CAMERA: Adapting to Semantic Camouflage in Unsupervised Text-Attributed Graph Fraud Detection
Pith reviewed 2026-05-20 06:50 UTC · model grok-4.3
The pith
A mixture-of-experts model with adaptive gating and one-class objectives detects fraudsters who camouflage text in unsupervised graph settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
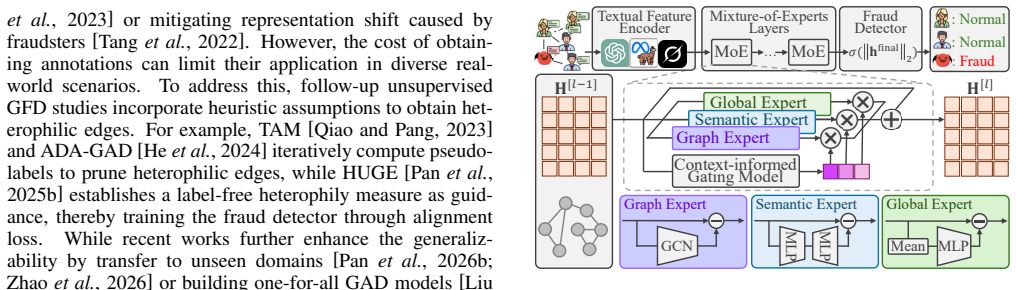
CAMERA employs an ego-decoupled mixture-of-experts architecture where each expert specializes in modeling a distinct type of fraud-indicative cue, introduces a context-informed gating model to jointly consider the ego node representation and its local neighborhood context for adaptive integration of cues, and leverages the inherent rarity of fraudsters to support unsupervised one-class learning with expert-level objectives that encourage modeling dominant benign patterns, thereby enabling reliable unsupervised detection of camouflaged fraudsters.
What carries the argument
The ego-decoupled mixture-of-experts architecture with context-informed gating and expert-level one-class objectives, which lets separate experts handle distinct cues while the gate adapts their combination to local context and the one-class step isolates rare deviations.
If this is right
- It allows unsupervised TAGFD to remain effective even when camouflage undermines usual structural and attribute signals.
- Expert specialization and adaptive gating together support cue integration without any labeled fraud examples.
- One-class objectives at the expert level turn the scarcity of fraud into a stable modeling target for benign behavior.
- Performance gains appear consistently across four challenging datasets against prior unsupervised methods.
Where Pith is reading between the lines
- Similar expert specialization and context gating could apply to other anomaly tasks where adversaries evolve to mimic normal behavior, such as spam or bot detection.
- The approach suggests testing whether adding more cue types or dynamic expert addition improves handling of new camouflage tactics over time.
- If the rarity assumption weakens, hybrid semi-supervised extensions that incorporate a small number of confirmed cases might maintain separation.
- This framing highlights a broader pattern in graph learning where modeling what is normal can be more robust than chasing shifting anomalies directly.
Load-bearing premise
Fraudsters remain rare enough that their presence does not disrupt the ability of one-class objectives to reliably capture the dominant benign patterns across experts.
What would settle it
A dataset in which fraudsters become common enough to alter overall patterns or achieve perfect semantic mimicry of benign text would cause detection performance to fall to levels indistinguishable from random guessing.
