Automating concept-drift detection by self-evaluating predictive model degradation
Pith reviewed 2026-05-24 19:38 UTC · model grok-4.3
The pith
A methodology detects class-based concept drift by monitoring degradation in model prediction quality on new data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prediction-quality degradation on new data can be directly used to detect and describe class-based concept drift, defined as the appearance of samples that do not match the class labels known to the current model, with experiments confirming this works on both synthetic and real-world datasets.
What carries the argument
Self-evaluation of predictive model degradation that links observable quality drops to changes in class-label distributions.
If this is right
- Models can trigger their own updates when class-based drift is detected through quality monitoring.
- The same self-evaluation process both detects the presence of drift and describes its effect on class distributions.
- No external labeled data is required to assess whether the original training distribution still holds.
- The approach applies across synthetic data with controlled shifts and real-world public datasets.
Where Pith is reading between the lines
- Extending the method to other drift types might work if degradation signals remain reliable beyond class changes.
- Production pipelines could reduce manual oversight by letting models flag when retraining is needed based on this signal alone.
- Testing the approach on streaming data with gradual rather than abrupt class shifts would check its sensitivity limits.
Load-bearing premise
Observable drops in prediction quality on new data can be attributed to class-based concept drift without interference from noise or other kinds of distribution shifts.
What would settle it
A collection of new data where class labels have changed but measured prediction quality stays stable, or where quality drops sharply with no change in class labels.
Figures


read the original abstract
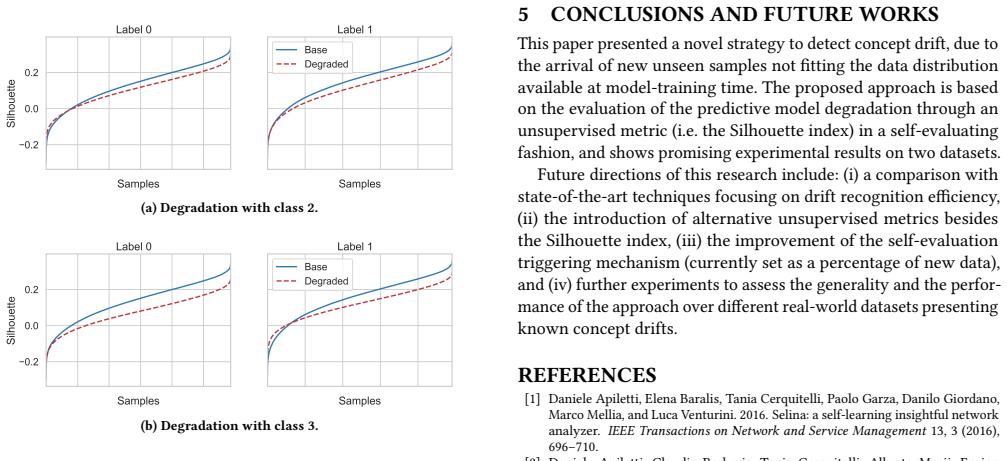
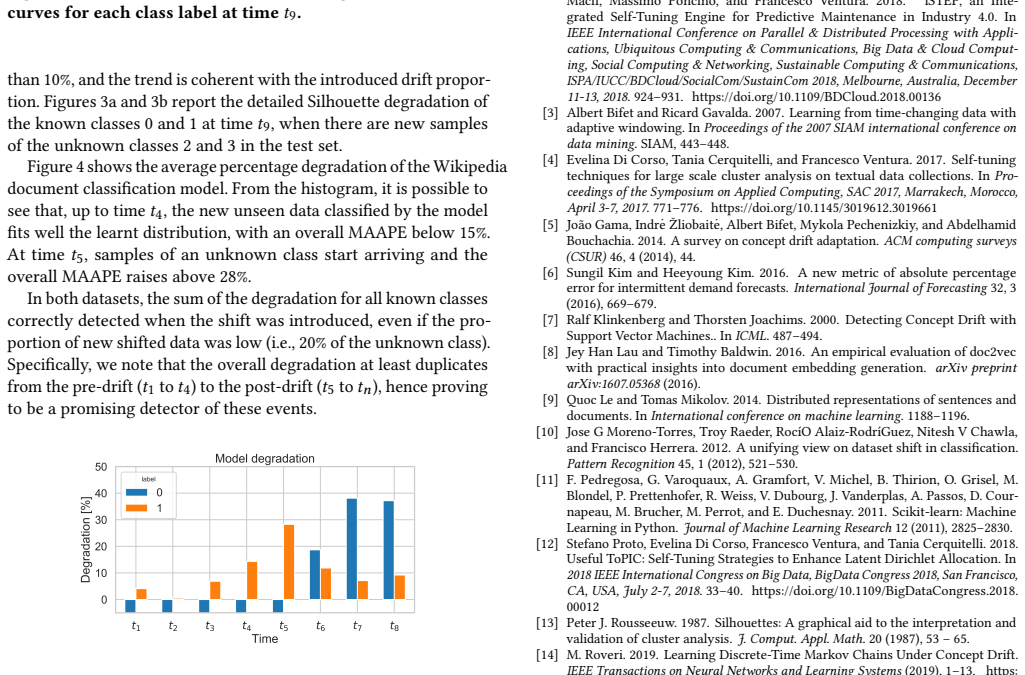
A key aspect of automating predictive machine learning entails the capability of properly triggering the update of the trained model. To this aim, suitable automatic solutions to self-assess the prediction quality and the data distribution drift between the original training set and the new data have to be devised. In this paper, we propose a novel methodology to automatically detect prediction-quality degradation of machine learning models due to class-based concept drift, i.e., when new data contains samples that do not fit the set of class labels known by the currently-trained predictive model. Experiments on synthetic and real-world public datasets show the effectiveness of the proposed methodology in automatically detecting and describing concept drift caused by changes in the class-label data distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel methodology to automatically detect prediction-quality degradation of machine learning models due to class-based concept drift, i.e., when new data contains samples that do not fit the set of class labels known by the currently-trained predictive model. It asserts that experiments on synthetic and real-world public datasets show the effectiveness of the proposed methodology in automatically detecting and describing concept drift caused by changes in the class-label data distributions.
Significance. If the methodology holds, it addresses an important practical problem in maintaining deployed ML models under non-stationary conditions by enabling self-triggered updates based on observable performance degradation. The emphasis on class-label distribution changes and the use of both synthetic and real-world datasets are positive elements for demonstrating relevance.
