Smaller Text Classifiers with Discriminative Cluster Embeddings
Pith reviewed 2026-05-25 18:05 UTC · model grok-4.3
The pith
Text classifiers shrink by learning hard word clusters end-to-end with the task loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By maximizing over latent word-to-cluster assignments with the Gumbel-Softmax distribution while minimizing the downstream task loss, the method produces a hard clustering that replaces individual word embeddings with shared cluster embeddings, yielding smaller classifiers; optional per-word parameter additions further improve accuracy at modest extra cost.
What carries the argument
Gumbel-Softmax relaxation that selects discrete cluster assignments for each word while the entire model is trained on the classification loss.
If this is right
- Deployed text classifiers require substantially less memory for the embedding table at comparable accuracy.
- The resulting clusters are task-specific rather than generic.
- Accuracy-size trade-offs can be tuned by assigning extra parameters only to selected words.
- The approach applies directly to any neural text classifier whose size is dominated by the embedding matrix.
Where Pith is reading between the lines
- The same clustering mechanism could be tested on sequence labeling or generation tasks where embedding size also dominates.
- Combining the cluster embeddings with other compression methods such as quantization might yield further reductions.
- The learned clusters might reveal task-specific semantic groupings that differ from those produced by unsupervised methods.
Load-bearing premise
The Gumbel-Softmax approximation stays close enough to true hard clustering that the joint optimization produces useful discrete assignments.
What would settle it
A controlled experiment in which models trained with the learned clusters show no accuracy gain over models that use the same number of randomly chosen or fixed clusters at identical parameter budgets would falsify the central claim.
Figures

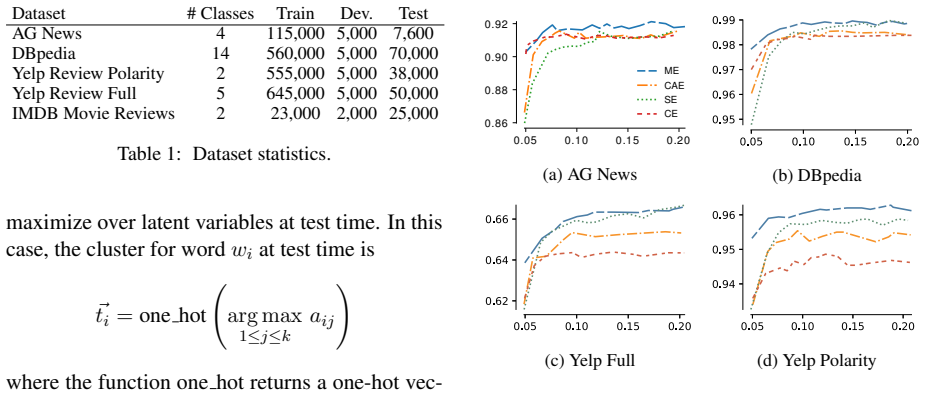
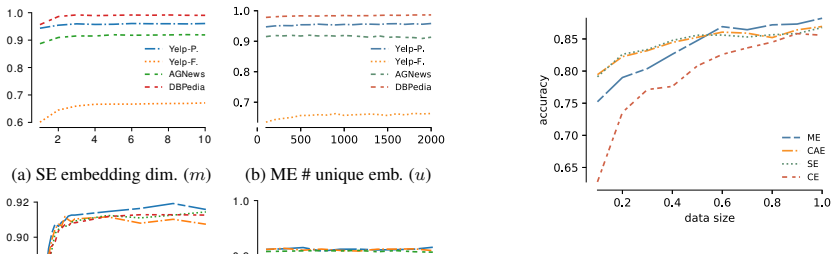
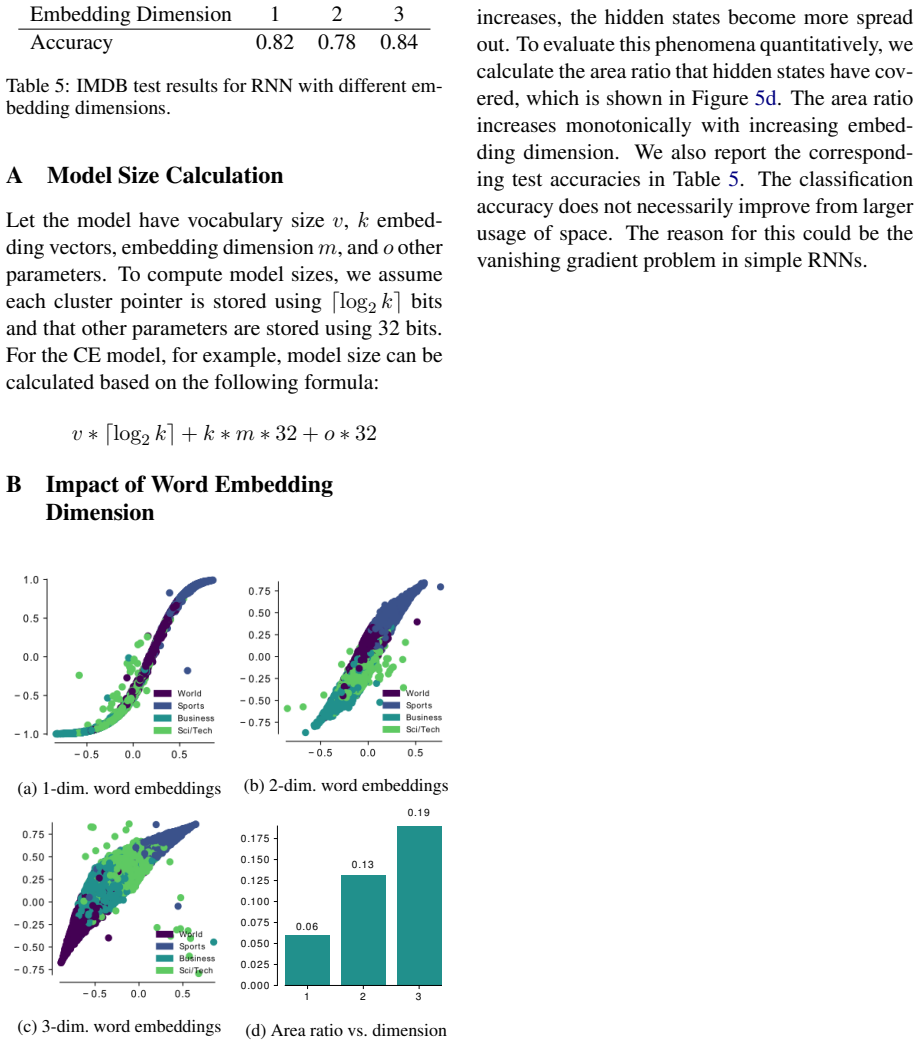
read the original abstract
Word embedding parameters often dominate overall model sizes in neural methods for natural language processing. We reduce deployed model sizes of text classifiers by learning a hard word clustering in an end-to-end manner. We use the Gumbel-Softmax distribution to maximize over the latent clustering while minimizing the task loss. We propose variations that selectively assign additional parameters to words, which further improves accuracy while still remaining parameter-efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that word embedding parameters dominate model sizes in neural NLP, and proposes to reduce deployed sizes of text classifiers by learning a hard word-to-cluster assignment end-to-end via the Gumbel-Softmax distribution (maximizing over the latent clustering while minimizing task loss). It also introduces variations that selectively assign extra parameters to individual words while remaining parameter-efficient.
