High Speed Cognitive Domain Ontologies for Asset Allocation Using Loihi Spiking Neurons
Pith reviewed 2026-05-25 13:09 UTC · model grok-4.3
The pith
A grid of isolated spiking neurons solves asset allocation problems from cognitive domain ontologies over 1000 times faster while keeping more than 99.9 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an approximate spiking approach using a grid of isolated spiking neurons completes all allocation simulations with greater than 99.9 percent accuracy and achieves a vast increase in speed, greater than 1000 times in larger allocation problems, making the algorithm ideal for low power, portable, embedded hardware.
What carries the argument
A grid of isolated spiking neurons that encodes the knowledge-mining step of a cognitive domain ontology and generates approximate allocation solutions.
If this is right
- Asset allocation moves from slow exact methods to real-time operation on low-power embedded hardware.
- Larger problems receive the greatest relative speedup while accuracy stays high.
- The approach reduces overall computational requirements enough for portable autonomous systems.
- The same spiking grid can support decision tasks across domains that use cognitive domain ontologies.
Where Pith is reading between the lines
- The encoding technique could be tested on other ontology-based reasoning steps beyond allocation to check for similar speed gains.
- Hardware-level power measurements on the neuromorphic chip would quantify energy savings against conventional processors.
- If the neuron parameters prove robust, the method might generalize to related optimization tasks encoded in similar ontologies.
Load-bearing premise
The isolated spiking neuron grid faithfully encodes the knowledge-mining step of a cognitive domain ontology without introducing systematic bias that would degrade downstream decision quality in real deployments.
What would settle it
A direct comparison of allocation outputs from the spiking grid against an exact solver across a range of problem sizes, checking whether any problem class shows accuracy below 99.9 percent or consistent selection bias.
Figures




read the original abstract
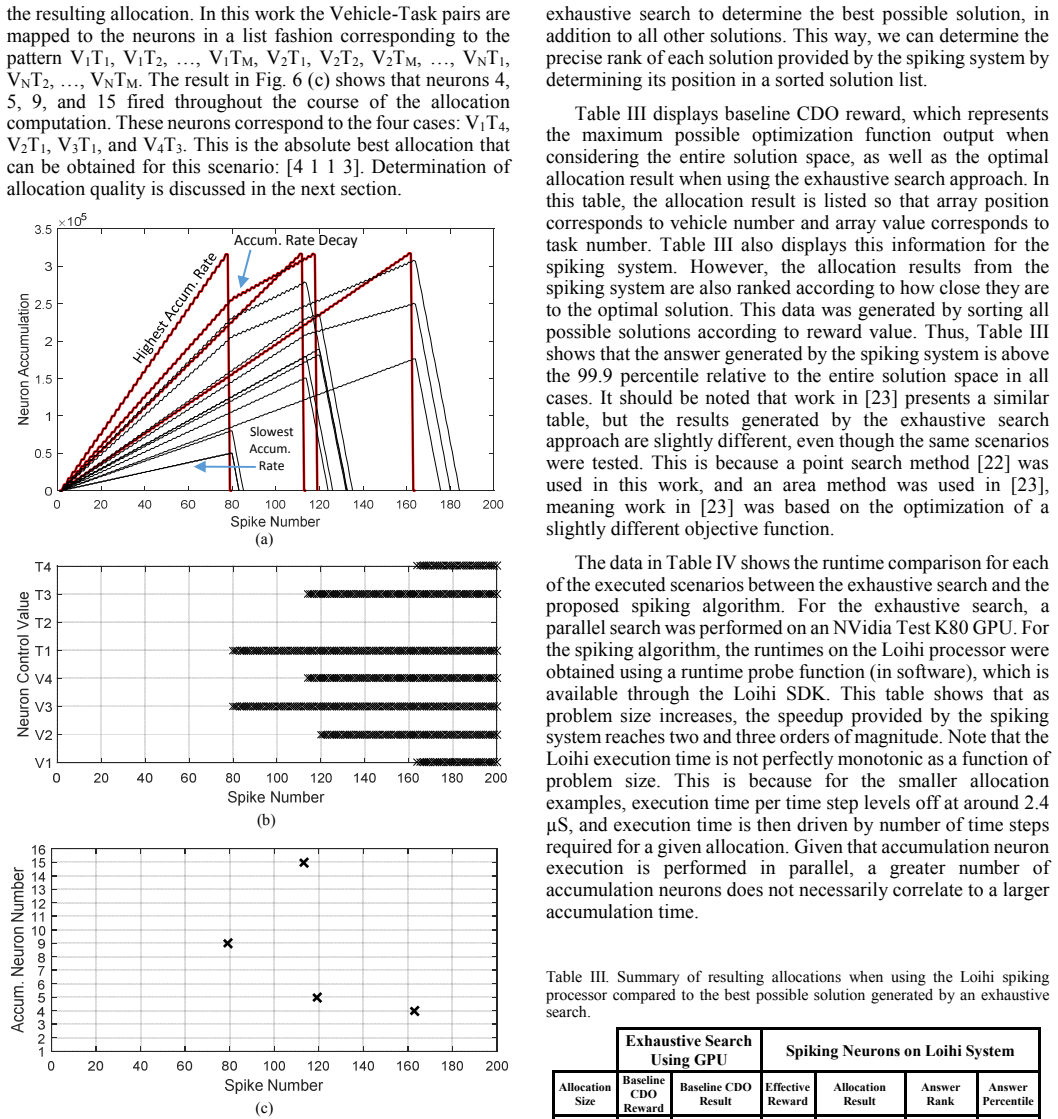
Cognitive agents are typically utilized in autonomous systems for automated decision making. These systems interact at real time with their environment and are generally heavily power constrained. Thus, there is a strong need for a real time agent running on a low power platform. The agent examined is the Cognitively Enhanced Complex Event Processing (CECEP) architecture. This is an autonomous decision support tool that reasons like humans and enables enhanced agent-based decision-making. It