How LLMs See Creativity: Zero-Shot Scoring of Visual Creativity with Interpretable Reasoning
Pith reviewed 2026-07-01 07:09 UTC · model grok-4.3
The pith
Multimodal LLMs can judge visual creativity zero-shot and align with human ratings on images and sketches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
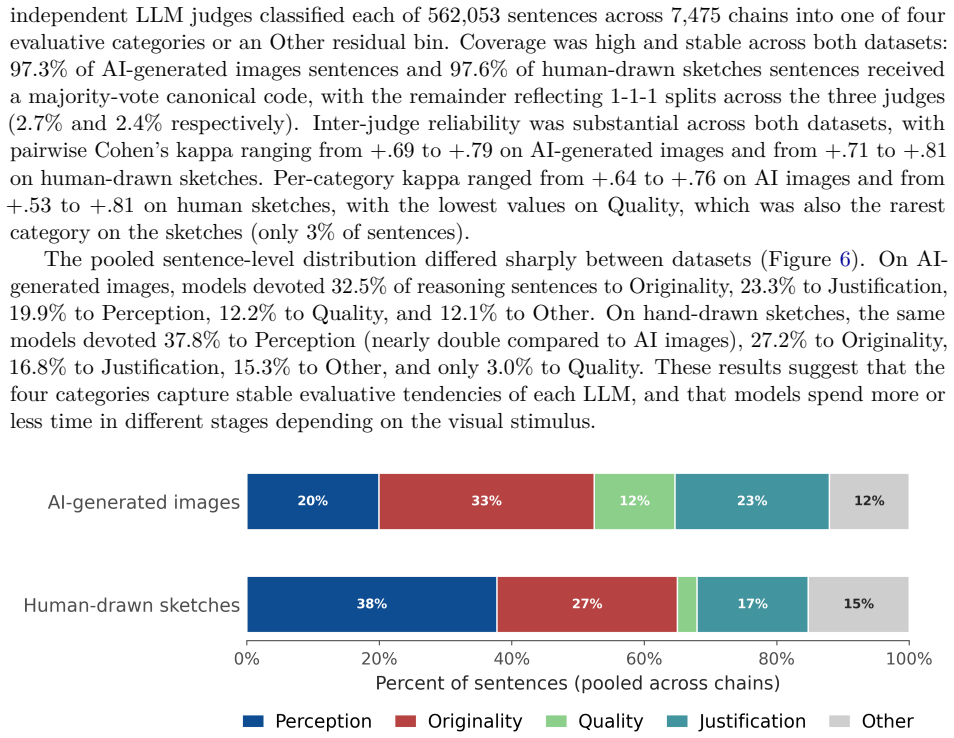
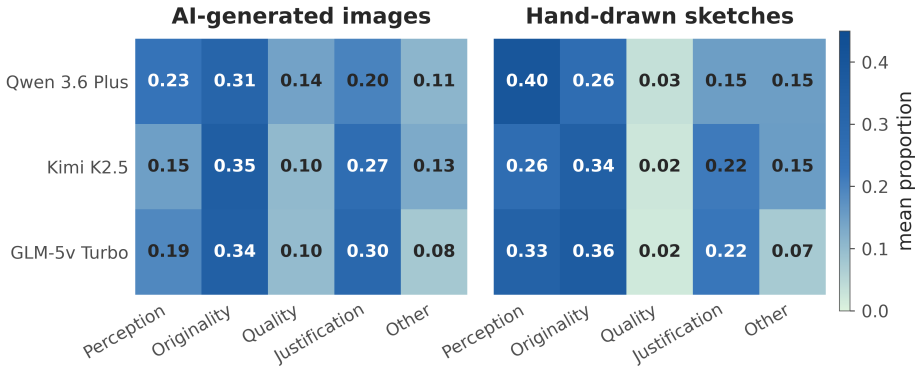
The central finding is that multimodal LLMs, when prompted zero-shot, produce creativity ratings for both AI-generated images and hand-drawn sketches that correlate substantially with human judgments, and that their chain-of-thought reasoning provides an interpretable account of the features and trade-offs they consider in arriving at those ratings.
What carries the argument
Zero-shot multimodal prompting for creativity scoring combined with analysis of the models' step-by-step reasoning outputs.
If this is right
- Large collections of visual works can be scored for creativity automatically.
- Model reasoning can be inspected to understand evaluation criteria like originality and quality.
- The same approach works across different image types without model-specific adjustments.
- Public tools can be built to apply this scoring pipeline.
Where Pith is reading between the lines
- This capability might reflect how LLMs encode common cultural notions of visual creativity from their training data.
