High Probability Guarantees for Random Reshuffling
Pith reviewed 2026-05-24 05:15 UTC · model grok-4.3
The pith
Random reshuffling attains high-probability ergodic complexity for epsilon-stationary points matching best in-expectation bounds up to a log factor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard assumptions, random reshuffling admits a high-probability bound on the ergodic sample complexity for reaching an epsilon-stationary point that matches the best in-expectation bound up to a logarithmic factor, and a computable stopping test extends this guarantee to the last iterate without changing the algorithm.
What carries the argument
A newly established concentration property for the random reshuffling process that provides tail bounds on the deviation of reshuffled stochastic gradients from their mean over epochs.
Load-bearing premise
The derived concentration property for random reshuffling holds true under the smoothness and bounded variance conditions used in the analysis.
What would settle it
A counter-example function that is smooth and has bounded gradient variance but where random reshuffling fails to satisfy the claimed high-probability ergodic bound with the stated probability.
Figures




read the original abstract
We consider the stochastic gradient method with random reshuffling ($\mathsf{RR}$) for tackling smooth nonconvex optimization problems. $\mathsf{RR}$ finds broad applications in practice, notably in training neural networks. In this work, we provide high probability complexity guarantees for this method. First, we establish a high probability ergodic sample complexity result (without taking expectation) for finding an $\varepsilon$-stationary point. Our derived complexity matches the best existing in-expectation one up to a logarithmic term while imposing no additional assumptions nor modifying $\mathsf{RR}$'s updating rule. Second, building on this analysis, we propose a simple stopping criterion embedded with a computable stopping test for $\mathsf{RR}$ (denoted as $\mathsf{RR}$-$\mathsf{sc}$). This criterion is guaranteed to be triggered after a finite number of iterations, enabling us to prove the same order high probability complexity for the returned last iterate. The fundamental ingredient in deriving the aforementioned results is a new concentration property for random reshuffling, which could be of independent interest. Finally, we conduct numerical experiments on small neural network training to support our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims high-probability ergodic sample complexity bounds for random reshuffling (RR) on smooth nonconvex problems that match the best known in-expectation rates up to a logarithmic factor, without extra assumptions or changes to the RR update. It further introduces a computable stopping criterion (RR-sc) that triggers after finitely many steps and yields the same-order high-probability guarantee for the returned last iterate. Both results rest on a new concentration inequality for the without-replacement sampling structure of RR, presented as the fundamental technical ingredient and potentially of independent interest. Numerical experiments on small neural-network training are included to support the theory.
Significance. If the new concentration property holds under the stated L-smoothness and bounded-variance assumptions, the work would be significant: it supplies the first high-probability (non-expectation) guarantees for unmodified RR that are essentially as strong as the best in-expectation results, which matters for the practical use of RR in neural-network training. The concentration inequality itself could be reusable in other analyses of shuffling-based methods.
major comments (2)
- [Section deriving the concentration property (likely §3 or §4)] The high-probability ergodic bound and the RR-sc guarantee both collapse if the new concentration property (the 'fundamental ingredient') fails to deliver the claimed tail decay under only L-smoothness and bounded variance. The derivation must be checked for the handling of epoch-wise dependence induced by without-replacement sampling; any gap here is load-bearing for the central claims.
- [Main ergodic complexity theorem] Theorem stating the ergodic high-probability complexity: confirm that the logarithmic overhead is the only difference from the best in-expectation rate and that no hidden constants or additional assumptions (e.g., on gradient norms) are introduced in the passage from expectation to high probability.
minor comments (2)
- [Definition of RR-sc] Notation for the stopping test in RR-sc should be clarified so that the computability of the test is immediate from the displayed expressions.
