Composition-Aware Image Aesthetics Assessment
Pith reviewed 2026-05-24 16:46 UTC · model grok-4.3
The pith
A graph linking similar local regions lets networks learn image composition for better aesthetics ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
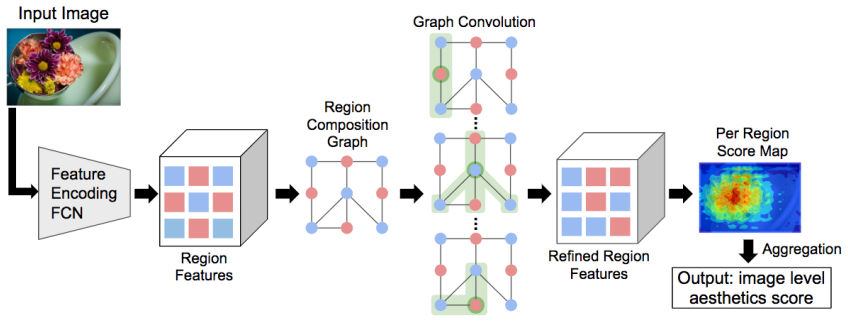
Image composition can be modeled as the mutual dependency among local regions; this dependency is captured by constructing a region composition graph whose nodes carry aesthetics-preserving features and whose edges are weighted by feature similarity, then applying graph convolution so that each node’s activation is determined by its highly correlated neighbors.
What carries the argument
The region composition graph, in which nodes represent densely partitioned local image regions and edges are weighted by similarity of their aesthetics-preserving features; graph convolution propagates information across correlated neighbors to encode composition.
If this is right
- The training procedure naturally discovers mutual dependencies among local regions without explicit composition labels.
- The method reaches state-of-the-art performance on established visual aesthetics assessment datasets.
- Composition information extracted via the graph improves accuracy compared with prior holistic mapping approaches.
- Dense partitioning into local regions supplies the basic elements whose relationships encode artistic harmony.
Where Pith is reading between the lines
- The same graph-construction pattern could be tested on other tasks that require modeling spatial or relational structure, such as layout-aware image retrieval.
- Performance may depend on the quality of the initial region features; swapping the feature extractor would be a direct test of how much the composition signal relies on pre-trained aesthetics cues.
- If the similarity-weighted edges truly capture harmony, the learned graph structure itself could be inspected to see which region pairs most influence high versus low ratings.
Load-bearing premise
That weighting edges by feature similarity and running graph convolution on the resulting graph will extract compositional harmony information that improves aesthetics prediction beyond what holistic image features already provide.
What would settle it
An ablation that removes the graph edges and convolution, processes each region independently, and shows no drop in accuracy on the same benchmark datasets would falsify the necessity of the mutual-dependency mechanism.
Figures



read the original abstract
Automatic image aesthetics assessment is important for a wide variety of applications such as on-line photo suggestion, photo album management and image retrieval. Previous methods have focused on mapping the holistic image content to a high or low aesthetics rating. However, the composition information of an image characterizes the harmony of its visual elements according to the principles of art, and provides richer information for learning aesthetics. In this work, we propose to model the image composition information as the mutual dependency of its local regions, and design a novel architecture to leverage such information to boost the performance of aesthetics assessment. To achieve this, we densely partition an image into local regions and compute aesthetics-preserving features over the regions to characterize the aesthetics properties of image content. With the feature representation of local regions, we build a region composition graph in which each node denotes one region and any two nodes are connected by an edge weighted by the similarity of the region features. We perform reasoning on this graph via graph convolution, in which the activation of each node is determined by its highly correlated neighbors. Our method naturally uncovers the mutual dependency of local regions in the network training procedure, and achieves the state-of-the-art performance on the benchmark visual aesthetics datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that image composition can be modeled as mutual dependency among densely partitioned local regions by extracting aesthetics-preserving features, building a region composition graph with edges weighted by feature similarity, and applying graph convolution to perform reasoning on the graph; this approach is said to uncover region dependencies during training and achieve state-of-the-art results on benchmark aesthetics datasets beyond holistic baselines.
