Product Image Recognition with Guidance Learning and Noisy Supervision
Pith reviewed 2026-05-24 16:06 UTC · model grok-4.3
The pith
Guidance learning improves CNNs on noisy web product images by combining teacher soft labels with given noisy labels plus a small clean set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
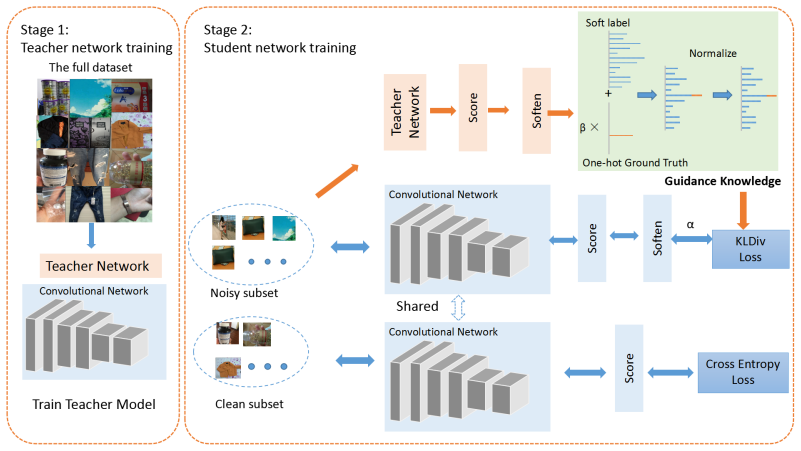
The paper claims that a student network trained with guidance knowledge—the combination of each example's given noisy label and the softened label produced by a teacher network pretrained on the full noisy dataset—together with a small clean set, achieves superior recognition accuracy on product images compared with state-of-the-art noisy-supervision techniques.
What carries the argument
Guidance learning, the two-stage teacher-student procedure that supplies combined noisy-plus-soft labels to the student network.
If this is right
- The method handles real-world challenges such as background clutter and category diversity in consumer photos.
- Large noisy web datasets become usable when paired with only a modest clean set.
- Performance gains appear across product, food, and clothing recognition tasks.
- The approach is simple enough to apply directly to existing CNN training pipelines.
Where Pith is reading between the lines
- The same teacher-student label combination could be tested on other web-collected image tasks such as general object or scene recognition.
- Replacing the single teacher pass with an iterative update of soft labels might yield further gains.
- The soft labels appear to encode useful visual patterns that hard noisy labels miss, suggesting the technique could complement other semi-supervised methods.
Load-bearing premise
The teacher network trained on the full noisy dataset produces soft labels accurate enough that combining them with the given noisy labels improves the student beyond what the clean set or standard noisy-label methods alone can achieve.
What would settle it
Training the student network on the same data splits but without the teacher's soft labels and finding that test accuracy on Product-90 or Clothing1M does not drop below the levels reported for guidance learning.
Figures





read the original abstract
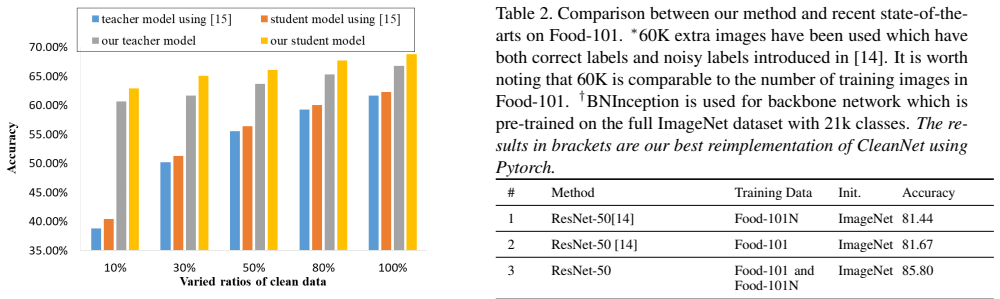
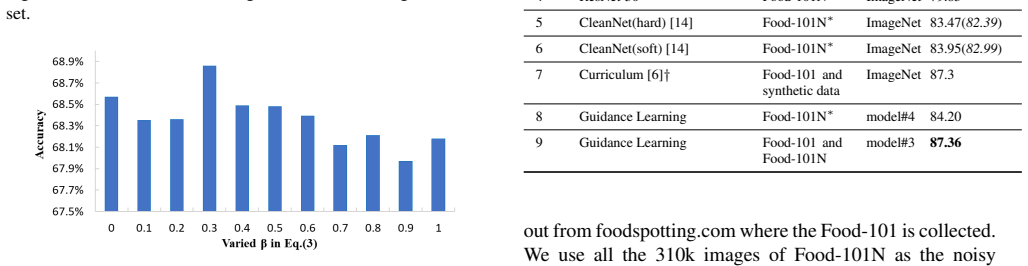
This paper considers recognizing products from daily photos, which is an important problem in real-world applications but also challenging due to background clutters, category diversities, noisy labels, etc. We address this problem by two contributions. First, we introduce a novel large-scale product image dataset, termed as Product-90. Instead of collecting product images by labor-and time-intensive image capturing, we take advantage of the web and download images from the reviews of several e-commerce websites where the images are casually captured by consumers. Labels are assigned automatically by the categories of e-commerce websites. Totally the Product-90 consists of more than 140K images with 90 categories. Due to the fact that consumers may upload unrelated images, it is inevitable that our Product-90 introduces noisy labels. As the second contribution, we develop a simple yet efficient \textit{guidance learning} (GL) method for training convolutional neural networks (CNNs) with noisy supervision. The GL method first trains an initial teacher network with the full noisy dataset, and then trains a target/student network with both