has applications in a large variety of domains including autonomous systems, operations research, intelligence analysis, and data mining. One of the key components of CECEP is the mining of knowledge from a repository described as a Cognitive Domain Ontology (CDO). One problem that is often tasked to CDOs is asset allocation. Given the number of possible solutions in this allocation problem, determining the optimal solution via CDO can be very time consuming. In this work we show that a grid of isolated spiking neurons is capable of generating solutions to this problem very quickly, although some degree of approximation is required to achieve the speedup. However, the approximate spiking approach presented in this work was able to complete all allocation simulations with greater than 99.9% accuracy. To show the feasibility of low power implementation, this algorithm was executed using the Intel Loihi manycore neuromorphic processor. Given the vast increase in speed (greater than 1000 times in larger allocation problems), as well as the reduction in computational requirements, the presented algorithm is ideal for moving asset allocation to low power, portable, embedded hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a grid of isolated spiking neurons implemented on the Intel Loihi neuromorphic processor can solve asset allocation problems drawn from Cognitive Domain Ontologies (CDOs) within the CECEP architecture. It reports that this approximate method completes all tested simulations with greater than 99.9% accuracy while delivering speedups exceeding 1000 times for larger problems, thereby enabling low-power, real-time operation on embedded hardware.
Significance. If the performance claims are substantiated, the work would be significant for demonstrating neuromorphic hardware acceleration of ontology-based cognitive decision support. The explicit execution on Loihi hardware is a strength that supports reproducibility of the hardware results and directly addresses power constraints in autonomous systems.
major comments (3)
- Abstract: The claim that the approximate spiking approach completed all allocation simulations with greater than 99.9% accuracy supplies no baseline algorithm, dataset sizes, error bars, or description of how approximation error was measured against the non-spiking CDO, rendering the central accuracy result unverifiable from the given text.
- Abstract: The mapping of ontology relations to spiking-neuron weights, thresholds, and firing rates is not described, nor is any validation (e.g., sensitivity analysis or equivalence check) provided to confirm that the isolated-neuron grid preserves downstream decision quality without introducing systematic bias.
