GaNI: Global and Near Field Illumination Aware Neural Inverse Rendering
Pith reviewed 2026-05-24 02:50 UTC · model grok-4.3
The pith
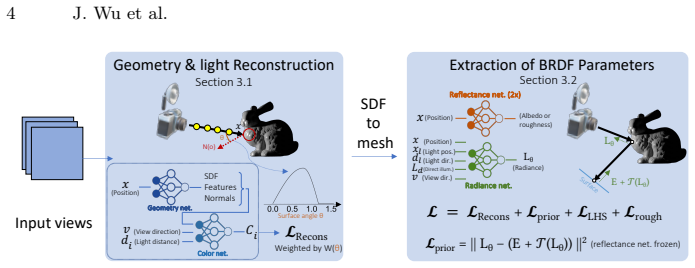
GaNI reconstructs geometry albedo and roughness from co-located light-camera images by separating NeuS geometry from light-position-aware inverse neural radiosity and adding fixes for near-field effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
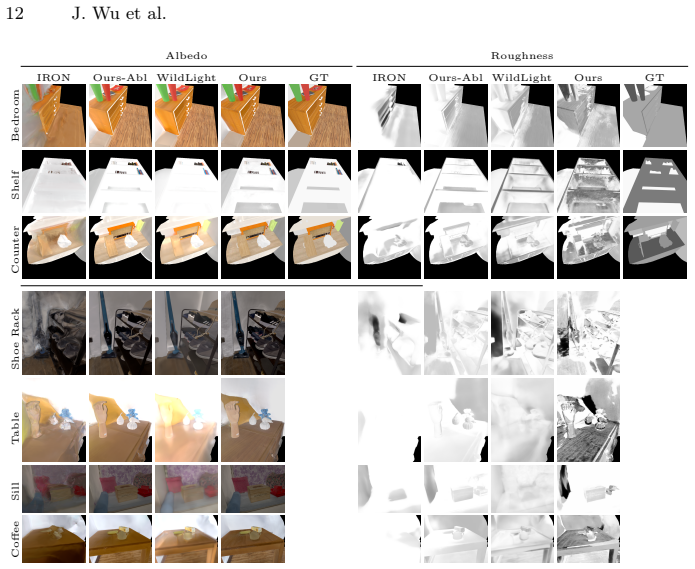
The authors claim that their two-stage system, after the listed technical fixes, outperforms existing co-located inverse rendering techniques by delivering significantly better reflectance estimates and modestly better geometry on both synthetic and real data, without needing a dark room.
What carries the argument
Two-stage pipeline of NeuS geometry followed by inverse neural radiosity, augmented with implicit near-field illumination modeling, surface angle loss, light-position-aware radiance cache, and roughness smoothness priors.
If this is right
- Reflectance parameters are recovered more accurately than in prior co-located methods.
- Geometry improves slightly over capture strategies that skip dark-room conditions.
- Moving flashlights during capture become usable because the radiance cache accounts for changing light position.
- Multi-object scenes with global illumination can be processed without assuming constant lighting.
Where Pith is reading between the lines
- The same separation strategy might extend to other non-constant illumination sources if the near-field and position-aware modules are retrained.
- Casual phone-flash captures could become sufficient input for material digitization pipelines in consumer applications.
- Failure cases on highly specular or translucent surfaces would indicate where additional priors are still required.
Load-bearing premise
The introduced fixes for near-field illumination and specular reflections keep the geometry-to-reflectance separation stable even when NeuS produces errors typical of flashlight capture.
What would settle it
A real multi-object scene captured with a moving co-located flashlight where measured albedo and roughness values differ substantially from the method's output would falsify the performance claim.
