On Diffusion Modeling for Anomaly Detection
Pith reviewed 2026-05-24 08:41 UTC · model grok-4.3
The pith
Diffusion Time Estimation simplifies DDPM into a fast anomaly scorer using diffusion time distribution
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By simplifying DDPM for anomaly detection the authors obtain an analytical expression for the density over diffusion time; a neural network then estimates this density so that its mode or mean can be used directly as an anomaly score. On ADBench this score yields competitive detection performance in both unsupervised and semi-supervised settings while running far faster than full DDPM sampling.
What carries the argument
Diffusion Time Estimation (DTE): the derived density over diffusion time for an input, whose mode or mean supplies the anomaly score
If this is right
- Diffusion-based detectors are competitive with existing methods for both unsupervised and semi-supervised anomaly detection.
- DTE inference is orders of magnitude faster than DDPM while matching or exceeding its benchmark scores.
- Diffusion modeling therefore supplies a practical, scalable route to anomaly detection.
Where Pith is reading between the lines
- The analytical density derived for DTE may allow closed-form analysis of how diffusion steps separate normal from anomalous points.
- DTE could be paired with other generative backbones that admit a diffusion-time interpretation.
Load-bearing premise
The mode or mean of the estimated distribution over diffusion time reliably flags anomalies for inputs drawn from the training distribution.
What would settle it
A result on ADBench in which DTE anomaly scores do not rank true anomalies above normal points or in which DTE inference time is not orders of magnitude below DDPM would refute the central performance claim.
Figures
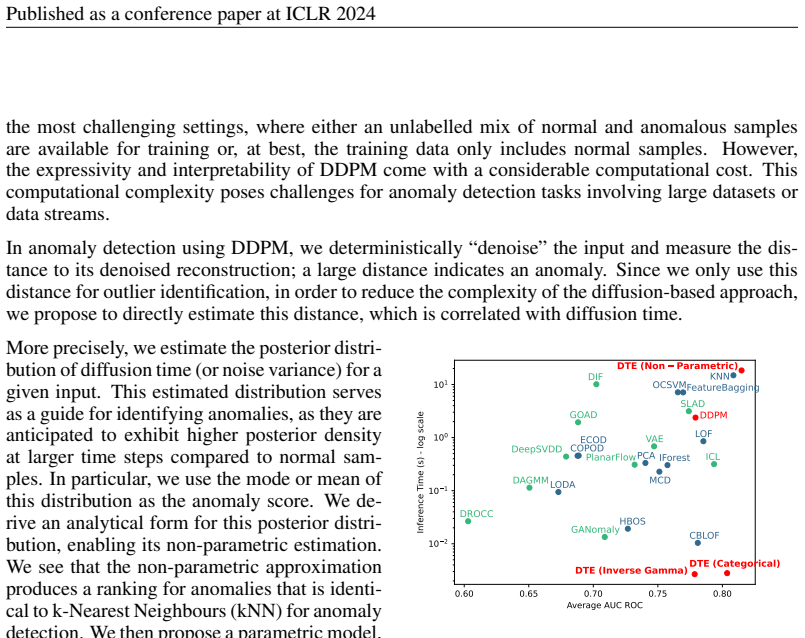








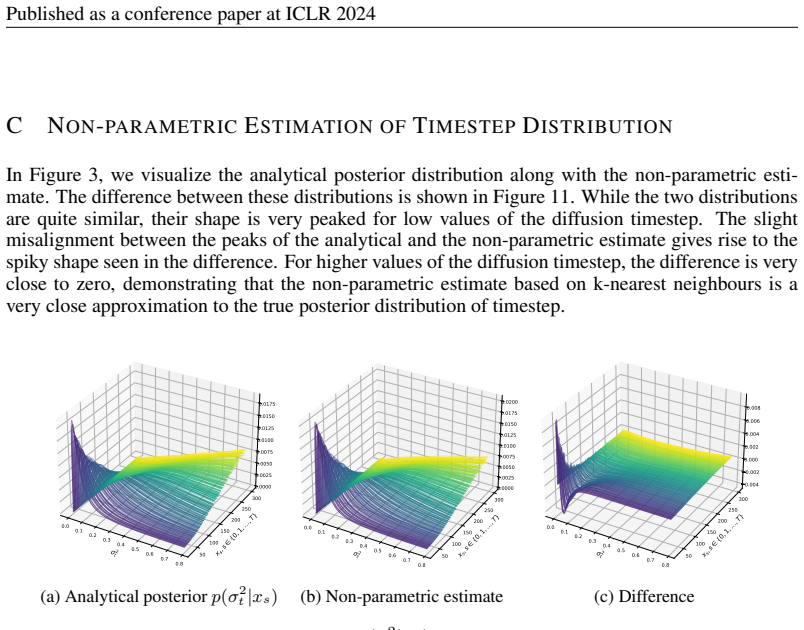



read the original abstract
Known for their impressive performance in generative modeling, diffusion models are attractive candidates for density-based anomaly detection. This paper investigates different variations of diffusion modeling for unsupervised and semi-supervised anomaly detection. In particular, we find that Denoising Diffusion Probability Models (DDPM) are performant on anomaly detection benchmarks yet computationally expensive. By simplifying DDPM in application to anomaly detection, we are naturally led to an alternative approach called Diffusion Time Estimation (DTE). DTE estimates the distribution over diffusion time for a given input and uses the mode or mean of this distribution as the anomaly score. We derive an analytical form for this density and leverage a deep neural network to improve inference efficiency. Through empirical evaluations on the ADBench benchmark, we demonstrate that all diffusion-based anomaly detection methods perform competitively for both semi-supervised and unsupervised settings. Notably, DTE achieves orders of magnitude faster