Y-Autoencoders: disentangling latent representations via sequential-encoding
Pith reviewed 2026-05-24 16:12 UTC · model grok-4.3
The pith
Y-Autoencoders split encoder output into implicit and explicit latent paths to achieve disentanglement without adversarial training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
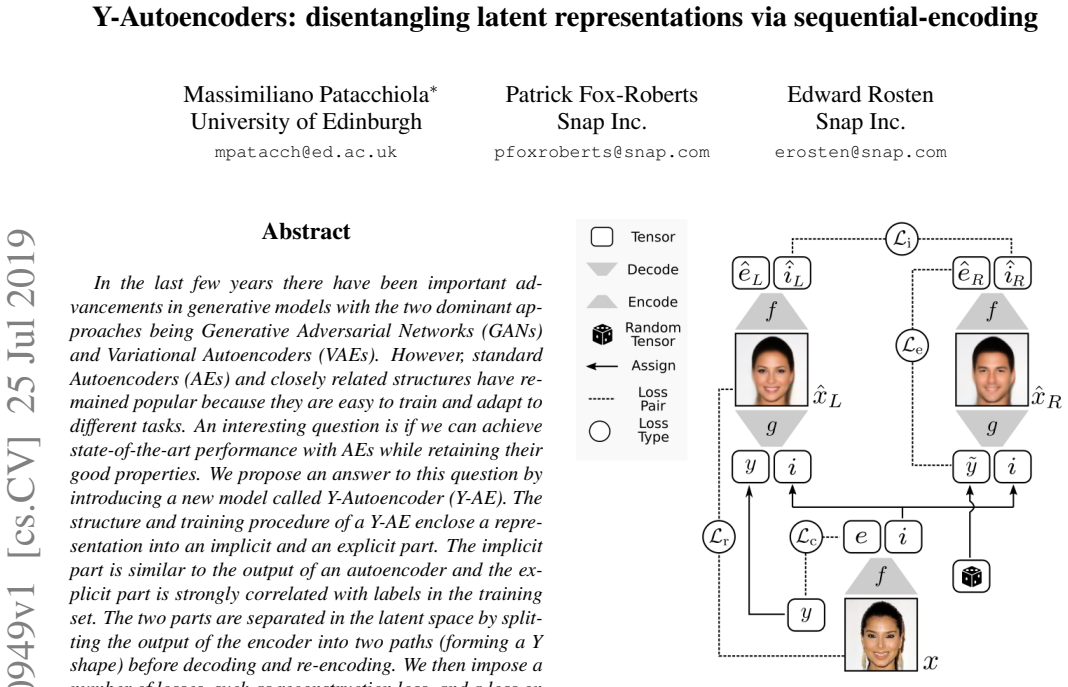
The structure and training procedure of a Y-AE enclose a representation into an implicit and an explicit part. The implicit part is similar to the output of an autoencoder and the explicit part is strongly correlated with labels in the training set. The two parts are separated in the latent space by splitting the output of the encoder into two paths before decoding and re-encoding. A number of losses are imposed, including reconstruction loss and a loss on dependence between the implicit and explicit parts. The projection in the explicit manifold is monitored by a predictor embedded in the encoder and trained end-to-end.
What carries the argument
The Y-shaped split of the encoder output into implicit and explicit paths, combined with a dependence loss between them and an embedded predictor trained jointly on the explicit path.
If this is right
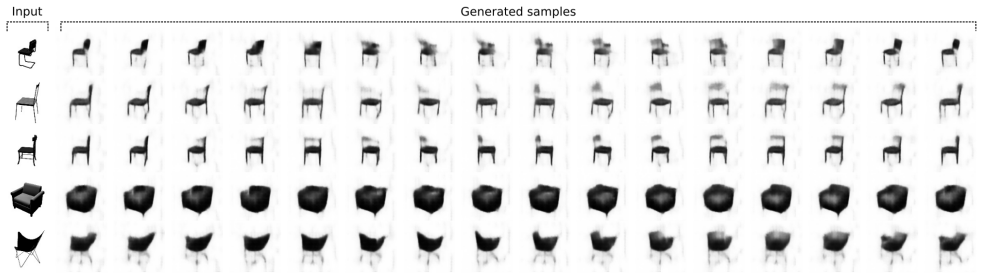
- Style and content factors can be separated in image datasets.
- Image-to-image translation tasks become feasible with the split structure.
- Inverse graphics problems can be addressed using the disentangled explicit and implicit codes.
- Standard autoencoder training properties are retained while adding the disentanglement capability.
Where Pith is reading between the lines
- The explicit path could support direct control over output attributes by changing the label inputs at inference time.