Figures







read the original abstract
Text-attributed graph fraud detection (TAGFD) plays a critical role in preventing fraudulent activities on online social and e-commerce platforms. However, to evade detection, fraudsters continuously evolve their camouflaging strategies by deliberately mimicking textual responses of benign users, thereby concealing their malicious purposes. This phenomenon, referred to as semantic camouflage, fundamentally undermines commonly relied assumptions on how structural and attribute cues can be exploited to identify fraudsters, and makes it difficult to spot fraudsters with unsupervised TAGFD. To bridge the gaps, we propose a Case-Adaptive Multi-cue Expert fRAmework (CAMERA) for unsupervised TAGFD. CAMERA employs an ego-decoupled mixture-of-experts architecture, where each expert specializes in modeling a distinct type of fraud-indicative cue. A context-informed gating model is introduced to jointly consider the ego node representation and its local neighborhood context for adaptive integration of cues learned by different experts. Furthermore, CAMERA leverages the inherent rarity of fraudsters to support unsupervised one-class learning with expert-level objectives that encourage modeling dominant benign patterns, thereby enabling reliable unsupervised detection of camouflaged fraudsters. Experiments on 4 challenging datasets show that CAMERA consistently outperforms competitors, showing its effectiveness against semantically camouflaged fraudsters. Code available at https://github.com/CampanulaBells/CAMERA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAMERA, a Case-Adaptive Multi-cue Expert fRAmework for unsupervised text-attributed graph fraud detection (TAGFD) to address semantic camouflage where fraudsters mimic benign textual responses. It features an ego-decoupled mixture-of-experts architecture with each expert specializing in distinct fraud-indicative cues, a context-informed gating model that considers ego node and neighborhood context, and expert-level one-class objectives that leverage the inherent rarity of fraudsters to model dominant benign patterns. Experiments on 4 challenging datasets report that CAMERA consistently outperforms competitors.
Significance. If the results hold, this work is significant for tackling an important and evolving challenge in fraud detection on social and e-commerce platforms. The mixture-of-experts design with adaptive cue integration and unsupervised one-class learning offers a novel direction for handling semantic camouflage. The public release of code supports reproducibility and is a clear strength.
major comments (2)
- [§3.3] §3.3, expert-level one-class objectives: The central unsupervised separation claim depends on the assumption that fraudster rarity allows each expert to reliably model only dominant benign patterns. No analysis is provided on the case where semantic camouflage aligns fraudster text attributes with benign distributions (potentially across multiple cues), which could cause the mixture to model a blended distribution rather than isolating the rare class.
- [§4] §4, experimental results: The claim of consistent outperformance on 4 datasets is load-bearing for the paper's contribution, yet the manuscript lacks details on exact metrics (e.g., AUC or F1), baseline configurations, statistical significance testing, and ablation studies on the number of experts or gating network weights. This makes it difficult to assess robustness against semantic camouflage.
minor comments (2)
- [§3.1] The notation for the gating network and expert outputs could be clarified with a single consolidated diagram or table to improve readability of the architecture.
- [§1] A few sentences in the introduction repeat the problem motivation without adding new technical context; tightening would improve flow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating revisions made to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3.3] §3.3, expert-level one-class objectives: The central unsupervised separation claim depends on the assumption that fraudster rarity allows each expert to reliably model only dominant benign patterns. No analysis is provided on the case where semantic camouflage aligns fraudster text attributes with benign distributions (potentially across multiple cues), which could cause the mixture to model a blended distribution rather than isolating the rare class.
Authors: We acknowledge that the effectiveness of the expert-level one-class objectives relies on the rarity assumption and that extreme alignment of camouflaged fraudster attributes with benign distributions across cues could in principle lead to modeling challenges. The design of CAMERA mitigates this through ego-decoupled experts that specialize on distinct fraud-indicative cues and a context-informed gating mechanism that adaptively weights them based on both ego and neighborhood information. In the revised manuscript, we have expanded Section 3.3 with additional discussion of this edge case and included new empirical analysis on synthetically modified datasets that increase cross-cue alignment to illustrate that performance degradation remains limited compared to baselines. revision: yes
-
Referee: [§4] §4, experimental results: The claim of consistent outperformance on 4 datasets is load-bearing for the paper's contribution, yet the manuscript lacks details on exact metrics (e.g., AUC or F1), baseline configurations, statistical significance testing, and ablation studies on the number of experts or gating network weights. This makes it difficult to assess robustness against semantic camouflage.
