What to Say and When to Say it: Live Fitness Coaching as a Testbed for Situated Interaction
Pith reviewed 2026-05-23 22:49 UTC · model grok-4.3
The pith
A simple streaming baseline can deliver timely feedback in live fitness coaching while state-of-the-art vision-language models cannot handle asynchronous responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fitness coaching serves as a controlled testbed for situated interaction; existing state-of-the-art vision-language models exhibit limitations for asynchronous responses, whereas a simple end-to-end streaming baseline can recognize human actions and supply appropriate feedback at the appropriate time.
What carries the argument
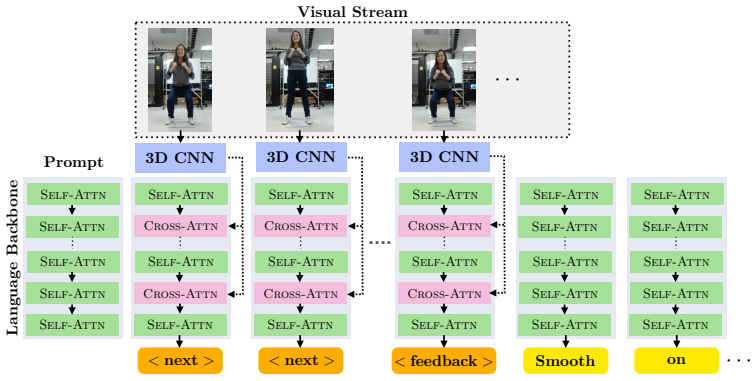
The QEVD benchmark and dataset, which requires models to recognize complex human actions, identify mistakes, and generate real-time feedback during live fitness sessions.
If this is right
- Models for real-world interaction must process continuous video streams rather than discrete prompted turns.
- The timing of feedback is as important as its content in situated tasks.
- Fitness coaching provides a measurable proxy for evaluating proactive AI behavior in other physical domains.
Where Pith is reading between the lines
- The same streaming approach could be tested on related tasks such as physical therapy or assembly guidance.
- Combining the baseline with stronger action-recognition backbones might close remaining performance gaps.
- Future systems may need explicit mechanisms for deciding both content and delivery timing rather than relying on external prompts.
Load-bearing premise
Fitness coaching is a suitable controlled yet challenging domain that intrinsically requires monitoring live user activity and immediate feedback.
What would settle it
If leading vision-language models achieve high performance on the QEVD benchmark without streaming changes, or if the proposed baseline fails to match the timing and appropriateness of human coach responses.
Figures


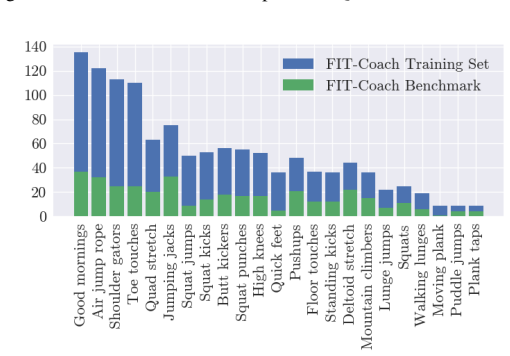
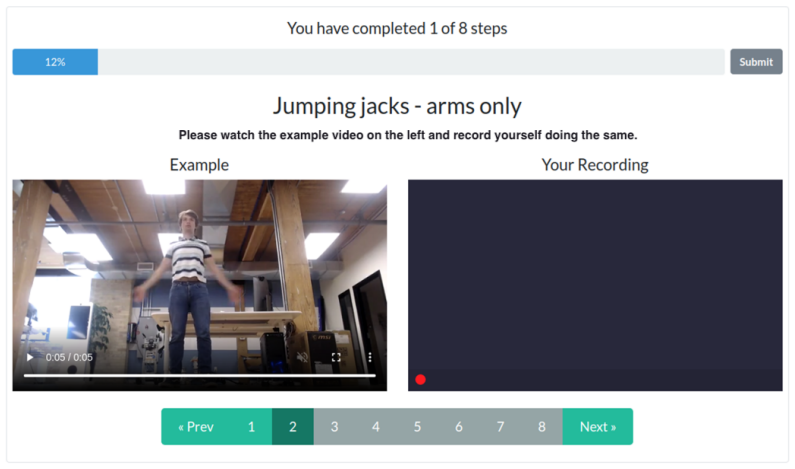
read the original abstract
Vision-language models have shown impressive progress in recent years. However, existing models are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions, where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time, are an open challenge. In this work, we present the QEVD benchmark and dataset, which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching -- a task which intrinsically requires monitoring live user activity and providing immediate feedback. The benchmark requires vision-language models to recognize complex human actions, identify possible mistakes, and provide appropriate feedback in real-time. Our experiments reveal the limitations of existing state-of-the-art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedback at the appropriate time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the QEVD benchmark and associated dataset for evaluating vision-language models on asynchronous, situated interactions in the domain of live fitness coaching. It claims that existing SOTA VLMs are limited to turn-based interactions, demonstrates their shortcomings via experiments on this benchmark (recognizing actions, identifying mistakes, and providing timely feedback), and proposes a simple end-to-end streaming baseline capable of responding asynchronously with appropriate feedback at the right time.