- The method could extend to evaluating creativity in other visual domains such as design or photography.
- Discrepancies between models and humans on specific images might highlight unique human perceptual biases.
- Future work could test whether fine-tuning on human ratings further improves performance or changes the reasoning patterns.
Load-bearing premise
The collected human ratings represent an accurate and unbiased measure of visual creativity that the LLMs are attempting to approximate.
What would settle it
Collecting new human ratings on a held-out set of similar images and finding that LLM scores no longer correlate above chance levels with those ratings.
Figures




read the original abstract
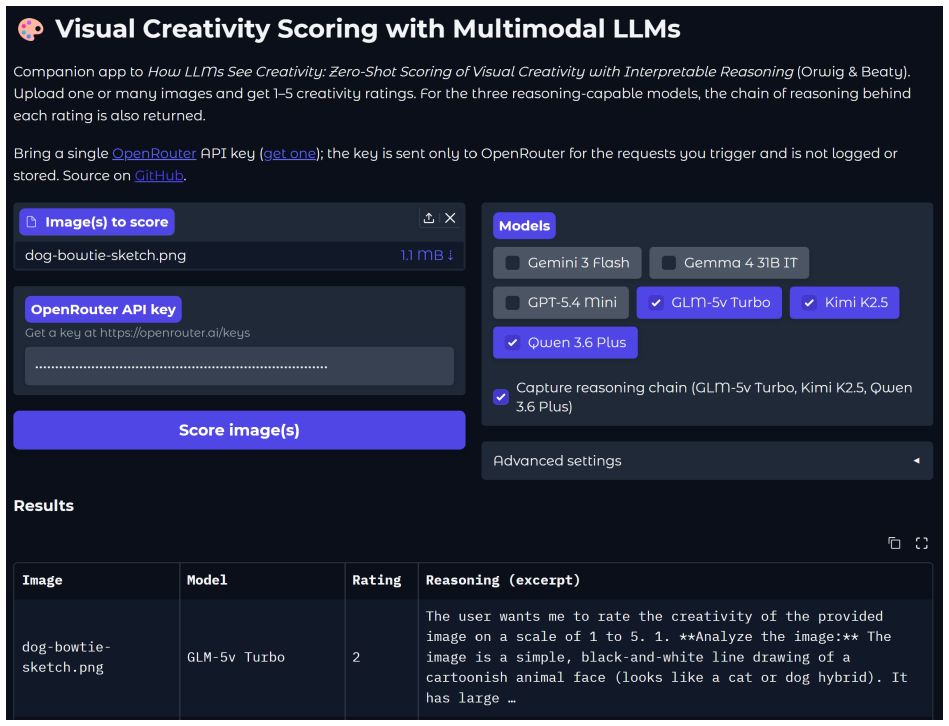
Evaluating the originality of visual images poses enduring challenges for creativity assessment. Automated scoring using AI models has proven effective in the verbal domain, yet key questions remain about evaluating visual creativity and understanding how models arrive at their ratings. The present research asks whether multimodal large language models (LLMs) can serve as judges of visual creativity zero-shot (without any fine-tuning or examples of human ratings) and whether their "reasoning" output offers an interpretable window into their evaluation process. We tested six multimodal LLMs (Gemini 3 Flash, Gemma 4 31B IT, GPT-5.4 Mini, GLM-5v Turbo, Kimi K2.5, and Qwen 3.6 Plus) on 992 AI-generated images (based on human-written prompts) and 1,500 hand-drawn sketches scored for creativity by human raters. In Study 1, all models showed substantial alignment with human creativity ratings on both datasets (r = .57-.68 on AI-generated images; r = .29-68 on sketches). In Study 2, we analyzed the step-by-step reasoning processes of three LLMs evaluating the same images and drawings. Although reasoning made model evaluations interpretable -- showing what they attend to, how they balance originality vs. quality, and how they justify their ratings -- reasoning did not improve alignment with human ratings. In sum, our findings indicate that multimodal LLMs can match human judgments of visual creativity without any additional training, and that their reasoning reveals how AI models evaluate creativity. An open scoring app implementing this pipeline is available at https://review-visual-eval-scoring.hf.space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that six multimodal LLMs can perform zero-shot scoring of visual creativity on 992 prompt-based AI-generated images and 1,500 hand-drawn sketches, achieving Pearson correlations of r = .57-.68 and r = .29-.68 respectively with human ratings; Study 2 further shows that the models' step-by-step reasoning is interpretable (attending to originality vs. quality) but does not improve alignment, supporting the conclusion that LLMs can serve as automated, interpretable judges of visual creativity without fine-tuning.
