Automated Surgical Activity Recognition with One Labeled Sequence
Pith reviewed 2026-05-24 18:47 UTC · model grok-4.3
The pith
Automated recognition of surgical activities from motion data is feasible using only one labeled sequence for training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
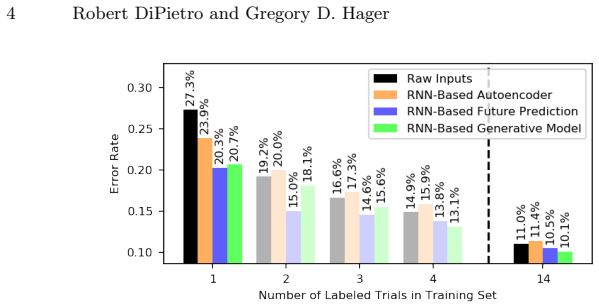
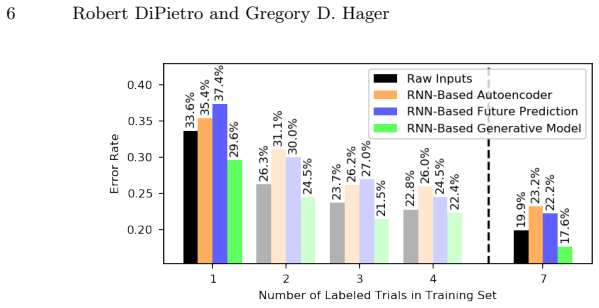
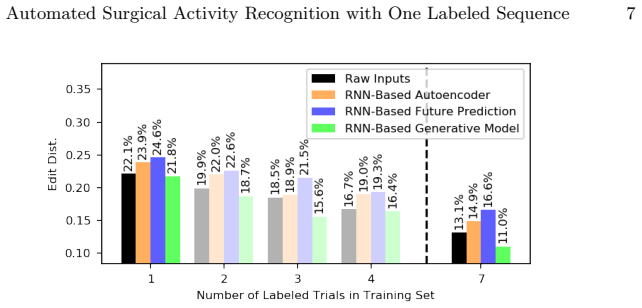
We demonstrate feasibility of automated activity recognition in robot-assisted surgery under the assumption that as little as one annotated sequence is available for training, and we show that learning representations in an unsupervised fashion before the recognition phase leads to significant gains in performance.
What carries the argument
Unsupervised representation learning on unlabeled motion sequences, followed by supervised training on a single labeled sequence for activity classification.
If this is right
- Expert annotation effort for surgical datasets can be reduced from many sequences to one without losing all recognition capability.
- Unsupervised pretraining on motion data becomes a standard first step when labeled examples are scarce.
- Recognition models can be deployed in new procedures or hospitals with only minimal new labeling.
- The community faces an explicit open problem of maximizing accuracy under the one-sequence constraint.
Where Pith is reading between the lines
- The same one-sequence approach could be tested in other high-cost annotation domains such as industrial robotics or medical imaging.
- Selecting which single sequence to label might matter more than the paper explores; a representative sequence could be chosen by diversity metrics on unlabeled data.
- If the unsupervised step captures general motion primitives, the method might extend to zero labeled sequences via clustering or nearest-neighbor matching.
Load-bearing premise
That one annotated sequence is representative enough for the model to generalize to other sequences that may differ in surgeon technique, patient anatomy, or procedure variations.
What would settle it
Measure recognition accuracy on a held-out set of sequences performed by different surgeons or on different patients; if accuracy falls below a level needed for practical use, the feasibility claim does not hold.
Figures



read the original abstract
Prior work has demonstrated the feasibility of automated activity recognition in robot-assisted surgery from motion data. However, these efforts have assumed the availability of a large number of densely-annotated sequences, which must be provided manually by experts. This process is tedious, expensive, and error-prone. In this paper, we present the first analysis under the assumption of scarce annotations, where as little as one annotated sequence is available for training. We demonstrate feasibility of automated recognition in this challenging setting, and we show that learning representations in an unsupervised fashion, before the recognition phase, leads to significant gains in performance. In addition, our paper poses a new challenge to the community: how much further can we push performance in this important yet relatively unexplored regime?
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to present the first analysis of automated surgical activity recognition from motion data under the scarce-annotation regime of a single labeled sequence. It asserts that feasibility is demonstrated in this setting and that unsupervised representation learning prior to the supervised recognition phase yields significant performance gains, while posing an open challenge for further progress.
