Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives
Pith reviewed 2026-05-24 00:20 UTC · model grok-4.3
The pith
Video-language understanding methods are summarized and compared from model architecture, training, and data perspectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
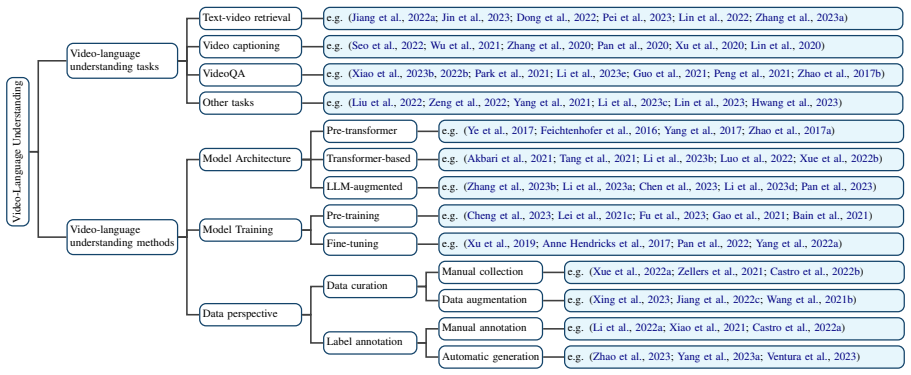
The survey establishes that video-language understanding systems can be reviewed through their key tasks and challenges, with methods then summarized from model architecture, model training, and data perspectives, accompanied by performance comparisons and discussion of future directions.
What carries the argument
The three-perspective categorization of methods into model architecture, model training, and data that structures the review and enables performance comparisons.
Load-bearing premise
The selected papers, tasks, and division into architecture, training, and data perspectives give a representative organization of the video-language understanding literature without major omissions or biases.
What would settle it
Discovery of a substantial set of video-language methods or tasks whose design, challenges, or performance results cannot be accounted for within the architecture, training, or data categories.
Figures





read the original abstract
Humans use multiple senses to comprehend the environment. Vision and language are two of the most vital senses since they allow us to easily communicate our thoughts and perceive the world around us. There has been a lot of interest in creating video-language understanding systems with human-like senses since a video-language pair can mimic both our linguistic medium and visual environment with temporal dynamics. In this survey, we review the key tasks of these systems and highlight the associated challenges. Based on the challenges, we summarize their methods from model architecture, model training, and data perspectives. We also conduct performance comparison among the methods, and discuss promising directions for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript surveys video-language understanding systems. It reviews key tasks and associated challenges, then organizes methods into three categories (model architecture, model training, and data perspectives), presents performance comparisons across methods, and outlines promising future directions.
Significance. If the taxonomy is comprehensive and the comparisons are fair, the survey could help researchers navigate a rapidly growing literature by providing a structured overview grounded in identified challenges. However, the absence of any stated search protocol or coverage statistics in the provided abstract and framing limits the ability to evaluate whether the three-way split faithfully captures the field or systematically omits unified models that cross the stated categories.
major comments (2)
- [Abstract] Abstract and introductory framing: the organization is stated to be 'based on the challenges,' yet no literature search protocol, inclusion/exclusion criteria, or quantitative coverage statistics (e.g., number of papers screened vs. included) are supplied. This directly affects the load-bearing claim that the architecture/training/data partition is representative rather than author-selected, leaving open the risk that end-to-end unified models or other major lines of work are under-represented or misclassified.
- [Performance comparison] Performance comparison section (as referenced in the abstract): without an explicit statement of how cited results were normalized for dataset, metric, model scale, or training compute, it is impossible to determine whether the tabulated comparisons support cross-method conclusions or are confounded by inconsistent experimental settings.
minor comments (1)
- Notation for model components and task definitions should be introduced with a single consolidated table or figure early in the manuscript to improve readability across the three perspectives.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which will help improve the clarity and transparency of our survey. We address the major comments point by point below.
read point-by-point responses
-
Referee: Abstract and introductory framing: the organization is stated to be 'based on the challenges,' yet no literature search protocol, inclusion/exclusion criteria, or quantitative coverage statistics (e.g., number of papers screened vs. included) are supplied. This directly affects the load-bearing claim that the architecture/training/data partition is representative rather than author-selected, leaving open the risk that end-to-end unified models or other major lines of work are under-represented or misclassified.