Authors: We agree that greater detail on the experimental setup and results is necessary for full assessment of robustness. The revised Section 4 now reports precise AUC and F1 values for CAMERA and all baselines, provides complete hyperparameter configurations and implementation details for each baseline, includes statistical significance testing via paired t-tests with reported p-values, and adds ablation studies examining performance as a function of the number of experts (ranging from 2 to 8) as well as variations in gating network architecture and loss weighting. These updates directly support the robustness claims under semantic camouflage. revision: yes
Circularity Check
No circularity: new architecture and objectives are independently defined
full rationale
The paper introduces an ego-decoupled mixture-of-experts architecture, context-informed gating, and expert-level one-class objectives that explicitly leverage the external rarity assumption for unsupervised modeling of benign patterns. No equations, fitted parameters, or self-citations are shown that reduce the central claims or performance metrics to quantities defined from the same evaluation data. The derivation chain consists of architectural proposals and modeling choices that remain self-contained against external benchmarks and do not collapse by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of experts
- gating network weights
axioms (1)
- domain assumption Fraudsters are rare relative to benign users and their patterns deviate from dominant benign behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CAMERA leverages the inherent rarity of fraudsters to support unsupervised one-class learning with expert-level objectives that encourage modeling dominant benign patterns
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
si = σ(∥h_final_i∥₂) … LOC = 1/N Σ BCE(si,0)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Out-of- distribution detection on graphs: A survey.arXiv preprint arXiv:2502.08105,
[Caiet al., 2025 ] Tingyi Cai, Yunliang Jiang, Yixin Liu, Ming Li, Changqin Huang, and Shirui Pan. Out-of- distribution detection on graphs: A survey.arXiv preprint arXiv:2502.08105,
-
[2]
[Cybenko, 1989] George Cybenko. Approximation by su- perpositions of a sigmoidal function.Mathematics of con- trol, signals and systems, 2(4):303–314,
work page 1989
-
[3]
Deep anomaly detection on attributed networks
[Dinget al., 2019 ] Kaize Ding, Jundong Li, Rohit Bhanushali, and Huan Liu. Deep anomaly detection on attributed networks. InProceedings of the 2019 SIAM international conference on data mining, pages 594–602. SIAM,
work page 2019
-
[4]
[Donget al., 2025 ] Xiangyu Dong, Xingyi Zhang, Lei Chen, Mingxuan Yuan, and Sibo Wang. SpaceGNN: Multi-space graph neural network for node anomaly detection with ex- tremely limited labels. InThe Thirteenth International Conference on Learning Representations,
work page 2025
-
[5]
Enhancing graph neural network-based fraud detectors against camouflaged fraudsters
[Douet al., 2020 ] Yingtong Dou, Zhiwei Liu, Li Sun, Yu- tong Deng, Hao Peng, and Philip S Yu. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. InProceedings of the 29th ACM interna- tional conference on information & knowledge manage- ment, pages 315–324,
work page 2020
-
[6]
[Feduset al., 2022 ] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion param- eter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
work page 2022
-
[7]
Ad- dressing heterophily in graph anomaly detection: A per- spective of graph spectrum
[Gaoet al., 2023 ] Yuan Gao, Xiang Wang, Xiangnan He, Zhenguang Liu, Huamin Feng, and Yongdong Zhang. Ad- dressing heterophily in graph anomaly detection: A per- spective of graph spectrum. InProceedings of the ACM web conference 2023, pages 1528–1538,
