scaleTRIM: Scalable TRuncation-Based Integer Approximate Multiplier with Linearization and Compensation
Pith reviewed 2026-05-24 09:58 UTC · model grok-4.3
The pith
scaleTRIM approximates multiplication by fitting linear functions to truncated operands and adding piecewise error compensation from segment averages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
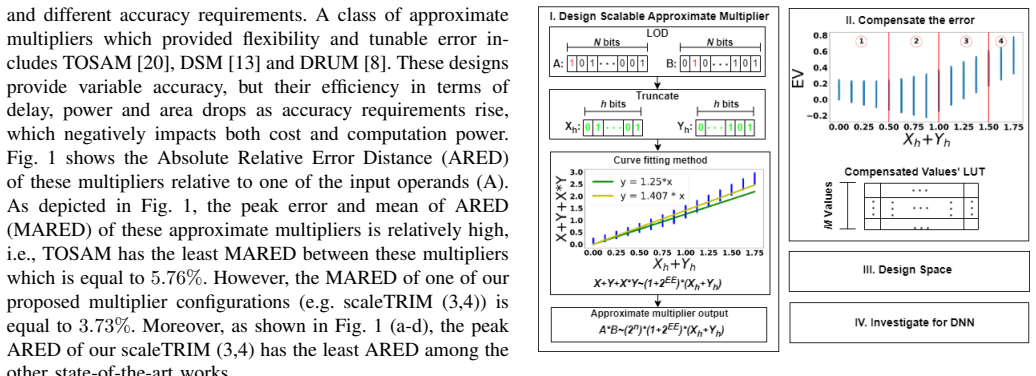
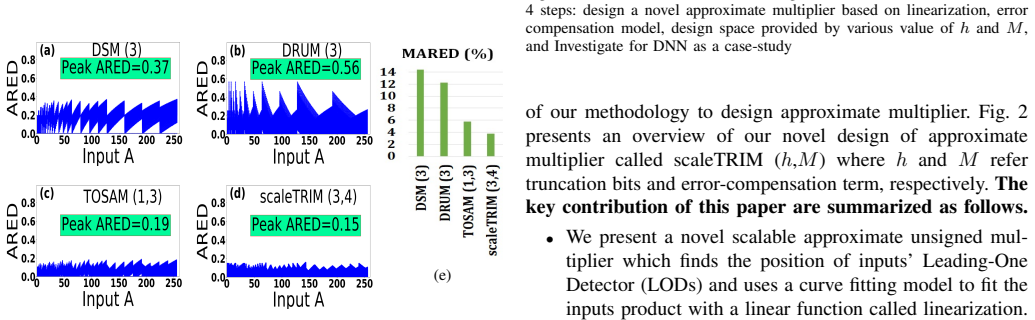
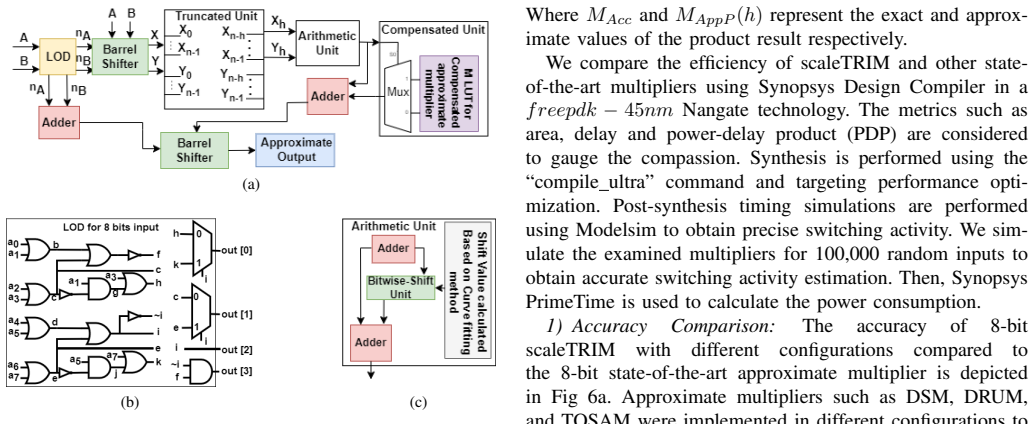
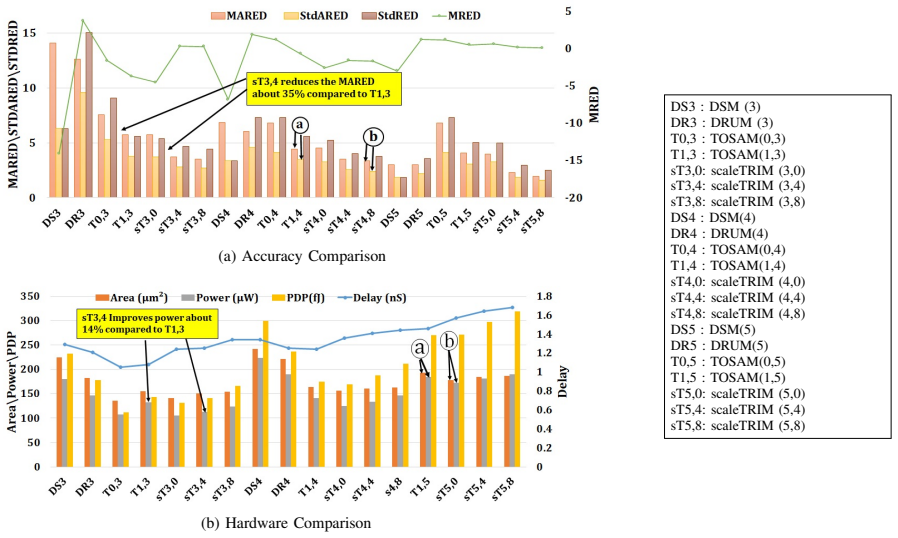
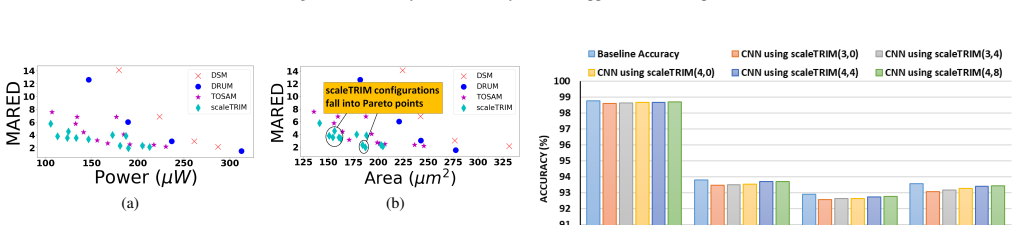
Multiplication of two integers can be replaced by a linear function fitted to their h-bit truncated versions together with an M-segment piecewise-constant correction obtained by averaging the residual error inside each segment; the resulting circuit uses only additions, shifts, and a lookup table and yields lower mean relative error distance and lower power-delay product than existing approximate multipliers while preserving usability inside DNN inference workloads.
What carries the argument
Truncation of operands to h bits followed by curve-fitted linearization of the product term and an M-segment piecewise-average error compensation unit realized with a lookup table.
If this is right
- Designers can select any truncation depth and any number of compensation segments to obtain a desired accuracy-efficiency operating point without redesigning the core arithmetic.
- The multiplier satisfies both the accuracy constraint and the efficiency constraint while improving mean relative error distance relative to prior art.
- The multiplier satisfies both the accuracy constraint and the efficiency constraint while improving power-delay product relative to prior art.
- When substituted into deep neural networks for image classification, the design produces a measurably better accuracy-efficiency trade-off than the compared state-of-the-art approximate multipliers.
Where Pith is reading between the lines
- The same truncation-plus-linear-fit pattern could be retargeted to other fixed-point arithmetic operations such as squaring or division by deriving new fitting coefficients and segment tables.
- An adaptive version that chooses the number of segments or the truncation depth at run time according to operand statistics might further improve the average trade-off without changing the hardware template.
- Because the method is parameter-free once the linear coefficients and segment table are stored, it could be instantiated for many different integer widths simply by regenerating the small lookup tables.
Load-bearing premise
The linear functions obtained by curve fitting on the truncated operands and the piecewise averages used for compensation will continue to produce the reported accuracy-efficiency numbers for the bit widths, input distributions, and DNN workloads examined in the evaluation.
What would settle it
Measuring mean relative error distance and power-delay product on the same bit widths but with input distributions or neural-network models drawn from a source materially different from those used in the paper and finding that the claimed 15.2 percent and 22.8 percent gains disappear or reverse.