Significance. If the claimed gains hold after controlling for local features alone, the work would be significant for introducing a graph-based mechanism to incorporate local region interactions into aesthetics assessment, providing a concrete architecture that moves beyond global image representations and potentially aligning better with artistic principles of composition.
major comments (2)
- [Abstract] Abstract: edges in the region composition graph are defined solely by similarity of region features, with no term for relative spatial position, adjacency, or layout. Because GCN message passing then aggregates content-similar regions irrespective of geometric arrangement, it is unclear whether the architecture models compositional harmony (arrangement) rather than non-spatial feature smoothing; this assumption is load-bearing for the central claim that the graph captures composition information beyond holistic baselines.
- [Abstract] Abstract: the claim that the method 'naturally uncovers the mutual dependency of local regions in the network training procedure' is not accompanied by an explicit mechanism or loss term that enforces spatial or compositional structure; without such a term the dependency may reduce to implicit feature correlation.
minor comments (1)
- [Abstract] The abstract does not specify the exact partitioning scheme, feature extractor backbone, or number of regions, making it difficult to reproduce the graph construction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. Below we address the major comments point by point, providing clarifications on the modeling choices and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: edges in the region composition graph are defined solely by similarity of region features, with no term for relative spatial position, adjacency, or layout. Because GCN message passing then aggregates content-similar regions irrespective of geometric arrangement, it is unclear whether the architecture models compositional harmony (arrangement) rather than non-spatial feature smoothing; this assumption is load-bearing for the central claim that the graph captures composition information beyond holistic baselines.
Authors: We acknowledge that edge weights are computed exclusively from feature similarity and do not incorporate explicit spatial coordinates, adjacency, or layout terms. The regions themselves are obtained by dense spatial partitioning of the input image, so their geometric arrangement is preserved in the node set; the GCN then learns which similarity-based connections are most predictive of aesthetic scores. This design choice follows from the premise that compositional harmony arises from mutual dependencies among content elements rather than from a separate spatial graph. Our experiments demonstrate consistent gains over holistic baselines that use the same region features without the graph, indicating that the learned dependencies contribute beyond simple feature smoothing. To make this distinction clearer we will revise the abstract and method section to explicitly state that spatial layout is encoded via the region extraction process while dependencies are discovered through similarity-weighted message passing. revision: partial
-
Referee: [Abstract] Abstract: the claim that the method 'naturally uncovers the mutual dependency of local regions in the network training procedure' is not accompanied by an explicit mechanism or loss term that enforces spatial or compositional structure; without such a term the dependency may reduce to implicit feature correlation.