Authors: We acknowledge that a more explicit description of the paper selection process would strengthen the manuscript. This survey is structured around the key challenges in video-language understanding rather than following a formal systematic review protocol. In the revised version, we will expand the introduction to describe the criteria used for selecting papers (e.g., relevance to core tasks and challenges, recency, and impact) and note the limitations of this approach, including the possibility that some unified models may span multiple categories. We believe this addresses the concern without altering the challenge-based organization. revision: yes
-
Referee: Performance comparison section (as referenced in the abstract): without an explicit statement of how cited results were normalized for dataset, metric, model scale, or training compute, it is impossible to determine whether the tabulated comparisons support cross-method conclusions or are confounded by inconsistent experimental settings.
Authors: The comparisons in the performance section present results as originally reported in the cited works to provide an overview of the state of the art. We agree that an explicit caveat is necessary. In the revision, we will add a clear statement at the beginning of the performance comparison section explaining that no additional normalization was performed and highlighting that differences in datasets, metrics, model scales, and compute may affect direct comparisons. This will help readers interpret the tables appropriately. revision: yes
Circularity Check
No circularity: survey taxonomy and citations are not derivations
full rationale
This is a literature survey paper with no equations, fitted parameters, predictions, or first-principles derivations. The three-way categorization (architecture/training/data) is presented as an organizational lens chosen by the authors after reviewing challenges; it does not reduce any claim to a self-citation chain or to fitted inputs by construction. All references to prior work are external citations whose validity is independent of the present paper. Selection bias and completeness are validity concerns, not circularity. Score 0 is the appropriate finding for a self-contained survey.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Motion-aware Contrastive Learning for Temporal Panoptic Scene Graph Generation
Motion-aware contrastive learning on mask tubes improves temporal panoptic scene graph generation over pooling-based methods on video and 4D datasets.
Reference graph
Works this paper leans on
-
[1]
A CLIP-Hitchhiker’s Guide to Long Video Retrieval
Vatt: Transformers for multimodal self- supervised learning from raw video, audio and text. Advances in Neural Information Processing Systems, 34:24206–24221. Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In Proceedings of the IEEE international con...
-
[2]
A Short Note about Kinetics-600
Hierarchical boundary-aware neural encoder for video captioning. In Proceedings of the IEEE con- ference on computer vision and pattern recognition, pages 1657–1666. Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. 2018. A short note about kinetics-600. arXiv preprint arXiv:1808.01340. Joao Carreira, Eric Noland, Chlo...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
International Journal of Computer Vision, pages 1–23. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understand- ing. arXiv preprint arXiv:1810.04805. Zihan Ding, Tianrui Hui, Junshi Huang, Xiaoming Wei, Jizhong Han, and Si Liu. 2022. Language-bridged spatial-tempo...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Pixmix: Dreamlike pictures comprehensively improve safety measures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 16783–16792. Gabriel Huang, Bo Pang, Zhenhai Zhu, Clara Rivera, and Radu Soricut. 2020. Multimodal pretrain- ing for dense video captioning. arXiv preprint arXiv:2011.11760. Minyoung Hwang, Jaeye...
-
[5]
Temporal Tessellation: A Unified Approach for Video Analysis
Temporal tessellation for video annotation and summarization. arXiv preprint arXiv:1612.06950, 3. Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. 2017. The Ki- netics Human Action Video Dataset. arXiv preprint arXiv:1...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Tvqa: Localized, compositional video ques- tion answering. In Proceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1369–1379. Jie Lei, Licheng Yu, Tamara L Berg, and Mohit Bansal
work page 2018
-
[7]
VideoChat: Chat-Centric Video Understanding
Tvr: A large-scale dataset for video-subtitle moment retrieval. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23– 28, 2020, Proceedings, Part XXI 16, pages 447–463. Springer. Jiangtong Li, Li Niu, and Liqing Zhang. 2022a. From representation to reasoning: Towards both evidence and commonsense reasoning for video question- ans...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
In European Conference on Computer Vision, pages 413–430
Eclipse: Efficient long-range video retrieval using sight and sound. In European Conference on Computer Vision, pages 413–430. Springer. Ye Liu, Siyuan Li, Yang Wu, Chang-Wen Chen, Ying Shan, and Xiaohu Qie. 2022. Umt: Unified multi- modal transformers for joint video moment retrieval and highlight detection. In Proceedings of the IEEE/CVF Conference on C...
