Distill-2MD-MTL: Data Distillation based on Multi-Dataset Multi-Domain Multi-Task Frame Work to Solve Face Related Tasksks, Multi Task Learning, Semi-Supervised Learning
Pith reviewed 2026-05-25 01:28 UTC · model grok-4.3
The pith
A multi-task learning method with data distillation improves accuracy on face tasks like age and gender by using multiple datasets from different domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
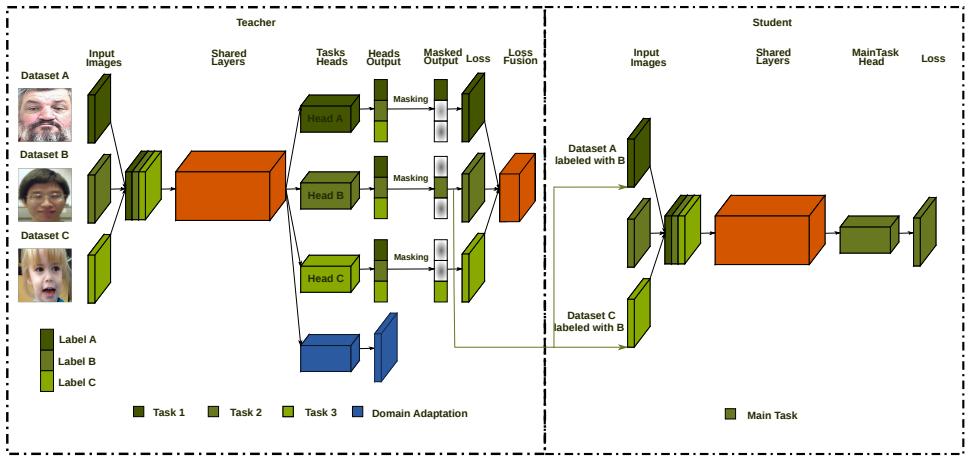
The Distill-2MD-MTL framework performs several face tasks simultaneously on weakly labeled multi-domain datasets through a multi-task learning architecture that accommodates missing labels, paired with an MTL-based data distillation process that transfers knowledge to unlabeled samples and reduces domain shift.
What carries the argument
The MTL-based data distillation framework, which trains on multiple related tasks across domains and uses the joint predictions to label and refine training on unlabeled data from different domains.
If this is right
- Joint training raises accuracy on each task above the corresponding single-task baseline.
- Adding datasets from different domains improves generalization and reduces the effect of domain differences.
- Data distillation inside the multi-task framework produces more accurate labels for unlabeled cross-domain data than distillation inside single-task training.
- The added dynamic learning-rate method allows automatic adjustment of step size during optimization.
Where Pith is reading between the lines
- The approach could lower labeling costs for new face-analysis applications if the positive transfer holds for additional tasks.
- Similar distillation across tasks might apply to other groups of related visual attributes where full labeling is expensive.
- Experiments that deliberately vary the degree of task overlap would show the boundary at which joint training stops helping.
Load-bearing premise
The face-related tasks share enough common structure that joint training and distillation produce positive transfer rather than interference from weak or missing labels.
What would settle it
A controlled comparison in which the multi-task distilled model shows lower accuracy than the single-task baseline on at least one task when trained and tested on the same data splits would falsify the performance claim.
Figures



read the original abstract
We propose a new semi-supervised learning method on face-related tasks based on Multi-Task Learning (MTL) and data distillation. The proposed method exploits multiple datasets with different labels for different-but-related tasks such as simultaneous age, gender, race, facial expression estimation. Specifically, when there are only a few well-labeled data for a specific task among the multiple related ones, we exploit the labels of other related tasks in different domains. Our approach is composed of (1) a new MTL method which can deal with weakly labeled datasets and perform several tasks simultaneously, and (2) an MTL-based data distillation framework which enables network generalization for the training and test data from different domains. Experiments show that the proposed multi-task system performs each task better than the baseline single task. It is also demonstrated that using different domain datasets along with the main dataset can enhance network generalization and overcome the domain differences between datasets. Also, comparing data distillation both on the baseline and MTL framework, the latter shows more accurate predictions on unlabeled data from different domains. Furthermore, by proposing a new learning-rate optimization method, our proposed network is able to dynamically tune its learning rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Distill-2MD-MTL, a semi-supervised framework combining multi-task learning (MTL) with data distillation for simultaneous face-related tasks (age, gender, race, expression estimation) across multiple weakly-labeled datasets from different domains. It claims that the MTL approach outperforms single-task baselines on each task, that incorporating cross-domain data improves generalization and overcomes domain shifts, that MTL-based distillation yields more accurate predictions on unlabeled cross-domain data than baseline distillation, and that a new dynamic learning-rate optimization method further aids training.