Figures

read the original abstract
In this paper, we propose a scalable approximate multiplier design, scaleTRIM, that approximates the multiplication operation using fitted linear functions, also referred to as linearization. We show that multiplication operations can be completely replaced by low-cost addition and bit-wise shift operations by exploiting linearization. Moreover, our proposed design utilizes a lookup table (LUT)-based compensation unit as a novel error-reduction method. In essence, input operands are truncated to a reduced bit-width representation (i.e., h bits) based on their leading-one positions. Then, a curve-fitting method is employed to map the product term to a linear function. Additionally, a piecewise constant error-correction term is used to reduce the approximation error. To compute the piecewise constant, we divide the function space into M segments and average the errors within each segment. In particular, our multiplier supports various degrees of truncation and error compensation to offer a range of accuracy-efficiency trade-offs. The proposed multiplier improves the Mean Relative Error Distance (MRED) by about 15.2% while satisfying the efficiency constraint and improves the Power Delay Product (PDP) by about 22.8% while satisfying the accuracy and efficiency constraints compared to different state-of-the-art approximate multipliers. From a usability perspective, our evaluation of the proposed design for image classification using Deep Neural Networks (DNNs) demonstrates that scaleTRIM offers a better accuracy-efficiency trade-off than state-of-the-art approximate multiplier designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes scaleTRIM, a scalable approximate integer multiplier that truncates operands to h bits based on leading-one position, replaces multiplication with low-cost linear functions (additions and shifts) obtained via curve-fitting, and applies a LUT-based piecewise constant compensation (M segments, segment-wise error averages) for error reduction. It reports ~15.2% MRED improvement under efficiency constraints and ~22.8% PDP improvement under accuracy/efficiency constraints versus prior approximate multipliers, plus improved accuracy-efficiency trade-offs when used in DNN image classification.
Significance. If the accuracy and efficiency gains prove robust to input distributions and bit-widths beyond the fitting data, the design contributes a tunable truncation-plus-linearization methodology that converts multiplication to add/shift operations with explicit compensation, offering a new point in the approximate-computing design space for energy-constrained accelerators.
major comments (3)
- [Abstract / design methodology] Abstract and design section: the linear functions are obtained by curve-fitting directly to the product of the truncated operands being approximated, and the piecewise constants are segment-wise averages computed on the identical error surface; this makes the reported MRED/PDP gains specific to the fitting distribution and segment boundaries rather than intrinsic, undermining the claim of general scalability across bit-widths and DNN workloads without per-application retuning.
- [Evaluation / results] Evaluation section: the headline 15.2% MRED and 22.8% PDP improvements are stated without error bars, statistical tests, or explicit description of how the curve-fitting was validated (e.g., hold-out sets, cross-distribution testing); the central empirical claim therefore rests on point estimates whose stability is unquantified.
- [DNN evaluation] DNN evaluation: while the paper shows better trade-offs on image classification, it does not report whether the same (h, M) parameters fitted on generic operands were used or whether retuning was performed per network; this directly affects the usability claim.
minor comments (2)
- [Design] Notation for the linear function coefficients and the exact definition of the truncation width h should be introduced with an equation in the design section for reproducibility.
- [Abstract / results tables] The abstract states concrete percentage improvements; the corresponding tables or figures should explicitly list the exact baseline designs and bit-widths used for each comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses to the major comments below, indicating where we agree and will make revisions.
read point-by-point responses
-
Referee: [Abstract / design methodology] Abstract and design section: the linear functions are obtained by curve-fitting directly to the product of the truncated operands being approximated, and the piecewise constants are segment-wise averages computed on the identical error surface; this makes the reported MRED/PDP gains specific to the fitting distribution and segment boundaries rather than intrinsic, undermining the claim of general scalability across bit-widths and DNN workloads without per-application retuning.
Authors: The curve-fitting and compensation calculations are performed exhaustively over all possible combinations of the h-bit truncated operands, which constitute the complete function space rather than samples from any particular distribution. This makes the approximation intrinsic to the truncated multiplication operation. The scalability arises from the parametric nature of h and M, allowing the same methodology to be applied to different bit-widths. We will revise the design section to clarify that the fitting uses exhaustive enumeration of the truncated operand space. revision: partial
-
Referee: [Evaluation / results] Evaluation section: the headline 15.2% MRED and 22.8% PDP improvements are stated without error bars, statistical tests, or explicit description of how the curve-fitting was validated (e.g., hold-out sets, cross-distribution testing); the central empirical claim therefore rests on point estimates whose stability is unquantified.