large-scale noisy set and small manually-verified clean set in a multi-task manner. Specifically, in the stage of student network training, the large-scale noisy data is supervised by its guidance knowledge which is the combination of its given noisy label and the soften label from the teacher network. We conduct extensive experiments on our Products-90 and public datasets, namely Food101, Food-101N, and Clothing1M. Our guidance learning method achieves performance superior to state-of-the-art methods on these datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Product-90 dataset (>140K images, 90 categories) collected from e-commerce review photos with automatically assigned but noisy labels. It proposes a guidance learning (GL) procedure: train a teacher CNN on the full noisy set, then train a student CNN in multi-task fashion on the noisy set (supervised by a combination of the original noisy label and the teacher's softened prediction) plus a small manually verified clean set. Experiments on Product-90 plus Food-101, Food-101N and Clothing1M are said to show GL outperforming prior state-of-the-art noisy-label methods.
Significance. If the reported gains are robust, the Product-90 dataset supplies a realistic large-scale benchmark for noisy consumer-product imagery, and the GL procedure offers a lightweight way to exploit abundant noisy web data together with limited clean supervision. Both contributions would be of practical value for e-commerce vision tasks.
major comments (2)
- [Abstract] Abstract: the central empirical claim (superior performance on four datasets) is asserted without any numerical results, error bars, ablation tables, or description of how the small clean set was chosen or sized; this directly prevents verification of the claim from the given text.
- [Guidance Learning] Guidance learning description: the method rests on the assumption that soft labels produced by a teacher trained on the identical noisy data meaningfully augment the original noisy labels beyond what the clean set alone or standard noisy-label techniques achieve; no ablation that removes the soft-label term or compares against clean-set-only training is described, leaving the weakest assumption untested.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the two major points below and indicate the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (superior performance on four datasets) is asserted without any numerical results, error bars, ablation tables, or description of how the small clean set was chosen or sized; this directly prevents verification of the claim from the given text.
Authors: We agree that the abstract would be strengthened by the inclusion of key quantitative results and a brief description of the clean-set size and selection. In the revised version we will add specific accuracy figures (with standard deviations where available) for Product-90 and the three public datasets, together with the size of the manually verified clean subset used during student training. revision: yes
-
Referee: [Guidance Learning] Guidance learning description: the method rests on the assumption that soft labels produced by a teacher trained on the identical noisy data meaningfully augment the original noisy labels beyond what the clean set alone or standard noisy-label techniques achieve; no ablation that removes the soft-label term or compares against clean-set-only training is described, leaving the weakest assumption untested.