inference time than DDPM, while outperforming it on this benchmark. These results establish diffusion-based anomaly detection as a scalable alternative to traditional methods and recent deep-learning techniques for standard unsupervised and semi-supervised anomaly detection settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the use of diffusion models for unsupervised and semi-supervised anomaly detection. It shows that DDPM achieves competitive results on the ADBench benchmark but is computationally expensive; it then proposes Diffusion Time Estimation (DTE), which derives an analytical density over diffusion time for a given input and uses the mode or mean of that distribution as the anomaly score, with a neural network to enable efficient inference. Empirical results indicate that diffusion-based methods (including DTE) perform competitively in both settings, with DTE achieving orders-of-magnitude faster inference while outperforming DDPM.
Significance. If the benchmark results hold under standard evaluation protocols, the work provides evidence that diffusion models can serve as a practical, scalable alternative for anomaly detection, with DTE's efficiency advantage being a concrete contribution. The explicit analytical derivation of the time-density and its empirical validation on a public benchmark (ADBench) are strengths that support reproducibility.
major comments (2)
- [Experiments section (ADBench results)] Experiments section (ADBench results): the outperformance of DTE over DDPM is load-bearing for the central empirical claim, yet the manuscript does not report whether hyperparameter search budgets and data splits were held identical across all compared methods; without this, the speed/accuracy advantage cannot be isolated from implementation differences.
- [DTE derivation] DTE derivation: the mapping from the estimated time distribution to the final anomaly score (mode or mean) is presented as a simplification that works in practice, but the paper provides no ablation showing that alternative statistics (e.g., variance or entropy) yield materially worse detection; this choice is therefore not yet shown to be robust.
minor comments (2)
- Notation for the analytical density p(t|x) should be introduced once in the main text with a clear reference to the appendix derivation rather than appearing only in the latter.
- Figure captions for runtime comparisons should state the hardware platform and batch size used, to allow direct replication of the reported speed-up.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address the two major comments below.
read point-by-point responses
-
Referee: Experiments section (ADBench results): the outperformance of DTE over DDPM is load-bearing for the central empirical claim, yet the manuscript does not report whether hyperparameter search budgets and data splits were held identical across all compared methods; without this, the speed/accuracy advantage cannot be isolated from implementation differences.