Significance. If the method reliably produces near-discrete assignments, it would offer a practical route to smaller deployed text classifiers by replacing a V-by-d embedding matrix with a K-by-d matrix (plus a small assignment table). The end-to-end discriminative training of the clustering is a clear strength relative to post-hoc clustering approaches.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: the central size-reduction claim requires that the Gumbel-Softmax relaxation converge to sufficiently hard (near one-hot) assignments so that only K embeddings are stored at inference; the manuscript provides no guarantee, temperature schedule, or post-training discretization procedure that would ensure the effective parameter count is K·d rather than closer to V·d.
- [Method section (Gumbel-Softmax formulation)] Method section (Gumbel-Softmax formulation): without an explicit analysis or ablation showing that the learned cluster-assignment entropy is low (or that the straight-through estimator yields discrete behavior at test time), the claimed compression benefit remains unsecured even if task accuracy is preserved.
minor comments (1)
- The abstract states that selective additional parameters 'further improves accuracy' but does not indicate the criterion used to decide which words receive extra parameters.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to secure the parameter-efficiency claim through explicit analysis of assignment hardness. We address both major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: the central size-reduction claim requires that the Gumbel-Softmax relaxation converge to sufficiently hard (near one-hot) assignments so that only K embeddings are stored at inference; the manuscript provides no guarantee, temperature schedule, or post-training discretization procedure that would ensure the effective parameter count is K·d rather than closer to V·d.
Authors: We agree that the size-reduction claim depends on near-discrete assignments at inference. The original manuscript describes the Gumbel-Softmax but does not detail the temperature schedule or a discretization step. In the revision we will add: (1) the annealing schedule used (starting at τ=1.0 and decaying to 0.1), (2) the explicit post-training procedure of taking argmax over the learned assignment logits for each word, and (3) a statement that only the K cluster embeddings plus the resulting V-to-K lookup table are stored at deployment. We will also report the final average assignment entropy on the test sets. revision: yes
-
Referee: [Method section (Gumbel-Softmax formulation)] Method section (Gumbel-Softmax formulation): without an explicit analysis or ablation showing that the learned cluster-assignment entropy is low (or that the straight-through estimator yields discrete behavior at test time), the claimed compression benefit remains unsecured even if task accuracy is preserved.
