Disentangled Makeup Transfer with Generative Adversarial Network
Pith reviewed 2026-05-25 11:32 UTC · model grok-4.3
The pith
A GAN disentangles identity from makeup style to support strength-controlled transfer and style sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
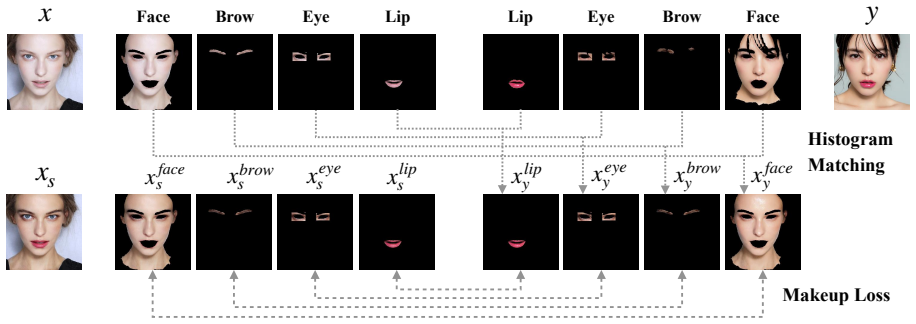
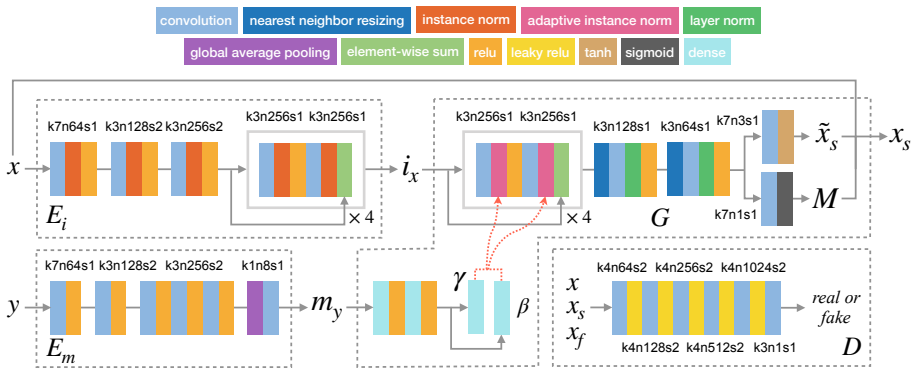
The model employs an identity encoder and a makeup encoder to disentangle personal identity and makeup style for arbitrary face images. Based on the outputs of the two encoders, a decoder reconstructs the original faces, and a discriminator distinguishes real faces from generated ones. As a result, the model can transfer makeup styles from one or more reference face images to a non-makeup face with controllable strength and produce various outputs with styles sampled from a prior distribution.
What carries the argument
The identity encoder and makeup encoder that disentangle personal identity from makeup style, allowing independent control in the decoder.
If this is right
- Makeup can be transferred from single or multiple reference images to a non-makeup source face.
- The transferred makeup strength can be adjusted continuously during generation.
- Multiple distinct outputs can be produced by sampling makeup styles from a learned prior distribution.
- Generated faces remain high-quality and realistic across these different transfer scenarios.
Where Pith is reading between the lines
- The same encoder separation might be reused to control other facial attributes such as age or expression without retraining the full model.
- Interactive editing tools could let users drag a strength slider and see immediate results on uploaded photos.
- Sampling from the prior could generate large synthetic datasets of made-up faces for training downstream recognition systems.
Load-bearing premise
The two encoders can separate identity information from makeup information without mixing or loss for any input face images.
What would settle it
A test set where increasing the makeup strength parameter either alters the source person's identity or produces outputs that no longer match the reference makeup style would show the disentanglement has failed.