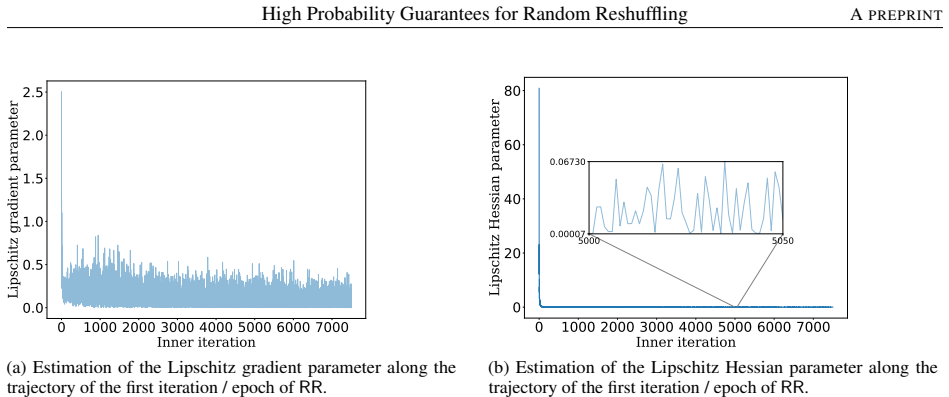
- [Experiments] The numerical experiments section would benefit from reporting the observed iteration counts against the theoretical bounds for the tested networks.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We are pleased that the significance of the work is recognized. We address each major comment below.
read point-by-point responses
-
Referee: [Section deriving the concentration property (likely §3 or §4)] The high-probability ergodic bound and the RR-sc guarantee both collapse if the new concentration property (the 'fundamental ingredient') fails to deliver the claimed tail decay under only L-smoothness and bounded variance. The derivation must be checked for the handling of epoch-wise dependence induced by without-replacement sampling; any gap here is load-bearing for the central claims.
Authors: We confirm that the derivation in the relevant section properly handles the epoch-wise dependence through a carefully constructed martingale argument that respects the without-replacement sampling within each epoch. The concentration inequality is derived under precisely the stated assumptions of L-smoothness and bounded variance, delivering the claimed tail decay. This ensures the high-probability bounds hold as stated. We are happy to elaborate on specific steps if the referee identifies a particular concern. revision: no
-
Referee: [Main ergodic complexity theorem] Theorem stating the ergodic high-probability complexity: confirm that the logarithmic overhead is the only difference from the best in-expectation rate and that no hidden constants or additional assumptions (e.g., on gradient norms) are introduced in the passage from expectation to high probability.
Authors: The main ergodic complexity theorem establishes a high-probability bound that differs from the best known in-expectation rate solely by a logarithmic factor in 1/δ (where δ is the failure probability). The transition from expectation to high probability relies exclusively on the new concentration inequality and does not introduce any hidden constants or additional assumptions, such as bounds on gradient norms beyond the problem's standard assumptions. This is explicitly verified in the proof. revision: no
Circularity Check
No circularity; new concentration property derived independently under standard assumptions
full rationale
The paper's high-probability ergodic bound and RR-sc stopping criterion are derived from a newly stated concentration inequality for random reshuffling, presented explicitly as an independent technical contribution under L-smoothness and bounded variance. No equations reduce a claimed prediction or result to a fitted parameter or self-citation by construction; the complexity statements are obtained by applying the new inequality to the RR iterates without renaming or smuggling prior ansatzes. The derivation chain remains self-contained against external benchmarks, with the concentration property serving as a verifiable primitive rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Incremental proximal methods for large scale convex optimization
Dimitri P Bertsekas. Incremental proximal methods for large scale convex optimization. Mathematical Program- ming, 129(2):163–195, 2011
work page 2011
-
[2]
Curiously fast convergence of some stochastic gradient descent algorithms
Léon Bottou. Curiously fast convergence of some stochastic gradient descent algorithms. In Proceedings of the symposium on learning and data science, volume 8, pages 2624–2633, 2009
work page 2009
-
[3]
Stochastic gradient descent tricks
Léon Bottou. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade, pages 421–436. Springer, 2012
work page 2012
-
[4]
Optimization methods for large-scale machine learning
Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. SIAM Review, 60(2):223–311, 2018
work page 2018
-
[5]
Tighter lower bounds for shuffling sgd: Random permutations and beyond
Jaeyoung Cha, Jaewook Lee, and Chulhee Yun. Tighter lower bounds for shuffling sgd: Random permutations and beyond. International Conference on Machine Learning, 2023
work page 2023
-
[6]
Nonconvex optimization meets low-rank matrix factorization: An overview