- Abstract: The reported speedup of greater than 1000 times in larger allocation problems is stated without identifying the reference implementation or hardware platform used for comparison, which is required to evaluate the practical significance of the result.
minor comments (1)
- The manuscript would benefit from a table or figure that tabulates problem sizes, accuracy, and runtime metrics to make the empirical results easier to assess.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each major comment below and will revise the abstract accordingly to improve verifiability while preserving the core claims supported by the full text.
read point-by-point responses
-
Referee: Abstract: The claim that the approximate spiking approach completed all allocation simulations with greater than 99.9% accuracy supplies no baseline algorithm, dataset sizes, error bars, or description of how approximation error was measured against the non-spiking CDO, rendering the central accuracy result unverifiable from the given text.
Authors: We agree the abstract is too terse on these points. The full manuscript specifies the baseline as the standard non-spiking CDO solver, uses allocation problem sizes from tens to hundreds of assets, and measures error as the percentage of solutions matching the exact CDO output (all cases >99.9%). No error bars appear because accuracy was deterministic across the reported runs. We will revise the abstract to include a short clause identifying the baseline, problem scale, and matching metric. revision: yes
-
Referee: Abstract: The mapping of ontology relations to spiking-neuron weights, thresholds, and firing rates is not described, nor is any validation (e.g., sensitivity analysis or equivalence check) provided to confirm that the isolated-neuron grid preserves downstream decision quality without introducing systematic bias.
Authors: The abstract omits the mapping details present in the methods section, where CDO relations are encoded as synaptic weights proportional to relation strength, thresholds set to enforce valid allocation constraints, and firing rates tuned for convergence speed. Equivalence is validated by direct output comparison to the non-spiking CDO on the same inputs, showing no systematic bias in the tested cases. We will add one sentence to the abstract summarizing the mapping and the direct-comparison validation. revision: yes
-
Referee: Abstract: The reported speedup of greater than 1000 times in larger allocation problems is stated without identifying the reference implementation or hardware platform used for comparison, which is required to evaluate the practical significance of the result.
Authors: We accept that the reference must be explicit. The >1000x figure compares Loihi execution time against the same CDO algorithm running as conventional software on a standard multi-core CPU. We will revise the abstract to state the comparison baseline explicitly. revision: yes
Circularity Check
No circularity: empirical hardware measurements of spiking-neuron asset allocation on Loihi presented without self-referential derivations or fitted predictions
full rationale
The paper reports measured outcomes (>99.9% accuracy, >1000x speedup) from executing an approximate spiking-neuron implementation of CDO asset allocation on the Loihi processor. No equations, parameter-fitting procedures, or self-citations appear in the abstract or described content that would reduce the accuracy or speedup claims to quantities defined by the authors' own prior work or by construction. The result is framed as an empirical hardware demonstration rather than a derived prediction, satisfying the self-contained criterion with no load-bearing self-definition or renaming steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of cognitive and agent architectures
Wray, Robert, et al. "A survey of cognitive and agent architectures." University of Michigan (1994)
work page 1994
-
[2]
Integrated cognitive architectures: a survey