Authors: We acknowledge the absence of such an ablation. The revision will include a new subsection with: (a) plots of assignment entropy versus temperature and training epoch, (b) comparison of straight-through vs. soft Gumbel-Softmax at test time, and (c) measured compression ratios (effective parameters = K·d + V·log₂K bits for the assignment table) on the reported datasets. These additions will directly address the concern that the compression benefit may not be realized. revision: yes
Circularity Check
No circularity; proposal is a new training procedure with independent content
full rationale
The paper introduces an end-to-end optimization for hard word clustering via Gumbel-Softmax to reduce embedding parameters at deployment. No equations or claims reduce to fitted quantities defined within the paper itself, no self-citation chains justify core premises, and no predictions are statistically forced by construction from inputs. The method applies an established external relaxation technique to a task loss without renaming known results or smuggling ansatzes. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter doi edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Mart\' n Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Man\' e , Rajat Monga, Sherry Moore, Derek...
work page 2015
-
[4]
Yoshua Bengio, R \'e jean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A neural probabilistic language model. Journal of machine learning research\/ 3(Feb):1137--1155
work page 2003
-
[5]
Jan A. Botha, Emily Pitler, Ji Ma, Anton Bakalov, Alex Salcianu, David Weiss, Ryan McDonald, and Slav Petrov. 2017. Natural language processing with small feed-forward networks http://aclweb.org/anthology/D17-1309. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing\/ . Association for Computational Linguistics, pages...
work page 2017
-
[6]
Peter F. Brown, Peter V. deSouza, Robert L. Mercer, T. J. Watson, Vincent J. Della Pietra, and Jenifer C. Lai. 1992. Class-based n-gram models of natural language http://www.aclweb.org/anthology/J92-4003. Computational Linguistics\/ 18(4). http://www.aclweb.org/anthology/J92-4003 http://www.aclweb.org/anthology/J92-4003
work page 1992
-
[7]
Song Han, Huizi Mao, and William J Dally. 2016. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In International Conference on Learning Representations\/
work page 2016
-
[8]
Song Han, Jeff Pool, John Tran, and William Dally. 2015. Learning both weights and connections for efficient neural network http://papers.nips.cc/paper/5784-learning-both-weights-and-connections-for-efficient-neural-network.pdf. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems...
work page 2015
-
[9]
Sepp Hochreiter and J \"u rgen Schmidhuber. 1997. Long short-term memory. Neural computation\/ 9(8):1735--1780
work page 1997
-
[10]
Eric Jang, Shixiang Gu, and Ben Poole. 2016. Categorical reparameterization with G umbel-softmax. In International Conference on Learning Representations\/
work page 2016
-
[11]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2011. Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis and Machine Intelligence\/ 33(1):117--128
work page 2011
-
[12]
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Herv \'e J \'e gou, and Tomas Mikolov. 2017. Fasttext.zip: Compressing text classification models. In International Conference on Learning Representations\/
work page 2017
-
[13]
Yoon Kim. 2014. Convolutional neural networks for sentence classification https://doi.org/10.3115/v1/D14-1181. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP)\/ . Association for Computational Linguistics, pages 1746--1751. https://doi.org/10.3115/v1/D14-1181 https://doi.org/10.3115/v1/D14-1181
-
[14]
Diederik Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations\/
work page 2015
-
[15]
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis http://www.aclweb.org/anthology/P11-1015. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies\/ . Association for Computational Linguistics, p...
work page 2011
-
[16]
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. 2016. The concrete distribution: A continuous relaxation of discrete random variables. In International Conference on Learning Representations\/
work page 2016
-
[17]
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. https://doi.org/10.3115/v1/D14-1162 GloVe : Global vectors for word representation . In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP)\/ . Association for Computational Linguistics, pages 1532--1543. https://doi.org/10.3115/v1/D14-1162 https:...
-
[18]
Raphael Shu and Hideki Nakayama. 2018. Compressing word embeddings via deep compositional code learning. In International Conference on Learning Representations\/
work page 2018
-
[19]
Dan Tito Svenstrup, Jonas Hansen, and Ole Winther. 2017. Hash embeddings for efficient word representations http://papers.nips.cc/paper/7078-hash-embeddings-for-efficient-word-representations.pdf. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30\/ ,...
work page 2017
-
[20]
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification http://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text-classification.pdf. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28\/ , Curran Ass...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.