Significance. If the benchmark construction, dataset quality, and experimental results hold, this work offers a controlled yet realistic testbed for an important open challenge in situated AI. The domain choice is explicitly motivated as requiring live monitoring and immediate feedback. Credit is due for creating a new empirical benchmark and dataset focused on proactive, real-time interaction rather than turn-based prompting, along with a minimal baseline that directly targets the identified gap.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments reveal the limitations of existing state-of-the-art vision-language models' and that the baseline 'can respond asynchronously... at the appropriate time' is presented without any quantitative results, metrics, dataset statistics, or experimental details. This makes it impossible to evaluate whether the central empirical claims are supported.
- [Introduction / Benchmark description (inferred from abstract)] The manuscript positions fitness coaching as an effective testbed, but without the full methods section describing how action recognition, mistake identification, and timing of feedback are operationalized and measured (e.g., annotation protocol, temporal granularity, success criteria), it is unclear whether the benchmark actually isolates the asynchronous aspect or reduces to standard action recognition.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for acknowledging the potential value of the QEVD benchmark as a testbed for asynchronous situated interaction. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments reveal the limitations of existing state-of-the-art vision-language models' and that the baseline 'can respond asynchronously... at the appropriate time' is presented without any quantitative results, metrics, dataset statistics, or experimental details. This makes it impossible to evaluate whether the central empirical claims are supported.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. The full manuscript reports detailed experimental results comparing SOTA VLMs against the streaming baseline on the QEVD tasks. In revision we will update the abstract to include key dataset statistics (e.g., number of videos and action instances) and summary performance metrics that illustrate the identified limitations and the baseline's ability to produce timely asynchronous feedback. revision: yes
-
Referee: [Introduction / Benchmark description (inferred from abstract)] The manuscript positions fitness coaching as an effective testbed, but without the full methods section describing how action recognition, mistake identification, and timing of feedback are operationalized and measured (e.g., annotation protocol, temporal granularity, success criteria), it is unclear whether the benchmark actually isolates the asynchronous aspect or reduces to standard action recognition.
Authors: The full manuscript contains a methods section that specifies the annotation protocol, temporal granularity of the streams, and success criteria for evaluating when feedback should be issued. The benchmark isolates the asynchronous requirement by evaluating models on continuous video input where they must both recognize actions/mistakes and decide the appropriate moment to respond, rather than reacting only to explicit user turns. We will add an explicit cross-reference in the introduction to the methods section to make this distinction clearer. revision: partial
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical benchmark (QEVD) and dataset for asynchronous situated interaction in fitness coaching, demonstrates limitations of existing VLMs through experiments, and introduces a simple streaming baseline. No derivations, equations, fitted parameters presented as predictions, or self-citation chains are described in the abstract or setup. The central claims rest on empirical evaluation and domain motivation rather than any self-referential reduction or imported uniqueness theorem. The work is self-contained as a benchmark proposal without load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sense Core. https://github.com/quic/sense. [Online; accessed Oct-2024]
work page 2024
-
[2]
https://www.statista.com/topics/12564/home-fitness/ #topicOverview
Statista home fitness. https://www.statista.com/topics/12564/home-fitness/ #topicOverview. [Online; accessed Oct-2024]
work page 2024
-
[3]
AI@Meta. Llama 3 model card. https://github.com/meta-llama/llama3/blob/main/ MODEL_CARD.md. [Online; accessed Oct-2024]
work page 2024
-
[4]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkow...
