Interpolation of mountain weather forecasts by machine learning
Pith reviewed 2026-05-24 07:51 UTC · model grok-4.3
The pith
LightGBM interpolates future mountain temperature and precipitation from surrounding plain forecasts plus past observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
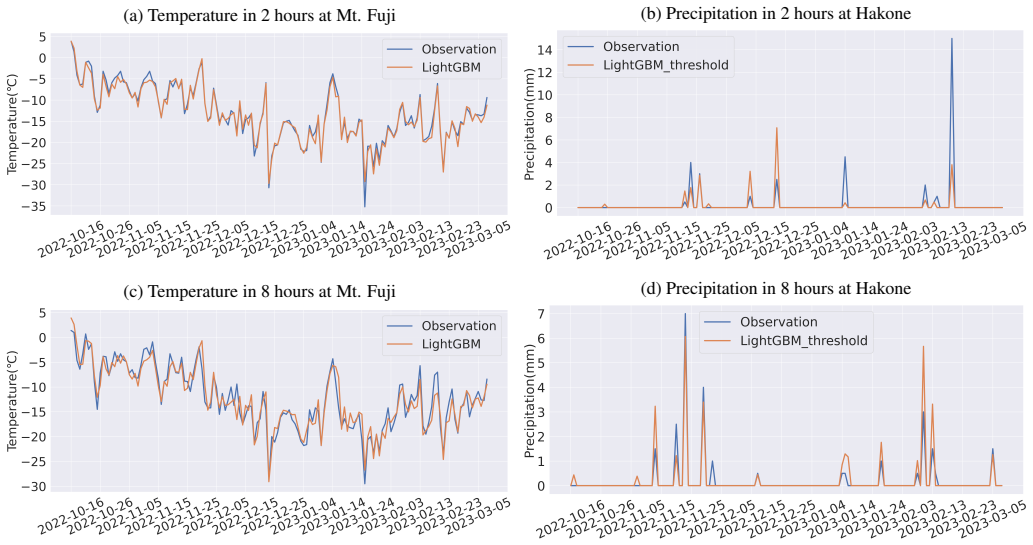
The authors establish that forecast data from surrounding plains combined with past observed data contain sufficient information for a LightGBM model to produce accurate future interpolations at mountain sites, partially improving RMSE with significantly less training time.
What carries the argument
LightGBM gradient-boosted decision tree model trained on engineered features drawn from plain-area forecasts and lagged mountain observations.
If this is right
- Temperature at mountain sites can be corrected without rerunning a full physics model at finer grid spacing.
- Some precipitation amounts at elevation are captured more accurately than the input plain forecasts alone.
- The method remains effective even when only a small training dataset is available.
- Training finishes in minutes rather than the hours required by neural-network alternatives.
Where Pith is reading between the lines
- The same feature set could be tested on mountain ranges outside Japan if the surrounding plains reliably encode the incoming weather systems.
- Extending the inputs to include additional variables such as humidity or wind speed might enlarge the set of forecast quantities that improve.
- Operational systems could run the model on demand to supply site-specific corrections for ski areas or avalanche services.
Load-bearing premise
Forecast data from surrounding plains together with past observed data contain sufficient information for a LightGBM model to produce accurate future interpolations at mountain sites.
What would settle it
Applying the trained model to held-out mountain sites and finding that its RMSE for temperature or precipitation exceeds the RMSE obtained by simply using the unmodified plain forecasts.
Figures


read the original abstract
Recent advances in numerical simulation methods based on physical models and their combination with machine learning have improved the accuracy of weather forecasts. However, the accuracy decreases in complex terrains such as mountainous regions because these methods usually use grids of several kilometers square and simple machine learning models. While deep learning has also made significant progress in recent years, its direct application is difficult to utilize the physical knowledge used in the simulation. This paper proposes a method that uses machine learning to interpolate future weather in mountainous regions using forecast data from surrounding plains and past observed data to improve weather forecasts in mountainous regions. We focus on mountainous regions in Japan and predict temperature and precipitation mainly using LightGBM as a machine learning model. Despite the use of a small dataset, through feature engineering and model tuning, our method partially achieves improvements in the RMSE with significantly less training time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a LightGBM-based method to interpolate future temperature and precipitation forecasts for Japanese mountain sites, using numerical forecast fields from surrounding plains together with historical local observations. Through feature engineering and hyperparameter tuning on a small dataset, the authors claim partial RMSE reductions relative to unspecified baselines while requiring far less training time than deep-learning alternatives.