work page 2023
-
[8]
Demix layers: Disentangling domains for modular lan- guage modeling
[Gururanganet al., 2022 ] Suchin Gururangan, Mike Lewis, Ari Holtzman, Noah A Smith, and Luke Zettlemoyer. Demix layers: Disentangling domains for modular lan- guage modeling. InProceedings of the 2022 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, pages 5557–5576,
work page 2022
-
[9]
Ada-gad: Anomaly-denoised autoencoders for graph anomaly detec- tion
[Heet al., 2024 ] Junwei He, Qianqian Xu, Yangbangyan Jiang, Zitai Wang, and Qingming Huang. Ada-gad: Anomaly-denoised autoencoders for graph anomaly detec- tion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 8481–8489,
work page 2024
-
[10]
[Huet al., 2023 ] Xinxin Hu, Haotian Chen, Hongchang Chen, Shuxin Liu, Xing Li, Shibo Zhang, Yahui Wang, and Xiangyang Xue. Cost-sensitive gnn-based imbal- anced learning for mobile social network fraud detec- tion.IEEE Transactions on Computational Social Systems, 11(2):2675–2690,
work page 2023
-
[11]
Unsupervised graph outlier de- tection: Problem revisit, new insight, and superior method
[Huanget al., 2023 ] Yihong Huang, Liping Wang, Fan Zhang, and Xuemin Lin. Unsupervised graph outlier de- tection: Problem revisit, new insight, and superior method. In2023 IEEE 39th International Conference on Data En- gineering (ICDE), pages 2565–2578. IEEE,
work page 2023
-
[12]
Anemone: Graph anomaly detection with multi-scale contrastive learning
[Jinet al., 2021 ] Ming Jin, Yixin Liu, Yu Zheng, Lianhua Chi, Yuan-Fang Li, and Shirui Pan. Anemone: Graph anomaly detection with multi-scale contrastive learning. In Proceedings of the 30th ACM international conference on information & knowledge management, pages 3122–3126,
work page 2021
-
[13]
Auto-Encoding Variational Bayes
[Kingma and Welling, 2013] Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Base lay- ers: Simplifying training of large, sparse models
[Lewiset al., 2021 ] Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base lay- ers: Simplifying training of large, sparse models. InInter- national Conference on Machine Learning, pages 6265–
work page 2021
-
[15]
[Liet al., 2022 ] Ranran Li, Zhaowei Liu, Yuanqing Ma, Dong Yang, and Shuaijie Sun. Internet financial fraud de- tection based on graph learning.IEEE Transactions on Computational Social Systems, 10(3):1394–1401,
work page 2022
-
[16]
[Liet al., 2024 ] Yuhan Li, Peisong Wang, Xiao Zhu, Aochuan Chen, Haiyun Jiang, Deng Cai, Victor W Chan, and Jia Li. Glbench: A comprehensive benchmark for graph with large language models.Advances in Neural Information Processing Systems, 37:42349–42368,
work page 2024
-
[17]
Dgp: A dual-granularity prompting framework for fraud detection with graph-enhanced llms
[Liet al., 2025 ] Yuan Li, Jun Hu, Bryan Hooi, Bingsheng He, and Cheng Chen. Dgp: A dual-granularity prompting framework for fraud detection with graph-enhanced llms. arXiv preprint arXiv:2507.21653,
-
[18]
Towards one-for- all anomaly detection for tabular data
[Liet al., 2026 ] Shiyuan Li, Yixin Liu, Yu Zheng, Xiaofeng Cao, Shirui Pan, and Heng Tao Shen. Towards one-for- all anomaly detection for tabular data. InInternational Conference on Machine Learning (ICML),
work page 2026
-
[19]
Pick and choose: a gnn-based imbalanced learning approach for fraud detection
[Liuet al., 2021a ] Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. Pick and choose: a gnn-based imbalanced learning approach for fraud detection. InProceedings of the web conference 2021, pages 3168–3177,
work page 2021
-
[20]
Diver- sifying the mixture-of-experts representation for language models with orthogonal optimizer