work page 2022
-
[5]
Situated dialogue learning through procedural environment generation
Prithviraj Ammanabrolu, Renee Jia, and Mark O Riedl. Situated dialogue learning through procedural environment generation. In ACL, 2022
work page 2022
-
[6]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In ICCV, 2015
work page 2015
-
[7]
Butt, Keith Curtis, Yooyoung Lee, Jonathan G
George Awad, Asad A. Butt, Keith Curtis, Yooyoung Lee, Jonathan G. Fiscus, Afzal Godil, David Joy, Andrew Delgado, Alan F. Smeaton, Yvette Graham, Wessel Kraaij, Georges Quénot, João Magalhães, David Semedo, and Saverio G. Blasi. TRECVID 2018: Bench- marking video activity detection, video captioning and matching, video storytelling linking and video sear...
work page 2018
-
[8]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, 2021
work page 2021
-
[9]
METEOR: an automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In IEEvaluation@ACL, 2005
work page 2005
-
[10]
Can foundation models watch, talk and guide you step by step to make a cake? In EMNLP Findings, 2023
Yuwei Bao, Keunwoo Peter Yu, Yichi Zhang, Shane Storks, Itamar Bar-Yossef, Alexander De La Iglesia, Megan Su, Xiao-Lin Zheng, and Joyce Chai. Can foundation models watch, talk and guide you step by step to make a cake? In EMNLP Findings, 2023
work page 2023
-
[11]
Look, remember and reason: Visual reasoning with grounded rationales
Apratim Bhattacharyya, Sunny Panchal, Mingu Lee, Reza Pourreza, Pulkit Madan, and Roland Memisevic. Look, remember and reason: Visual reasoning with grounded rationales. In ICLR, 2024
work page 2024
-
[12]
Platform for situated intelligence
Dan Bohus, Sean Andrist, Ashley Feniello, Nick Saw, Mihai Jalobeanu, Pat Sweeney, Anne Loomis Thompson, and Eric Horvitz. Platform for situated intelligence. Technical report, Microsoft, 2021
work page 2021
-
[13]
Rodney A. Brooks. Intelligence without reason. In IJCAI, 1991
work page 1991
-
[14]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017
work page 2017
-
[15]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In NeurIPS, 2023
work page 2023
-
[16]
Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evange- los Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100. In IJCV, 2022
work page 2022
-
[17]
Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José M. F. Moura, Devi Parikh, and Dhruv Batra. Visual dialog. In CVPR, 2017. 11
work page 2017
-
[18]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009
work page 2009
-
[19]
Every picture tells a story: Generating sentences from images
Ali Farhadi, Mohsen Hejrati, Mohammad Amin Sadeghi, Peter Young, Cyrus Rashtchian, Julia Hockenmaier, and David Forsyth. Every picture tells a story: Generating sentences from images. In ECCV, 2010
work page 2010
-
[20]
Aifit: Automatic 3d human-interpretable feedback models for fitness training
Mihai Fieraru, Mihai Zanfir, Silviu Cristian Pirlea, Vlad Olaru, and Cristian Sminchisescu. Aifit: Automatic 3d human-interpretable feedback models for fitness training. In CVPR, 2021
work page 2021
-
[21]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “something some- thing” video database for learning and evaluating visual common sense. In ICCV, 2017
work page 2017
-
[22]
Ego4d: Around the world in 3, 000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Ro- hit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, et al. Ego4d: Around the...