Significance. If the alignment specifically tracks the creativity construct rather than correlated attributes, the work would offer a practical, scalable method for visual creativity assessment with built-in interpretability via reasoning traces; the release of an open scoring app strengthens reproducibility and utility.
major comments (3)
- [Abstract, Study 1] Abstract and Study 1: The reported Pearson r values for alignment with human creativity ratings supply no inter-rater reliability statistics (e.g., ICC, Cronbach's alpha, or percentage agreement) for the human scores on either dataset; without this, it is impossible to determine whether the observed correlations reflect stable measurement of the target construct or shared noise.
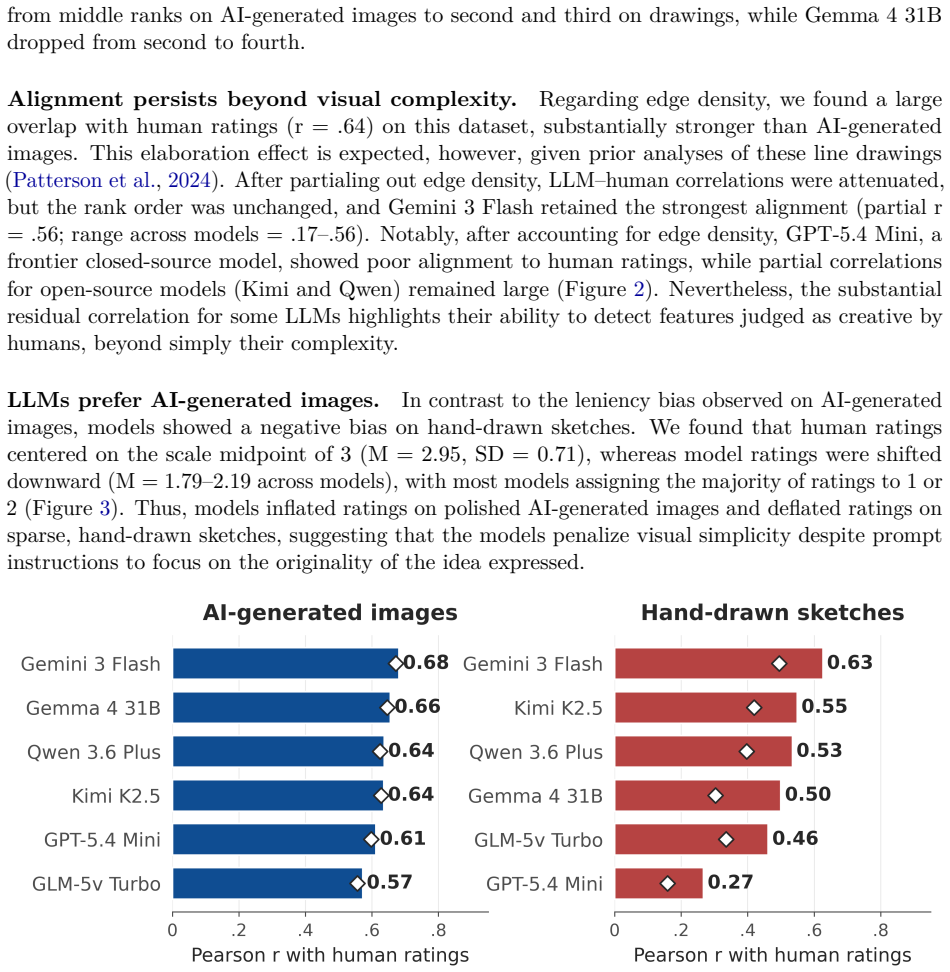
- [Study 1] Study 1, AI-generated image results: No partial correlations, auxiliary ratings (image quality, prompt adherence, aesthetic appeal), or discriminant validity checks are reported to test whether model scores track originality/usefulness rather than prompt fidelity or visual polish; this is load-bearing because the images are generated from human prompts, making such confounds plausible explanations for r ≈ .6.