Figures











read the original abstract
Facial makeup transfer is a widely-used technology that aims to transfer the makeup style from a reference face image to a non-makeup face. Existing literature leverage the adversarial loss so that the generated faces are of high quality and realistic as real ones, but are only able to produce fixed outputs. Inspired by recent advances in disentangled representation, in this paper we propose DMT (Disentangled Makeup Transfer), a unified generative adversarial network to achieve different scenarios of makeup transfer. Our model contains an identity encoder as well as a makeup encoder to disentangle the personal identity and the makeup style for arbitrary face images. Based on the outputs of the two encoders, a decoder is employed to reconstruct the original faces. We also apply a discriminator to distinguish real faces from fake ones. As a result, our model can not only transfer the makeup styles from one or more reference face images to a non-makeup face with controllable strength, but also produce various outputs with styles sampled from a prior distribution. Extensive experiments demonstrate that our model is superior to existing literature by generating high-quality results for different scenarios of makeup transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DMT, a GAN with an identity encoder, a makeup encoder, a decoder, and a discriminator. The encoders are intended to disentangle personal identity from makeup style on arbitrary faces; their outputs are combined by the decoder to reconstruct or transfer makeup. The central claims are that this enables (i) makeup transfer from one or more reference images with controllable strength and (ii) generation of diverse outputs by sampling makeup styles from a prior distribution, with the model asserted to be superior to prior work on the basis of extensive experiments.
Significance. If the claimed disentanglement holds and is supported by appropriate quantitative evidence, the architecture would offer a more flexible alternative to fixed-output makeup transfer methods, supporting both reference-driven transfer and unconditional sampling. The approach aligns with broader trends in disentangled representation learning for image manipulation.
major comments (2)
- [Abstract] Abstract: The claim that the identity encoder and makeup encoder 'disentangle the personal identity and the makeup style' is load-bearing for both controllable transfer and prior sampling, yet the abstract supplies no description of loss terms (e.g., explicit invariance penalties, mutual-information minimization, or cycle-consistency constraints) that would force the identity encoder to ignore makeup variations and the makeup encoder to ignore identity cues. Standard reconstruction plus adversarial losses alone do not guarantee this separation.
- [Abstract] Abstract: Superiority is asserted via 'extensive experiments' that 'demonstrate that our model is superior,' but no quantitative metrics (FID, PSNR, user-study percentages, or comparison tables), training details, or failure-case analysis are referenced. This absence prevents verification of whether the encoders actually achieve the required factor separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. Below we respond point by point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the identity encoder and makeup encoder 'disentangle the personal identity and the makeup style' is load-bearing for both controllable transfer and prior sampling, yet the abstract supplies no description of loss terms (e.g., explicit invariance penalties, mutual-information minimization, or cycle-consistency constraints) that would force the identity encoder to ignore makeup variations and the makeup encoder to ignore identity cues. Standard reconstruction plus adversarial losses alone do not guarantee this separation.
Authors: The abstract is a concise summary and therefore omits the specific loss formulations, which are presented in Section 3 of the manuscript. There the identity encoder is trained with a reconstruction objective on the source face while the makeup encoder is trained to extract style features that are combined by the decoder; the separate encoder pathways and the reconstruction objective are intended to encourage the desired factor separation. We acknowledge that the abstract does not make this explicit and will revise it to include a brief reference to the reconstruction and adversarial losses that support disentanglement. revision: yes
-
Referee: [Abstract] Abstract: Superiority is asserted via 'extensive experiments' that 'demonstrate that our model is superior,' but no quantitative metrics (FID, PSNR, user-study percentages, or comparison tables), training details, or failure-case analysis are referenced. This absence prevents verification of whether the encoders actually achieve the required factor separation.