Authors: The explicit mechanism is the region composition graph together with the graph convolution layers: each node’s updated representation is a learned aggregation of its similarity-weighted neighbors, and the entire pipeline is trained end-to-end to predict aesthetic scores. No auxiliary loss is required because the supervision signal on the final aesthetics prediction directly shapes which inter-region dependencies are useful. This is analogous to how attention mechanisms discover dependencies without an explicit structure loss. We will add a clarifying sentence in the abstract and a short paragraph in the method section that describes the end-to-end training objective as the sole driver for uncovering these dependencies. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper defines a region composition graph with nodes as local regions and edges weighted by cosine similarity of aesthetics-preserving features, then applies graph convolution for reasoning. This architectural choice is presented as an independent modeling decision to capture mutual dependencies, with no equations, fitted parameters, or self-citations shown that would make the claimed composition modeling or SOTA performance reduce to the inputs by construction. The performance gain is reported as an empirical result on external benchmarks rather than a tautological outcome. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
www.dpchallenge.com. 5
- [2]
- [3]
-
[4]
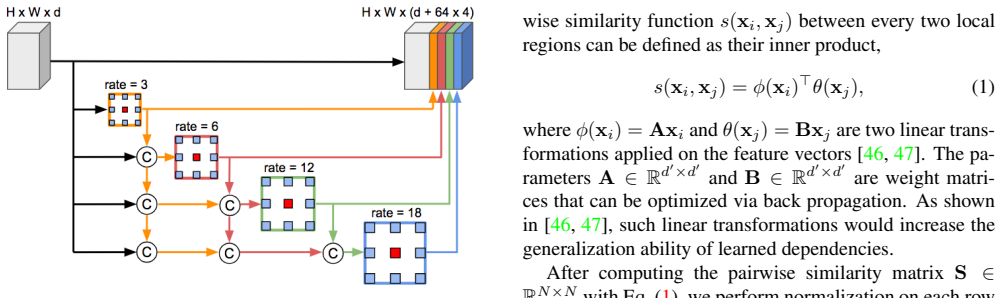
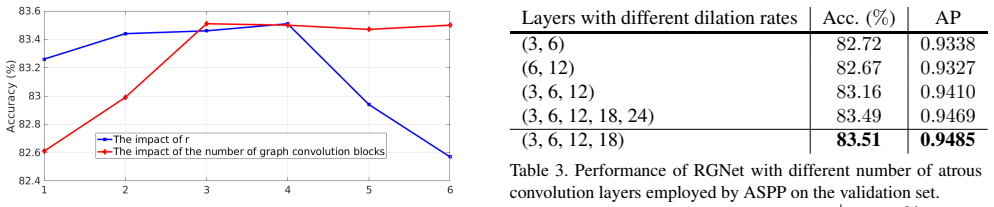
L. Chen, G. Papandreou, I. Kokkinos, K. Murphy and A. Yuille. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. TPAMI, 2018. 4, 6
work page 2018
-
[5]
L. Chen, G. Papandreou, I. Kokkinos, K. Murphy and A. Yuille. Semantic Image Segmentation with Deep Con- volutional Nets and Fully Connected CRFs. In ICLR, 2015. 3
work page 2015
- [6]
-
[7]
Y . Deng, D. Loy, and X. Tang. Image Aesthetic Assessment: An Experimental Survey.IEEE Signal Processing Magazine,
-
[8]
S. Dhar, V . Ordonez and T. Berg. High Level Describable Attributes for Predicting Aesthetics and Interestingness. In CVPR, 2011. 1
work page 2011
-
[9]
I. Goodfellow, J. Abadie, M. Mirza, B. Xu, D. Farley, S. Ozair, A. Courville and Y . Bengio. Generative Adversarial Nets. In NIPS, 2014. 8
work page 2014
- [10]
-
[11]
L. Hou, C. Yu and D. Samaras. Squared Earth Movers Dis- tance Loss for Training Deep Neural Networks on Ordered- Classes. In NIPS, 2017. 2
work page 2017
-
[12]
K. He, X. Zhang, S. Ren and J. Sun. Delving Deep into Rec- tifiers: Surpassing Human-Level Performance on Imagenet Classification. In ICCV, 2015. 5
work page 2015
-
[13]
K. He, X. Zhang, S. Ren and J. Sun. Deep Residual Learning for Image Recognition. In CVPR, 2016. 6
work page 2016
-
[14]
K. He, X. Zhang, S. Ren and J. Sun. Spatial Pyramid Pool- ing in Deep Convolutional Networks for Visual Recognition. TPAMI, 2015. 2, 8
work page 2015
-
[15]
S. Ioffe and C. Szegedy. Batch Normalization: Accelerat- ing Deep Network Training by Reducing Internal Covariate Shift. In ICML, 2015. 5
work page 2015
-
[16]
X. Jin, L. Wu, X. Li, S. Chen, S. Peng, J. Chi, S. Ge, C. Song and G. Zhao. Predicting Aesthetic Score Distri- bution through Cumulative Jensen-Shannon Divergence. In AAAI, 2018. 1
work page 2018
-
[17]
D. Kingma and J. Ba. Adam: A Method for Stochastic Opti- mization. In ICLR, 2015. 5
work page 2015
-
[18]
Y . Kao, R. He and K. Huang. Deep Aesthetic Quality As- sessment with Semantic Information. TIP, 2017. 7
work page 2017
-
[19]
P. Kr ¨ahenb¨uhl and V . Koltun. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In NIPS,
-
[20]
A. Krizhevsky, I. Sutskever and G. Hinton. ImageNet Classi- fication with Deep Convolutional Neural Networks. InNIPS,
-
[21]
S. Kong, X. Shen, Z. Lin, R. Mech and C. Fowlkes. Photo Aesthetics Ranking Network with Attributes and Content Adaptation. In ECCV, 2016. 1, 2, 5, 7, 8