Authors: We agree that explicit confirmation of identical experimental conditions is necessary to isolate methodological differences. The original experiments followed ADBench's provided data splits and applied comparable hyperparameter tuning effort (grid/random search within similar compute limits) to all methods including DDPM. We will revise the Experiments section to document the search budgets, ranges, and confirmation of identical splits. revision: yes
-
Referee: DTE derivation: the mapping from the estimated time distribution to the final anomaly score (mode or mean) is presented as a simplification that works in practice, but the paper provides no ablation showing that alternative statistics (e.g., variance or entropy) yield materially worse detection; this choice is therefore not yet shown to be robust.
Authors: We thank the referee for highlighting this. The selection of mode/mean is motivated by the analytical density derivation, where normal points concentrate at lower diffusion times. We will add an ablation comparing mode, mean, variance, and entropy as anomaly scores on a representative subset of ADBench datasets to empirically support the choice. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical benchmark results from ADBench comparing diffusion variants (DDPM and DTE) for anomaly detection, with DTE positioned as a practical simplification that yields an analytical density over diffusion time whose mode/mean serves as the anomaly score. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the derivation of the density is presented as following from the diffusion process itself, and the evaluation is external to any internal fitting loop. The work is self-contained against the stated benchmark without invoking uniqueness theorems or ansatzes from prior author work as forcing functions.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights for time estimation
axioms (1)
- domain assumption The forward diffusion process follows the same Gaussian noise schedule as standard DDPM.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p(σ²_t | x_s) ∝ σ^{-d}_t exp(−||x_s||² / (2 σ²_t)) … inverse Gamma distribution … a = d/2−1, b = ||x_s||²/2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Beyond Binary Out-of-Distribution Detection: Characterizing Distributional Shifts with Multi-Statistic Diffusion Trajectories
DISC extracts multi-statistic trajectories from diffusion denoising to both detect and classify types of distributional shifts in OOD data.
-
uLEAD-TabPFN: Uncertainty-aware Dependency-based Anomaly Detection with TabPFN
uLEAD-TabPFN detects anomalies in tabular data by scoring violations of conditional dependencies estimated via frozen PFNs with uncertainty awareness, achieving top average rank and up to 20% ROC-AUC gains on high-dim...
Reference graph
Works this paper leans on
-
[1]
A survey of network anomaly detection techniques
Mohiuddin Ahmed, Abdun Naser Mahmood, and Jiankun Hu. A survey of network anomaly detection techniques. Journal of Network and Computer Applications, 60: 0 19--31, 2016 a
work page 2016
-
[2]
A survey of anomaly detection techniques in financial domain
Mohiuddin Ahmed, Abdun Naser Mahmood, and Md Rafiqul Islam. A survey of anomaly detection techniques in financial domain. Future Generation Computer Systems, 55: 0 278--288, 2016 b
work page 2016
-
[3]
Variational autoencoder based anomaly detection using reconstruction probability
Jinwon An and Sungzoon Cho. Variational autoencoder based anomaly detection using reconstruction probability. 2015
work page 2015
-
[4]
Classification-based anomaly detection for general data
Lion Bergman and Yedid Hoshen. Classification-based anomaly detection for general data. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=H1lK_lBtvS
work page 2020
-
[5]
Breunig, Hans-Peter Kriegel, Raymond T
Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, and J\" o rg Sander. Lof: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, SIGMOD '00, page 93–104, New York, NY, USA, 2000. Association for Computing Machinery. ISBN 1581132174. doi:10.1145/342009.335388. URL https://doi.or...
-
[6]
Varun Chandola, Arindam Banerjee, and Vipin Kumar. Anomaly detection: A survey. ACM Comput. Surv., 41 0 (3), jul 2009. ISSN 0360-0300. doi:10.1145/1541880.1541882. URL https://doi.org/10.1145/1541880.1541882
-
[7]
Erfani, Sutharshan Rajasegarar, Shanika Karunasekera, and Christopher Leckie
Sarah M. Erfani, Sutharshan Rajasegarar, Shanika Karunasekera, and Christopher Leckie. High-dimensional and large-scale anomaly detection using a linear one-class svm with deep learning. Pattern Recognition, 58: 0 121--134, 2016. ISSN 0031-3203. doi:https://doi.org/10.1016/j.patcog.2016.03.028. URL https://www.sciencedirect.com/science/article/pii/S003132...