Yuejie Chi, Yue M Lu, and Yuxin Chen. Nonconvex optimization meets low-rank matrix factorization: An overview. IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019
work page 2019
-
[7]
High-probability bounds for non-convex stochastic optimization with heavy tails
Ashok Cutkosky and Harsh Mehta. High-probability bounds for non-convex stochastic optimization with heavy tails. Adv. in Neural Information Processing Systems, 34:4883–4895, 2021
work page 2021
-
[8]
Escaping from saddle points—online stochastic gradient for tensor decomposition
Rong Ge, Furong Huang, Chi Jin, and Yang Yuan. Escaping from saddle points—online stochastic gradient for tensor decomposition. In Conference on Learning Theory, pages 797–842, 2015
work page 2015
-
[9]
Stochastic first- and zeroth-order methods for nonconvex stochastic program- ming
Saeed Ghadimi and Guanghui Lan. Stochastic first- and zeroth-order methods for nonconvex stochastic program- ming. SIAM Journal on Optimization, 2013
work page 2013
-
[10]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
work page 2010
-
[11]
Stochastic optimization with heavy-tailed noise via accelerated gradient clipping
Eduard Gorbunov, Marina Danilova, and Alexander Gasnikov. Stochastic optimization with heavy-tailed noise via accelerated gradient clipping. Adv. in Neural Info. Processing Systems, 2020
work page 2020
-
[12]
Note on sampling without replacing from a finite collection of matrices
David Gross and Vincent Nesme. Note on sampling without replacing from a finite collection of matrices. arXiv preprint arXiv:1001.2738, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Convergence rate of incremental gradient and incremental Newton methods
M Gürbüzbalaban, A Ozdaglar, and Pablo A Parrilo. Convergence rate of incremental gradient and incremental Newton methods. SIAM Journal on Optimization, 29(4):2542–2565, 2019
work page 2019
-
[14]
Why random reshuffling beats stochastic gradient descent
Mert Gürbüzbalaban, Asu Ozdaglar, and PA Parrilo. Why random reshuffling beats stochastic gradient descent. Mathematical Programming, 186(1-2):49–84, 2021
work page 2021
-
[15]
Random shuffling beats SGD after finite epochs
Jeff Haochen and Suvrit Sra. Random shuffling beats SGD after finite epochs. In International Conference on Machine Learning, pages 2624–2633, 2019
work page 2019
-
[16]
Nicholas J. A. Harvey, Christopher Liaw, Y . Plan, and Sikander Randhawa. Tight analyses for non-smooth stochastic gradient descent. Annual Conference Computational Learning Theory, 2018
work page 2018
-
[17]
Probability inequalities for sums of bounded random variables
Wassily Hoeffding. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58(301):13–30, 1963
work page 1963
-
[18]
An improved analysis and rates for variance reduction under without-replacement sampling orders
Xinmeng Huang, Kun Yuan, Xianghui Mao, and Wotao Yin. An improved analysis and rates for variance reduction under without-replacement sampling orders. Advances in Neural Information Processing Systems, 34, 2021
work page 2021
-
[19]
How to escape saddle points efficiently
Chi Jin, Rong Ge, Praneeth Netrapalli, Sham M Kakade, and Michael I Jordan. How to escape saddle points efficiently. In International conference on machine learning, pages 1724–1732, 2017
work page 2017
-
[20]
On nonconvex optimization for machine learning: Gradients, stochasticity, and saddle points
Chi Jin, Praneeth Netrapalli, Rong Ge, Sham M Kakade, and Michael I Jordan. On nonconvex optimization for machine learning: Gradients, stochasticity, and saddle points. Journal of the ACM, 68(2):1–29, 2021
work page 2021
-
[21]
Better theory for sgd in the nonconvex world
Ahmed Khaled and Peter Richtárik. Better theory for sgd in the nonconvex world. Transactions on Machine Learning Research, 2022
work page 2022
-
[22]
Using statistics to automate stochastic optimization
Hunter Lang, Lin Xiao, and Pengchuan Zhang. Using statistics to automate stochastic optimization. In Advances in Neural Information Processing Systems, 2019
work page 2019
-
[23]
Gradient-based learning applied to document recognition
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998
work page 1998
-
[24]
A unified convergence theorem for stochastic optimization methods
