Improving Description-based Person Re-identification by Multi-granularity Image-text Alignments
Pith reviewed 2026-05-25 17:37 UTC · model grok-4.3
The pith
Multi-granularity alignments between images and texts improve description-based person re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
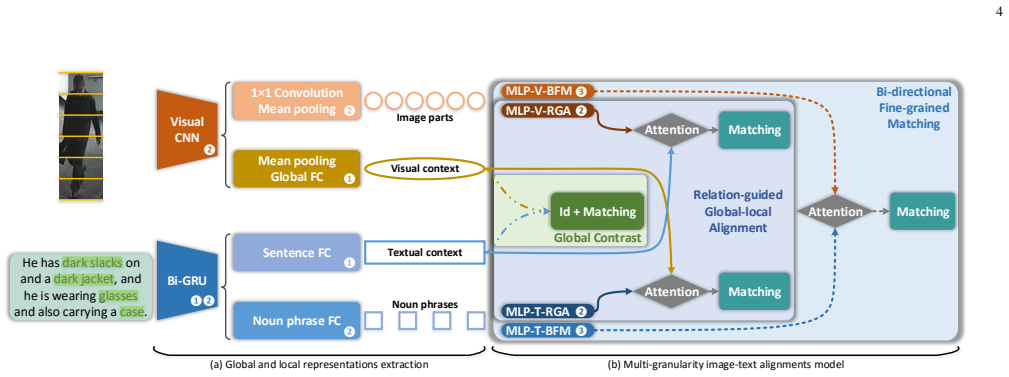
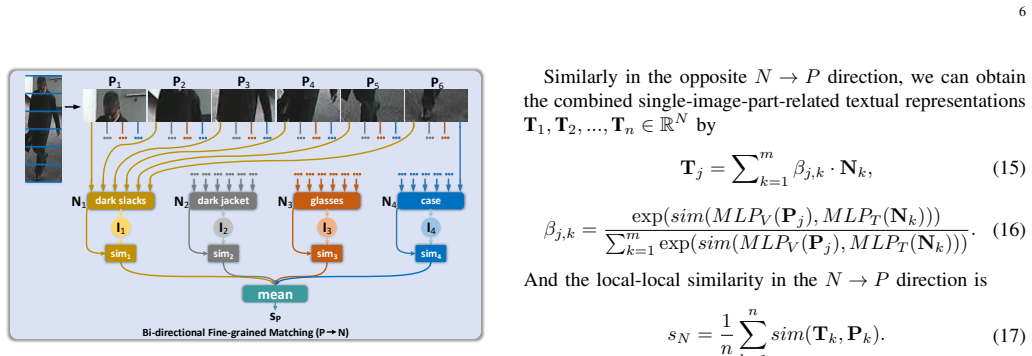
The Multi-granularity Image-text Alignments (MIA) model alleviates the cross-modal fine-grained problem by carrying out global-global alignment in the Global Contrast module, global-local alignment in the Relation-guided Global-local Alignment module, and local-local alignment in the Bi-directional Fine-grained Matching module, with the full network trained end-to-end via a step training strategy to reach state-of-the-art performance on the CUHK-PEDES dataset.
What carries the argument
The Multi-granularity Image-text Alignments (MIA) model, which hierarchically executes global-global, global-local, and local-local alignments through the Global Contrast, Relation-guided Global-local Alignment, and Bi-directional Fine-grained Matching modules.
If this is right
- Global-global alignment matches the overall contexts of images and descriptions.
- Global-local alignment adaptively highlights distinguishable components while suppressing uninvolved ones.
- Local-local alignment directly matches visual human parts to noun phrases in the description.
- The step training strategy overcomes the training difficulties that arise when combining the three granularities.
Where Pith is reading between the lines
- The same hierarchical alignment pattern could be tested on other cross-modal retrieval tasks that involve fine details, such as attribute-based image search.
- The adaptive component highlighting might reduce sensitivity to extraneous words in longer or noisier descriptions.
- End-to-end training without extra pre-processing steps suggests the modules could be inserted into larger video surveillance pipelines with minimal added overhead.
Load-bearing premise
The combination of multiple granularities can be effectively trained using the proposed step training strategy without complex pre-processing.
What would settle it
Implementing the three alignment modules on the CUHK-PEDES dataset and obtaining accuracy no higher than the best prior single-granularity method would falsify the central performance claim.
