Vendor-Conditioned Contrastive Learning for Predicting Organizational Cyber Threat Targets
Pith reviewed 2026-05-24 14:07 UTC · model grok-4.3
The pith
TRACE uses vendor-conditioned contrastive learning on CySecBERT to classify organizational targets of exploits at 97 percent macro F1 under temporal shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TRACE is a vendor-conditioned contrastive learning framework built on CySecBERT that jointly optimizes organizational target classification and vendor-coherent representations, reaching 97.00 percent macro F1 on a 129126-sample multi-source dataset when evaluated under temporal distribution shift and outperforming seventeen benchmark methods.
What carries the argument
Vendor-conditioned contrastive learning that enforces coherence between exploit vendors and organizational targets while performing classification.
If this is right
- Large multi-source corpora spanning three decades enable better handling of temporal shifts than small single-source datasets used in prior work.
- Joint optimization of target classification and vendor coherence improves robustness compared with standard supervised training.
- The 97 percent macro F1 under temporal out-of-distribution evaluation exceeds results from classical ML, GloVe or FastText embeddings, and pretrained transformers.
- The approach scales to 352866 raw posts reduced to 129126 labeled samples across seven categories.
Where Pith is reading between the lines
- Conditioning on vendor identity could be tested as an auxiliary signal in other security tasks such as malware family attribution.
- Periodic retraining on newer forum data would be required to maintain performance as exploit-sharing patterns evolve.
- If the seven organizational categories prove stable across future data releases, the same contrastive objective could support semi-supervised expansion of the label set.
Load-bearing premise
The multi-source dataset assembled from nine exploit databases and forums over three decades yields unbiased, correctly labeled samples that support generalization under temporal shift without leakage or category definition issues.
What would settle it
Retraining and testing on a fresh set of exploits posted after the training cutoff, or auditing a random sample of the 129126 labels for overlaps between the seven organizational categories, would show whether the 97 percent F1 holds.
Figures




read the original abstract
Cyberattacks cause billions of dollars in damage annually, with malicious hackers often sharing exploit code and techniques on underground forums. Identifying which organizations are targeted by these exploits is critical for proactive Cyber Threat Intelligence (CTI). To address that gap, we propose Temporal Representation and Classification of Exploits (TRACE), a vendor-conditioned contrastive learning framework built on CySecBERT that jointly optimizes organizational target classification and vendor-coherent representations while evaluating robustness under temporal distribution shift. Unlike prior work limited to small, single-source datasets, we leverage a large-scale, multi-source corpus spanning 9 exploit databases and hacker forums, comprising 352,866 posts collected over three decades, yielding a 129,126-sample dataset across seven organizational categories. In the temporal out-of-distribution evaluation, TRACE achieves macro F1=97.00\%, substantially outperforming 17 benchmark classical ML methods, deep learning with GloVe/FastText embeddings, and pretrained transformer models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a vendor-conditioned contrastive learning framework built on CySecBERT, for predicting which organizations are targeted by exploits discussed in underground forums and databases. It constructs a 129,126-sample dataset spanning seven organizational categories from 352,866 posts across nine sources over three decades, and reports that TRACE achieves 97.00% macro F1 in a temporal out-of-distribution evaluation, substantially outperforming 17 classical ML, embedding-based, and pretrained transformer baselines.
Significance. If the temporal OOD performance holds after proper verification of splits and labeling, the work would be significant for cyber threat intelligence by scaling to a large multi-source corpus and introducing a contrastive approach that enforces vendor coherence. The scale of the dataset and the explicit temporal robustness evaluation would provide a useful benchmark for the field.
major comments (3)
- [Abstract] Abstract: the temporal out-of-distribution claim (macro F1=97.00%) cannot be assessed without the exact date-based partitioning rule, post-date cutoff, and confirmation that no future information is available at training time; this detail is load-bearing for the central generalization result.
- [Abstract] Abstract / data construction: the procedure for assigning the seven organizational category labels across the nine exploit databases and forums is not described (heuristic, manual, or automated), leaving open the possibility of source-specific bias or inconsistent definitions that would undermine the reported performance under temporal shift.