- The same split-and-predictor pattern might apply to autoencoders in non-image domains where some form of supervision is available.
- If dependence loss alone proves insufficient, adding a small amount of explicit decorrelation regularization could be tested as a direct extension.
Load-bearing premise
That the reconstruction loss, dependence loss, and embedded predictor together will force the two paths to capture genuinely separate factors rather than allowing label information to leak into the implicit path.
What would settle it
A classifier trained on the implicit latent codes alone achieving substantially above-chance accuracy on the original labels would indicate the separation did not occur.
Figures








read the original abstract
In the last few years there have been important advancements in generative models with the two dominant approaches being Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). However, standard Autoencoders (AEs) and closely related structures have remained popular because they are easy to train and adapt to different tasks. An interesting question is if we can achieve state-of-the-art performance with AEs while retaining their good properties. We propose an answer to this question by introducing a new model called Y-Autoencoder (Y-AE). The structure and training procedure of a Y-AE enclose a representation into an implicit and an explicit part. The implicit part is similar to the output of an autoencoder and the explicit part is strongly correlated with labels in the training set. The two parts are separated in the latent space by splitting the output of the encoder into two paths (forming a Y shape) before decoding and re-encoding. We then impose a number of losses, such as reconstruction loss, and a loss on dependence between the implicit and explicit parts. Additionally, the projection in the explicit manifold is monitored by a predictor, that is embedded in the encoder and trained end-to-end with no adversarial losses. We provide significant experimental results on various domains, such as separation of style and content, image-to-image translation, and inverse graphics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Y-Autoencoder (Y-AE), an autoencoder variant whose encoder output is split into two paths (implicit and explicit) forming a Y shape. The implicit path is trained to behave like a standard AE via reconstruction loss; the explicit path is driven to capture label information via an end-to-end embedded predictor; a dependence loss is imposed between the two paths. No adversarial training is used. Experiments are reported on style-content separation, image-to-image translation, and inverse graphics tasks.
Significance. If the claimed separation is reproducible, the method supplies a non-adversarial, end-to-end trainable route to factorized latent codes that retains the training stability of ordinary autoencoders. The absence of free adversarial losses and the use of a single embedded predictor constitute concrete engineering advantages over many contemporary disentanglement approaches.
major comments (2)
- [§3.2] §3.2: the dependence loss is stated to penalize mutual information or correlation between the implicit and explicit codes, yet the precise functional form (e.g., whether it is a kernel-based estimator, a simple covariance penalty, or an adversarial term) is not written out; without the equation it is impossible to verify that the loss cannot be satisfied by trivial constant solutions.
- [§4] §4, quantitative tables: label-prediction accuracy on the explicit codes is reported, but no corresponding metric (e.g., downstream reconstruction quality or mutual-information estimate) is given for the implicit codes to demonstrate that they remain uninformative about the labels; this measurement is load-bearing for the central disentanglement claim.
minor comments (2)
- [§3] Notation for the split latent dimensions (implicit vs. explicit) is introduced inconsistently across figures and equations; a single consistent symbol pair would improve readability.
- [Abstract, §4] The abstract claims “state-of-the-art performance with AEs”; the experimental section should include direct numerical comparison against at least one contemporary non-adversarial baseline (e.g., β-VAE or InfoGAN) on the same datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to incorporate the suggested clarifications and additional metrics.
read point-by-point responses
-
Referee: [§3.2] §3.2: the dependence loss is stated to penalize mutual information or correlation between the implicit and explicit codes, yet the precise functional form (e.g., whether it is a kernel-based estimator, a simple covariance penalty, or an adversarial term) is not written out; without the equation it is impossible to verify that the loss cannot be satisfied by trivial constant solutions.
Authors: We agree that the exact equation for the dependence loss was not provided. In the revised manuscript we will insert the precise mathematical definition (a covariance penalty between the implicit and explicit vectors) into §3.2 and will add a short argument showing that the combination of this term with the reconstruction and predictor losses precludes trivial constant solutions. revision: yes
-
Referee: [§4] §4, quantitative tables: label-prediction accuracy on the explicit codes is reported, but no corresponding metric (e.g., downstream reconstruction quality or mutual-information estimate) is given for the implicit codes to demonstrate that they remain uninformative about the labels; this measurement is load-bearing for the central disentanglement claim.
