Gradient Noise Convolution (GNC): Smoothing Loss Function for Distributed Large-Batch SGD
Pith reviewed 2026-05-25 15:39 UTC · model grok-4.3
The pith
Gradient noise from stochastic gradients smooths sharp loss minima in large-batch distributed SGD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
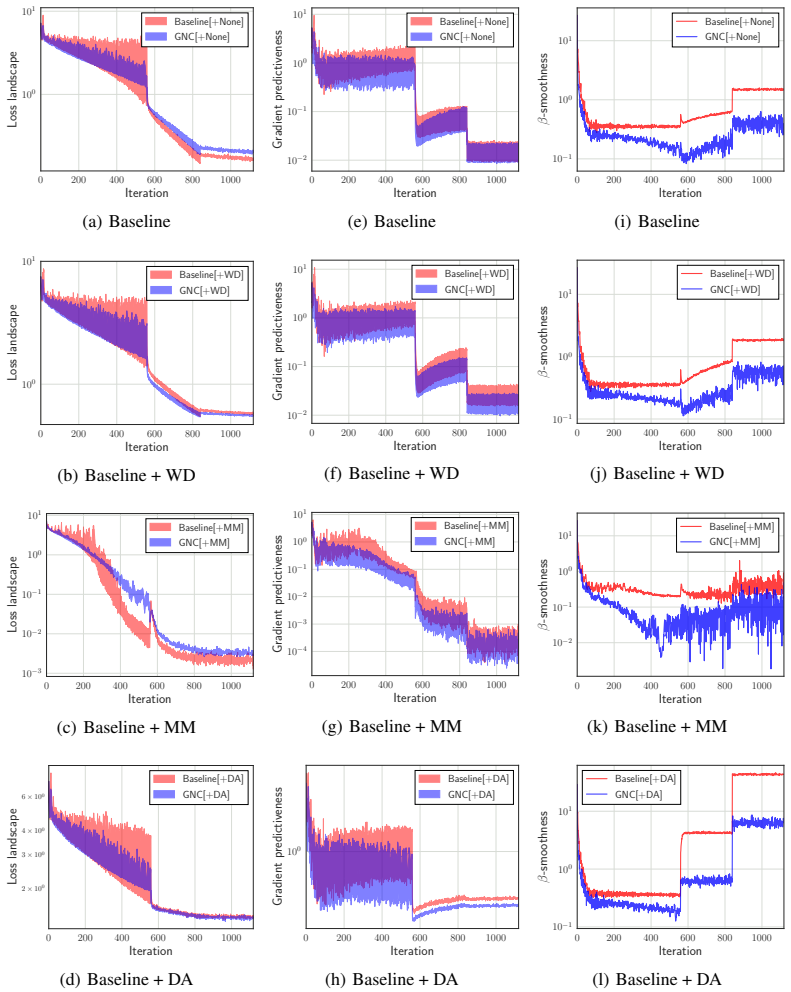
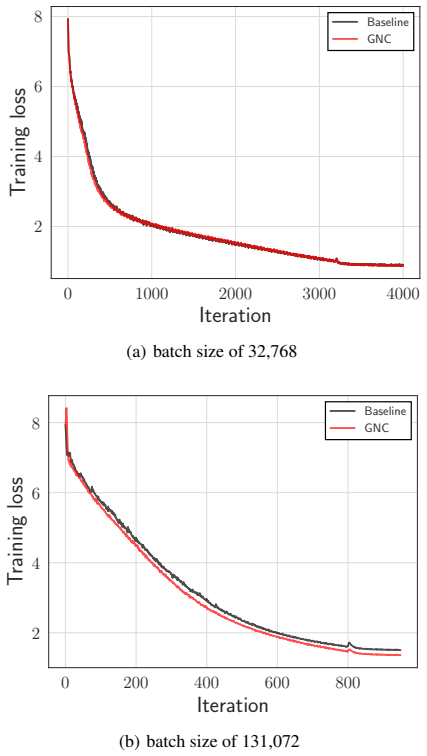
GNC utilizes so-called gradient noise, which is induced by stochastic gradient variation and convolved to the loss function as a smoothing effect. Due to convolving with the gradient noise, which tends to spread along a sharper direction of the loss function, GNC can effectively smooth sharp minima and achieve better generalization, whereas isotropic random noise cannot.
What carries the argument
Gradient noise convolution (GNC): the operation that convolves the loss with the empirical distribution of gradient differences across parallel workers.
If this is right
- Large-batch training can reach flatter minima without changing batch size or adding explicit regularizers.