Figures







read the original abstract
Description-based person re-identification (Re-id) is an important task in video surveillance that requires discriminative cross-modal representations to distinguish different people. It is difficult to directly measure the similarity between images and descriptions due to the modality heterogeneity (the cross-modal problem). And all samples belonging to a single category (the fine-grained problem) makes this task even harder than the conventional image-description matching task. In this paper, we propose a Multi-granularity Image-text Alignments (MIA) model to alleviate the cross-modal fine-grained problem for better similarity evaluation in description-based person Re-id. Specifically, three different granularities, i.e., global-global, global-local and local-local alignments are carried out hierarchically. Firstly, the global-global alignment in the Global Contrast (GC) module is for matching the global contexts of images and descriptions. Secondly, the global-local alignment employs the potential relations between local components and global contexts to highlight the distinguishable components while eliminating the uninvolved ones adaptively in the Relation-guided Global-local Alignment (RGA) module. Thirdly, as for the local-local alignment, we match visual human parts with noun phrases in the Bi-directional Fine-grained Matching (BFM) module. The whole network combining multiple granularities can be end-to-end trained without complex pre-processing. To address the difficulties in training the combination of multiple granularities, an effective step training strategy is proposed to train these granularities step-by-step. Extensive experiments and analysis have shown that our method obtains the state-of-the-art performance on the CUHK-PEDES dataset and outperforms the previous methods by a significant margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Multi-granularity Image-text Alignments (MIA) model for description-based person re-identification to address cross-modal and fine-grained challenges. It hierarchically applies global-global alignment via the Global Contrast (GC) module, global-local alignment via the Relation-guided Global-local Alignment (RGA) module, and local-local alignment via the Bi-directional Fine-grained Matching (BFM) module. The model is trained end-to-end using a proposed step training strategy to handle difficulties in combining the granularities, and the abstract claims state-of-the-art performance on the CUHK-PEDES dataset that significantly outperforms prior methods.
Significance. If the performance claims and the contribution of the multi-granularity alignments hold after verification, the work would provide a concrete hierarchical approach to cross-modal matching that could improve similarity evaluation in fine-grained person re-identification tasks.
major comments (1)
- [Abstract] The abstract states that joint training of the three granularities is difficult and therefore introduces the step training strategy, yet supplies no ablation results, quantitative comparisons, or evidence that end-to-end joint optimization fails or that the reported margins disappear without the schedule. This directly affects the central claim that the MIA model (GC + RGA + BFM) obtains its gains via the alignments rather than the training schedule.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the major comment below and agree that additional clarification is warranted.
read point-by-point responses
-
Referee: [Abstract] The abstract states that joint training of the three granularities is difficult and therefore introduces the step training strategy, yet supplies no ablation results, quantitative comparisons, or evidence that end-to-end joint optimization fails or that the reported margins disappear without the schedule. This directly affects the central claim that the MIA model (GC + RGA + BFM) obtains its gains via the alignments rather than the training schedule.
Authors: We agree that the abstract would be strengthened by explicitly referencing supporting evidence for the training strategy. The full manuscript contains ablation studies in the experiments section that compare end-to-end joint optimization against the proposed step training, showing measurable performance degradation without the step-wise schedule. To address the concern directly, we will revise the abstract to briefly note these quantitative comparisons, making clear that the reported gains rely on both the multi-granularity alignments and the training procedure. revision: yes
Circularity Check
No significant circularity; model is a new construction
full rationale
The paper presents MIA as a novel hierarchical alignment architecture (GC + RGA + BFM) plus a step-wise training schedule. No equations, fitted parameters, or self-citations are shown that reduce the claimed SOTA performance or the necessity of the schedule to a quantity defined by the authors' own prior work. The derivation chain consists of architectural choices and an empirical training heuristic whose justification rests on external benchmarks rather than self-referential definitions or renamings. This is the normal case of an independent construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, 2018
work page 2018