- [Abstract] Abstract: the model architecture, contrastive loss formulation, and how vendor conditioning is implemented on CySecBERT are omitted, so it is impossible to determine whether the performance gain is attributable to the proposed method rather than data artifacts.
minor comments (1)
- [Abstract] The abstract states 352,866 posts but a 129,126-sample dataset; clarify the filtering steps that produce the final labeled set.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying areas where the abstract lacks sufficient detail to fully support the central claims. We will revise the abstract to incorporate the requested information on temporal partitioning, labeling, and model specifics while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the temporal out-of-distribution claim (macro F1=97.00%) cannot be assessed without the exact date-based partitioning rule, post-date cutoff, and confirmation that no future information is available at training time; this detail is load-bearing for the central generalization result.
Authors: We agree these details are essential. The manuscript uses a strict temporal split with all training data from posts dated before January 1, 2019 and evaluation on posts from 2019 onward; no post-cutoff information is available during training or hyperparameter selection. We will add a concise statement of this rule and cutoff to the abstract. revision: yes
-
Referee: [Abstract] Abstract / data construction: the procedure for assigning the seven organizational category labels across the nine exploit databases and forums is not described (heuristic, manual, or automated), leaving open the possibility of source-specific bias or inconsistent definitions that would undermine the reported performance under temporal shift.
Authors: We acknowledge the labeling procedure is not summarized in the abstract. It combines automated keyword and entity matching against a fixed ontology of organizational targets drawn from the nine sources, followed by cross-source consistency checks and limited manual adjudication for ambiguous cases. We will include a brief description of this process in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the model architecture, contrastive loss formulation, and how vendor conditioning is implemented on CySecBERT are omitted, so it is impossible to determine whether the performance gain is attributable to the proposed method rather than data artifacts.
Authors: The architecture, contrastive objective, and vendor-conditioning mechanism (via an auxiliary embedding that is concatenated to the CySecBERT [CLS] representation before the projection head) are detailed in Section 3. We will add a one-sentence summary of the vendor-conditioned contrastive loss to the abstract so readers can immediately distinguish the method from the data. revision: yes
Circularity Check
No significant circularity; empirical temporal OOD evaluation is independent of inputs
full rationale
The paper describes an empirical ML framework (TRACE) trained on a multi-source dataset and evaluated via temporal out-of-distribution split, reporting macro F1 on held-out future data. No equations, derivations, or self-referential definitions appear in the provided text that would reduce the reported performance metric to a fitted quantity or input by construction. No self-citation load-bearing steps, ansatz smuggling, or uniqueness theorems are invoked. The central claim rests on standard contrastive learning optimization and benchmark comparisons, which remain falsifiable against external data partitions and do not collapse to the training inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive learning hyperparameters