Significance. If the reported RMSE gains prove robust under proper controls, the work would demonstrate a computationally lightweight route to orographic downscaling that exploits existing coarse forecasts and sparse observations without retraining full physics-based models or large neural networks.
major comments (3)
- [Abstract] Abstract: the central claim that the method 'partially achieves improvements in the RMSE' supplies neither the identity of the baseline forecast, the cross-validation scheme, nor any statistical test or uncertainty estimate, so the improvement cannot be evaluated.
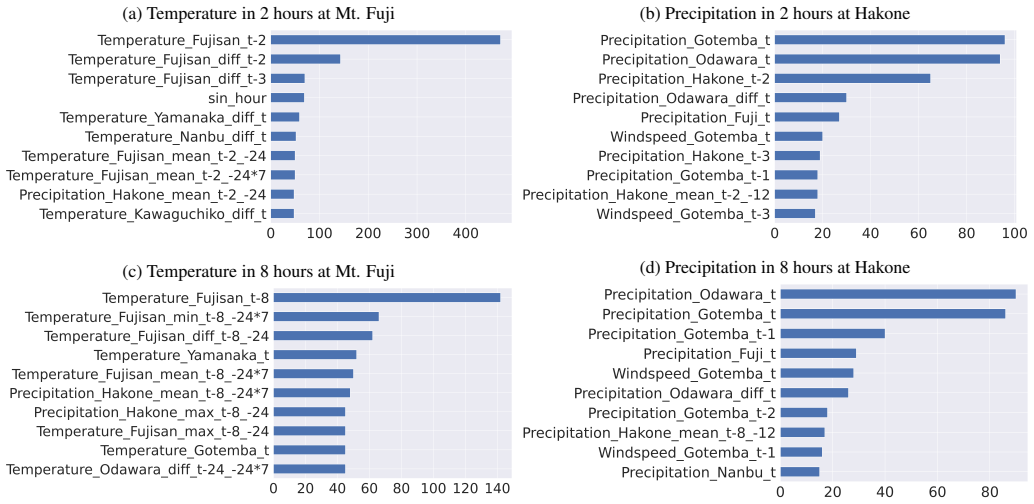
- [Methods and Results] Methods/Results: no ablation of plain-forecast versus local-observation features, no feature-importance ranking, and no stratification of errors by topographic complexity are presented; without these the sufficiency of plains data for capturing orographic effects remains untested.
- [Results] Results: given the explicit mention of a 'small dataset' and 'heavy feature engineering,' the absence of any hold-out or temporal cross-validation details leaves open the possibility that reported gains are site-specific fits rather than generalizable interpolation skill.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction should explicitly state the spatial resolution of the input forecasts and the exact mountain stations used.
- [Methods] Notation for the engineered features (e.g., what 'past observed data' variables are included) is not defined before the results are discussed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional clarity and analysis will strengthen the manuscript. We address each major comment below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'partially achieves improvements in the RMSE' supplies neither the identity of the baseline forecast, the cross-validation scheme, nor any statistical test or uncertainty estimate, so the improvement cannot be evaluated.
Authors: We agree that these details are necessary for proper evaluation. The baseline is the raw numerical forecast interpolated from surrounding plain sites without machine learning. We used temporal cross-validation with multiple time-based folds to prevent leakage. We will revise the abstract to name the baseline, briefly describe the cross-validation, and report RMSE improvements with uncertainty estimates from repeated runs. revision: yes
-
Referee: [Methods and Results] Methods/Results: no ablation of plain-forecast versus local-observation features, no feature-importance ranking, and no stratification of errors by topographic complexity are presented; without these the sufficiency of plains data for capturing orographic effects remains untested.
Authors: This observation is correct and points to a useful addition. We will include an ablation study contrasting models trained on plain-forecast features alone versus those augmented with local observations. We will also add LightGBM feature-importance rankings and stratify RMSE results by topographic complexity (e.g., local elevation variance) to test whether plains data suffice for orographic effects. revision: yes
-
Referee: [Results] Results: given the explicit mention of a 'small dataset' and 'heavy feature engineering,' the absence of any hold-out or temporal cross-validation details leaves open the possibility that reported gains are site-specific fits rather than generalizable interpolation skill.