work page 2016
-
[22]
X. Lu, Z. Lin, H. Jin, J. Yang and J. Wang. RAPID: Rating Pictorial Aesthetics using Deep Learning. In MM, 2014. 1, 2, 5, 7
work page 2014
-
[23]
X. Lu, Z. Lin, X. Shen, R. Mech and J. Wang. Deep Multi- Patch Aggregation Network for Image Style, Aesthetics, and Quality Estimation. In ICCV, 2015. 1, 2, 5, 7
work page 2015
-
[24]
A deep architecture for unified aesthetic prediction
N. Murray and A. Gordo. A Deep Architecture for Unified Aesthetic Prediction. arXiv:1708.04890, 2017. 1, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
L. Mai, H. Jin and F. Liu. Composition-preserving Deep Photo Aesthetics Assessment. In CVPR, 2016. 1, 2, 5, 7, 8
work page 2016
-
[26]
C. Ma, A. Kadav, I. Melvin, Z. Kira, G. AlRegib and H. Graf. Attend and Interact: Higher-Order Object Interactions for Video Understanding. In CVPR, 2018. 2
work page 2018
-
[27]
S. Ma, J. Liu and C. Chen. A-lamp: Adaptive Layout-aware Multi-Patch Deep Convolutional Neural Network for Photo Aesthetic Assessment. In CVPR, 2017. 2, 5, 7, 8
work page 2017
- [28]
-
[29]
L. Marchesotti, N. Murray, and F. Perronnin. Discovering Beautiful Attributes for Aesthetic Image Analysis. IJCV,
-
[30]
L. Marchesotti, F. Perronnin, D. Larlus and G. Csurka. As- sessing the Aesthetic Quality of Photographs using Generic Image Descriptors. In ICCV, 2011. 1
work page 2011
-
[31]
V . Ordonez, S. Dhar and T. Berg. High Level Describable Attributes for Predicting Aesthetics and Interestingness. In CVPR, 2011. 1
work page 2011
-
[32]
P. Pinheiro and R. Collobert. From Image-level to Pixel-level Labeling with Convolutional Networks. In CVPR, 2015. 5, 7
work page 2015
- [33]
-
[34]
G. Papandreou, I. Kokkinos and P. Savalle. Modeling Local and Global Deformations in Deep Learning: Epitomic Con- volution, Multiple Instance Learning, and Sliding Window Detection. In CVPR, 2015. 3
work page 2015
-
[35]
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg and L. Fei-Fei. ImageNet Large Scale Visual Recog- nition Challenge. IJCV, 2015. 5, 6
work page 2015
- [36]
-
[37]
F. Scarselli, M. Gori, A. Tsoi, M. Hagenbuchner and G. Monfardini. The Graph Neural Network Model. TNN,
-
[38]
A. Santoro, D. Raposo, D. Barrett, M. Malinowski, R. Pas- canu, P. Battaglia and T. Lillicrap. A Simple Neural Network Module for Relational Reasoning. In NIPS, 2017. 3
work page 2017
-
[39]
E. Shelhamer, J. Long and T. Darrell. Fully Convolutional Networks for Semantic Segmentation. TPAMI, 2016. 3
work page 2016
-
[40]
K. Schwarz, P. Wieschollek and H. Lensch. Will People Like Your Image? Learning the Aesthetic Space. In WACV, 2018. 2, 7
work page 2018
-
[41]
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. In ICLR,
-
[42]
X. Tang, W. Luo and X. Wang. Content-based Photo Quality Assessment. TMM, 2013. 1
work page 2013
-
[43]
H. Talebi and P. Milanfar. NIMA: Neural Image Assessment. TIP, 2018. 2, 7
work page 2018
- [44]
-
[45]
X. Wang and A. Gupta. Videos as Space-Time Region Graphs. In ECCV, 2018. 2, 3, 4
work page 2018
-
[46]
X. Wang, R. Girshick, A. Gupta and K. He. Non-local Neural Networks. In CVPR, 2018. 3, 4
work page 2018
-
[47]
Z. Wang, D. Liu, S. Chang, F. Dolcos, D. Beck and T. Huang. Image Aesthetics Assessment using Deep Chatterjee’s Ma- chine. In IJCNN, 2017. 7
work page 2017
-
[48]
W. Wang and J. Shen. Deep Cropping via Attention Box Prediction and Aesthetics Assessment. In ICCV, 2017. 1
work page 2017
-
[49]
W. Wang, J. Shen and H. Ling. A Deep Network Solution for Attention and Aesthetics Aware Photo Cropping.TPAMI,
-
[50]
M. Yang, K. Yu, C. Zhang, Z. Li and K. Yang. DenseASPP for Semantic Segmentation in Street Scenes. InCVPR, 2018. 4
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.