[Liuet al., 2023 ] Boan Liu, Liang Ding, Li Shen, Keqin Peng, Yu Cao, Dazhao Cheng, and Dacheng Tao. Diver- sifying the mixture-of-experts representation for language models with orthogonal optimizer. InProceedings of the European Conference on Artificial Intelligence (ECAI). IOS Press,
work page 2023
-
[21]
To- wards anomaly detection on text-attributed graphs
[Liuet al., 2025 ] Xudong Liu, Yanan Ren, Hengtong Zhang, Run-An Wang, Shenghe Zheng, and Zhaonian Zou. To- wards anomaly detection on text-attributed graphs. https: //openreview.net/forum?id=LMKYd9JHgU,
work page 2025
-
[22]
Open- Review preprint. [Liuet al., 2026 ] Yixin Liu, Shiyuan Li, Yu Zheng, Qingfeng Chen, Chengqi Zhang, Philip S Yu, and Shirui Pan. From few-shot to zero-shot: Towards generalist graph anomaly detection.arXiv preprint arXiv:2602.18793,
-
[23]
[Maet al., 2021 ] Xiaoxiao Ma, Jia Wu, Shan Xue, Jian Yang, Chuan Zhou, Quan Z Sheng, Hui Xiong, and Le- man Akoglu. A comprehensive survey on graph anomaly detection with deep learning.IEEE transactions on knowl- edge and data engineering, 35(12):12012–12038,
work page 2021
-
[24]
On fake news detec- tion with llm enhanced semantics mining
[Maet al., 2024 ] Xiaoxiao Ma, Yuchen Zhang, Kaize Ding, Jian Yang, Jia Wu, and Hao Fan. On fake news detec- tion with llm enhanced semantics mining. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 508–521,
work page 2024
-
[25]
From amateurs to connoisseurs: model- ing the evolution of user expertise through online reviews
[McAuley and Leskovec, 2013] Julian John McAuley and Jure Leskovec. From amateurs to connoisseurs: model- ing the evolution of user expertise through online reviews. InProceedings of the 22nd international conference on World Wide Web, pages 897–908,
work page 2013
-
[26]
Prem: A simple yet effective approach for node-level graph anomaly detection
[Panet al., 2023 ] Junjun Pan, Yixin Liu, Yizhen Zheng, and Shirui Pan. Prem: A simple yet effective approach for node-level graph anomaly detection. In2023 IEEE In- ternational Conference on Data Mining (ICDM), pages 1253–1258. IEEE,
work page 2023
-
[27]
Guard: Effective anomaly detection through a text-rich and graph- informed language model
[Panget al., 2025 ] Yunhe Pang, Bo Chen, Fanjin Zhang, Yanghui Rao, Evgeny Kharlamov, and Jie Tang. Guard: Effective anomaly detection through a text-rich and graph- informed language model. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 2222–2233,
work page 2025
-
[28]
[Qianet al., 2026 ] Yanyu Qian, Yue Tan, Yixin Liu, Wang Yu, and Shirui Pan. Dynhd: Hallucination detection for diffusion large language models via denoising dynam- ics deviation learning.arXiv preprint arXiv:2603.16459,
-
[29]
[Qiao and Pang, 2023] Hezhe Qiao and Guansong Pang. Truncated affinity maximization: One-class homophily modeling for graph anomaly detection.Advances in Neural Information Processing Systems, 36:49490–49512,
work page 2023
-
[30]
Collective opinion spam detection: Bridging re- view networks and metadata
[Rayana and Akoglu, 2015] Shebuti Rayana and Leman Akoglu. Collective opinion spam detection: Bridging re- view networks and metadata. InProceedings of the 21th acm sigkdd international conference on knowledge discov- ery and data mining, pages 985–994,
work page 2015
-
[31]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
[Reimers and Gurevych, 2019] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Gad-nr: Graph anomaly detection via neighborhood reconstruc- tion
[Royet al., 2024 ] Amit Roy, Juan Shu, Jia Li, Carl Yang, Olivier Elshocht, Jeroen Smeets, and Pan Li. Gad-nr: Graph anomaly detection via neighborhood reconstruc- tion. InProceedings of the 17th ACM international con- ference on web search and data mining, pages 576–585,
work page 2024
-
[33]
A sur- vey on oversmoothing in graph neural networks,