Significance. If the central generalization result holds under proper cross-sequence evaluation, the work would be significant for reducing the annotation burden in robot-assisted surgery, a domain where dense expert labeling is costly. Explicit demonstration of gains from unsupervised pretraining would be a concrete strength worth building upon.
major comments (2)
- [Experiments] The feasibility claim rests on cross-sequence generalization from a single labeled training sequence. The experimental design must therefore establish that held-out test sequences differ in surgeon technique, patient anatomy, or procedure variations; without such explicit variation or a clear description of the data split (e.g., in the Experiments section), the result does not yet support the stated feasibility.
- [Results] Quantitative evidence for the claimed 'significant gains' from unsupervised pretraining is load-bearing. The manuscript should report concrete metrics, baselines, and statistical tests comparing the unsupervised-then-supervised pipeline against a purely supervised baseline trained on the same single sequence (e.g., in the Results tables or figures).
minor comments (1)
- [Methods] Notation for the unsupervised representation stage and the subsequent recognition head should be introduced consistently in the Methods section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the experimental design and results.
read point-by-point responses
-
Referee: [Experiments] The feasibility claim rests on cross-sequence generalization from a single labeled training sequence. The experimental design must therefore establish that held-out test sequences differ in surgeon technique, patient anatomy, or procedure variations; without such explicit variation or a clear description of the data split (e.g., in the Experiments section), the result does not yet support the stated feasibility.
Authors: We agree that a clear description of the data split and inter-sequence variations is required to substantiate the cross-sequence generalization claim. The experiments use the JIGSAWS dataset, which contains sequences from different surgeons with natural differences in technique and execution style. In the revised manuscript we will expand the Experiments section with an explicit description of the single-sequence training split, including a table or paragraph documenting surgeon identity, task variations, and other differences across the held-out test sequences. revision: yes
-
Referee: [Results] Quantitative evidence for the claimed 'significant gains' from unsupervised pretraining is load-bearing. The manuscript should report concrete metrics, baselines, and statistical tests comparing the unsupervised-then-supervised pipeline against a purely supervised baseline trained on the same single sequence (e.g., in the Results tables or figures).
Authors: While the manuscript reports performance improvements from unsupervised pretraining, we acknowledge that additional concrete metrics, direct baseline comparisons, and statistical tests would better support the significance claim. In the revision we will add an expanded results table (or new figure) showing specific metrics such as accuracy and F1-score for the unsupervised-then-supervised pipeline versus the purely supervised baseline on the single labeled sequence, along with statistical significance tests (e.g., paired t-test or McNemar's test) computed over multiple random seeds or cross-validation folds. revision: yes
Circularity Check
No circularity: empirical ML feasibility study with no derivations
full rationale
The paper is an empirical study demonstrating activity recognition feasibility from one labeled surgical sequence plus unsupervised pretraining. No equations, derivations, predictions, or first-principles results are claimed. Claims rest on experimental performance gains rather than any self-referential definitions, fitted inputs renamed as predictions, or self-citation chains. The central feasibility result is evaluated on held-out data and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Biomedical Engineering 64(9), 2025–2041 (2017)
Ahmidi, N., Tao, L., Sefati, S., Gao, Y., Lea, C., Haro, B.B., Zappella, L., Khu- danpur, S., Vidal, R., Hager, G.D.: A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Transactions on Biomedical Engineering 64(9), 2025–2041 (2017)
work page 2025
-
[2]
New England Journal of Medicine 369(15), 1434–1442 (2013)
Birkmeyer, J.D., Finks, J.F., O’reilly, A., Oerline, M., Carlin, A.M., Nunn, A.R., Dimick, J., Banerjee, M., Birkmeyer, N.J.: Surgical skill and complication rates af- ter bariatric surgery. New England Journal of Medicine 369(15), 1434–1442 (2013)