-
[8]
Fauconnier and Gentiane Haesbroeck
C. Fauconnier and Gentiane Haesbroeck. Outliers detection with the minimum covariance determinant estimator in practice. Statistical Methodology, 6: 0 363--379, 07 2009. doi:10.1016/j.stamet.2008.12.005
-
[9]
Mishra, Bryan Ostdiek, and Matthew D
Katherine Fraser, Samuel Homiller, Rashmish K. Mishra, Bryan Ostdiek, and Matthew D. Schwartz. Challenges for unsupervised anomaly detection in particle physics. Journal of High Energy Physics, 2022 0 (3), mar 2022. doi:10.1007/jhep03(2022)066. URL https://doi.org/10.1007\
-
[10]
Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm
Markus Goldstein and Andreas Dengel. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. 09 2012
work page 2012
-
[11]
Lunar: Unifying local outlier detection methods via graph neural networks
Adam Goodge, Bryan Hooi, See Kiong Ng, and Wee Siong Ng. Lunar: Unifying local outlier detection methods via graph neural networks. 2022
work page 2022
-
[12]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=i_Q1yrOegLY
work page 2021
-
[13]
DROCC : Deep robust one-class classification
Sachin Goyal, Aditi Raghunathan, Moksh Jain, Harsha Vardhan Simhadri, and Prateek Jain. DROCC : Deep robust one-class classification. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3711--3721. PMLR, 13--18 Jul 2020. URL https://p...
work page 2020
-
[14]
ADB ench: Anomaly detection benchmark
Songqiao Han, Xiyang Hu, Hailiang Huang, Minqi Jiang, and Yue Zhao. ADB ench: Anomaly detection benchmark. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https://openreview.net/forum?id=foA_SFQ9zo0
work page 2022
-
[15]
Identification of outliers, volume 11
Douglas M Hawkins. Identification of outliers, volume 11. Springer, 1980
work page 1980
-
[16]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Discovering cluster-based local outliers
Zengyou He, Xiaofei Xu, and Shengchun Deng. Discovering cluster-based local outliers. Pattern Recogn. Lett., 24 0 (9–10): 0 1641–1650, jun 2003. ISSN 0167-8655. doi:10.1016/S0167-8655(03)00003-5. URL https://doi.org/10.1016/S0167-8655(03)00003-5
-
[18]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33: 0 6840--6851, 2020
work page 2020
-
[19]
A survey of outlier detection methodologies
Victoria Hodge and Jim Austin. A survey of outlier detection methodologies. Artificial Intelligence Review, 22: 0 85--126, 10 2004. doi:10.1023/B:AIRE.0000045502.10941.a9
-
[20]
Ki Hyun Kim, Sangwoo Shim, Yongsub Lim, Jongseob Jeon, Jeongwoo Choi, Byungchan Kim, and Andre S. Yoon. Rapp: Novelty detection with reconstruction along projection pathway. In ICLR. OpenReview.net, 2020. URL http://dblp.uni-trier.de/db/conf/iclr/iclr2020.html#KimSLJCKY20
work page 2020
-
[21]
Tabddpm: Modelling tabular data with diffusion models, 2022
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models, 2022. URL https://arxiv.org/abs/2209.15421
-
[22]
Feature bagging for outlier detection
Aleksandar Lazarevic and Vipin Kumar. Feature bagging for outlier detection. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, KDD '05, page 157–166, New York, NY, USA, 2005. Association for Computing Machinery. ISBN 159593135X. doi:10.1145/1081870.1081891. URL https://doi.org/10.1145/1081870.1081891
-
[23]
COPOD : Copula-based outlier detection
Zheng Li, Yue Zhao, Nicola Botta, Cezar Ionescu, and Xiyang Hu. COPOD : Copula-based outlier detection. In 2020 IEEE International Conference on Data Mining ( ICDM ) . IEEE , nov 2020. doi:10.1109/icdm50108.2020.00135. URL https://doi.org/10.1109\
-
[24]
ECOD : Unsupervised outlier detection using empirical cumulative distribution functions
Zheng Li, Yue Zhao, Xiyang Hu, Nicola Botta, Cezar Ionescu, and George Chen. ECOD : Unsupervised outlier detection using empirical cumulative distribution functions. IEEE Transactions on Knowledge and Data Engineering , pages 1--1, 2022. doi:10.1109/tkde.2022.3159580. URL https://doi.org/10.1109\