major comments (2)
- [Abstract] Abstract: The assertion that 'Experiments on synthetic and real-world public datasets show the effectiveness of the proposed methodology' is unsupported because the abstract (and visible text) provides no description of the detection algorithm, the self-evaluation mechanism, evaluation metrics for degradation, baselines, or statistical tests.
- [Abstract] Abstract: The framing that observable degradation can be directly attributed to class-based concept drift does not address potential confounding factors such as label noise or other distribution shifts; no controls or discussion for isolating this specific form of drift are mentioned.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and agree that the abstract requires strengthening to better support its claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experiments on synthetic and real-world public datasets show the effectiveness of the proposed methodology' is unsupported because the abstract (and visible text) provides no description of the detection algorithm, the self-evaluation mechanism, evaluation metrics for degradation, baselines, or statistical tests.
Authors: We agree that the abstract, as a concise summary, does not describe the detection algorithm, self-evaluation mechanism, metrics, baselines, or statistical tests. The full manuscript provides these details in the methodology and experiments sections. To better substantiate the abstract's assertion, we will revise the abstract to include a brief overview of the methodology and evaluation approach. revision: yes
-
Referee: [Abstract] Abstract: The framing that observable degradation can be directly attributed to class-based concept drift does not address potential confounding factors such as label noise or other distribution shifts; no controls or discussion for isolating this specific form of drift are mentioned.
Authors: The paper specifically addresses class-based concept drift defined as new samples outside known class labels. The experiments focus on this form of drift, but we acknowledge that potential confounders such as label noise or other shifts are not explicitly discussed or controlled for. We will add a discussion of these factors and how the methodology isolates class-label distribution changes. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical methodology for detecting class-based concept drift via observable prediction-quality degradation, validated through experiments on synthetic and real-world datasets. No equations, derivations, or first-principles claims appear in the abstract or described content that reduce to fitted parameters, self-definitions, or self-citation chains. The contribution is self-contained as an applied detection approach without load-bearing mathematical steps that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Daniele Apiletti, Elena Baralis, Tania Cerquitelli, Paolo Garza, Danilo Giordano, Marco Mellia, and Luca Venturini. 2016. Selina: a self-learning insightful network analyzer. IEEE Transactions on Network and Service Management 13, 3 (2016), 696–710
work page 2016
-
[2]
Daniele Apiletti, Claudia Barberis, Tania Cerquitelli, Alberto Macii, Enrico Macii, Massimo Poncino, and Francesco Ventura. 2018. iSTEP, an Inte- grated Self-Tuning Engine for Predictive Maintenance in Industry 4.0. In IEEE International Conference on Parallel & Distributed Processing with Appli- cations, Ubiquitous Computing & Communications, Big Data & ...