Figures












read the original abstract
In this paper, we present GaNI, a Global and Near-field Illumination-aware neural inverse rendering technique that can reconstruct geometry, albedo, and roughness parameters from images of a scene captured with co-located light and camera. Existing inverse rendering techniques with co-located light-camera focus on single objects only, without modeling global illumination and near-field lighting more prominent in scenes with multiple objects. We introduce a system that solves this problem in two stages; we first reconstruct the geometry powered by neural volumetric rendering NeuS, followed by inverse neural radiosity that uses the previously predicted geometry to estimate albedo and roughness. However, such a naive combination fails and we propose multiple technical contributions that enable this two-stage approach. We observe that NeuS fails to handle near-field illumination and strong specular reflections from the flashlight in a scene. We propose to implicitly model the effects of near-field illumination and introduce a surface angle loss function to handle specular reflections. Similarly, we observe that invNeRad assumes constant illumination throughout the capture and cannot handle moving flashlights during capture. We propose a light position-aware radiance cache network and additional smoothness priors on roughness to reconstruct reflectance. Experimental evaluation on synthetic and real data shows that our method outperforms the existing co-located light-camera-based inverse rendering techniques. Our approach produces significantly better reflectance and slightly better geometry than capture strategies that do not require a dark room.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GaNI, a two-stage neural inverse rendering pipeline for scenes captured under co-located flashlight illumination. Stage 1 uses NeuS to recover geometry; Stage 2 feeds that geometry into a modified invNeRad (inverse neural radiosity) to recover albedo and roughness. The authors note that a direct combination fails because NeuS cannot handle near-field flashlight effects and strong specularities, and because invNeRad assumes constant illumination. They therefore introduce implicit near-field modeling, a surface-angle loss, a light-position-aware radiance cache, and roughness smoothness priors. Experiments on synthetic and real data are reported to show better reflectance and modestly better geometry than prior co-located-light methods and than capture strategies that do not require a dark room.
Significance. If the two-stage separation proves robust, the work would be useful for practical inverse rendering outside controlled dark-room settings. The explicit handling of near-field and moving-flashlight effects addresses a clear gap in existing co-located pipelines. No machine-checked proofs or parameter-free derivations are present, but the method is falsifiable via the reported synthetic/real comparisons.
major comments (2)
- [Abstract / Method overview] The central claim that the proposed fixes make the NeuS-to-invNeRad separation reliable rests on an untested assumption. The abstract states that the naive combination fails precisely because of near-field and specular errors in NeuS geometry; however, no quantitative ablation (e.g., controlled injection of geometry error magnitude versus resulting reflectance error) is described that would demonstrate the fixes close this gap rather than merely compensate for training instabilities.
- [Experimental evaluation] The outperformance claim over existing co-located techniques is load-bearing for the contribution. Without visible error tables, per-scene breakdowns, or statistical significance tests in the provided description, it is impossible to verify whether the reported reflectance gains are driven by the new components or by re-tuning of the two pre-existing networks on the target data.
minor comments (2)
- [Method] Notation for the light-position-aware radiance cache and the implicit near-field model should be defined explicitly with equations rather than descriptive prose only.
- [Implementation details] The surface-angle loss and roughness smoothness priors are introduced as necessary; their relative weighting and sensitivity to hyper-parameters should be reported in an ablation table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method overview] The central claim that the proposed fixes make the NeuS-to-invNeRad separation reliable rests on an untested assumption. The abstract states that the naive combination fails precisely because of near-field and specular errors in NeuS geometry; however, no quantitative ablation (e.g., controlled injection of geometry error magnitude versus resulting reflectance error) is described that would demonstrate the fixes close this gap rather than merely compensate for training instabilities.
Authors: We agree that a controlled ablation injecting varying magnitudes of geometry error into the second stage and measuring the resulting reflectance error would provide stronger evidence that the proposed components (implicit near-field modeling, surface-angle loss, light-position-aware cache, and roughness priors) specifically mitigate the identified failure modes. The revised manuscript will include such an experiment on synthetic data, reporting reflectance metrics as a function of injected geometry error with and without each contribution. revision: yes
-
Referee: [Experimental evaluation] The outperformance claim over existing co-located techniques is load-bearing for the contribution. Without visible error tables, per-scene breakdowns, or statistical significance tests in the provided description, it is impossible to verify whether the reported reflectance gains are driven by the new components or by re-tuning of the two pre-existing networks on the target data.
Authors: The manuscript reports quantitative metrics on synthetic data and qualitative results on real scenes, but we acknowledge that additional tabular breakdowns would improve verifiability. The revision will add per-scene error tables for albedo and roughness, component-wise ablations, and statistical significance tests (e.g., Wilcoxon signed-rank) comparing GaNI against the baselines to clarify the source of the reported gains. revision: yes
Circularity Check
No circularity: two-stage pipeline with external priors and experimental validation
full rationale
The paper describes a two-stage method (NeuS geometry followed by modified inverse neural radiosity) with explicit technical fixes for near-field illumination, specular reflections, and moving lights. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce any claimed result to its inputs by construction. The central claims rest on experimental comparisons to prior co-located techniques and non-dark-room capture, which are independent of the method definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer 25 Vision and Pattern Recognition, pp
Bi, S., Xu, Z., Sunkavalli, K., Kriegman, D., Ramamoorthi, R.: Deep 3d capture: Geometry and reflectance from sparse multi-view images. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5959–5968. IEEE Computer Society, Los Alamitos, CA, USA (jun 2020).https://doi.org/ 10.1109/CVPR42600.2020.00600,https://doi.ieeecomputer...