-
[9]
In Proceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640
Howto100m: Learning a text-video embed- ding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640. Mathew Monfort, Alex Andonian, Bolei Zhou, Kandan Ramakrishnan, Sarah Adel Bargal, Tom Yan, Lisa Brown, Quanfu Fan, Dan Gutfreund, Carl V ondrick, et al. 2019. Moments i...
-
[10]
Clipping: Distilling clip-based models with a student base for video-language retrieval. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18983–18992. Wenjie Pei, Jiyuan Zhang, Xiangrong Wang, Lei Ke, Xiaoyong Shen, and Yu-Wing Tai. 2019. Memory- attended recurrent network for video captioning. In Proceedings o...
work page 2019
-
[11]
In Proceedings of the 29th ACM International Conference on Multimedia, pages 2871– 2879
Progressive graph attention network for video question answering. In Proceedings of the 29th ACM International Conference on Multimedia, pages 2871– 2879. Michaela Regneri, Marcus Rohrbach, Dominikus Wet- zel, Stefan Thater, Bernt Schiele, and Manfred Pinkal
-
[12]
How2: A Large-scale Dataset for Multimodal Language Understanding
Grounding action descriptions in videos. Transactions of the Association for Computational Linguistics, 1:25–36. Anna Rohrbach, Marcus Rohrbach, Niket Tandon, and Bernt Schiele. 2015. A dataset for movie description. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3202–3212. Marcus Rohrbach, Sikandar Amin, Mykhaylo ...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Coin: A large-scale dataset for comprehen- sive instructional video analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207–1216. Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. 2023b. Video understanding with large language mod...
-
[14]
In 2017 IEEE In- ternational Conference on Image Processing (ICIP), pages 4197–4201
Graph-theoretic spatiotemporal context mod- eling for video saliency detection. In 2017 IEEE In- ternational Conference on Image Processing (ICIP), pages 4197–4201. IEEE. Bofeng Wu, Guocheng Niu, Jun Yu, Xinyan Xiao, Jian Zhang, and Hua Wu. 2021. Weakly supervised dense video captioning via jointly usage of knowledge dis- tillation and cross-modal matchin...
-
[15]
In International Conference on Machine Learning, pages 3891–3900
Tensor-train recurrent neural networks for video classification. In International Conference on Machine Learning, pages 3891–3900. PMLR. Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Bal- las, Christopher Pal, Hugo Larochelle, and Aaron Courville. 2015. Describing videos by exploiting temporal structure. In Proceedings of the IEEE in- ternational conferen...
work page 2015
-
[16]
arXiv preprint arXiv:2307.03166
Videoglue: Video general understanding evaluation of foundation models. arXiv preprint arXiv:2307.03166. Yitian Yuan, Tao Mei, and Wenwu Zhu. 2019. To find where you talk: Temporal sentence localization in video with attention based location regression. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9159–9166. Sangdoo Y...
-
[17]
In Proceedings of the IEEE/CVF international conference on com- puter vision, pages 6023–6032
Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international conference on com- puter vision, pages 6023–6032. Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi
-
[18]
Advances in Neural Information Processing Systems, 34:23634–23651
Merlot: Multimodal neural script knowledge models. Advances in Neural Information Processing Systems, 34:23634–23651. Kuo-Hao Zeng, Tseng-Hung Chen, Ching-Yao Chuang, Yuan-Hong Liao, Juan Carlos Niebles, and Min Sun
-
[19]
In Thirty-First AAAI Conference on Artificial Intelligence
Leveraging video descriptions to learn video question answering. In Thirty-First AAAI Conference on Artificial Intelligence. Yawen Zeng, Da Cao, Shaofei Lu, Hanling Zhang, Jiao Xu, and Zheng Qin. 2022. Moment is important: Language-based video moment retrieval via adversar- ial learning. ACM Transactions on Multimedia Com- puting, Communications, and Appl...
-
[20]
bow to people 1. set up the stand ✔ 2. take away the stand 3. takes out some paper
-
[21]
Video moment retrieval 38s 48s 60s 64s Q: People in scuba gear are swimming around
hands him a bottle NExT-QA (Xiao et al., 2021) Counting-based VideoQA Question: how many people are nodding their heads to music ? Answer: 2 TGIF-QA (Jang et al., 2017) Figure 5: Illustration of text-video retrieval, video captioning, and video question answer (videoQA) tasks. Video moment retrieval 38s 48s 60s 64s Q: People in scuba gear are swimming aro...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.