Authors: The abstract summarizes the outcome of the experiments; the full manuscript reports quantitative comparisons using FID, user-study percentages, and side-by-side tables against prior methods, together with training details and selected failure cases. To address the referee's concern we will revise the abstract to mention that superiority is demonstrated via quantitative metrics and user studies. revision: yes
Circularity Check
No circularity: architecture description contains no derivations or fitted predictions
full rationale
The paper presents a GAN-based model with identity and makeup encoders feeding a decoder, plus a discriminator. No equations, parameter-fitting steps, or predictions are described that reduce to inputs by construction. The disentanglement claim rests on the stated architecture and (unstated) training losses rather than any self-referential reduction or self-citation chain. This matches the default expectation of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- makeup strength control
axioms (1)
- domain assumption Separate encoders can disentangle identity from makeup style in face images
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our model contains an identity encoder as well as a makeup encoder to disentangle the personal identity and the makeup style... decoder... discriminator
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Reconstruction Loss... Perceptual Loss... Makeup Loss... Attention Loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Ba et al., 2016] Lei Jimmy Ba, Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. CoRR, abs/1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
[Bengio et al., 2013] Yoshua Bengio, Aaron C. Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828,
work page 2013
-
[3]
Attention-gan for object transfig- uration in wild images
[Chen et al., 2018] Xinyuan Chen, Chang Xu, Xiaokang Yang, and Dacheng Tao. Attention-gan for object transfig- uration in wild images. In ECCV, pages 167–184,
work page 2018
-
[4]
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
[Choi et al., 2017] Yunjey Choi, Min-Je Choi, Muny- oung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. CoRR, abs/1711.09020,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
A Neural Algorithm of Artistic Style
[Gatys et al., 2015] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. A neural algorithm of artistic style. CoRR, abs/1508.06576,
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
Goodfellow, Jean Pouget- Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C
[Goodfellow et al., 2014] Ian J. Goodfellow, Jean Pouget- Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, pages 2672– 2680,
work page 2014
- [7]
-
[8]
Digital face makeup by example
[Guo and Sim, 2009] Dong Guo and Terence Sim. Digital face makeup by example. In CVPR, pages 73–79,
work page 2009
-
[9]
Delving deep into rectifiers: Surpass- ing human-level performance on imagenet classification
[He et al., 2015] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpass- ing human-level performance on imagenet classification. In ICCV, pages 1026–1034,
work page 2015
-
[10]
[Huang and Belongie, 2017] Xun Huang and Serge J. Be- longie. Arbitrary style transfer in real-time with adaptive instance normalization. In ICCV, pages 1510–1519,
work page 2017
-
[11]
[Huang et al., 2018] Xun Huang, Ming-Yu Liu, Serge J. Be- longie, and Jan Kautz. Multimodal unsupervised image- to-image translation. In ECCV, pages 179–196,
work page 2018
-
[12]
[Isola et al., 2017] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with con- ditional adversarial networks. InCVPR, pages 5967–5976,
work page 2017
-
[13]
Perceptual losses for real-time style transfer and super-resolution
[Johnson et al., 2016] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, pages 694–711,
work page 2016
-
[14]
Learning to dis- cover cross-domain relations with generative adversarial networks
[Kim et al., 2017] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, and Jiwon Kim. Learning to dis- cover cross-domain relations with generative adversarial networks. In ICML, pages 1857–1865,
work page 2017
-
[15]
Adam: A Method for Stochastic Optimization
[Kingma and Ba, 2014] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi
[Ledig et al., 2017] Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew P. Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo-realistic single im- age super-resolution using a generative adversarial net- work. In CVPR, pages 105–114,
work page 2017
-
[17]
Diverse image-to-image translation via disentangled representa- tions
[Lee et al., 2018] Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Diverse image-to-image translation via disentangled representa- tions. In ECCV, pages 36–52,
work page 2018
-
[18]
Maskgan: Towards diverse and interactive facial image manipulation
[Lee et al., 2019] Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. Maskgan: Towards diverse and interactive facial image manipulation. Technical Report,
work page 2019
-
[19]
Sim- ulating makeup through physics-based manipulation of in- trinsic image layers