work page 2013
-
[3]
Bishop, C.M.: Mixture density networks. Tech. rep., Aston University (1994)
work page 1994
-
[4]
Bodenstedt, S., Wagner, M., Kati´ c, D., Mietkowski, P., Mayer, B., Kenngott, H., M¨ uller-Stich, B., Dillmann, R., Speidel, S.: Unsupervised temporal context learn- ing using convolutional neural networks for laparoscopic workflow analysis. arXiv preprint arXiv:1702.03684 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
In: In- telligent Robots and Systems (IROS)
Chen, Z., Malpani, A., Chalasani, P., Deguet, A., Vedula, S.S., Kazanzides, P., Taylor, R.H.: Virtual fixture assistance for needle passing and knot tying. In: In- telligent Robots and Systems (IROS). pp. 2343–2350 (2016)
work page 2016
-
[6]
International journal of computer assisted radiol- ogy and surgery (2019)
DiPietro, R., Ahmidi, N., Malpani, A., Waldram, M., Lee, G.I., Lee, M.R., Vedula, S.S., Hager, G.D.: Segmenting and classifying activities in robot-assisted surgery with recurrent neural networks. International journal of computer assisted radiol- ogy and surgery (2019)
work page 2019
-
[7]
International Conference on Medical Image Computing and Computer-Assisted Intervention (2018)
DiPietro, R., Hager, G.D.: Unsupervised learning for surgical motion by learning to predict the future. International Conference on Medical Image Computing and Computer-Assisted Intervention (2018)
work page 2018
-
[8]
Inter- national Conference on Medical Image Computing and Computer-Assisted Inter- vention pp
DiPietro, R., Lea, C., Malpani, A., Ahmidi, N., Vedula, S.S., Lee, G.I., Lee, M.R., Hager, G.D.: Recognizing surgical activities with recurrent neural networks. Inter- national Conference on Medical Image Computing and Computer-Assisted Inter- vention pp. 551–558 (2016)
work page 2016
-
[9]
International journal of computer assisted radiology and surgery 11(6), 987–996 (2016)
Gao, Y., Vedula, S.S., Lee, G.I., Lee, M.R., Khudanpur, S., Hager, G.D.: Query- by-example surgical activity detection. International journal of computer assisted radiology and surgery 11(6), 987–996 (2016)
work page 2016
-
[10]
Gao, Y., Vedula, S.S., Reiley, C.E., Ahmidi, N., Varadarajan, B., Lin, H.C., Tao, L., Zappella, L., Bejar, B., Yuh, D.D., Chen, C.C.G., Vidal, R., Khudanpur, S., Hager, G.D.: Language of surgery: A surgical gesture dataset for human motion modeling. Modeling and Monitoring of Computer Assisted Interventions (2014) Automated Surgical Activity Recognition w...
work page 2014
-
[11]
2016 IEEE International Conference on Robotics and Automation (ICRA) (2016)
Gao, Y., Vedula, S., Lee, G.I., Lee, M.R., Khudanpur, S., Hager, G.D.: Unsuper- vised surgical data alignment with application to automatic activity annotation. 2016 IEEE International Conference on Robotics and Automation (ICRA) (2016)
work page 2016
-
[12]
Neural computation 12(10), 2451–2471 (2000)
Gers, F.A., Schmidhuber, J., Cummins, F.: Learning to forget: Continual prediction with LSTM. Neural computation 12(10), 2451–2471 (2000)
work page 2000
-
[13]
Neural computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
work page 1997
-
[14]
(eds.): Surgical Educators’ Handbook
Jacobs, D.M., Poenaru, D. (eds.): Surgical Educators’ Handbook. Association for Surgical Education (2001)
work page 2001
-
[15]
The Journal of thoracic and cardiovascular surgery 135(1), 196–202 (2008)
Reiley, C.E., Akinbiyi, T., Burschka, D., Chang, D.C., Okamura, A.M., Yuh, D.D.: Effects of visual force feedback on robot-assisted surgical task performance. The Journal of thoracic and cardiovascular surgery 135(1), 196–202 (2008)
work page 2008
-
[16]
segment-level quantitative metrics for surgical skill assessment
Vedula, S.S., Malpani, A., Ahmidi, N., Khudanpur, S., Hager, G., Chen, C.C.G.: Task-level vs. segment-level quantitative metrics for surgical skill assessment. Jour- nal of surgical education 73(3), 482–489 (2016)
work page 2016
-
[17]
Yengera, G., Mutter, D., Marescaux, J., Padoy, N.: Less is more: surgical phase recognition with less annotations through self-supervised pre-training of cnn-lstm networks. arXiv preprint arXiv:1805.08569 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
arXiv preprint arXiv:1812.00033 (2018)
Yu, T., Mutter, D., Marescaux, J., Padoy, N.: Learning from a tiny dataset of manual annotations: a teacher/student approach for surgical phase recognition. arXiv preprint arXiv:1812.00033 (2018)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.