-
[25]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining, pages 413--422, 2008. doi:10.1109/ICDM.2008.17
-
[26]
Generative adversarial active learning for unsupervised outlier detection, 2019 a
Yezheng Liu, Zhe Li, Chong Zhou, Yuanchun Jiang, Jianshan Sun, Meng Wang, and Xiangnan He. Generative adversarial active learning for unsupervised outlier detection, 2019 a
work page 2019
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019 b . URL http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
J. B. MacQueen. Some methods for classification and analysis of multivariate observations. In L. M. Le Cam and J. Neyman, editors, Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 281--297. University of California Press, 1967
work page 1967
-
[29]
Anomaly detection in medical wireless sensor networks using machine learning algorithms
Girik Pachauri and Sandeep Sharma. Anomaly detection in medical wireless sensor networks using machine learning algorithms. Procedia Computer Science, 70: 0 325--333, 2015. ISSN 1877-0509. doi:https://doi.org/10.1016/j.procs.2015.10.026. URL https://www.sciencedirect.com/science/article/pii/S1877050915031907. Proceedings of the 4th International Conferenc...
-
[30]
Deep learning for anomaly detection
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection. ACM Computing Surveys , 54 0 (2): 0 1--38, mar 2021. doi:10.1145/3439950. URL https://doi.org/10.1145\
-
[31]
Loci: Fast outlier detection using the local correlation integral
Spiros Papadimitriou, Hiroyuki Kitagawa, Phillip Gibbons, and Christos Faloutsos. Loci: Fast outlier detection using the local correlation integral. pages 315--326, 01 2003. doi:10.1109/ICDE.2003.1260802
-
[32]
Emanuel Parzen. On Estimation of a Probability Density Function and Mode . The Annals of Mathematical Statistics, 33 0 (3): 0 1065 -- 1076, 1962. doi:10.1214/aoms/1177704472. URL https://doi.org/10.1214/aoms/1177704472
-
[33]
Loda: Lightweight on-line detector of anomalies
Tom\' a s Pevn\' y . Loda: Lightweight on-line detector of anomalies. Mach. Learn., 102 0 (2): 0 275–304, feb 2016. ISSN 0885-6125. doi:10.1007/s10994-015-5521-0. URL https://doi.org/10.1007/s10994-015-5521-0
-
[34]
Efficient algorithms for mining outliers from large data sets
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. Efficient algorithms for mining outliers from large data sets. SIGMOD Rec., 29 0 (2): 0 427–438, may 2000. ISSN 0163-5808. doi:10.1145/335191.335437. URL https://doi.org/10.1145/335191.335437
-
[35]
Hierarchical text-conditional image generation with clip latents, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents, 2022
work page 2022
-
[36]
Variational inference with normalizing flows
Danilo Jimenez Rezende and Shakir Mohamed. Variational inference with normalizing flows. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML'15, page 1530–1538. JMLR.org, 2015
work page 2015
-
[37]
Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel M \"u ller, and Marius Kloft. Deep one-class classification. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 4393--440...
work page 2018
-
[38]
Lukas Ruff, Jacob R. Kauffmann, Robert A. Vandermeulen, Gregoire Montavon, Wojciech Samek, Marius Kloft, Thomas G. Dietterich, and Klaus-Robert Muller. A unifying review of deep and shallow anomaly detection. Proceedings of the IEEE , 109 0 (5): 0 756--795, may 2021. doi:10.1109/jproc.2021.3052449. URL https://doi.org/10.1109\
-
[39]
Anomaly detection using autoencoders with nonlinear dimensionality reduction
Mayu Sakurada and Takehisa Yairi. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, MLSDA'14, page 4–11, New York, NY, USA, 2014. Association for Computing Machinery. ISBN 9781450331593. doi:10.1145/2689746.2689747. URL https://doi.org/...
