntoLearner is open-source (MIT license) at https://github.com/sciknoworg/OntoLearner/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OntoLearner, a modular Python library for ontology learning with LLMs. It releases 180 machine-readable ontologies spanning 22 domains together with train/dev/test splits for three core tasks (term typing, taxonomy discovery, non-taxonomic relation extraction), then benchmarks 22 retrieval models and 12 LLMs. The central empirical claim is that failure modes scale with ontological complexity rather than model size or architectural sophistication, with the primary bottleneck being a structural mismatch between how models encode knowledge and how ontologies organize it.
Significance. If the scaling result holds under proper controls, the work supplies reusable infrastructure and a cross-domain benchmark that could reduce fragmentation in ontology learning research. The released datasets and library (MIT license) constitute a concrete contribution that enables future reproducible comparisons; the reframing of the bottleneck away from raw model scale is potentially actionable for method development.
major comments (2)
- [Data / Methods] Data / Methods section: the claim that failure modes scale with ontological complexity (rather than model size) is load-bearing for the central finding, yet the manuscript supplies no selection criteria for the 180 ontologies, no stratification by complexity metrics such as depth, axiom density or relation arity, and no evidence that the set is not convenience-sampled. Without these details the observed scaling could be an artifact of corpus bias rather than a general property of OL.
- [Results / Evaluation] Results / Evaluation: the abstract asserts that failure modes scale with ontological complexity and that the bottleneck is structural mismatch, but provides no information on how ontological complexity was quantified, which statistical controls were applied, or how prompt and retrieval setups were standardized across the 22+12 models. These omissions prevent assessment of support for the claim.
minor comments (1)
- [Abstract] Abstract: the phrasing 'first-of-its-kind framework' should be accompanied by citations to prior ontology-learning toolkits or benchmarking efforts to substantiate novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve transparency and support for the central claims.
read point-by-point responses
-
Referee: [Data / Methods] Data / Methods section: the claim that failure modes scale with ontological complexity (rather than model size) is load-bearing for the central finding, yet the manuscript supplies no selection criteria for the 180 ontologies, no stratification by complexity metrics such as depth, axiom density or relation arity, and no evidence that the set is not convenience-sampled. Without these details the observed scaling could be an artifact of corpus bias rather than a general property of OL.
Authors: We agree that the current manuscript lacks explicit documentation of selection criteria and stratification, which is needed to rule out sampling artifacts. In the revised version we will add a new subsection under Data describing the collection process (public repositories, domain coverage requirements, machine-readability filters), provide descriptive statistics, and include stratification tables and plots by depth, axiom density, and relation arity. We will also report the distribution of these metrics across the 180 ontologies to allow readers to evaluate potential bias. revision: yes
-
Referee: [Results / Evaluation] Results / Evaluation: the abstract asserts that failure modes scale with ontological complexity and that the bottleneck is structural mismatch, but provides no information on how ontological complexity was quantified, which statistical controls were applied, or how prompt and retrieval setups were standardized across the 22+12 models. These omissions prevent assessment of support for the claim.
Authors: We accept that the manuscript must supply these details for the scaling claim to be evaluable. The revision will expand the Results section to: (1) define the exact complexity metrics used (depth, axiom count, arity, etc.) and how they were computed from the OWL files, (2) report the regression or correlation analyses with controls for model size/parameters, and (3) document the fixed prompt templates, retrieval hyperparameters, and evaluation scripts applied uniformly across all 22 retrieval models and 12 LLMs. These additions will be placed before the main empirical results. revision: yes
Circularity Check
No circularity: empirical benchmarking release with no derivation chain
full rationale
The paper introduces an open-source library and releases 180 ontologies plus task datasets for benchmarking 22 retrieval models and 12 LLMs. Its central claim (failure modes scale with ontological complexity) is an empirical observation drawn from those external, released resources rather than any internal equation, fitted parameter, or self-citation chain. No mathematical derivation, ansatz, uniqueness theorem, or self-definitional step exists; the work is infrastructure and experiment reporting. The representativeness concern raised by the skeptic is a validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 180 ontologies and three task definitions capture the central challenges of ontology learning across domains.
Reference graph
Works this paper leans on
-
[1]
[Auer et al
Agriculturalsemantics/agro: November 2022 release. [Auer et al. 2007] Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; and Ives, Z. 2007. Dbpedia: A nucleus for a web of open data. Ininternational semantic web conference, 722–735. Springer. [Babaei Giglou et al. 2025] Babaei Giglou, H.; D’Souza, J.; Mihindukulasooriya, N.; and Auer, S. 2025....
2022
-
[2]
[Beliaeva and Rahmatullaev 2025] Beliaeva, A., and Rah- matullaev, T
The ontology for biomedical investigations.PloS one 11(4):e0154556. [Beliaeva and Rahmatullaev 2025] Beliaeva, A., and Rah- matullaev, T. 2025. Alexbek at llms4ol 2025 tasks a, b, and c: Heterogeneous llm methods for ontology learning (few- shot prompting, ensemble typing, and attention-based tax- onomies). InOpen Conference Proceedings, volume 6. [Bhuyan...