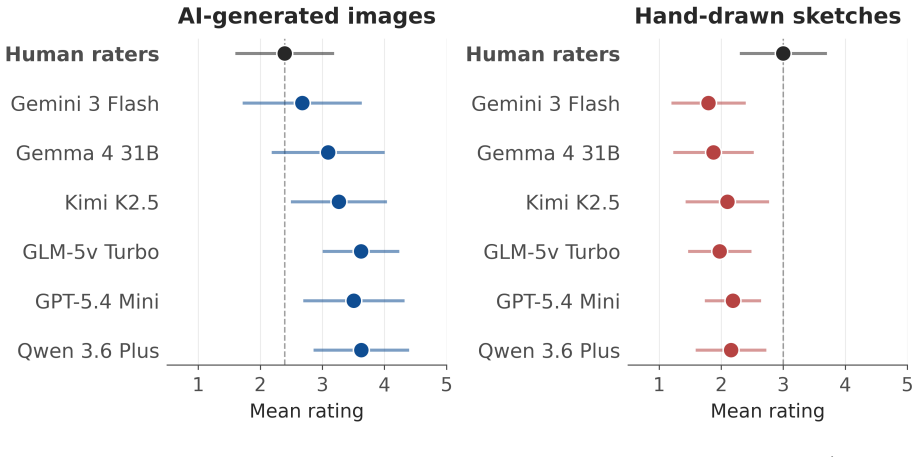
- [Study 1] Study 1, sketch dataset: The correlation range includes a lower bound of r = .29 with no accompanying analysis of dataset- or model-specific moderators, statistical tests for the correlations, or confidence intervals; this undermines the uniform claim of "substantial alignment" across both datasets.
minor comments (1)
- [Abstract] Abstract: the reported range "r = .29-68" for sketches is missing a decimal point and should read "r = .29-.68".
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on measurement issues. We address each major comment below with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, Study 1] Abstract and Study 1: The reported Pearson r values for alignment with human creativity ratings supply no inter-rater reliability statistics (e.g., ICC, Cronbach's alpha, or percentage agreement) for the human scores on either dataset; without this, it is impossible to determine whether the observed correlations reflect stable measurement of the target construct or shared noise.
Authors: We agree that inter-rater reliability statistics are necessary to properly interpret the reported correlations. The human ratings originate from prior datasets; in the revision we will add any available IRR metrics from the source studies or explicitly note their absence as a limitation if unavailable. This will clarify the upper bound on achievable alignment. revision: yes
-
Referee: [Study 1] Study 1, AI-generated image results: No partial correlations, auxiliary ratings (image quality, prompt adherence, aesthetic appeal), or discriminant validity checks are reported to test whether model scores track originality/usefulness rather than prompt fidelity or visual polish; this is load-bearing because the images are generated from human prompts, making such confounds plausible explanations for r ≈ .6.
Authors: This concern is valid given the prompt-based generation process. While models received explicit instructions to score creativity, auxiliary attributes could contribute. In revision we will add partial correlations or auxiliary analyses where the datasets contain relevant ratings; otherwise we will expand the discussion to address this potential confound and its implications for the zero-shot results. revision: partial
-
Referee: [Study 1] Study 1, sketch dataset: The correlation range includes a lower bound of r = .29 with no accompanying analysis of dataset- or model-specific moderators, statistical tests for the correlations, or confidence intervals; this undermines the uniform claim of "substantial alignment" across both datasets.
Authors: We acknowledge that the lower correlation (r = .29) and lack of supporting statistics weaken the uniformity claim. The revision will include confidence intervals, significance tests, moderator analyses (e.g., by model or sketch features), and revised language describing alignment as ranging from moderate to substantial. revision: yes
Circularity Check
Empirical benchmarking study with no derivation chain or self-referential steps
full rationale
The paper reports direct Pearson correlations between LLM zero-shot ratings and external human creativity ratings on two image datasets (r values given in abstract). No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central claim rests on empirical alignment with independent human data rather than any internal reduction or ansatz. This is a standard external-validation design; the derivation chain is empty by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human ratings collected on the image sets constitute a stable ground truth for visual creativity
Reference graph
Works this paper leans on
-
[1]
The Journal of Creative Behavior , volume =
Acar, Selcuk and Organisciak, Peter and Dumas, Denis , title =. The Journal of Creative Behavior , volume =. 2025 , doi =
2025
-
[2]
, title =
Amabile, Teresa M. , title =. Journal of Personality and Social Psychology , volume =. 1982 , doi =
1982
-
[3]
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Avogaro, Niccolo and Debnath, Nayanika and Mi, Li and Frick, Thomas and Wang, Junling and He, Zexue and Hua, Hang and Schindler, Konrad and Rigotti, Mattia , title =. 2026 , note =. doi:10.48550/arXiv.2602.06566 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.06566 2026
-
[4]
and Johnson, Dan R
Beaty, Roger E. and Johnson, Dan R. , title =. Behavior Research Methods , volume =. 2021 , doi =