[Li et al., 2015] Chen Li, Kun Zhou, and Stephen Lin. Sim- ulating makeup through physics-based manipulation of in- trinsic image layers. In CVPR, pages 4621–4629,
work page 2015
-
[20]
Beautygan: Instance-level facial makeup transfer with deep generative adversarial network
[Li et al., 2018] Tingting Li, Ruihe Qian, Chao Dong, Si Liu, Qiong Yan, Wenwu Zhu, and Liang Lin. Beautygan: Instance-level facial makeup transfer with deep generative adversarial network. In ACM MM, pages 645–653,
work page 2018
-
[21]
Visual attribute transfer through deep image analogy
[Liao et al., 2017] Jing Liao, Yuan Yao, Lu Yuan, Gang Hua, and Sing Bing Kang. Visual attribute transfer through deep image analogy. ACM Trans. Graph., 36(4):120:1–120:15,
work page 2017
-
[22]
Makeup like a superstar: Deep lo- calized makeup transfer network
[Liu et al., 2016] Si Liu, Xinyu Ou, Ruihe Qian, Wei Wang, and Xiaochun Cao. Makeup like a superstar: Deep lo- calized makeup transfer network. In IJCAI, pages 2568– 2575,
work page 2016
-
[23]
[Liu et al., 2018] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Im- age inpainting for irregular holes using partial convolu- tions. In ECCV, pages 89–105,
work page 2018
-
[24]
Dis- entangled person image generation
[Ma et al., 2018] Liqian Ma, Qianru Sun, Stamatios Geor- goulis, Luc Van Gool, Bernt Schiele, and Mario Fritz. Dis- entangled person image generation. In CVPR, pages 99– 108,
work page 2018
-
[25]
[Mao et al., 2017] Xudong Mao, Qing Li, Haoran Xie, Ray- mond Y . K. Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In ICCV, pages 2813–2821,
work page 2017
-
[26]
Unsupervised attention-guided image-to-image translation
[Mejjati et al., 2018] Youssef Alami Mejjati, Christian Richardt, James Tompkin, Darren Cosker, and Kwang In Kim. Unsupervised attention-guided image-to-image translation. In NeurIPS, pages 3697–3707,
work page 2018
-
[27]
Martinez, Alberto Sanfeliu, and Francesc Moreno-Noguer
[Pumarola et al., 2018] Albert Pumarola, Antonio Agudo, Aleix M. Martinez, Alberto Sanfeliu, and Francesc Moreno-Noguer. Ganimation: Anatomically-aware facial animation from a single image. In ECCV, pages 835–851,
work page 2018
-
[28]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
[Radford et al., 2015] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. CoRR, abs/1511.06434,
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
[Russakovsky et al., 2015] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Fei-Fei Li. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252,
work page 2015
-
[30]
Very deep convolutional networks for large-scale image recognition
[Simonyan and Zisserman, 2015] Karen Simonyan and An- drew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR,
work page 2015
-
[31]
Smith, Li Zhang, Jonathan Brandt, Zhe Lin, and Jianchao Yang
[Smith et al., 2013] Brandon M. Smith, Li Zhang, Jonathan Brandt, Zhe Lin, and Jianchao Yang. Exemplar-based face parsing. In CVPR, pages 3484–3491,
work page 2013
-
[32]
[Tong et al., 2007] Wai-Shun Tong, Chi-Keung Tang, Michael S. Brown, and Ying-Qing Xu. Example-based cosmetic transfer. In PCCGA, pages 211–218,
work page 2007
-
[33]
Instance Normalization: The Missing Ingredient for Fast Stylization
[Ulyanov et al., 2016] Dmitry Ulyanov, Andrea Vedaldi, and Victor S. Lempitsky. Instance normalization: The miss- ing ingredient for fast stylization. CoRR, abs/1607.08022,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
[Wang et al., 2004] Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Processing, 13(4):600–612,
work page 2004
-
[35]
[Yang et al., 2018] Chao Yang, Taehwan Kim, Ruizhe Wang, Hao Peng, and C.-C. Jay Kuo. Show, attend and translate: Unsupervised image translation with self-regularization and attention. CoRR, abs/1806.06195,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Dualgan: Unsupervised dual learning for image-to-image translation
[Yi et al., 2017] Zili Yi, Hao (Richard) Zhang, Ping Tan, and Minglun Gong. Dualgan: Unsupervised dual learning for image-to-image translation. In ICCV, pages 2868–2876,
work page 2017
-
[37]
Bisenet: Bi- lateral segmentation network for real-time semantic seg- mentation
[Yu et al., 2018] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. Bisenet: Bi- lateral segmentation network for real-time semantic seg- mentation. In ECCV, pages 334–349,
work page 2018
-
[38]
Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks
[Zhang et al., 2017] Han Zhang, Tao Xu, and Hongsheng Li. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In ICCV, pages 5908–5916,
work page 2017
-
[39]
Generative adversarial network with spatial attention for face attribute editing
[Zhang et al., 2018] Gang Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. Generative adversarial network with spatial attention for face attribute editing. In ECCV, pages 422–437,
work page 2018
-
[40]
[Zhao et al., 2017] Hengshuang Zhao, Jianping Shi, Xiao- juan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, pages 6230–6239,
work page 2017
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.