-
[2]
Bi, S., Xu, Z., Sunkavalli, K., Hašan, M., Hold-Geoffroy, Y., Kriegman, D., Ra- mamoorthi, R.: Deep reflectance volumes: Relightable reconstructions from multi- view photometric images. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III. p. 294–311. Springer-Verlag, Berlin, Heidelberg (2020).h...
-
[3]
Burley, B., Studios, W.D.A.: Physically-based shading at disney. In: Acm Siggraph. vol. 2012, pp. 1–7. vol. 2012 (2012) 3, 4, 6, 8
work page 2012
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng, Z., Li, J., Li, H.: Wildlight: In-the-wild inverse rendering with a flashlight. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4305–4314 (June 2023) 1, 2, 3, 4, 5, 6, 10, 11, 12
work page 2023
-
[5]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Fu, Q., Xu, Q., Ong, Y.S., Tao, W.: Geo-neus: Geometry-consistent neural im- plicit surfaces learning for multi-view reconstruction. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural In- formation Processing Systems. vol. 35, pp. 3403–3416. Curran Associates, Inc. (2022),https : / / proceedings . neurips . c...
work page 2022
-
[6]
IEEE Trans- actions on Pattern Analysis and Machine Intelligence32(12), 2276–2288 (2010)
Goldman, D.B.: Vignette and exposure calibration and compensation. IEEE Trans- actions on Pattern Analysis and Machine Intelligence32(12), 2276–2288 (2010). https://doi.org/10.1109/TPAMI.2010.552
-
[7]
Guo, K., Lincoln, P., Davidson, P., Busch, J., Yu, X., Whalen, M., Harvey, G., Orts-Escolano, S., Pandey, R., Dourgarian, J., Tang, D., Tkach, A., Kowdle, A., Cooper, E., Dou, M., Fanello, S., Fyffe, G., Rhemann, C., Taylor, J., Debevec, P., Izadi, S.: The relightables: Volumetric performance capture of humans with realistic relighting. ACM Trans. Graph.3...
-
[8]
In: ACM SIGGRAPH 2023 Confer- ence Proceedings
Hadadan, S., Lin, G., Novák, J., Rousselle, F., Zwicker, M.: Inverse global illu- mination using a neural radiometric prior. In: ACM SIGGRAPH 2023 Confer- ence Proceedings. SIGGRAPH ’23, Association for Computing Machinery, New York, NY, USA (2023).https://doi.org/10.1145/3588432.3591553,https: //doi.org/10.1145/3588432.35915533, 5, 6, 8, 9
-
[9]
Hasselgren, J., Hofmann, N., Munkberg, J.: Shape, Light, and Material Decompo- sition from Images using Monte Carlo Rendering and Denoising. arXiv:2206.03380 (2022) 4
-
[10]
Jakob, W., Speierer, S., Roussel, N., Nimier-David, M., Vicini, D., Zeltner, T., Nicolet, B., Crespo, M., Leroy, V., Zhang, Z.: Mitsuba 3 renderer (2022), https://mitsuba-renderer.org 10, 1
work page 2022
-
[11]
Kim, H., Zollöfer, M., Tewari, A., Thies, J., Richardt, C., Theobalt, C.: Inverse- facenet:Deepsingle-shotinversefacerenderingfromasingleimage.In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 1
work page 2018
-
[12]
Li, Z., Shafiei, M., Ramamoorthi, R., Sunkavalli, K., Chandraker, M.: Inverse ren- dering for complex indoor scenes: Shape, spatially-varying lighting and svbrdf from Abbreviated paper title 17 a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 1, 2, 4
work page 2020
-
[13]
LibRaw LLC: Libraw.https://github.com/LibRaw/LibRaw2
-
[14]
Lichy, D., Sengupta, S., Jacobs, D.W.: Fast light-weight near-field photometric stereo. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 12602–12611. IEEE Computer Society, Los Alamitos, CA, USA (jun 2022).https://doi.org/10.1109/CVPR52688.2022.01228,https: //doi.ieeecomputersociety.org/10.1109/CVPR52688.2022.012281, 2
-
[15]
Derf: Decomposed radiance fields,
Lichy, D., Wu, J., Sengupta, S., Jacobs, D.W.: Shape and material capture at home. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 6119–6129. IEEE Computer Society, Los Alamitos, CA, USA (jun 2021).https://doi.org/10.1109/CVPR46437.2021.00606,https://doi. ieeecomputersociety.org/10.1109/CVPR46437.2021.006061, 4