Authors: We agree that more details on the validation of the curve-fitting would strengthen the paper. Since the fitting is deterministic and based on the exact mathematical products, hold-out validation is not relevant. We will add an explicit description of the curve-fitting and compensation computation process in the revised manuscript. We will also consider including results across multiple input distributions to quantify stability. revision: yes
-
Referee: [DNN evaluation] DNN evaluation: while the paper shows better trade-offs on image classification, it does not report whether the same (h, M) parameters fitted on generic operands were used or whether retuning was performed per network; this directly affects the usability claim.
Authors: We will update the DNN evaluation section to clarify that the (h, M) parameters were selected from the general accuracy-efficiency characterization of the multiplier and used consistently across all DNN experiments without any per-network retuning. This supports the claim of usability as a general-purpose approximate multiplier. revision: yes
Circularity Check
No significant circularity; design uses explicit curve-fitting as stated method
full rationale
The paper explicitly describes its core technique as employing curve-fitting to obtain linear functions for truncated operands and computing piecewise averages for compensation. These are presented as design choices for an approximate multiplier, not as a first-principles derivation or prediction. Performance claims (MRED/PDP improvements) are empirical comparisons to other designs and exact multiplication, with no reduction of the central result to a self-referential fit or self-citation chain. The approach is self-contained engineering work; the fitting process is the approximation mechanism itself rather than a hidden circular step.
Axiom & Free-Parameter Ledger
free parameters (3)
- linear function coefficients
- M (number of segments)
- h (truncation width)
axioms (1)
- domain assumption Multiplication of truncated operands can be usefully approximated by a linear function of the inputs.
Reference graph
Works this paper leans on
-
[2]
An Improved Logarithmic Multiplier for Energy-Efficient Neural Computing
Mohammad Saeed Ansari, Bruce F. Cockburn, and Jie Han. “An Improved Logarithmic Multiplier for Energy-Efficient Neural Computing”. In: IEEE Trans- actions on Computers 70.4 (2021), pp. 614–625. DOI: 10.1109/TC.2020.2992113
-
[3]
AdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch
Dimitrios Danopoulos et al. “AdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch”. In: IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (2022), pp. 1–1. DOI: 10 . 1109 / TCAD . 2022 . 3212645
work page 2022
-
[4]
On the use of approximate adders in carry-save multiplier- accumulators
Darjn Esposito et al. “On the use of approximate adders in carry-save multiplier- accumulators”. In: 2017 IEEE International Symposium on Circuits and Systems (ISCAS). 2017, pp. 1–4. DOI: 10.1109/ISCAS.2017.8050437
-
[5]
Approximate multipliers based on a novel unbiased approximate 4-2 compressor
Bao Fang et al. “Approximate multipliers based on a novel unbiased approximate 4-2 compressor”. In: Integration 81 (2021), pp. 17–24
work page 2021
-
[6]
High performance and optimal configuration of accurate heterogeneous block-based approximate adder
Ebrahim Farahmand et al. “High performance and optimal configuration of accurate heterogeneous block-based approximate adder”. In: arXiv preprint arXiv:2106.08800 (2021)
-
[7]
Muhammad Abdullah Hanif, Rehan Hafiz, and Muhammad Shafique. “Error resilience analysis for systematically employing approximate computing in con- volutional neural networks”. In: 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE) . 2018, pp. 913–916. DOI: 10 . 23919 / DATE . 2018.8342139
-
[8]
DRUM: A Dynamic Range Unbiased Multiplier for approximate applications
Soheil Hashemi, R. Iris Bahar, and Sherief Reda. “DRUM: A Dynamic Range Unbiased Multiplier for approximate applications”. In: 2015 IEEE/ACM Interna- tional Conference on Computer-Aided Design (ICCAD). 2015, pp. 418–425. DOI: 10.1109/ICCAD.2015.7372600
-
[9]
ApproxLP: Approximate Multiplication with Linearization and Iterative Error Control