- Implementation reduces to computing per-worker stochastic gradients and merging them, adding negligible overhead.
- The same mechanism explains why isotropic noise injection fails to match GNC performance.
- State-of-the-art test accuracy is reported for large-scale deep-network training under data-parallel SGD.
Where Pith is reading between the lines
- The directional bias of gradient noise may generalize to other first-order methods that already compute multiple gradient samples.
- If the smoothing effect is truly curvature-dependent, similar gains might appear in non-distributed settings by deliberately sampling gradient directions along estimated Hessian eigenvectors.
- Theoretical work could quantify how the covariance of per-worker gradients relates to the local Hessian eigenvalues.
Load-bearing premise
Stochastic gradient variation produces noise whose directional statistics align with and preferentially smooth the sharper directions of the loss surface without extra tuning.
What would settle it
An ablation in which replacing the observed gradient noise with isotropic random noise of matched magnitude yields equal or better generalization and sharpness metrics.
Figures








read the original abstract
Large-batch stochastic gradient descent (SGD) is widely used for training in distributed deep learning because of its training-time efficiency, however, extremely large-batch SGD leads to poor generalization and easily converges to sharp minima, which prevents naive large-scale data-parallel SGD (DP-SGD) from converging to good minima. To overcome this difficulty, we propose gradient noise convolution (GNC), which effectively smooths sharper minima of the loss function. For DP-SGD, GNC utilizes so-called gradient noise, which is induced by stochastic gradient variation and convolved to the loss function as a smoothing effect. GNC computation can be performed by simply computing the stochastic gradient on each parallel worker and merging them, and is therefore extremely easy to implement. Due to convolving with the gradient noise, which tends to spread along a sharper direction of the loss function, GNC can effectively smooth sharp minima and achieve better generalization, whereas isotropic random noise cannot. We empirically show this effect by comparing GNC with isotropic random noise, and show that it achieves state-of-the-art generalization performance for large-scale deep neural network optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Gradient Noise Convolution (GNC) for distributed large-batch SGD. GNC convolves the loss function with gradient noise induced by stochastic gradient variation across parallel workers, claiming this preferentially smooths sharp minima (because the noise covariance aligns with high-curvature directions) and yields better generalization than isotropic random noise. The method requires no extra hyperparameters and is implemented by simply computing and merging per-worker stochastic gradients; the abstract states that this achieves state-of-the-art generalization for large-scale DNN training.
Significance. If the directional alignment between mini-batch gradient noise and loss curvature is rigorously shown, GNC would supply a parameter-free mechanism that exploits existing stochasticity to close the generalization gap of large-batch training, with direct relevance to distributed deep-learning systems.
major comments (2)
- [Abstract] Abstract: the central claim that gradient noise 'tends to spread along a sharper direction of the loss function' (thereby smoothing sharp minima more effectively than isotropic noise) is load-bearing yet unsupported by any derivation from the mini-batch sampling process or by a controlled experiment that isolates noise-covariance anisotropy from other large-batch effects such as effective step-size scaling.
- [Abstract] Abstract: the assertion of 'state-of-the-art generalization performance' and empirical superiority over isotropic random noise is stated without any reported metrics, baselines, datasets, model architectures, or ablation details, preventing assessment of whether the claimed directional smoothing actually occurs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to strengthen the presentation of the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that gradient noise 'tends to spread along a sharper direction of the loss function' (thereby smoothing sharp minima more effectively than isotropic noise) is load-bearing yet unsupported by any derivation from the mini-batch sampling process or by a controlled experiment that isolates noise-covariance anisotropy from other large-batch effects such as effective step-size scaling.
Authors: We agree that the abstract would benefit from explicit support for this claim. The manuscript provides an empirical demonstration via direct comparison of GNC against isotropic random noise under matched conditions; this comparison is intended to isolate the benefit of the noise covariance structure. To make the argument more rigorous, we will add a short derivation in the revised manuscript showing how the per-worker gradient covariance aligns with the Hessian eigenvectors of high-curvature directions. We will also clarify that the experimental controls already hold effective step size and batch size fixed across the GNC and isotropic-noise arms. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'state-of-the-art generalization performance' and empirical superiority over isotropic random noise is stated without any reported metrics, baselines, datasets, model architectures, or ablation details, preventing assessment of whether the claimed directional smoothing actually occurs.