work page 2022
-
[23]
Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Tri- antafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives. CoRR, abs/2311.18259, 2023
-
[24]
AGQA: A bench- mark for compositional spatio-temporal reasoning
Madeleine Grunde-McLaughlin, Ranjay Krishna, and Maneesh Agrawala. AGQA: A bench- mark for compositional spatio-temporal reasoning. In CVPR, 2021
work page 2021
-
[25]
Visual programming: Compositional visual reason- ing without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reason- ing without training. CoRR, abs/2211.11559, 2022
-
[26]
Activi- tynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activi- tynet: A large-scale video benchmark for human activity understanding. In CVPR, 2015
work page 2015
-
[27]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022
work page 2022
-
[28]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross B. Girshick. CLEVR: A diagnostic dataset for compositional language and elemen- tary visual reasoning. In CVPR, 2017
work page 2017
-
[30]
FIXMYPOSE: pose correc- tional captioning and retrieval
Hyounghun Kim, Abhay Zala, Graham Burri, and Mohit Bansal. FIXMYPOSE: pose correc- tional captioning and retrieval. In AAAI, 2021
work page 2021
-
[31]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Ross, João Carreira, Alexander V ostrikov, and Andrew Zisserman
Ang Li, Meghana Thotakuri, David A. Ross, João Carreira, Alexander V ostrikov, and Andrew Zisserman. The ava-kinetics localized human actions video dataset. CoRR, abs/2005.00214, 2020
-
[33]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. CoRR, abs/2311.17043, 2023. 12
-
[34]
Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo
Yuncheng Li, Yale Song, Liangliang Cao, Joel R. Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo. TGIF: A new dataset and benchmark on animated GIF description. In CVPR, 2016
work page 2016
-
[35]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. CoRR, abs/2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Chin-Yew Lin and Franz Josef Och. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In ACL, 2004
work page 2004
-
[37]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023
work page 2023
-
[38]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https: //llava-vl.github.io/blog/2024-01-30-llava-next/
work page 2024
-
[39]
G-eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, EMNLP, 2023
work page 2023
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Chameleon: Plug-and-play compositional reasoning with large lan- guage models
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-play compositional reasoning with large lan- guage models. CoRR, abs/2304.09842, 2023
-
[42]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Abdul Rasheed, Salman H. Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. CoRR, abs/2306.05424, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Something-else: Compositional action recognition with spatial-temporal interaction networks
Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu, Xiaolong Wang, and Trevor Darrell. Something-else: Compositional action recognition with spatial-temporal interaction networks. In CVPR, 2020
work page 2020
-
[44]
Is end-to-end learning enough for fitness activity recogni- tion? CoRR, abs/2305.08191, 2023
Antoine Mercier, Guillaume Berger, Sunny Panchal, Florian Dietrichkeit, Cornelius Böhm, Ingo Bax, and Roland Memisevic. Is end-to-end learning enough for fitness activity recogni- tion? CoRR, abs/2305.08191, 2023
-
[45]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In ICCV, 2019
work page 2019
-
[46]
Brown, Quanfu Fan, and Dan Gutfreund
Mathew Monfort, Carl V ondrick, Aude Oliva, Alex Andonian, Bolei Zhou, Kandan Ramakr- ishnan, Sarah Adel Bargal, Tom Yan, Lisa M. Brown, Quanfu Fan, and Dan Gutfreund. Mo- ments in time dataset: One million videos for event understanding. In IEEE PAMI, 2020
work page 2020
-
[47]
OpenAI. “Hello gpt-4o.”. https://openai.com/index/hello-gpt-4oâĄă. [Online; ac- cessed Oct-2024]
work page 2024
-
[48]
Sci- enceqa: A novel resource for question answering on scholarly articles
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhattacharyya. Sci- enceqa: A novel resource for question answering on scholarly articles. International Journal on Digital Libraries, 23(3):289–301, 2022
work page 2022
-
[49]
Assembly101: A large-scale multi-view video dataset for under- standing procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for under- standing procedural activities. In CVPR, 2022
work page 2022
-
[50]
NTU RGB+D: A large scale dataset for 3d human activity analysis
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. NTU RGB+D: A large scale dataset for 3d human activity analysis. In CVPR, 2016