[Ruschet al., 2023 ] T Konstantin Rusch, Michael M Bron- stein, and Siddhartha Mishra. A survey on over- smoothing in graph neural networks.arXiv preprint arXiv:2303.10993,
-
[34]
[Tanet al., 2025 ] Yue Tan, Xiaoqian Hu, Hao Xue, Celso De Melo, and Flora Salim. Bisecle: Binding and separa- tion in continual learning for video language understand- ing.Advances in Neural Information Processing Systems, 38:33752–33782,
work page 2025
-
[35]
Rethinking graph neural networks for anomaly de- tection
[Tanget al., 2022 ] Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. Rethinking graph neural networks for anomaly de- tection. InInternational conference on machine learning, pages 21076–21089. PMLR,
work page 2022
-
[36]
[Wanget al., 2021 ] Xuhong Wang, Baihong Jin, Ying Du, Ping Cui, Yingshui Tan, and Yupu Yang. One-class graph neural networks for anomaly detection in at- tributed networks.Neural computing and applications, 33(18):12073–12085,
work page 2021
-
[37]
[Xuet al., 2025b ] Yiming Xu, Xu Hua, Zhen Peng, Bin Shi, Jiarun Chen, Xingbo Fu, Song Wang, and Bo Dong. Text-attributed graph anomaly detection via multi-scale cross-and uni-modal contrastive learning.arXiv preprint arXiv:2508.00513,
-
[38]
Grad: Guided relation diffusion generation for graph augmentation in graph fraud detection
[Yanget al., 2025b ] Jie Yang, Rui Zhang, Ziyang Cheng, Dawei Cheng, Guang Yang, and Bo Wang. Grad: Guided relation diffusion generation for graph augmentation in graph fraud detection. InProceedings of the ACM on Web Conference 2025, pages 5308–5319,
work page 2025
-
[39]
Group-based fraud detection network on e- commerce platforms
[Yuet al., 2023 ] Jianke Yu, Hanchen Wang, Xiaoyang Wang, Zhao Li, Lu Qin, Wenjie Zhang, Jian Liao, and Ying Zhang. Group-based fraud detection network on e- commerce platforms. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, pages 5463–5475,
work page 2023
-
[40]
Freegad: A training-free yet effective approach for graph anomaly de- tection
[Zhaoet al., 2025 ] Yunfeng Zhao, Yixin Liu, Shiyuan Li, Qingfeng Chen, Yu Zheng, and Shirui Pan. Freegad: A training-free yet effective approach for graph anomaly de- tection. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 4379–4389,
work page 2025
-
[41]
Fedcigar: A personalized reconstruction approach for federated graph- level anomaly detection
[Zhaoet al., 2026 ] Yunfeng Zhao, Yixin Liu, Qingfeng Chen, Shiyuan Li, Yue Tan, and Shirui Pan. Fedcigar: A personalized reconstruction approach for federated graph- level anomaly detection. InInternational Joint Conference on Artificial Intelligence,
work page 2026
-
[42]
A Related work in details A.1 Fraud Detection on Attributed Graph Graph fraud detection (GFD) aims to identify fraudulent ac- tivities in real-world graph applications, such as financial fraud [Liet al., 2022 ], fake reviews [Yuet al., 2023 ], and spamming [Huet al., 2023 ]. Earlier works treat GFD as a class-imbalance classification problem and incorpora...
work page 2022
-
[43]
minL OC ⇐ ⇒min X i X k g[L] i,k e[L] k (h[L−1] i ,A) 2
From this, it follows that minimizingL OC is equivalent to minimizing theℓ 2 norm of the gating-weighted expert resid- uals: 24 25 26 27 28 29 210 211 212 Hidden Dimension 0.55 0.60AUROC (%) AmazonVideo YelpChi Figure 7: Over-parameterization study on YelpChi and Amazon datasets. minL OC ⇐ ⇒min X i X k g[L] i,k e[L] k (h[L−1] i ,A) 2 . Therefore, to analy...
work page 2024
-
[44]
←LLM(T) 3://Training phase 4:forepoch= 1, ..., Edo 5:L expert ←0 6:L gating ←0 7:forl= 1, ..., Ldo 8:H [l] ←f [l](H[l−1],A) 9:L expert ← Lexpert +P k 1 N PN i=1 ∥e[l] k (h[l−1] i ,A)∥ 2 2 10:L gating ← Lgating +P k − 1 N PN i=1 g[l] i,k log(g[l] i,k +ϵ) 11:end for 12:Computes, wheres i =σ(∥h L i ∥2) 13:L OC = 1 N PN i=1 BCE(si,0) 14:L=L expert +αL gating ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.