Authors: The referee is correct that the current manuscript does not contain an explicit ablation that isolates the soft-label guidance term from clean-set-only training. While the reported comparisons against prior noisy-label methods already demonstrate gains, we acknowledge that a direct ablation removing the teacher soft-label component would more rigorously test the added value of the guidance signal. We will therefore add these ablation experiments to the revised manuscript. revision: yes
Circularity Check
Empirical training procedure with no circular derivation
full rationale
The paper presents an empirical method: train a teacher CNN on the full noisy Product-90 (and similar) dataset, then train a student in multi-task fashion using a combination of the original noisy label and the teacher's softened prediction. No equations, uniqueness theorems, or derivations are claimed; performance is evaluated via standard experiments on Product-90, Food-101, Food-101N, and Clothing1M. The central claim (superiority to SOTA) is a reported experimental outcome rather than a result forced by definition, fitted parameters renamed as predictions, or a self-citation chain. The method is self-contained against external benchmarks and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L. Bossard, M. Guillaumin, and L. Van Gool. Food-101– mining discriminative components with random forests. In ECCV, pages 446–461. Springer, 2014
work page 2014
-
[2]
C. E. Brodley and M. A. Friedl. Identifying mislabeled train- ing data. Journal of artificial intelligence research, 11:131– 167, 1999
work page 1999
-
[3]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009. 8
work page 2009
-
[4]
B. Fr ´enay and M. Verleysen. Classification in the presence of label noise: a survey. IEEE transactions on neural networks and learning systems, 25(5):845–869, 2014
work page 2014
-
[5]
M. George and C. Floerkemeier. Recognizing products: A per-exemplar multi-label image classification approach. In ECCV, pages 440–455. Springer, 2014
work page 2014
-
[6]
S. Guo, W. Huang, H. Zhang, C. Zhuang, D. Dong, M. R. Scott, and D. Huang. Curriculumnet: Weakly supervised learning from large-scale web images. arXiv preprint arXiv:1808.01097, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016
work page 2016
-
[8]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
L. Jiang, Z. Zhou, T. Leung, L.-J. Li, and L. Fei-Fei. Men- tornet: Regularizing very deep neural networks on corrupted labels. arXiv preprint arXiv:1712.05055, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [11]
-
[12]
P. Jund, N. Abdo, A. Eitel, and W. Burgard. The freiburg groceries dataset. arXiv preprint arXiv:1611.05799, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [13]
-
[14]
K.-H. Lee, X. He, L. Zhang, and L. Yang. Cleannet: Trans- fer learning for scalable image classifier training with label noise. arXiv preprint arXiv:1711.07131, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
W. Li, L. Wang, W. Li, E. Agustsson, and L. Van Gool. We- bvision database: Visual learning and understanding from web data. arXiv preprint arXiv:1708.02862, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Y . Li, J. Yang, Y . Song, L. Cao, J. Luo, and L.-J. Li. Learning from noisy labels with distillation. In ICCV, pages 1928– 1936, 2017
work page 1928
-
[17]
S. Liu, Z. Song, G. Liu, C. Xu, H. Lu, and S. Yan. Street-to- shop: Cross-scenario clothing retrieval via parts alignment and auxiliary set. In CVPR, pages 3330–3337. IEEE, 2012
work page 2012
-
[18]
Y . Lu, C. Yuan, Z. Lai, X. Li, W. K. Wong, and D. Zhang. Nuclear norm-based 2dlpp for image classification. IEEE Transactions on Multimedia, 19(11):2391–2403, 2017
work page 2017
-
[19]
N. Manwani and P. Sastry. Noise tolerance under risk min- imization. IEEE transactions on cybernetics , 43(3):1146– 1151, 2013
work page 2013
- [20]
-
[21]
A. L. Miranda, L. P. F. Garcia, A. C. Carvalho, and A. C. Lorena. Use of classification algorithms in noise detection and elimination. In International Conference on Hybrid Ar- tificial Intelligence Systems, pages 417–424. Springer, 2009
work page 2009
- [22]
-
[23]
V . Mnih and G. E. Hinton. Learning to label aerial images from noisy data. In ICML, pages 567–574, 2012
work page 2012
-
[24]
D. F. Nettleton, A. Orriols-Puig, and A. Fornells. A study of the effect of different types of noise on the precision of su- pervised learning techniques. Artificial intelligence review, 33(4):275–306, 2010
work page 2010
-
[25]
G. Patrini, A. Rozza, A. K. Menon, R. Nock, and L. Qu. Making deep neural networks robust to label noise: A loss correction approach. In CVPR, pages 2233–2241, 2017
work page 2017
-
[26]
S. Reed, H. Lee, D. Anguelov, C. Szegedy, D. Erhan, and A. Rabinovich. Training deep neural networks on noisy la- bels with bootstrapping. arXiv preprint arXiv:1412.6596 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [27]
-
[28]
Deep Learning is Robust to Massive Label Noise
D. Rolnick, A. Veit, S. Belongie, and N. Shavit. Deep learning is robust to massive label noise. arXiv preprint arXiv:1705.10694, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Training Convolutional Networks with Noisy Labels
S. Sukhbaatar, J. Bruna, M. Paluri, L. Bourdev, and R. Fer- gus. Training convolutional networks with noisy labels. arXiv preprint arXiv:1406.2080, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2080
-
[30]
Joint Optimization Framework for Learning with Noisy Labels
D. Tanaka, D. Ikami, T. Yamasaki, and K. Aizawa. Joint optimization framework for learning with noisy labels.arXiv preprint arXiv:1803.11364, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
A. Veit, N. Alldrin, G. Chechik, I. Krasin, A. Gupta, and S. J. Belongie. Learning from noisy large-scale datasets with minimal supervision. In CVPR, pages 6575–6583, 2017
work page 2017
-
[32]
X.-S. Wei, Q. Cui, L. Yang, P. Wang, and L. Liu. Rpc: A large-scale retail product checkout dataset. arXiv preprint arXiv:1901.07249, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[33]
T. Xiao, T. Xia, Y . Yang, C. Huang, and X. Wang. Learning from massive noisy labeled data for image classification. In CVPR, pages 2691–2699, 2015. 9
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.