-
[3]
[Buttigieg et al
The environment ontology: contextualising biological and biomedical entities.Journal of biomedical semantics 4(1):43. [Buttigieg et al. 2016] Buttigieg, P. L.; Pafilis, E.; Lewis, S. E.; Schildhauer, M. P.; Walls, R. L.; and Mungall, C. J
2016
-
[4]
Journal of biomedical semantics7(1):57
The environment ontology in 2016: bridging domains with increased scope, semantic density, and interoperation. Journal of biomedical semantics7(1):57. [Carlson et al. 2010] Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.; and Mitchell, T. 2010. Toward an architecture for never-ending language learning. InPro- ceedings of the AAAI confer...
2016
-
[5]
InInternational conference on application of natural language to information systems, 227–238
Text2onto: A framework for ontology learning and data-driven change discovery. InInternational conference on application of natural language to information systems, 227–238. Springer. [Consortium et al. 2023] Consortium, T. G. O.; Aleksander, S. A.; Balhoff, J.; Carbon, S.; Cherry, J. M.; Drabkin, H. J.; Ebert, D.; Feuermann, M.; Gaudet, P.; Harris, N. L....
2023
-
[6]
InThe 32nd International Joint Conference on Artificial Intelli- gence, IJCAI 2023
Neuro-symbolic class expression learning. InThe 32nd International Joint Conference on Artificial Intelli- gence, IJCAI 2023. [Demir et al. 2025] Demir, C.; Baci, A.; Kouagou, N. J.; Sieger, L. N.; Heindorf, S.; Bin, S.; Bl¨ubaum, L.; Bigerl, A.; and Ngomo, A.-C. N. 2025. Ontolearn—a framework for large-scale owl class expression learning in python.Journa...
2023
-
[7]
Description: Structured knowledge graph of over 10 bil- lion public web entities with 50+ data fields for news, orga- nizations, people, products, and more. [Dong et al. 2024] Dong, Y .; Jiang, X.; Liu, H.; Jin, Z.; Gu, B.; Yang, M.; and Li, G. 2024. Generalization or memo- rization: Data contamination and trustworthy evaluation for large language models....
-
[8]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Simcse: Simple contrastive learning of sentence em- beddings.arXiv preprint arXiv:2104.08821. [Gatto 2025] Gatto, L. 2025. An r interface to the ontology lookup service.https://www.bioconductor. org/packages/devel/bioc/vignettes/rols/ inst/doc/rols.html. Bioconductor vignette, accessed May 3, 2025. [Giglou et al. 2025] Giglou, H. B.; D’Souza, J.; Mihinduk...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
A hierarchy of hop-indexed models for the capaci- tated minimum spanning tree problem.Networks: An Inter- national Journal35(1):1–16. [Grac ¸a et al. 2005] Grac ¸a, J.; Mourao, M.; Anunciac ¸˜ao, O.; Monteiro, P.; Pinto, H. S.; and Loureiro, V . 2005. Ontology building process: the wine domain. InProc. of the 5th Conf. of EFITA. [Gu et al. 2021] Gu, Y .; ...
-
[10]
[Jupp et al
Singapore: Association for Computational Linguis- tics. [Jupp et al. 2015] Jupp, S.; Burdett, T.; Leroy, C.; and Parkinson, H. E. 2015. A new ontology lookup service at embl-ebi.SWAT4LS2:118–119. [Kamath et al. 2025] Kamath, A.; Ferret, J.; Pathak, S.; Vieillard, N.; Merhej, R.; Perrin, S.; Matejovicova, T.; Ram´e, A.; Rivi`ere, M.; Rouillard, L.; et al. ...
2015
-
[11]
Comparison and evaluation of ontologies for units of measurement.Semantic Web10(1):33–51. [Kommineni, K¨onig-Ries, and Samuel 2024] Kommineni, V . K.; K¨onig-Ries, B.; and Samuel, S. 2024. From human experts to machines: An llm supported approach to ontology and knowledge graph construction.CoRR. [Kraft, Engel, and Koepler 2023] Kraft, A.; Engel, F.; and ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
[Machina and Mercer 2024] Machina, A., and Mercer, R
End-to-end ontology learning with large language models.Advances in Neural Information Processing Sys- tems37:87184–87225. [Machina and Mercer 2024] Machina, A., and Mercer, R
2024
-
[13]
Anisotropy is not inherent to transformers. In Duh, K.; Gomez, H.; and Bethard, S., eds.,Proceedings of the 2024 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 4892–4907. Mexico City, Mexico: Association for Computational Linguistics. [Maedche 2002] Maedche,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Large dual encoders are generalizable retrievers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 9844–9855. [Nicolajsen 2025] Nicolajsen, S. M. 2025. Extensibility in programming languages: An overview.CoRR1–12. [Nielsen and Hansen 2024] Nielsen, B. M. G., and Hansen, L. K. 2024. Hubness reduction improves sente...
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Poolparty extractor – graph-based text mining at the highest level.https://www.poolparty.biz/ poolparty-extractor. Accessed: 2026-01-27. Pool- Party Extractor is an intelligent semantic text mining tool that combines natural language processing and machine learning with knowledge graph–based concept extraction to analyze and enrich unstructured text. [Sin...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Probase: A probabilistic taxonomy for text under- standing. InProceedings of the 2012 ACM SIGMOD in- ternational conference on management of data, 481–492. [Yang and Chen 2025] Yang, H., and Chen, J. 2025. Achiev- ing hyperbolic-like expressiveness with arbitrary euclidean regions: A new approach to hierarchical embeddings. [Yang et al. 2025] Yang, A.; Li...
work page internal anchor Pith review Pith/arXiv arXiv 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.