Authors: We acknowledge that the abstract is too terse on these points. The full manuscript reports concrete results on standard large-scale image-classification benchmarks (ImageNet, CIFAR-10/100) with ResNet and VGG architectures, comparing against both naive large-batch DP-SGD and isotropic-noise baselines. We will expand the abstract to include the key quantitative improvements (e.g., top-1 accuracy deltas) and the primary experimental settings so that the claims can be assessed without reading the full text. revision: yes
Circularity Check
No circularity: method is direct computation on existing gradients; directional claim is heuristic, not derived by construction.
full rationale
The paper defines GNC explicitly as merging stochastic gradients across workers and presents the smoothing benefit as an empirical observation from the noise's directional spread. No equations, fitted parameters, or self-citations are shown reducing the claimed advantage to an input quantity by definition. The abstract and description treat the anisotropy as an observed tendency rather than a self-referential prediction, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic gradient noise tends to spread along sharper directions of the loss function
invented entities (1)
-
Gradient Noise Convolution (GNC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ChainerMN: Scalable Distributed Deep Learning Framework
Takuya Akiba, Keisuke Fukuda, and Shuji Suzuki. ChainerMN: Scalable Distributed Deep Learning Framework. arXiv e-prints, art. arXiv:1710.11351, Oct 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
Takuya Akiba, Shuji Suzuki, and Keisuke Fukuda. Extremely large minibatch SGD: training resnet-50 on imagenet in 15 minutes. CoRR, abs/1711.04325, 2017. URL http://arxiv.org/abs/1711.04325
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Pratik Chaudhari and Stefano Soatto. Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks. arXiv e-prints, art. arXiv:1710.11029, Oct 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Entropy-SGD: Biasing Gradient Descent Into Wide Valleys
Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Yann LeCun, Carlo Baldassi, Christian Borgs, Jennifer T. Chayes, Levent Sagun, and Riccardo Zecchina. Entropy-sgd: Biasing gradient descent into wide valleys. CoRR, abs/1611.01838, 2016. URL http://arxiv.org/abs/1611.01838
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Valeriu Codreanu, Damian Podareanu, and Vikram Saletore. Scale out for large minibatch SGD: Residual network training on ImageNet-1K with improved accuracy and reduced time to train. arXiv e-prints, art. arXiv:1711.04291, Nov 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Escaping saddles with stochastic gradients
Hadi Daneshmand, Jonas Kohler, Aurelien Lucchi, and Thomas Hofmann. Escaping saddles with stochastic gradients. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research , pages 1155–1164, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR....
work page 2018
-
[7]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017. URL http://arxiv.org/abs/1706.02677
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015. URL http://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
FireCaffe: near-linear acceleration of deep neural network training on compute clusters
Forrest N. Iandola, Khalid Ashraf, Matthew W. Moskewicz, and Kurt Keutzer. Firecaffe: near-linear acceleration of deep neural network training on compute clusters. CoRR, abs/1511.00175, 2015. URL http://arxiv.org/abs/1511.00175
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
On the relation between the sharpest directions of DNN loss and the SGD step length
Stanisław Jastrz˛ ebski, Zachary Kenton, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amost Storkey. On the relation between the sharpest directions of DNN loss and the SGD step length. InInternational Con- ference on Learning Representations, 2019. URL https://openreview.net/forum?id=SkgEaj05t7
work page 2019
-
[11]
Xianyan Jia, Shutao Song, Wei He, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi, and Xiaowen Chu. Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes. CoRR, abs/1807.11205, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
URL http://arxiv.org/abs/1609.04836
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Bobby Kleinberg, Yuanzhi Li, and Yang Yuan. An alternative view: When does SGD escape local minima? In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research , pages 2698–2707, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR. URL http://...
work page 2018
-
[15]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[16]
Visualizing the Loss Landscape of Neural Nets
Hao Li, Zheng Xu, Gavin Taylor, and Tom Goldstein. Visualizing the loss landscape of neural nets. CoRR, abs/1712.09913, 2017. URL http://arxiv.org/abs/1712.09913. 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Kazuki Osawa, Yohei Tsuji, Yuichiro Ueno, Akira Naruse, Rio Yokota, and Satoshi Matsuoka. Large-Scale Distributed Second-Order Optimization Using Kronecker-Factored Approximate Curvature for Deep Convolutional Neural Networks. arXiv e-prints, art. arXiv:1811.12019, Nov 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, Dec 2015. ISSN 1573-
work page 2015
-
[19]
ImageNet Large Scale Visual Recognition Challenge,
doi: 10.1007/s11263-015-0816-y. URL https://doi.org/10.1007/s11263-015-0816-y
-
[20]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V . Ugur Güney, Yann Dauphin, and Léon Bottou. Empirical analysis of the hessian of over-parametrized neural networks. CoRR, abs/1706.04454, 2017. URL http://arxiv.org/ abs/1706.04454
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
How Does Batch Normalization Help Optimization?