2021
-
[5]
Chiang, Cheng-Han and Lee, Hung-yi , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , publisher =. doi:10.18653/v1/2023.acl-long.870 , url =
-
[6]
and Marrone, Rebecca L
Cropley, David H. and Marrone, Rebecca L. , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2025 , doi =
2025
-
[7]
and Theurer, Caroline and Mathijssen, Anne C
Cropley, David H. and Theurer, Caroline and Mathijssen, Anne C. S. and Marrone, Rebecca L. , title =. Creativity Research Journal , volume =. 2025 , doi =
2025
-
[8]
and Patterson, John D
DiStefano, Paul V. and Patterson, John D. and Beaty, Roger E. , title =. Creativity Research Journal , volume =. 2025 , doi =
2025
-
[9]
The Effect of Idea Elaboration on the Automatic Assessment of Idea Originality
Domanti, Umberto and Mock, Moritz and Agnoli, Sergio and De Angeli, Antonella , title =. 2026 , note =. doi:10.48550/arXiv.2604.20569 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.20569 2026
-
[10]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Dong, Qingxiu and Li, Lei and Dai, Damai and Zheng, Ce and Ma, Jingyuan and Li, Rui and Xia, Heming and Xu, Jingjing and Wu, Zhiyong and Chang, Baobao and Sun, Xu and Li, Lei and Sui, Zhifang , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =. doi:10.18653/v1/2024.emnlp-main.64 , url =
-
[11]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
2025
-
[12]
Jiang, Chaoya and Heng, Yongrui and Ye, Wei and Yang, Han and Xu, Haiyang and Yan, Ming and Zhang, Ji and Huang, Fei and Zhang, Shikun , title =. 2025 , note =. doi:10.48550/arXiv.2505.16192 , eprint =
-
[13]
and Maliakkal, Nadine T
Luchini, Simone A. and Maliakkal, Nadine T. and DiStefano, Paul V. and Laverghetta, Antonio and Patterson, John D. and Beaty, Roger E. and Reiter-Palmon, Roni , title =. Psychology of Aesthetics, Creativity, and the Arts , year =
-
[14]
Psychology of Aesthetics, Creativity, and the Arts , volume =
Myszkowski, Nils and Storme, Martin , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2019 , doi =
2019
-
[15]
Thinking Skills and Creativity , volume =
Organisciak, Peter and Acar, Selcuk and Dumas, Denis and Berthiaume, Kelly , title =. Thinking Skills and Creativity , volume =. 2023 , doi =
2023
-
[16]
and Barr, Nathaniel and Seli, Paul , title =
Orwig, William and Bellaiche, Lucas and Spooner, Sarah and Vo, Anh and Baig, Zia and Ragnhildstveit, Anya and Schacter, Daniel L. and Barr, Nathaniel and Seli, Paul , title =. Creativity Research Journal , volume =. 2026 , doi =
2026
-
[17]
and Greene, Joshua D
Orwig, William and Edenbaum, Emma R. and Greene, Joshua D. and Schacter, Daniel L. , title =. The Journal of Creative Behavior , volume =. 2024 , doi =
2024
-
[18]
and Feng, Shi , title =
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , title =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[19]
and Barbot, Baptiste and Lloyd-Cox, James and Beaty, Roger E
Patterson, John D. and Barbot, Baptiste and Lloyd-Cox, James and Beaty, Roger E. , title =. Behavior Research Methods , volume =. 2024 , doi =
2024
-
[20]
and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G
Patterson, John D. and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G. and Miller, Scarlett R. and Johnson, Dan R. and Beaty, Roger E. , title =. Behavior Research Methods , volume =. 2025 , doi =
2025
-
[21]
and Kaufman, James C
Rafner, Janet and Beaty, Roger E. and Kaufman, James C. and Lubart, Todd and Sherson, Jacob , title =. Nature Human Behaviour , volume =. 2023 , doi =
2023
-
[22]
Journal of Intelligence , volume =
Saretzki, Janika and Knopf, Thomas and Forthmann, Boris and Goecke, Benjamin and Jaggy, Ann-Kathrin and Benedek, Mathias and Weiss, Selina , title =. Journal of Intelligence , volume =. 2025 , doi =
2025
-
[23]
and Winterstein, Beate P
Silvia, Paul J. and Winterstein, Beate P. and Willse, John T. and Barona, Christopher M. and Cram, Joshua T. and Hess, Karl I. and Martinez, Jenna L. and Richard, Crystal A. , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2008 , doi =
2008
-
[24]
Self-Preference Bias in LLM-as-a-Judge
Wataoka, Koki and Takahashi, Tsubasa and Ri, Ryokan , title =. 2024 , note =. doi:10.48550/arXiv.2410.21819 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21819 2024
-
[25]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[26]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.