Authors: We will expand the results section to fully document the temporal cross-validation procedure, including the exact train/test period splits chosen to mimic operational forecasting. This temporal hold-out design was intended to assess generalization beyond site-specific fitting; we will make the protocol explicit and, where feasible, add performance on fully held-out sites. revision: yes
Circularity Check
No circularity; standard supervised regression on external data
full rationale
The paper presents an empirical machine learning pipeline: LightGBM is trained on forecast outputs from surrounding plains plus historical observations to regress temperature and precipitation at mountain sites. No equations, ansatzes, or uniqueness theorems are invoked. No parameter is fitted on a subset and then relabeled as a prediction of a related quantity. No self-citations are used to justify core premises. The workflow is a conventional supervised regression whose inputs and targets are drawn from independent observational and numerical-model sources; reported RMSE changes are therefore falsifiable against held-out data and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ishida, J. et al.: Outline of the operational numer- ical weather prediction at the Japan meteological angency March 2023, Japan Meteorological Agency (online), https://www.jma.go.jp/jma/jma-eng/ jma-center/nwp/outline-latest-nwp/index.htm (accessed 2023-12-11)
work page 2023
-
[2]
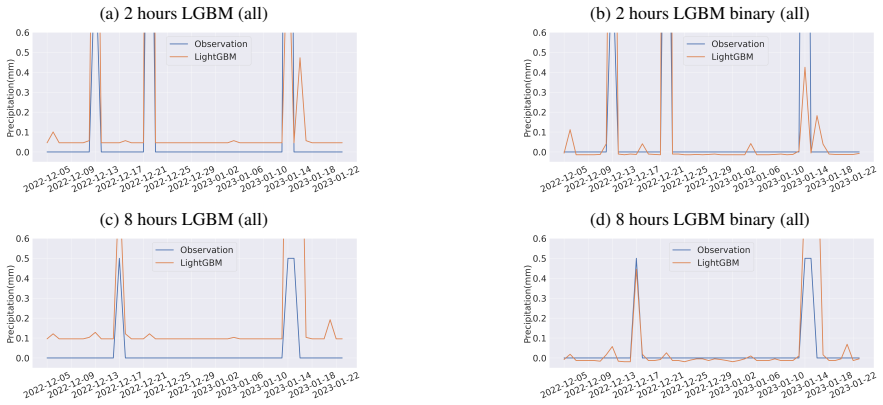
Goger, B., Rotach, M. W., Gohm, A., Stiperski, I. and Fuhrer, O.: Current challenges for numerical weather pre- 7 (a) 2 hours LGBM (all) (b) 2 hours LGBM binary (all) (c) 8 hours LGBM (all) (d) 8 hours LGBM binary (all) Figure 5: Precipitation predictions in 2 hours and in 8 hours at Hakone. Threshold procedure is not applied. A bias of size about (a) 0.0...
work page 2016
-
[3]
Golzio, A., Ferrarese, S., Cassardo, C., Diolaiuti, G. A. and Pelfini, M.: Land-use improvements in the weather re- search and forecasting model over complex mountainous terrain and comparison of di fferent grid sizes, Boundary- Layer Meteorology, V ol. 180, No. 2, pp. 319–351 (2021)
work page 2021
-
[4]
Mehrkanoon, S.: Deep shared representation learning for weather elements forecasting, Knowledge-Based Systems, V ol. 179, pp. 120–128 (2019)
work page 2019
-
[5]
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y ., Wong, W.-K. and Woo, W.-c.: Convolutional LSTM network: A ma- chine learning approach for precipitation nowcasting, Ad- vances in neural information processing systems , V ol. 28 (2015)
work page 2015
-
[6]
Zaytar, M. A. and El Amrani, C.: Sequence to sequence weather forecasting with long short-term memory recur- rent neural networks, International Journal of Computer Applications, V ol. 143, No. 11, pp. 7–11 (2016)
work page 2016
-
[7]