Xiao Li and Andre Milzarek. A unified convergence theorem for stochastic optimization methods. In Advances in Neural Information Processing Systems, volume 35, pages 33107–33119, 2022. 23 High Probability Guarantees for Random Reshuffling A PREPRINT
work page 2022
-
[25]
Convergence of random reshuffling under the kurdyka-łojasiewicz inequality
Xiao Li, Andre Milzarek, and Junwen Qiu. Convergence of random reshuffling under the kurdyka-łojasiewicz inequality. SIAM Journal on Optimization, 33(2):1092–1120, 2023
work page 2023
-
[26]
GraB: Finding provably better data permutations than random reshuffling
Yucheng Lu, Wentao Guo, and Christopher De Sa. GraB: Finding provably better data permutations than random reshuffling. Neural Information Processing Systems, 2022
work page 2022
-
[27]
Random reshuffling with variance reduction: New analysis and better rates
Grigory Malinovsky, Alibek Sailanbayev, and Peter Richtárik. Random reshuffling with variance reduction: New analysis and better rates. Conference on Uncertainty in Arti. Intell., 2021
work page 2021
-
[28]
Random reshuffling: Simple analysis with vast improvements
Konstantin Mishchenko, Ahmed Khaled, and Peter Richtárik. Random reshuffling: Simple analysis with vast improvements. Advances in Neural Information Processing Systems, 2020
work page 2020
-
[29]
Surpassing gradient descent provably: A cyclic incremental method with linear convergence rate
Aryan Mokhtari, Mert Gürbüzbalaban, and Alejandro Ribeiro. Surpassing gradient descent provably: A cyclic incremental method with linear convergence rate. SIAM Journal on Optimization, 28(2):1420–1447, 2018
work page 2018
-
[30]
Incremental subgradient methods for nondifferentiable optimization
Angelia Nedi´c and Dimitri P Bertsekas. Incremental subgradient methods for nondifferentiable optimization. SIAM Journal on Optimization, 12(1):109–138, 2001
work page 2001
-
[31]
Introductory lectures on convex optimization: A basic course, volume 87
Yurii Nesterov. Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, 2003
work page 2003
-
[32]
A unified convergence analysis for shuffling-type gradient methods
Lam M Nguyen, Quoc Tran-Dinh, Dzung T Phan, Phuong Ha Nguyen, and Marten Van Dijk. A unified convergence analysis for shuffling-type gradient methods. The Journal of Machine Learning Research, 22(1):9397–9440, 2021
work page 2021
-
[33]
Vivak Patel. Stopping criteria for, and strong convergence of, stochastic gradient descent on Bottou-Curtis-Nocedal functions. Mathematical Programming, 195(1-2):693–734, 2022
work page 2022
-
[34]
Closing the convergence gap of SGD without replacement
Shashank Rajput, Anant Gupta, and Dimitris Papailiopoulos. Closing the convergence gap of SGD without replacement. International Conference On Machine Learning, 2020
work page 2020
-
[35]
Parallel stochastic gradient algorithms for large-scale matrix completion
Benjamin Recht and Christopher Ré. Parallel stochastic gradient algorithms for large-scale matrix completion. Mathematical Programming Computation, 5(2):201–226, 2013
work page 2013
-
[36]
A stochastic approximation method
Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400–407, 1951
work page 1951
-
[37]
Itay Safran and Ohad Shamir. How good is SGD with random shuffling? In Conference on Learning Theory, volume 125, pages 3250–3284, 2020
work page 2020
-
[38]
Optimization for deep learning: An overview
Ruo-Yu Sun. Optimization for deep learning: An overview. Journal of the Operations Research Society of China, 8(2):249–294, 2020
work page 2020
-
[39]
Joel A. Tropp. An introduction to matrix concentration inequalities. Foundations and Trends® in Machine Learning, 8(1-2):1–230, 2015
work page 2015
-
[40]
A stopping rule for the Robbins-Monro method
George Yin. A stopping rule for the Robbins-Monro method. Journal of Optimization Theory and Applications, 67(1):151–173, 1990
work page 1990
-
[41]
Minibatch vs local SGD with shuffling: Tight convergence bounds and beyond
Chulhee Yun, Shashank Rajput, and Suvrit Sra. Minibatch vs local SGD with shuffling: Tight convergence bounds and beyond. In International Conference on Learning Representations, 2022
work page 2022
-
[42]
Why are adaptive methods good for attention models? Adv
Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models? Adv. in Neu. Info. Process. Systems, 2020. 24
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.