-
[40]
Sensor fault and patient anomaly detection and classification in medical wireless sensor networks
Osman Salem, Alexey Guerassimov, Ahmed Mehaoua, Anthony Marcus, and Borko Furht. Sensor fault and patient anomaly detection and classification in medical wireless sensor networks. In 2013 IEEE International Conference on Communications (ICC), pages 4373--4378, 2013. doi:10.1109/ICC.2013.6655254
-
[41]
Support vector method for novelty detection
Bernhard Schölkopf, Robert Williamson, Alex Smola, John Shawe-Taylor, and John Platt. Support vector method for novelty detection. volume 12, pages 582--588, 01 1999
work page 1999
-
[42]
Anomaly detection for tabular data with internal contrastive learning
Tom Shenkar and Lior Wolf. Anomaly detection for tabular data with internal contrastive learning. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=_hszZbt46bT
work page 2022
-
[43]
A novel anomaly detection scheme based on principal component classifier
Mei-Ling Shyu, Shu-Ching Chen, Kanoksri Sarinnapakorn, and Liwu Chang. A novel anomaly detection scheme based on principal component classifier. 01 2003
work page 2003
-
[44]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256--2265. PMLR, 2015
work page 2015
-
[45]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[46]
Anomaly detection approaches for semiconductor manufacturing
Gian Antonio Susto, Matteo Terzi, and Alessandro Beghi. Anomaly detection approaches for semiconductor manufacturing. Procedia Manufacturing, 11: 0 2018--2024, 2017
work page 2018
-
[47]
Enhancing effectiveness of outlier detections for low density patterns
Jian Tang, Zhixiang Chen, Ada Wai-Chee Fu, and David Wai-Lok Cheung. Enhancing effectiveness of outlier detections for low density patterns. In Proceedings of the 6th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, PAKDD '02, page 535–548, Berlin, Heidelberg, 2002. Springer-Verlag. ISBN 3540437045
work page 2002
-
[48]
Diffusion models for medical anomaly detection
Julia Wolleb, Florentin Bieder, Robin Sandk \"u hler, and Philippe C Cattin. Diffusion models for medical anomaly detection. In Medical Image Computing and Computer Assisted Intervention--MICCAI 2022: 25th International Conference, Singapore, September 18--22, 2022, Proceedings, Part VIII, pages 35--45. Springer, 2022
work page 2022
-
[49]
Julian Wyatt, Adam Leach, Sebastian M. Schmon, and Chris G. Willcocks. Anoddpm: Anomaly detection with denoising diffusion probabilistic models using simplex noise. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 649--655, 2022. doi:10.1109/CVPRW56347.2022.00080
-
[50]
Learning discriminative reconstructions for unsupervised outlier removal
Yan Xia, Xudong Cao, Fang Wen, Gang Hua, and Jian Sun. Learning discriminative reconstructions for unsupervised outlier removal. 2015 IEEE International Conference on Computer Vision (ICCV), pages 1511--1519, 2015
work page 2015
-
[51]
T. Yairi, Y. Kawahara, R. Fujimaki, Y. Sato, and K. Machida. Telemetry-mining: a machine learning approach to anomaly detection and fault diagnosis for space systems. In 2nd IEEE International Conference on Space Mission Challenges for Information Technology (SMC-IT'06), pages 8 pp.--476, 2006. doi:10.1109/SMC-IT.2006.79
-
[52]
Diffusionad: Denoising diffusion for anomaly detection, 2023
Hui Zhang, Zheng Wang, Zuxuan Wu, and Yu-Gang Jiang. Diffusionad: Denoising diffusion for anomaly detection, 2023
work page 2023
-
[53]
Chong Zhou and Randy C. Paffenroth. Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '17, page 665–674, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450348874. doi:10.1145/3097983.3098052. URL https://doi.org/10.1145/3097983.3098052
-
[54]
Deep autoencoding gaussian mixture model for unsupervised anomaly detection
Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Dae ki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International Conference on Learning Representations, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.