Authors: We acknowledge the need for direct evidence on the implicit branch. In the revised §4 we will add label-prediction accuracy (expected near chance) and a reconstruction-quality metric computed from the implicit codes alone, thereby confirming that label information is not retained in the implicit path. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper defines the Y-AE by explicit architectural choices (encoder split into Y-shaped implicit/explicit paths) and loss terms (reconstruction, dependence between paths, embedded end-to-end predictor) in sections 3.2-3.3. The central claim that this produces an implicit AE-like representation and an explicit label-correlated part follows directly from those design decisions rather than reducing to any fitted parameter on target data or to a self-citation chain. Experiments in section 4 supply independent empirical checks via visualizations and label-prediction metrics; no load-bearing equation equates a derived quantity to its own input by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- loss weighting coefficients
- latent dimension split ratio
axioms (2)
- domain assumption A predictor embedded in the encoder can reliably monitor and enforce correlation of the explicit branch with training labels.
- domain assumption The dependence loss between implicit and explicit branches is sufficient to prevent information leakage.
invented entities (2)
-
Y-shaped latent split
no independent evidence
-
embedded predictor inside encoder
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
P. Baldi and K. Hornik. Neural networks and principal com- ponent analysis: Learning from examples without local min- ima. Neural networks, 2(1):53–58, 1989. 1
work page 1989
-
[3]
D. H. Ballard. Modular learning in neural networks. In AAAI, pages 279–284, 1987. 1
work page 1987
-
[4]
J. Bromley, I. Guyon, Y . LeCun, E. S¨ackinger, and R. Shah. Signature verification using a” siamese” time delay neural network. In Advances in neural information processing sys- tems, pages 737–744, 1994. 3
work page 1994
-
[5]
X. Chen, Y . Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in neural information processing systems , pages 2172–2180, 2016. 2
work page 2016
-
[6]
Y . Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multi- domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 8789–8797, 2018. 2
work page 2018
-
[7]
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 7
work page 2016
-
[8]
B. Dai, S. Fidler, R. Urtasun, and D. Lin. Towards diverse and natural image descriptions via a conditional gan. In Pro- ceedings of the IEEE International Conference on Computer Vision, pages 2970–2979, 2017. 2
work page 2017
-
[9]
X. Glorot and Y . Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intel- ligence and statistics, pages 249–256, 2010. 4
work page 2010
-
[10]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Gen- erative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. 1, 2
work page 2014
-
[11]
A. Harsh Jha, S. Anand, M. Singh, and V . Veeravasarapu. Disentangling factors of variation with cycle-consistent vari- ational auto-encoders. In Proceedings of the European Con- ference on Computer Vision (ECCV), pages 805–820, 2018. 2
work page 2018
-
[12]
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Repre- sentations, volume 3, 2017. 2, 5, 6
work page 2017
-
[13]
Q. Hu, A. Szab ´o, T. Portenier, P. Favaro, and M. Zwicker. Disentangling factors of variation by mixing them. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3399–3407, 2018. 2
work page 2018
-
[14]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 4
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. 1, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. Tenenbaum. Deep convolutional inverse graphics network. In Advances in neural information processing systems, pages 2539–2547,
-
[17]
C. Lassner, G. Pons-Moll, and P. V . Gehler. A generative model of people in clothing. In Proceedings of the IEEE International Conference on Computer Vision , pages 853– 862, 2017. 2
work page 2017
- [18]
- [19]
-
[20]
Z. Liu, P. Luo, X. Wang, and X. Tang. Deep learning face attributes in the wild. In Proceedings of International Con- ference on Computer Vision (ICCV), December 2015. 7
work page 2015
-
[21]
A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow, and B. Frey. Adversarial autoencoders. arXiv preprint arXiv:1511.05644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero. Conditional generative adversar- ial nets. arXiv preprint arXiv:1411.1784, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [23]
-
[24]
Z. Shu, M. Sahasrabudhe, R. Alp Guler, D. Samaras, N. Para- gios, and I. Kokkinos. Deforming autoencoders: Unsuper- vised disentangling of shape and appearance. InProceedings of the European Conference on Computer Vision (ECCV) , pages 650–665, 2018. 2
work page 2018
-
[25]
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, et al. Image quality assessment: from error visibility to struc- tural similarity. IEEE transactions on image processing , 13(4):600–612, 2004. 5
work page 2004
-
[26]
X. Yan, J. Yang, K. Sohn, and H. Lee. Attribute2image: Con- ditional image generation from visual attributes. InEuropean Conference on Computer Vision , pages 776–791. Springer,
-
[27]
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image- to-image translation using cycle-consistent adversarial net- works. arXiv preprint, 2017. 2 Appendices A. Network architectures Figure 1: Neural network structure used in the MNIST and SVHN experiments. Notice that to avoid clutter just some of the feature maps have been reported. The notatio...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.