-
[16]
Lindenberger, P., Sarlin, P.E., Larsson, V., Pollefeys, M.: Pixel-Perfect Structure- from-Motion with Featuremetric Refinement. In: ICCV (2021) 2
work page 2021
-
[17]
Liu, Y., Wang, P., Lin, C., Long, X., Wang, J., Liu, L., Komura, T., Wang, W.: Nero: Neural geometry and brdf reconstruction of reflective objects from multiview images (2023) 4
work page 2023
-
[18]
Computer Graphics Forum40(2021),https: //api.semanticscholar.org/CorpusID:2324046682, 4
Luan, F., Zhao, S., Bala, K., Dong, Z.: Unified shape and svbrdf recovery using differentiable monte carlo rendering. Computer Graphics Forum40(2021),https: //api.semanticscholar.org/CorpusID:2324046682, 4
work page 2021
-
[19]
Maik Riechert: rawpy.https://github.com/letmaik/rawpy(2022) 2
work page 2022
-
[20]
Mildenhall, B., Hedman, P., Martin-Brualla, R., Srinivasan, P.P., Barron, J.T.: NeRF in the dark: High dynamic range view synthesis from noisy raw images. CVPR (2022) 7
work page 2022
-
[21]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM65(1), 99–106 (dec 2021).https://doi.org/10.1145/3503250,https:// doi.org/10.1145/35032507
-
[22]
Müller,T.,Evans,A.,Schied,C.,Keller,A.:Instantneuralgraphicsprimitiveswith a multiresolution hash encoding. ACM Trans. Graph.41(4) (jul 2022).https: //doi.org/10.1145/3528223.3530127,https://doi.org/10.1145/3528223. 35301277
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Munkberg, J., Hasselgren, J., Shen, T., Gao, J., Chen, W., Evans, A., Müller, T., Fidler, S.: Extracting Triangular 3D Models, Materials, and Lighting From Images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8280–8290 (June 2022) 4
work page 2022
-
[24]
Nam, G., Lee, J.H., Gutierrez, D., Kim, M.H.: Practical svbrdf acquisition of 3d objects with unstructured flash photography. ACM Trans. Graph.37(6) (dec 2018).https://doi.org/10.1145/3272127.3275017,https://doi.org/10.1145/ 3272127.32750172, 4
-
[25]
NVIDIA: Nvidia optix ray tracing engine,https://developer.nvidia.com/rtx/ ray-tracing/optix1
-
[26]
Pandey, R., Orts-Escolano, S., LeGendre, C., Haene, C., Bouaziz, S., Rhemann, C., Debevec, P., Fanello, S.: Total relighting: Learning to relight portraits for back- ground replacement. vol. 40 (August 2021).https://doi.org/10.1145/3450626. 34598721, 4
-
[27]
Schmitt, C., Donne, S., Riegler, G., Koltun, V., Geiger, A.: On joint estimation of pose, geometry and svbrdf from a handheld scanner. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2020) 4 18 J. Wu et al
work page 2020
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Sengupta, S., Gu, J., Kim, K., Liu, G., Jacobs, D.W., Kautz, J.: Neural inverse rendering of an indoor scene from a single image. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8598–8607 (2019) 2, 4
work page 2019
-
[29]
In: Proceedings of the IEEE con- ference on computer vision and pattern recognition
Sengupta, S., Kanazawa, A., Castillo, C.D., Jacobs, D.W.: Sfsnet: Learning shape, reflectance and illuminance of facesin the wild’. In: Proceedings of the IEEE con- ference on computer vision and pattern recognition. pp. 6296–6305 (2018) 1
work page 2018
-
[30]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Sun, C., Cai, G., Li, Z., Yan, K., Zhang, C., Marshall, C., Huang, J., Zhao, S., Dong, Z.: Neural-pbir reconstruction of shape, material, and illumination. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 18000– 18010. IEEE Computer Society, Los Alamitos, CA, USA (oct 2023).https:// doi.org/10.1109/ICCV51070.2023.01654,https://doi...