Mohsen Imani et al. “ApproxLP: Approximate Multiplication with Linearization and Iterative Error Control”. In: 2019 56th ACM/IEEE Design Automation Conference (DAC). 2019, pp. 1–6
work page 2019
-
[10]
A review, classification, and comparative evaluation of approximate arithmetic circuits
Honglan Jiang et al. “A review, classification, and comparative evaluation of approximate arithmetic circuits”. In: ACM Journal on Emerging Technologies in Computing Systems (JETC) 13.4 (2017), pp. 1–34
work page 2017
-
[11]
Leading one detectors and leading one position detectors - An evolutionary design methodology
K. Kunaraj and R. Seshasayanan. “Leading one detectors and leading one position detectors - An evolutionary design methodology”. In: Canadian Journal of Electrical and Computer Engineering 36.3 (2013), pp. 103–110. DOI: 10.1109/ CJECE.2013.6704691
-
[12]
Computer Multiplication and Division Using Binary Loga- rithms
John N. Mitchell. “Computer Multiplication and Division Using Binary Loga- rithms”. In: IRE Transactions on Electronic Computers EC-11.4 (1962), pp. 512–
work page 1962
-
[13]
DOI: 10.1109/TEC.1962.5219391
-
[14]
Srinivasan Narayanamoorthy et al. “Energy-Efficient Approximate Multiplication for Digital Signal Processing and Classification Applications”. In: IEEE Transac- tions on Very Large Scale Integration (VLSI) Systems23.6 (2015), pp. 1180–1184. DOI: 10.1109/TVLSI.2014.2333366
-
[15]
Architectural-space exploration of approximate multipli- ers
Semeen Rehman et al. “Architectural-space exploration of approximate multipli- ers”. In: 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE. 2016, pp. 1–8
work page 2016
-
[16]
Minimally Biased Multipliers for Approximate Integer and Floating-Point Multiplication
Hassaan Saadat, Haseeb Bokhari, and Sri Parameswaran. “Minimally Biased Multipliers for Approximate Integer and Floating-Point Multiplication”. In: IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems37.11 (2018), pp. 2623–2635. DOI: 10.1109/TCAD.2018.2857262
-
[17]
REALM: Reduced-Error Approximate Log-based Integer Multiplier
Hassaan Saadat et al. “REALM: Reduced-Error Approximate Log-based Integer Multiplier”. In: 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE) . 2020, pp. 1366–1371. DOI: 10 . 23919 / DATE48585 . 2020 . 9116315
work page 2020
-
[18]
Cross-layer approximate computing: From logic to architectures
Muhammad Shafique et al. “Cross-layer approximate computing: From logic to architectures”. In: Proceedings of the 53rd Annual Design Automation Confer- ence. 2016, pp. 1–6
work page 2016
-
[19]
High-performance accurate and approximate multipliers for fpga-based hardware accelerators
Salim Ullah et al. “High-performance accurate and approximate multipliers for fpga-based hardware accelerators”. In: IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 41.2 (2021), pp. 211–224
work page 2021
-
[20]
LETAM: A low energy truncation-based approximate multiplier
Shaghayegh Vahdat et al. “LETAM: A low energy truncation-based approximate multiplier”. In: Computers & Electrical Engineering 63 (2017), pp. 1–17. ISSN : 0045-7906. DOI: https://doi.org/10.1016/j.compeleceng.2017.08.019
-
[21]
TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approximate Multiplier
Shaghayegh Vahdat et al. “TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approximate Multiplier”. In: IEEE Transactions on Very Large Scale Integration (VLSI) Systems 27.5 (2019), pp. 1161–1173. DOI: 10.1109/TVLSI.2018.2890712
-
[22]
Approximate computing and the quest for comput- ing efficiency
Swagath Venkataramani et al. “Approximate computing and the quest for comput- ing efficiency”. In: 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC). IEEE. 2015, pp. 1–6
work page 2015
-
[23]
Reza Zendegani et al. “RoBA Multiplier: A Rounding-Based Approximate Multiplier for High-Speed yet Energy-Efficient Digital Signal Processing”. In: IEEE Transactions on Very Large Scale Integration (VLSI) Systems 25.2 (2017), pp. 393–401. DOI: 10.1109/TVLSI.2016.2587696
-
[24]
Design-Efficient Approximate Multiplication Circuits Through Partial Product Perforation
Georgios Zervakis et al. “Design-Efficient Approximate Multiplication Circuits Through Partial Product Perforation”. In: IEEE Transactions on Very Large Scale Integration (VLSI) Systems 24.10 (2016), pp. 3105–3117. DOI: 10.1109/TVLSI. 2016.2535398
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.