- [2]
- [3]
- [4]
-
[5]
D. Chen, H. Li, X. Liu, Y . Shen, J. Shao, Z. Yuan, and X. Wang. Improving deep visual representation for person re-identification by global and local image-language association. In ECCV, 2018
work page 2018
-
[6]
T. Chen, C. Xu, and J. Luo. Improving text-based person search by spatial matching and adaptive threshold. In WACV, 2018
work page 2018
- [7]
-
[8]
K. Cho, B. van Merrienboer, D. Bahdanau, and Y . Bengio. On the properties of neural machine translation: Encoder–decoder approaches. In SSST, 2014
work page 2014
-
[9]
Y .-J. Cho and K.-J. Yoon. Pamm: Pose-aware multi-shot matching for improving person re-identification. IEEE Transactions on Image Processing (TIP), 27(8):3739–3752, 2018
work page 2018
-
[10]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio. Empirical eval- uation of gated recurrent neural networks on sequence modeling. arXiv:1412.3555, 2014. 13
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
J. Dai, P. Zhang, D. Wang, H. Lu, and H. Wang. Video person re- identification by temporal residual learning. IEEE Transactions on Image Processing (TIP), 28(3):1366–1377, 2019
work page 2019
- [12]
- [13]
-
[14]
I. Haritaoglu, D. Harwood, and L. S. Davis. W/sup 4: real-time surveillance of people and their activities. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , 22(8):809–830, 2000
work page 2000
-
[15]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016
work page 2016
-
[16]
W. Hu, D. Xie, Z. Fu, W. Zeng, and S. Maybank. Semantic-based surveillance video retrieval. IEEE Transactions on Image Processing (TIP), 16(4):1168–1181, 2007
work page 2007
- [17]
- [18]
-
[19]
A. Karpathy and F. F. Li. Deep visual-semantic alignments for gener- ating image descriptions. In CVPR, 2015
work page 2015
-
[20]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, 2012
work page 2012
-
[22]
K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He. Stacked cross attention for image-text matching. In ECCV, 2018
work page 2018
-
[23]
S. Li, T. Xiao, H. Li, W. Yang, and X. Wang. Identity-aware textual- visual matching with latent co-attention. In ICCV, 2017
work page 2017
-
[24]
S. Li, T. Xiao, H. Li, B. Zhou, D. Yue, and X. Wang. Person search with natural language description. In CVPR, 2017
work page 2017
-
[25]
L. Lin, Y . Lu, Y . Pan, and X. Chen. Integrating graph partitioning and matching for trajectory analysis in video surveillance. IEEE Transactions on Image Processing (TIP) , 21(12):4844–4857, 2012
work page 2012
-
[26]
J. Liu, B. Ni, Y . Yan, P. Zhou, S. Cheng, and J. Hu. Pose transferrable person re-identification. In CVPR, 2018
work page 2018
-
[27]
J. Lu, C. Xiong, D. Parikh, and R. Socher. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In CVPR, 2017
work page 2017
-
[28]
J. Lu, J. Yang, D. Batra, and D. Parikh. Hierarchical question-image co-attention for visual question answering. In NeurIPS, 2016
work page 2016
-
[29]
V . Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010
work page 2010
- [30]
-
[31]
S. Reed, Z. Akata, H. Lee, and B. Schiele. Learning deep representations of fine-grained visual descriptions. In CVPR, 2016
work page 2016
-
[32]
S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015
work page 2015
-
[33]
S. J. Rennie, E. Marcheret, Y . Mroueh, J. Ross, and V . Goel. Self-critical sequence training for image captioning. In CVPR, 2017
work page 2017
-
[34]
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2014
work page 2014
-
[35]
C. Song, Y . Huang, W. Ouyang, and L. Wang. Mask-guided contrastive attention model for person re-identification. In CVPR, 2018
work page 2018
-
[36]
C. Su, J. Li, S. Zhang, J. Xing, W. Gao, and Q. Tian. Pose-driven deep convolutional model for person re-identification. In ICCV, 2017
work page 2017
-
[37]
Y . Sun, L. Zheng, Y . Yang, Q. Tian, and S. Wang. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In ECCV, 2018
work page 2018
- [38]
-
[39]
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator. In CVPR, 2015
work page 2015
-
[40]
B. Xu, N. Wang, T. Chen, and M. Li. Empirical evaluation of rectified activations in convolutional network. arXiv:1505.00853, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [41]
-
[42]
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y . Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015
work page 2015
-
[43]
X. Xu, F. Shen, Y . Yang, H. T. Shen, and X. Li. Learning discriminative binary codes for large-scale cross-modal retrieval. IEEE Transactions on Image Processing (TIP) , 26(5):2494–2507, 2017
work page 2017
-
[44]
H. Xue, Z. Zhao, and D. Cai. Unifying the video and question attentions for open-ended video question answering. IEEE Transactions on Image Processing (TIP), 26(12):5656–5666, 2017
work page 2017
-
[45]
H. Yao, S. Zhang, R. Hong, Y . Zhang, C. Xu, and Q. Tian. Deep representation learning with part loss for person re-identification. IEEE Transactions on Image Processing (TIP) , 28(6):2860–2871, 2019
work page 2019
- [46]
-
[47]
Y . Zhang and H. Lu. Deep cross-modal projection learning for image- text matching. In ECCV, 2018
work page 2018
-
[48]
L. Zhao, X. Li, Y . Zhuang, and J. Wang. Deeply-learned part-aligned representations for person re-identification. In ICCV, 2017
work page 2017
- [49]
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.