Bilgin, O., M˛ aka, P., Vergutz, T. and Mehrkanoon, S.: TENT: Tensorized encoder transformer for temperature forecasting, arXiv preprint arXiv:2106.14742 (2021)
-
[8]
Jahnavi, Y .: Analysis of weather data using various regres- sion algorithms, International Journal of Data Science , V ol. 4, No. 2, pp. 117–141 (2019)
work page 2019
-
[9]
Chen, L. and Lai, X.: Comparison between ARIMA and ANN models used in short-term wind speed forecasting, 2011 Asia-Pacific power and energy engineering confer- ence, IEEE, pp. 1–4 (2011)
work page 2011
-
[10]
Kuligowski, R. J. and Barros, A. P.: Localized precipita- tion forecasts from a numerical weather prediction model using artificial neural networks, Weather and forecasting, V ol. 13, No. 4, pp. 1194–1204 (1998)
work page 1998
-
[11]
Yoshikane, T. and Yoshimura, K.: A bias correction method for precipitation through recognizing mesoscale precipitation systems corresponding to weather conditions, PLoS Water, V ol. 1, No. 5, p. e0000016 (2022)
work page 2022
-
[12]
Larraondo, P. R., Renzullo, L. J., Van Dijk, A. I., Inza, I. and Lozano, J. A.: Optimization of deep learning precipi- tation models using categorical binary metrics, Journal of Advances in Modeling Earth Systems , V ol. 12, No. 5, p. e2019MS001909 (2020)
work page 2020
-
[13]
Zou, H. and Hastie, T.: Regularization and variable selec- tion via the elastic net, Journal of the Royal Statistical So- ciety Series B: Statistical Methodology, V ol. 67, No. 2, pp. 301–320 (2005)
work page 2005
-
[14]
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q. and Liu, T.-Y .: Lightgbm: A highly efficient gradi- ent boosting decision tree, Advances in neural information processing systems, V ol. 30 (2017)
work page 2017
-
[15]
Chen, T. and Guestrin, C.: Xgboost: A scalable tree boost- ing system, Proceedings of the 22nd acm sigkdd interna- tional conference on knowledge discovery and data mining, pp. 785–794 (2016)
work page 2016
-
[16]
and Wehenkel, L.: Extremely random- ized trees, Machine learning, V ol
Geurts, P., Ernst, D. and Wehenkel, L.: Extremely random- ized trees, Machine learning, V ol. 63, pp. 3–42 (2006)
work page 2006
-
[17]
and Armon, A.: Tabular data: Deep learn- ing is not all you need, Information Fusion, V ol
Shwartz-Ziv, R. and Armon, A.: Tabular data: Deep learn- ing is not all you need, Information Fusion, V ol. 81, pp. 84–90 (2022)
work page 2022
-
[18]
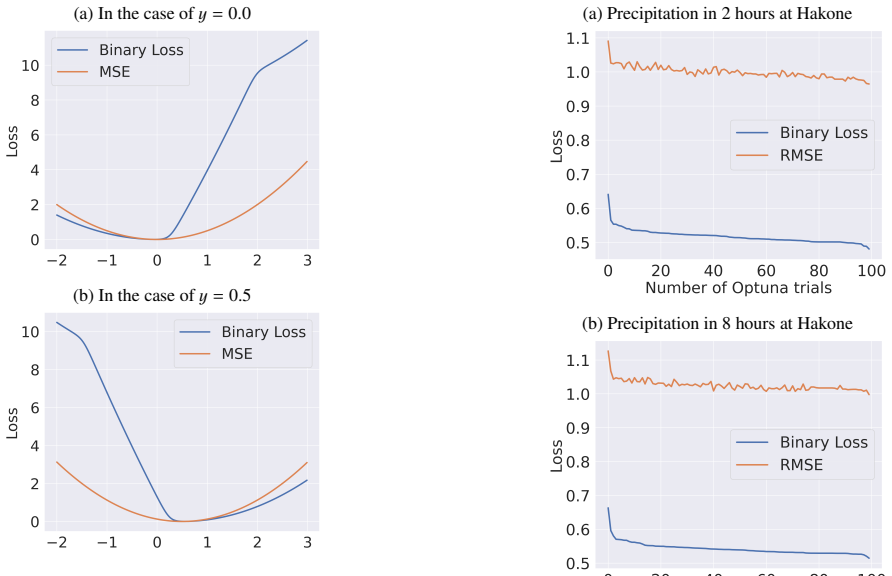
Akiba, T., Sano, S., Yanase, T., Ohta, T. and Koyama, M.: Optuna: A next-generation hyperparameter optimization framework, Proceedings of the 25th ACM SIGKDD inter- national conference on knowledge discovery & data min- ing, pp. 2623–2631 (2019). 8 (a) In the case of y = 0.0 (b) In the case of y = 0.5 Figure 6: MSE and Lbinary (Binary Loss) for y = 0.0 an...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.