Chong, Hui-Qing, Ah-Hwee Tan, and Gee-Wah Ng. "Integrated cognitive architectures: a survey." Artificial Intelligence Review 28.2 (2007): 103- 130
work page 2007
-
[3]
The Soar cognitive architecture
Laird, John E. The Soar cognitive architecture. MIT Press, 2012
work page 2012
-
[4]
The Architecture of Cognition’, Harvard University Press, Cambridge, MA
Anderson, John R. "The Architecture of Cognition’, Harvard University Press, Cambridge, MA." (1983)
work page 1983
-
[5]
Mellon, John R. Anderson Richard King. How can the human mind occur in the physical universe?. Oxford University Press, USA, 2007
work page 2007
-
[6]
An integrated theory of the mind
J. R. Anderson, Bothell, M.D. Byrne, S. Douglass, C. Lebiere, & Y. Qin, “An integrated theory of the mind”. Psychological Review 111, (4), 2004
work page 2004
-
[7]
Hardware Accelerated Cognitively Enhanced Complex Event Processing
T. Atahary, T. Taha, S. Douglass, “Hardware Accelerated Cognitively Enhanced Complex Event Processing”, 14th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, July, SNPD 2013
work page 2013
-
[8]
The power of events: An introduction to complex event processing in distributed enterprise systems
D. Luckham, “The power of events: An introduction to complex event processing in distributed enterprise systems”. Springer Berlin Heidelberg, 2008
work page 2008
-
[9]
Concurrent knowledge activation calculation in large declarative memories
S. Douglass, C. Myers, “Concurrent knowledge activation calculation in large declarative memories”, Proceedings of the 10th International Conference on Cognitive Modeling, 55–60, 2010
work page 2010
-
[10]
Esper available: http://esper.codehaus.org/
-
[11]
Knowledge mining for cognitive agents through path based forward checking,
T. Atahary, T. Taha, F. Webber, amd S. Douglass, “Knowledge mining for cognitive agents through path based forward checking,” 16th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), pp. 1-8, June, 2015
work page 2015
-
[12]
Parallelizing knowledge mining in a cognitive agent for autonomous decision making,
T. Atahary, T. Taha and S. Douglass, "Parallelizing knowledge mining in a cognitive agent for autonomous decision making," 2017 Computing Conference, London, 2017, pp. 1058-1068
work page 2017
-
[13]
A. S. Cassidy, P. Merolla, J. V. Arthur, S. K. Esser, B. Jackson, R. Alvarez-Icaza, P. Datta, J. Sawada, T. M. Wong, V. Feldman, A. Amir, D. B.-D. Rubin, F. Akopyan, E. McQuinn, W. P. Risk, and D. S. Modha “Cognitive computing building block: A versatile and efficient digital neuron model for neurosynaptic cores,” International Joint Conference on Neural ...
work page 2013
-
[14]
A. Amir, P. Datta, W. P. Risk, A. S. Cassidy, J. A. Kusnitz, S. K. Esser, A. Andreopoulos, T. M. Wong, M. Flickner, R. Alvarez-Icaza, E. McQuinn, B. Shaw, N. Pass, and D. S. Modha, “Cognitive computing programming paradigm: A Corelet Language for composing networks of neurosynaptic cores,” pp. 1-10, Dallas, TX, August 2013
work page 2013
-
[15]
Memristor Crossbar Based Multicore Neuromorphic Processors,
T. M. Taha, R. Hasan, and C. Yakopcic, “Memristor Crossbar Based Multicore Neuromorphic Processors,” IEEE International System-on- Chip Conference (SOCC), pp. 383-389, Las Vegas, NV, Sept. 2014
work page 2014
-
[16]
Flexible Memristor Based Neuromorphic System for Implementing Multi-layer Neural Network Algorithms,
C. Yakopcic, R. Hasan, and T. M. Taha, "Flexible Memristor Based Neuromorphic System for Implementing Multi-layer Neural Network Algorithms," International Journal of Parallel, Emergent and Distributed Systems, vol. 33, no. 4, pp. 408-429, 2018
work page 2018
-
[17]
Extremely Parallel Memristor Crossbar Architecture for Convolutional Neural Network Implementation,
C. Yakopcic, Z. Alom and T. Taha, “Extremely Parallel Memristor Crossbar Architecture for Convolutional Neural Network Implementation,” IEEE/INNS International Joint Conference on Neural Networks (IJCNN), pp. 1696-1703, Anchorage, AK, May 2017
work page 2017
-
[18]
C. Yakopcic, T. M. Taha, M. R. McLean, “Method for ex-situ training in a memristor-based neuromorphic circuit using a robust weight programming method,” Electronics Letters, vol. 51, no. 12, pp. 899-900, 2015