Significance. If the empirical claims are substantiated with rigorous experiments, the work could provide a practical approach to leveraging heterogeneous face datasets for multi-attribute prediction under label scarcity and domain shift. The integration of MTL with distillation to handle missing labels across tasks is a plausible direction, though its advantage over simpler data-augmentation or domain-adaptation baselines would need clear quantification.
major comments (2)
- [Abstract] Abstract: the central empirical claims (MTL outperforms single-task baselines; MTL distillation beats baseline distillation on cross-domain data) are asserted without any quantitative results, baseline descriptions, dataset sizes, label-missing mechanisms, loss-weighting scheme, or ablation isolating positive transfer from data-volume effects, rendering the claims unevaluable.
- [Abstract] The load-bearing assumption that age/gender/race/expression share sufficient structure for net positive MTL transfer (rather than interference or error propagation from weak labels) is stated but not supported by any mentioned ablation or analysis of task correlations or label noise propagation through the shared backbone.
minor comments (2)
- [Title] Title contains an obvious typo: 'Tasksks' should be 'Tasks'.
- [Abstract] The abstract mentions 'a new learning-rate optimization method' but provides no description of the method, its update rule, or comparison to standard schedulers such as cosine annealing or AdamW defaults.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We will revise the manuscript to address the concerns about evaluability of claims and support for the MTL transfer assumption.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (MTL outperforms single-task baselines; MTL distillation beats baseline distillation on cross-domain data) are asserted without any quantitative results, baseline descriptions, dataset sizes, label-missing mechanisms, loss-weighting scheme, or ablation isolating positive transfer from data-volume effects, rendering the claims unevaluable.
Authors: We agree the abstract would be stronger with quantitative highlights and setup details. The full paper reports experiments on multiple face datasets with specific metrics showing MTL gains over single-task baselines and improved distillation accuracy on cross-domain data. We will revise the abstract to include key numerical improvements, dataset sizes, brief baseline descriptions, and note on loss weighting. Our comparisons use matched data volumes for MTL vs. single-task to help isolate transfer effects; we will clarify this explicitly. revision: yes
-
Referee: [Abstract] The load-bearing assumption that age/gender/race/expression share sufficient structure for net positive MTL transfer (rather than interference or error propagation from weak labels) is stated but not supported by any mentioned ablation or analysis of task correlations or label noise propagation through the shared backbone.
Authors: The reported results demonstrate consistent outperformance of MTL over single-task baselines, providing empirical support for net positive transfer. However, the manuscript does not include dedicated ablations on task correlations or explicit analysis of label noise propagation. We will add a concise discussion section referencing the observed gains and potential for interference, while acknowledging this as a limitation; full new ablations would require additional experiments. revision: partial
Circularity Check
No circularity; empirical claims rest on external experiments
full rationale
The paper describes an MTL plus data-distillation framework for face tasks and reports experimental gains over single-task baselines and cross-domain distillation. No equations, parameter-fitting steps, or derivation chain appear in the provided text. Claims are validated by direct comparisons on held-out data rather than by any self-referential construction, self-citation load-bearing premise, or renaming of known results. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Neural Networks , volume 64, pages 59 – 63, 2015
Challenges in representation learning: A report on three ma- chine learning contests. In Neural Networks , volume 64, pages 59 – 63, 2015. Special Issue on Deep Learning of Representations
work page 2015
-
[2]
Learning efficient object detection mod- els with knowledge distillation
Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, and Man- mohan Chandraker. Learning efficient object detection mod- els with knowledge distillation. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 742–751. Curran Associates, Inc., 2017
work page 2017
-
[3]
Neil: Extracting visual knowledge from web data
Xinlei Chen, Abhinav Shrivastava, and Abhinav Gupta. Neil: Extracting visual knowledge from web data. InInternational Conference on Computer Vision (ICCV), December 2013
work page 2013
-
[4]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and An- drew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InICML, 2018
work page 2018
-
[5]
Stargan: Unified genera- tive adversarial networks for multi-domain image-to-image translation
Yunjey Choi, Min-Je Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified genera- tive adversarial networks for multi-domain image-to-image translation. In CVPR, 2017
work page 2017
-
[6]
Facenet2expnet: Regularizing a deep face recognition net for expression recognition
Hui Ding, Shaohua Kevin Zhou, and Rama Chellappa. Facenet2expnet: Regularizing a deep face recognition net for expression recognition. 2017
work page 2017
-
[7]
E. Eidinger, R. Enbar, and T. Hassner. Age and gender es- timation of unfiltered faces. In IEEE Transactions on Infor- mation Forensics and Security, volume 9, pages 2170–2179, Dec 2014
work page 2014
-
[8]
Object detection with discriminatively trained part-based models
Pedro F Felzenszwalb, Ross B Girshick, David McAllester, and Deva Ramanan. Object detection with discriminatively trained part-based models. In IEEE transactions on pattern analysis and machine intelligence, volume 32, pages 1627–
-
[9]
Tommaso Furlanello, Zachary C Lipton, Michael Tschan- nen, Laurent Itti, and Anima Anandkumar. Born again neural networks. In arXiv preprint arXiv:1805.04770, 2018
-
[10]
Cross Modal Distillation for Supervision Transfer
Saurabh Gupta, Judy Hoffman, and Jitendra Malik. Cross modal distillation for supervision transfer. In CoRR, volume abs/1507.00448, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop, 2015
work page 2015
-
[12]
Hospedales, Neil Martin Robertson, and Yongxin Yang
Guosheng Hu, Li Liu, Yang Yuan, Zehao Yu, Yang Hua, Zhihong Zhang, Fumin Shen, Ling Shao, Timothy M. Hospedales, Neil Martin Robertson, and Yongxin Yang. Deep multi-task learning to recognise subtle facial expres- sions of mental states. In ECCV, 2018
work page 2018
-
[13]
A Spatio-Temporal Descriptor Based on 3D-Gradients
Alexander Klaser, Marcin Marszalek, and Cordelia Schmid. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Mark Everingham, Chris Needham, and Roberto Fraile, edi- tors, BMVC 2008 - 19th British Machine Vision Conference, pages 275:1–10, Leeds, United Kingdom, Sept. 2008. British Machine Vision Association
work page 2008
-
[14]
Imagenet classification with deep convolutional neural net- works
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works. In Advances in neural information processing sys- tems, pages 1097–1105, 2012
work page 2012
-
[15]
Temporal Ensembling for Semi-Supervised Learning
Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In CoRR, volume abs/1610.02242, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Facial expression recog- nition with faster r-cnn
Jiaxing Li, Dexiang Zhang, Jingjing Zhang, Jun Zhang, Teng Li, Yi Xia, Qing Yan, and Lina Xun. Facial expression recog- nition with faster r-cnn. In Procedia Computer Science, vol- ume 107, pages 135 – 140, 2017. ICICT2017
work page 2017
-
[17]
L. Li, G. Wang, and Li Fei-Fei. Optimol: automatic online picture collection via incremental model learning. In CVPR, pages 1–8, June 2007
work page 2007
-
[18]
Deep facial expression recog- nition: A survey
Shan Li and Weihong Deng. Deep facial expression recog- nition: A survey. In CoRR, volume abs/1804.08348, 2018
-
[19]
Sijin LI, Zhi-Qiang Liu, and Antoni B. Chan. Heteroge- neous multi-task learning for human pose estimation with deep convolutional neural network. In CVPR, June 2014
work page 2014
- [20]
-
[21]
Model compression via distillation and quantization
Antonio Polino, Razvan Pascanu, and Dan Alistarh. Model compression via distillation and quantization. In Interna- tional Conference on Learning Representations, 2018
work page 2018
-
[22]
Data Distillation: Towards Omni-Supervised Learning
Ilija Radosavovic, Piotr Doll ´ar, Ross Girshick, Georgia Gkioxari, and Kaiming He. Data Distillation: Towards Omni-Supervised Learning. In CVPR, 2018