axioms (1)
- domain assumption Temporal data split induces meaningful distribution shift without leakage
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
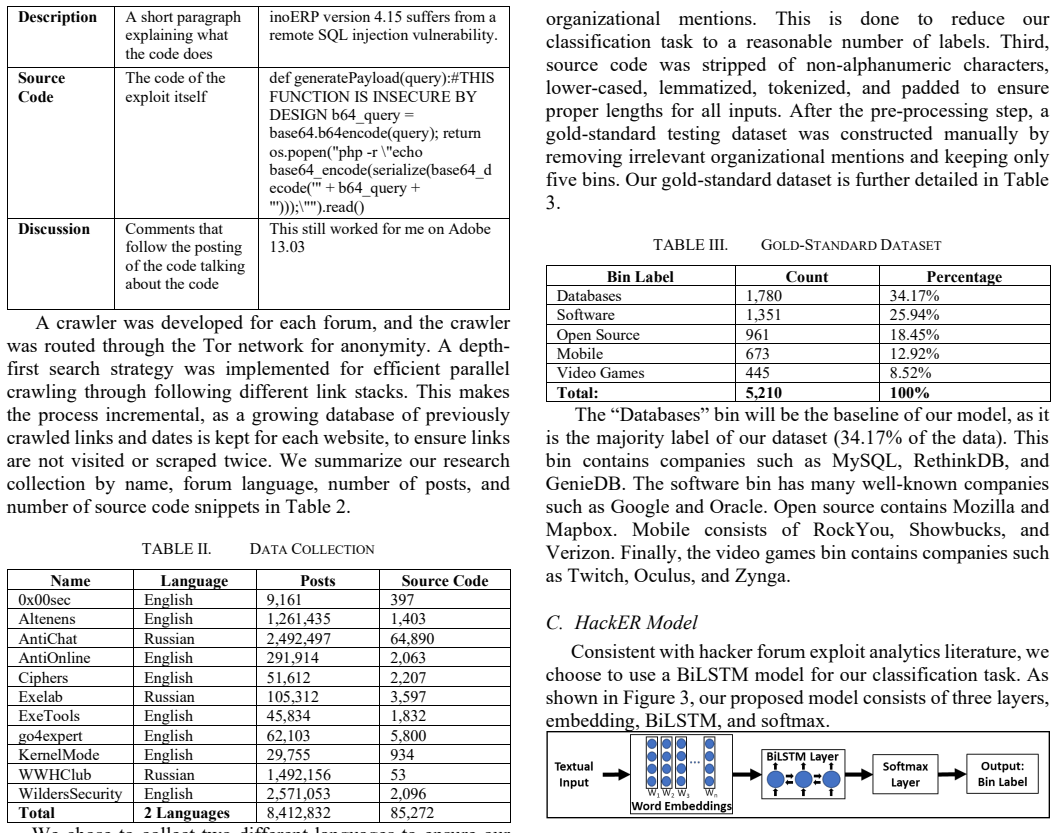
HackER BiLSTM model ... F1-score (79.71%) ... five bins (Databases, Software, Open Source, Mobile, Video Games)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proactively Identifying Emerging Hacker Threats from the Dark Web,
S. Samtani, H. Zhu, and H. Chen, “Proactively Identifying Emerging Hacker Threats from the Dark Web,” ACM Transactions on Privacy and Security , vol. 23, no. 4, pp. 1 –33, Aug. 2020, doi: 10.1145/3409289
-
[2]
DICE-E: A Framework for Conducting Darknet Identification, Collection, Evaluation with Ethics,
V. Benjamin, J. S. Valacich, and H. Chen, “DICE-E: A Framework for Conducting Darknet Identification, Collection, Evaluation with Ethics,” MIS Quarterly , vol. 43, no. 1, pp. 1 –22, Jan. 2019, doi: 10.25300/MISQ/2019/13808
-
[3]
Simulation Modeling Cyber Threats, Risks, and Prevention Costs,
J. E. Lerums, L. D. Poe, and J. E. Dietz, “Simulation Modeling Cyber Threats, Risks, and Prevention Costs,” in 2018 IEEE International Conference on Electro/Information Technology (EIT), May 2018, pp. 0096–0101, doi: 10.1109/EIT.2018.8500240
-
[4]
Cyber threat intelligence sharing: Survey and research directions,
T. D. Wagner, K. Mahbub, E. Palomar, and A. E. Abdallah, “Cyber threat intelligence sharing: Survey and research directions,” Computers & Security, vol. 87, Nov. 2019, doi: 10.1016/j.cose.2019.101589
-
[5]
Exploring Emerging Hacker Assets and Key Hackers for Proactive Cyber Threat Intelligence,
S. Samtani, R. Chinn, H. Chen, and J. F. Nunamaker, “Exploring Emerging Hacker Assets and Key Hackers for Proactive Cyber Threat Intelligence,” Journal of Management Information Sys tems, vol. 34, no. 4, pp. 1023– 1053, Oct. 2017, doi: 10.1080/07421222.2017.1394049
-
[6]
Exploring threats and vulnerabilities in hacker web: Forums, IRC and carding shops,
V. Benjamin, W. Li, T. Holt, and H. Chen, “Exploring threats and vulnerabilities in hacker web: Forums, IRC and carding shops,” in 2015 IEEE International Conference on Intelligence and Security Informatics (ISI), May 2015, pp. 85– 90, doi: 10.1109/ISI.2015.7165944
-
[7]
Labeling Hacker Exploits for Proactive Cyber Threat Intelligence: A Deep Transfer Learning Approach,
B. M. Ampel, S. Samtani, H. Zhu, S. Ullman, and H. Chen, “Labeling Hacker Exploits for Proactive Cyber Threat Intelligence: A Deep Transfer Learning Approach,” 2020 IEEE Conference on Intelligence and Security Informatics (ISI), no. November, 2020
work page 2020
-
[8]
See No Evil, Hear No Evil? Dissecting the Impact of Online Hacker Forums,
W. T. Yue, Q.-H. Wang, and K.-L. Hui, “See No Evil, Hear No Evil? Dissecting the Impact of Online Hacker Forums,” MIS Quarterly , vol. 43, no. 1, pp. 73 –95, Jan. 2019, doi: 10.25300/MISQ/2019/13042
-
[9]
BlackWidow: Monitoring the Dark Web for Cyber Security Information,
M. Schafer, M. Fuchs, M. Strohmeier, M. Engel, M. Liechti, and V. Lenders, “BlackWidow: Monitoring the Dark Web for Cyber Security Information,” in 2019 11th International Conference on Cyber Conflict (CyCon) , May 2019, pp. 1– 21, doi: 10.23919/CYCON.2019.8756845