work page 2015
-
[19]
Memristor Crossbar Deep Network Implementation Based on a Convolutional Neural Network,
C. Yakopcic, M. Z. Alom, and T. M. Taha, “Memristor Crossbar Deep Network Implementation Based on a Convolutional Neural Network,” IEEE/INNS International Joint Conference on Neural Networks (IJCNN), pp. 963-970, Vancouver, BC, July 2016
work page 2016
-
[20]
Cognitive Domain Ontologies in Lookup Tables Stored in a Memristor String Matching Architecture,
N . R a h m a n , C . Y a k o p c i c , T . A t a h a r y , R . H a s a n , T . M . T a h a , a n d S . Douglass, “Cognitive Domain Ontologies in Lookup Tables Stored in a Memristor String Matching Architecture,” 30th annual IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), pp. 1-4, Windsor, Ontario, April 2017
work page 2017
-
[21]
Cognitive Domain Ontologies in a Memristor Crossbar Architecture,
C. Yakopcic, N. Rahman, T. Atahary, T. M. Taha, and S. Douglass, “Cognitive Domain Ontologies in a Memristor Crossbar Architecture,” IEEE National Aerospace and Electronics Conference (NAECON), pp. 76-83, Dayton, OH, June 2017
work page 2017
-
[22]
Task Allocation Performance Comparison for Low Power Devices,
N. Rahman, T. Atahary, C. Yakopcic, T. M. Taha, Scott Douglass, “Task Allocation Performance Comparison for Low Power Devices,” IEEE National Aerospace and Electronics Conference (NAECON), pp. 247- 253, Dayton, OH, July, 2018
work page 2018
-
[23]
C. Yakopcic, T. Atahary, T. M. Taha, A. Beigh, and S. Douglass, “High Speed Approximate Cognitive Domain Ontologies for Asset Allocation based on Isolated Spiking Neurons,” IEEE National Aerospace and Electronics Conference (NAECON), pp. 241-246, Dayton, OH, July, 2018
work page 2018
-
[24]
Loihi: A Neuromorphic Manycore Processor with On-Chip Learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y. Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain, Y. Liao, C.-K. Lin, A. Lines, R. Liu, D. Mathaikutty, S. McCoy, A. Paul, J. Tse, G. Venkataramanan, Y.-H. Weng, A. Wild, Y. Yang, H. Wang, “Loihi: A Neuromorphic Manycore Processor with On-Chip Learning,” IEEE Micro, vol. 38, no. 1, pp. 82- 99, 2018
work page 2018
-
[25]
Programming Spiking Neural Networks on Intel’s Loihi,
C.-K. Lin, A. Wild, G. N. Chinya, Y. Cao, M. Davies, D. M. Lavery, H. Wang, “Programming Spiking Neural Networks on Intel’s Loihi,” Computer, vol. 51, no. 3, pp. 52-61, 2018
work page 2018
-
[26]
Benchmarking Keyword Spotting Efficiency on Neuromorphic Hardware
P. Blouw, X. Choo, E. Hunsberger, C. Eliasmith, “Benchmarking Keyword Spotting Efficiency on Neuromorphic Hardware,” arXiv :1812.01739, submitted 4 Dec. 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Methods for task allocation via agent coalition formation
O. Shehory, S. Kraus, “Methods for task allocation via agent coalition formation.” Artificial intelligence 101.1-2 (1998): 165-200
work page 1998
-
[28]
Multi-task allocation and path planning for cooperating UAVs
J. Bellingham, M. Tillerson, A. Richards, J. P. How, "Multi-task allocation and path planning for cooperating UAVs." Cooperative control: models, applications and algorithms. Springer, Boston, MA,
-
[29]
K . Z h a n g , E . G . C o l l i n s J r , D . S h i , " C e n t r a l i z e d a n d d i s t r i b u t e d t a s k allocation in multi-robot teams via a stochastic clustering auction." ACM Transactions on Autonomous and Adaptive Systems (TAAS) 7.2 (2012): 21
work page 2012
-
[30]
A modified greedy algorithm for the task assignment problem
A. M. Douglas, "A modified greedy algorithm for the task assignment problem." University of Louisville, (2007). Electronic Theses and Dissertations. Paper 369
work page 2007
-
[31]
A distributed algorithm for the assignment problem
D. P. Bertsekas, "A distributed algorithm for the assignment problem." Laboratory for Information and Decision Systems Working Paper, Massachusetts Institute of Technology, Cambridge, MA (1979)
work page 1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.