-
[3]
Albert Bifet and Ricard Gavalda. 2007. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM international conference on data mining. SIAM, 443–448
work page 2007
-
[4]
Evelina Di Corso, Tania Cerquitelli, and Francesco Ventura. 2017. Self-tuning techniques for large scale cluster analysis on textual data collections. In Pro- ceedings of the Symposium on Applied Computing, SAC 2017, Marrakech, Morocco, April 3-7, 2017. 771–776. https://doi.org/10.1145/3019612.3019661
-
[5]
João Gama, Indr˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A survey on concept drift adaptation. ACM computing surveys (CSUR) 46, 4 (2014), 44
work page 2014
-
[6]
Sungil Kim and Heeyoung Kim. 2016. A new metric of absolute percentage error for intermittent demand forecasts. International Journal of Forecasting 32, 3 (2016), 669–679
work page 2016
-
[7]
Ralf Klinkenberg and Thorsten Joachims. 2000. Detecting Concept Drift with Support Vector Machines.. In ICML. 487–494
work page 2000
-
[8]
Jey Han Lau and Timothy Baldwin. 2016. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv preprint arXiv:1607.05368 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In International conference on machine learning . 1188–1196
work page 2014
-
[10]
Jose G Moreno-Torres, Troy Raeder, RocíO Alaiz-RodríGuez, Nitesh V Chawla, and Francisco Herrera. 2012. A unifying view on dataset shift in classification. Pattern Recognition 45, 1 (2012), 521–530
work page 2012
-
[11]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research 12 (2011), 2825–2830
work page 2011
-
[12]
Stefano Proto, Evelina Di Corso, Francesco Ventura, and Tania Cerquitelli. 2018. Useful ToPIC: Self-Tuning Strategies to Enhance Latent Dirichlet Allocation. In 2018 IEEE International Congress on Big Data, BigData Congress 2018, San Francisco, CA, USA, July 2-7, 2018 . 33–40. https://doi.org/10.1109/BigDataCongress.2018. 00012
- [13]
-
[14]
M. Roveri. 2019. Learning Discrete-Time Markov Chains Under Concept Drift. IEEE Transactions on Neural Networks and Learning Systems (2019), 1–13. https: //doi.org/10.1109/TNNLS.2018.2886956
-
[15]
Y. Sun, K. Tang, Z. Zhu, and X. Yao. 2018. Concept Drift Adaptation by Exploiting Historical Knowledge. IEEE Transactions on Neural Networks and Learning Systems 29, 10 (Oct 2018), 4822–4832. https://doi.org/10.1109/TNNLS.2017.2775225
-
[16]
Pang-Ning Tan, Michael Steinbach, and Vipin Kumar. 2005. Introduction to Data Mining, (First Edition). Addison-Wesley Longman Publishing Co., Inc., Boston, 4 MA, USA
work page 2005
-
[17]
Alexey Tsymbal. 2004. The problem of concept drift: definitions and related work. Computer Science Department, Trinity College Dublin 106, 2 (2004), 58
work page 2004
-
[18]
Francesco Ventura, Stefano Proto, Daniele Apiletti, Tania Cerquitelli, Simone Panicucci, Elena Baralis, Enrico Macii, and Alberto Macii. 2019. A new un- supervised predictive-model self-assessment approach that SCALEs. In 2019 IEEE International Congress on Big Data (BigData Congress) . IEEE, 144–148. https://doi.org/10.1109/BigDataCongress.2019.00033
-
[19]
P. Vorburger and A. Bernstein. 2006. Entropy-based Concept Shift Detection. In Sixth International Conference on Data Mining (ICDM’06). 1113–1118. https: //doi.org/10.1109/ICDM.2006.66
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.