work page 2016
-
[51]
Finegym: A hierarchical video dataset for fine-grained action understanding
Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. Finegym: A hierarchical video dataset for fine-grained action understanding. In CVPR, 2020. 13
work page 2020
-
[52]
Finegym: A hierarchical video dataset for fine-grained action understanding
Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. Finegym: A hierarchical video dataset for fine-grained action understanding. In CVPR, 2020
work page 2020
-
[53]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hug- ginggpt: Solving AI tasks with chatgpt and its friends in huggingface. CoRR, abs/2303.17580, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In ECCV, 2016
work page 2016
-
[55]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. CoRR, abs/1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[56]
ViperGPT: Visual Inference via Python Execution for Reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execu- tion for reasoning. CoRR, abs/2303.08128, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: A family of highly capable multimodal models. CoRR, abs/2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Chatvideo: A tracklet-centric multimodal and versatile video understanding system
Junke Wang, Dongdong Chen, Chong Luo, Xiyang Dai, Lu Yuan, Zuxuan Wu, and Yu-Gang Jiang. Chatvideo: A tracklet-centric multimodal and versatile video understanding system. CoRR, abs/2304.14407, 2023
-
[60]
Vatex: A large-scale, high-quality multilingual dataset for video-and-language research
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In ICCV, 2019
work page 2019
-
[61]
Holoassist: an egocentric human interaction dataset for interactive AI assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bo- hus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, and Marc Pollefeys. Holoassist: an egocentric human interaction dataset for interactive AI assistants in the real world. In ICCV, 2023
work page 2023
-
[62]
STAR: A benchmark for situated reasoning in real-world videos
Bo Wu, Shoubin Yu, Zhenfang Chen, Josh Tenenbaum, and Chuang Gan. STAR: A benchmark for situated reasoning in real-world videos. In NeurIPS, 2021
work page 2021
-
[63]
Advancing high-resolution video-language representation with large-scale video transcriptions
Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Advancing high-resolution video-language representation with large-scale video transcriptions. In CVPR, 2022
work page 2022
-
[64]
Socratic models: Composing zero-shot multimodal reasoning with language
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Marcin Choromanski, Adrian Wong, Ste- fan Welker, Federico Tombari, Aveek Purohit, Michael S Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence. Socratic models: Composing zero-shot multimodal reasoning with language. In ICLR, 2023
work page 2023
-
[65]
Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. In EMNLP - System Demonstrations , 2023
work page 2023
-
[66]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero- init attention. CoRR, abs/2303.16199, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with BERT. In ICLR, 2020
work page 2020
-
[68]
Llava-next: A strong zero-shot video understanding model, April
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April
-
[69]
URL https://llava-vl.github.io/blog/2024-04-30-llava-next-video/ . 14
work page 2024
-
[70]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multi- modal chain-of-thought reasoning in language models. CoRR, abs/2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Judging llm-as-a-judge with mt- bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt- bench and chatbot arena. In NeurIPS, 2023
work page 2023
-
[72]
What exercise is the user doing? Describe how they are doing it
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. In AAAI, 2018. 15 Appendix A Overview Here we provide: (1) Additional qualitative examples from Q EVD -FIT-300K and Q EVD -FIT– COACH; (2) Additional data collection and annotation details, including instructions provided to the crowd-worker...
work page 2018
-
[73]
<exercise_name> (<variant>) – where variant may describe the side of the body being used or describing the position of the body
-
[74]
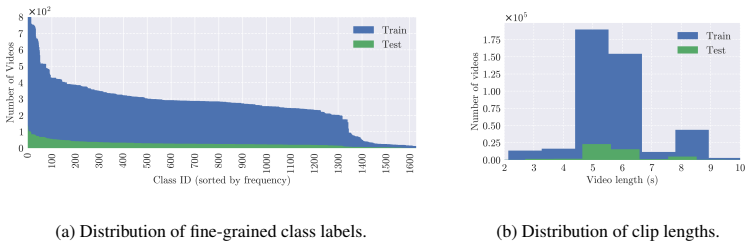
<exercise_name> For example: Templated name: spider man pushup Descriptive response: The user is doing spider man pushups. Templated name: lunges (left leg out in front) Descriptive response: The user is doing lunges with their left leg in front. 17 (a) Distribution of fine-grained class labels. (b) Distribution of clip lengths. Figure 6: Statistics of th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.