work page 2018
-
[23]
Semi-Supervised Learning with Ladder Networks
Antti Rasmus, Harri Valpola, Mikko Honkala, Mathias Berglund, and Tapani Raiko. Semi-supervised learning with ladder network. In CoRR, volume abs/1507.02672, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery
Zhongzheng Ren and Yong Jae Lee. Cross-domain self- supervised multi-task feature learning using synthetic im- agery. In CoRR, volume abs/1711.09082, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
K. Ricanek and T. Tesafaye. Morph: a longitudinal image database of normal adult age-progression. In 7th Interna- tional Conference on Automatic Face and Gesture Recogni- tion (FGR06), pages 341–345, April 2006
work page 2006
-
[26]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[27]
Adapting visual category models to new domains
Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell. Adapting visual category models to new domains. In Kostas Daniilidis, Petros Maragos, and Nikos Paragios, editors, ECCV, pages 213–226, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg
work page 2010
-
[28]
H. J. Scudder. Probability of error of some adaptive pattern- recognition machines. In IEEE Trans. Information Theory , volume 11, pages 363–371, 1965
work page 1965
-
[29]
A survey on semi- supervised feature selection methods
Razieh Sheikhpour, Mehdi Agha Sarram, Sajjad Gharaghani, and Mohammad Ali Zare Chahooki. A survey on semi- supervised feature selection methods. In Pattern Recogni- tion, volume 64, pages 141–158. Elsevier, 2017. 7
work page 2017
-
[30]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep con- volutional networks for large-scale image recognition. In CoRR, volume abs/1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
L. N. Smith. Cyclical learning rates for training neural net- works. In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 464–472, March 2017
work page 2017
-
[32]
Mitra, Yangyan Li, and Leonidas Guibas
Hao Su, Qixing Huang, Niloy J. Mitra, Yangyan Li, and Leonidas Guibas. Estimating image depth using shape col- lections. In Transactions on Graphics (Special issue of SIG- GRAPH 2014), 2014
work page 2014
-
[33]
Deeply learned face representations are sparse, selective, and robust
Yi Sun, Xiaogang Wang, and Xiaoou Tang. Deeply learned face representations are sparse, selective, and robust. In CVPR, pages 2892–2900, 2015
work page 2015
-
[34]
Scalable, High-Quality Object Detection
Christian Szegedy, Scott Reed, Dumitru Erhan, Dragomir Anguelov, and Sergey Ioffe. Scalable, high-quality object detection. In arXiv preprint arXiv:1412.1441, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [35]
-
[36]
Facial ex- pression recognition by de-expression residue learning
Huiyuan Yang, Umur Ciftci, and Lijun Yin. Facial ex- pression recognition by de-expression residue learning. In CVPR, 2018
work page 2018
-
[37]
Unsupervised word sense disambiguation rivaling supervised methods
David Yarowsky. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the 33rd an- nual meeting on Association for Computational Linguistics , pages 189–196. Association for Computational Linguistics, 1995
work page 1995
-
[38]
Sergey Zagoruyko and Nikos Komodakis. Paying more at- tention to attention: Improving the performance of convolu- tional neural networks via attention transfer. In ICLR, 2017
work page 2017
-
[39]
Facial expres- sion recognition with inconsistently annotated datasets
Jiabei Zeng, Shiguang Shan, and Xilin Chen. Facial expres- sion recognition with inconsistently annotated datasets. In ECCV, September 2018
work page 2018
-
[40]
Joint pose and expression modeling for facial expression recognition
Feifei Zhang, Tianzhu Zhang, Qirong Mao, and Changsheng Xu. Joint pose and expression modeling for facial expression recognition. In CVPR, pages 3359–3368, 2018
work page 2018
-
[41]
Facial landmark detection by deep multi-task learning
Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xi- aoou Tang. Facial landmark detection by deep multi-task learning. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, ECCV, pages 94–108, Cham,
-
[42]
Springer International Publishing
-
[43]
Semi-supervised learning literature survey
Xiaojin Zhu. Semi-supervised learning literature survey. In Computer Science, University of Wisconsin-Madison , vol- ume 2, page 4, 2006. 8
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.