-
[31]
In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W
Wang, P., Liu, L., Liu, Y., Theobalt, C., Komura, T., Wang, W.: Neus: Learn- ing neural implicit surfaces by volume rendering for multi-view reconstruction. In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W. (eds.) Ad- vances in Neural Information Processing Systems. vol. 34, pp. 27171–27183. Curran Associates, Inc. (2021),https://pro...
work page 2021
-
[32]
In: European Conference on Computer Vision (ECCV) (2022) 4
Yao, Y., Zhang, J., Liu, J., Qu, Y., Fang, T., McKinnon, D., Tsin, Y., Quan, L.: Neilf: Neural incident light field for physically-based material estimation. In: European Conference on Computer Vision (ECCV) (2022) 4
work page 2022
-
[33]
In: Thirty-Fifth Conference on Neural Information Processing Systems (2021) 5
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. In: Thirty-Fifth Conference on Neural Information Processing Systems (2021) 5
work page 2021
-
[34]
Advances in Neural Information Processing Systems33(2020) 2
Yariv, L., Kasten, Y., Moran, D., Galun, M., Atzmon, M., Ronen, B., Lipman, Y.: Multiview neural surface reconstruction by disentangling geometry and appear- ance. Advances in Neural Information Processing Systems33(2020) 2
work page 2020
-
[35]
Yu, Y., Smith, W.A.: Inverserendernet: Learning single image inverse rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019) 2
work page 2019
-
[36]
In: International Conference on Computer Vision (ICCV) (2023) 3, 4, 5, 8, 11, 13
Zhang, J., Yao, Y., Li, S., Liu, J., Fang, T., McKinnon, D., Tsin, Y., Quan, L.: Neilf++: Inter-reflectable light fields for geometry and material estimation. In: International Conference on Computer Vision (ICCV) (2023) 3, 4, 5, 8, 11, 13
work page 2023
-
[37]
Zhang, K., Luan, F., Li, Z., Snavely, N.: Iron: Inverse rendering by optimizing neural sdfs and materials from photometric images. In: 2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 5555–5564 (2022). https://doi.org/10.1109/CVPR52688.2022.005481, 2, 3, 4, 5, 6, 10, 11, 12, 13
-
[38]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang,K.,Luan,F.,Wang,Q.,Bala,K.,Snavely,N.:Physg:Inverserenderingwith spherical gaussians for physics-based material editing and relighting. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5453–5462 (June 2021) 1, 4
work page 2021
-
[39]
Zhang, X., Fanello, S., Tsai, Y.T., Sun, T., Xue, T., Pandey, R., Orts-Escolano, S., Davidson, P., Rhemann, C., Debevec, P., Barron, J.T., Ramamoorthi, R., Freeman, W.T.: Neural light transport for relighting and view synthesis. ACM Trans. Graph. 40(1) (jan 2021).https://doi.org/10.1145/3446328,https://doi.org/10. 1145/34463284
-
[40]
Project starline: A high-fidelity telepresence system,
Zhang, X., Srinivasan, P.P., Deng, B., Debevec, P., Freeman, W.T., Barron, J.T.: Nerfactor: Neural factorization of shape and reflectance under an unknown il- lumination. ACM Trans. Graph.40(6) (dec 2021).https://doi.org/10.1145/ 3478513.3480496,https://doi.org/10.1145/3478513.34804964 Abbreviated paper title 1
-
[41]
Zhang, Y., Sun, J., He, X., Fu, H., Jia, R., Zhou, X.: Modeling indirect illumina- tion for inverse rendering (2022).https://doi.org/10.48550/ARXIV.2204.06837, https://arxiv.org/abs/2204.068374, 5, 8
-
[42]
arXiv preprint arXiv:2305.11167 (2023) 4
Zhao, D., Lichy, D., Perrin, P.N., Frahm, J.M., Sengupta, S.: Mvpsnet: Fast gen- eralizable multi-view photometric stereo. arXiv preprint arXiv:2305.11167 (2023) 4
-
[43]
Zhu, J., Huo, Y., Ye, Q., Luan, F., Li, J., Xi, D., Wang, L., Tang, R., Hua, W., Bao, H., Wang, R.: I2-sdf: Intrinsic indoor scene reconstruction and editing via raytracing in neural sdfs. In: CVPR (2023) 2
work page 2023
-
[44]
In: SIGGRAPH Asia 2022 Confer- ence Papers
Zhu, J., Luan, F., Huo, Y., Lin, Z., Zhong, Z., Xi, D., Wang, R., Bao, H., Zheng, J., Tang, R.: Learning-based inverse rendering of complex indoor scenes with differentiable monte carlo raytracing. In: SIGGRAPH Asia 2022 Confer- ence Papers. SA ’22, Association for Computing Machinery, New York, NY, USA (2022).https://doi.org/10.1145/3550469.3555407,https...
-
[45]
Zhu, R., Li, Z., Matai, J., Porikli, F., Chandraker, M.: Irisformer: Dense vi- sion transformers for single-image inverse rendering in indoor scenes. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2812–2821. IEEE Computer Society, Los Alamitos, CA, USA (jun 2022).https:// doi.org/10.1109/CVPR52688.2022.00284,https://do...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.