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How Does Batch Normalization Help Optimization? arXiv e-prints, art. arXiv:1805.11604, May 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Chainer : a next-generation open source framework for deep learning
Seiya Tokui and Kenta Oono. Chainer : a next-generation open source framework for deep learning. In Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Twenty-ninth Annual Conference on Neural Information Processing Systems (NIPS-W), 2015
work page 2015
-
[23]
SmoothOut: Smoothing Out Sharp Minima to Improve Generalization in Deep Learning
Wei Wen, Yandan Wang, Feng Yan, Cong Xu, Yiran Chen, and Hai Li. Smoothout: Smoothing out sharp minima for generalization in large-batch deep learning. CoRR, abs/1805.07898, 2018. URL http://arxiv.org/abs/1805.07898
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Yeming Wen, Kevin Luk, Maxime Gazeau, Guodong Zhang, Harris Chan, and Jimmy Ba. Interplay between optimization and generalization of stochastic gradient descent with covariance noise. CoRR, abs/1902.08234, 2019. URL http://arxiv.org/abs/1902.08234
-
[25]
Image Classification at Supercomputer Scale
Chris Ying, Sameer Kumar, Dehao Chen, Tao Wang, and Youlong Cheng. Image classification at supercomputer scale. CoRR, abs/1811.06992, 2018. URL http://arxiv.org/abs/1811.06992
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Large Batch Training of Convolutional Networks
Yang You, Igor Gitman, and Boris Ginsburg. Large Batch Training of Convolutional Networks. arXiv e-prints, art. arXiv:1708.03888, Aug 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Yang You, Zhao Zhang, Cho-Jui Hsieh, and James Demmel. Imagenet training in minutes. CoRR, abs/1709.05011v10, 2018. URL https://arxiv.org/abs/1709.05011v10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Random Erasing Data Augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. CoRR, abs/1708.04896, 2017. URL http://arxiv.org/abs/1708.04896
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
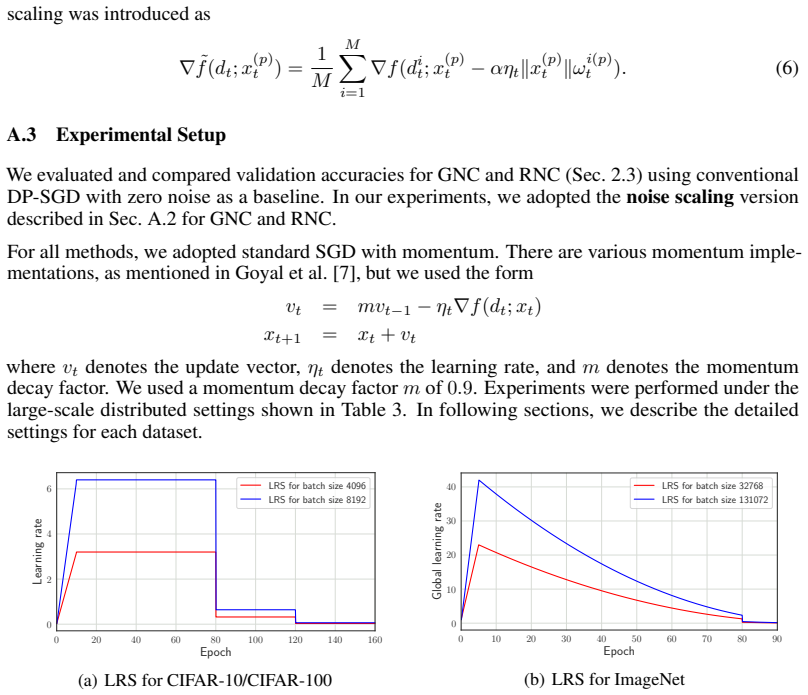
Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Minima and Regularization Effects. ArXiv e-prints, art. arXiv:1803.00195, February 2018. 10 A Detailed Experimental Setup A.1 Datasets We empirically evaluated the performance of GNC in large scale distributed trai...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
and Ying et al. [23] did not reveal the details of their experimental settings, so those results are beyond the scope of this paper. Epochs Batch size Accuracy(%) Goyal et al. [7] 90 32,768 72.45 Akiba et al. [2] 90 32,768 74.94 Codreanu et al. [5] 100 32,768 75.31 You et al. [25] 90 32,768 75.4 Jia et al. [11] 90 65,536 76.2 ∗ Ying et al. [23] 90 32,768 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.