-
[10]
J. Grisham, S. Samtani, M. Patton, and H. Chen, “Identifying Mobile Malware and Key Threat Actors in Online Hacker Forums for Proactive Cyber Threat Intelligence,” in 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Jul. 2017, pp. 13–18, doi: 10.1109/ISI.2017.8004867
-
[11]
I. Deliu, C. Leichter, and K. Franke, “Collecting Cyber Threat Intelligence from Hacker Forums via a Two -Stage, Hybrid Process using Support Vector Machines and Latent Dirichlet Allocation,” in 2018 IEEE International Conference on Big Data (Big Data) , Dec. 2018, pp. 5008–5013, doi: 10.1109/BigData.2018.8622469
-
[12]
R. Williams, S. Samtani, M. Patton, and H. Chen, “Incremental Hacker Forum Exploit Collection and Classification for Proa ctive Cyber Threat Intelligence: An Exploratory Study,” in 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), Nov. 2018, pp. 94–99, doi: 10.1109/ISI.2018.8587336
-
[13]
Reinforcement -Learning-Guided Sou rce Code Summarization via Hierarchical Attention,
W. Wang et al. , “Reinforcement -Learning-Guided Sou rce Code Summarization via Hierarchical Attention,” IEEE Transactions on Software Engineering , pp. 1 –1, 2020, doi: 10.1109/TSE.2020.2979701
-
[14]
I. Deliu, C. Leichter, and K. Franke, “Extracting cyber threat intelligence from hacker forums: Support vector machines versus convolutional neural networks,” in 2017 IEEE International Conference on Big Data (Big Data), Dec. 2017, pp. 3648–3656, doi: 10.1109/BigData.2017.8258359
-
[15]
Detecting Cyber Threats in Non-English Dark Net Markets: A Cross-Lingual Transfer Learning Approach,
M. Ebrahimi, M. Surdeanu, S. Samtani, and H. Chen, “Detecting Cyber Threats in Non-English Dark Net Markets: A Cross-Lingual Transfer Learning Approach,” in 2018 IEEE International Conference on Intelligence and Security Informatics (ISI) , Nov. 2018, pp. 85 –90, doi: 10.1109/ISI.2018.8587404
-
[16]
Text Classification Techniques: A Literature Review,
M. Thangaraj and M. Sivakami, “Text Classification Techniques: A Literature Review,” Interdisciplinary Journal of Information, Knowledge, and Management , vol. 13, pp. 117 –135, 2018, doi: 10.28945/4066
-
[17]
Bidirectional LSTM with Attention Mechanism and Convolutional Layer for Text Classification,
G. Liu and J. Guo, “Bidirectional LSTM with Attention Mechanism and Convolutional Layer for Text Classification,” Neurocomputing, vol. 337, pp. 325 –338, Apr. 2019, doi: 10.1016/j.neucom.2019.01.078
-
[18]
J. Pennington, R. Socher, and C. Manning, “Glove: Global Vectors for Word Representation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2014, pp. 1532–1543, doi: 10.3115/v1/D14-1162
-
[19]
Systems Development in In formation Systems Research,
J. F. Nunamaker, M. Chen, and T. D. M. Purdin, “Systems Development in In formation Systems Research,” Journal of Management Information Systems , vol. 7, no. 3, pp. 89 –106, Dec. 1990, doi: 10.1080/07421222.1990.11517898
-
[20]
A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection,
R. Kohavi, “A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, ” Proceedings of the 14th international joint conference on Artificial intelligence , pp. 1137– 1143, 1995
work page 1995
-
[21]
Deep Learning for Information Systems Research,
S. Samtani, H. Zhu, B. Padmanabhan, Y. Chai, and H. Chen, “Deep Learning for Information Systems Research,” no. Dl, pp. 1–55, 2020, [Online]. Available: http://arxiv.org/abs/2010.05774
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.