CRONOS: Enhancing Deep Learning with Scalable GPU Accelerated Convex Neural Networks
Pith reviewed 2026-05-25 08:47 UTC · model grok-4.3
The pith
CRONOS scales convex reformulations of two-layer neural networks to ImageNet while proving convergence to the global minimum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
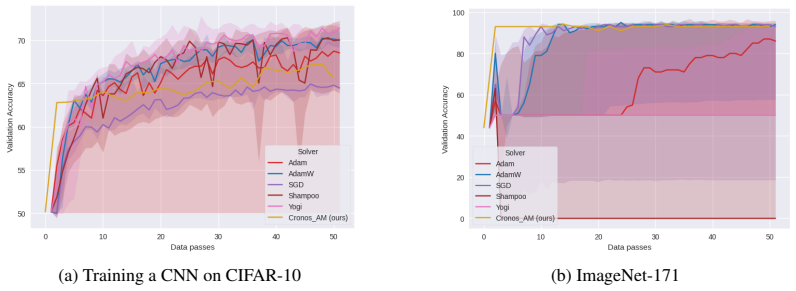
CRONOS solves the convex reformulation of two-layer networks at ImageNet scale with GPU acceleration in JAX and converges to the global minimum; CRONOS-AM extends the approach to multi-layer networks and yields validation accuracy matching or exceeding that of tuned deep learning optimizers on vision and language benchmarks.
What carries the argument
CRONOS algorithm for convex optimization of two-layer neural networks, extended via alternating minimization in CRONOS-AM to arbitrary multi-layer architectures.
If this is right
- Convex reformulations become usable for large-scale tasks previously limited to downsampled MNIST and CIFAR-10.
- Training of multi-layer networks can proceed with an explicit global-optimality guarantee.
- Validation accuracy on ImageNet and IMDb can equal or surpass that of predominant deep-learning optimizers.
- Arbitrary network architectures can be trained by alternating between convex steps and layer-wise updates.
Where Pith is reading between the lines
- The global-optimality guarantee may reduce sensitivity to random initialization compared with non-convex training.
- The same convex primitive could be tested on other high-dimensional modalities such as audio or tabular data.
- If the mild assumptions hold more broadly, the method offers a route to certify optimality for deeper convex relaxations.
Load-bearing premise
The mild assumptions that guarantee CRONOS converges to the global minimum of the convex reformulation continue to hold at ImageNet scale.
What would settle it
Running CRONOS-AM on ImageNet and observing validation accuracy that falls materially below the best tuned standard optimizers would falsify the claimed practical performance.
Figures







read the original abstract
We introduce the CRONOS algorithm for convex optimization of two-layer neural networks. CRONOS is the first algorithm capable of scaling to high-dimensional datasets such as ImageNet, which are ubiquitous in modern deep learning. This significantly improves upon prior work, which has been restricted to downsampled versions of MNIST and CIFAR-10. Taking CRONOS as a primitive, we then develop a new algorithm called CRONOS-AM, which combines CRONOS with alternating minimization, to obtain an algorithm capable of training multi-layer networks with arbitrary architectures. Our theoretical analysis proves that CRONOS converges to the global minimum of the convex reformulation under mild assumptions. In addition, we validate the efficacy of CRONOS and CRONOS-AM through extensive large-scale numerical experiments with GPU acceleration in JAX. Our results show that CRONOS-AM can obtain comparable or better validation accuracy than predominant tuned deep learning optimizers on vision and language tasks with benchmark datasets such as ImageNet and IMDb. To the best of our knowledge, CRONOS is the first algorithm which utilizes the convex reformulation to enhance performance on large-scale learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CRONOS algorithm for convex optimization of two-layer neural networks, claiming it scales to high-dimensional datasets such as ImageNet (unlike prior work limited to downsampled MNIST/CIFAR-10). It develops CRONOS-AM by combining CRONOS with alternating minimization to train multi-layer networks of arbitrary architecture. The manuscript asserts a theoretical proof that CRONOS converges to the global minimum of the convex reformulation under mild assumptions, and reports empirical results (via JAX GPU acceleration) showing CRONOS-AM achieves comparable or better validation accuracy than tuned deep learning optimizers on ImageNet and IMDb tasks. It positions CRONOS as the first use of convex reformulation to enhance large-scale learning performance.
Significance. If the scalability, convergence guarantee, and empirical competitiveness hold, the work would be significant for bridging convex optimization techniques with practical deep learning on large-scale vision and language tasks, offering potential global optimality where standard non-convex training does not. The explicit use of GPU-accelerated JAX implementation and the extension to arbitrary multi-layer architectures via alternating minimization are noted strengths for practical adoption.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical analysis section: the central claim that CRONOS converges to the global minimum under mild assumptions is load-bearing for both the theoretical contribution and the asserted practical advantage over standard optimizers. No derivation steps, explicit statement of the mild assumptions, or discussion of whether they remain valid for the convex reformulation at ImageNet scale are supplied, preventing verification of the guarantee.
- [Abstract] Abstract: the claim that CRONOS is the first algorithm to scale convex reformulation to high-dimensional datasets such as ImageNet (and that CRONOS-AM obtains comparable or better accuracy than predominant optimizers) is load-bearing for the novelty and impact assertions. Without details on the convex reformulation formulation, prior-work comparisons, or experimental controls (e.g., dataset preprocessing, error bars, or hyperparameter tuning protocols), the scalability and performance claims cannot be assessed.
minor comments (1)
- [Experiments] The abstract references extensive large-scale numerical experiments with GPU acceleration in JAX but supplies no dataset details, error-bar information, or specific benchmark configurations; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical analysis section: the central claim that CRONOS converges to the global minimum under mild assumptions is load-bearing for both the theoretical contribution and the asserted practical advantage over standard optimizers. No derivation steps, explicit statement of the mild assumptions, or discussion of whether they remain valid for the convex reformulation at ImageNet scale are supplied, preventing verification of the guarantee.
Authors: We agree that the theoretical analysis would benefit from greater explicitness to enable verification. In the revised manuscript, we will explicitly enumerate the mild assumptions, include a concise sketch of the key derivation steps supporting the global convergence result, and add a paragraph discussing why the assumptions remain valid at ImageNet scale (they depend on convexity of the reformulation and boundedness of activations rather than input dimensionality). revision: yes
-
Referee: [Abstract] Abstract: the claim that CRONOS is the first algorithm to scale convex reformulation to high-dimensional datasets such as ImageNet (and that CRONOS-AM obtains comparable or better accuracy than predominant optimizers) is load-bearing for the novelty and impact assertions. Without details on the convex reformulation formulation, prior-work comparisons, or experimental controls (e.g., dataset preprocessing, error bars, or hyperparameter tuning protocols), the scalability and performance claims cannot be assessed.
Authors: The body of the manuscript already supplies these details: the convex reformulation appears in Section 3, prior-work comparisons are in the introduction and related-work section, and experimental protocols (preprocessing, standard deviations over multiple seeds, and hyperparameter search) are described in Section 4. To improve accessibility from the abstract, we will revise the abstract to briefly reference the experimental controls and add a short summary paragraph in the introduction. We maintain the novelty claim on the basis of the reported ImageNet-scale results, which prior convex methods did not achieve. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an algorithmic contribution (CRONOS for convex reformulation of two-layer networks, extended via CRONOS-AM) with a convergence proof under stated mild assumptions and empirical validation on large-scale tasks. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work are exhibited in the text. The derivation chain is presented as independent theoretical analysis plus experimental outcomes rather than reductions to inputs by construction, satisfying the criteria for a self-contained result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild assumptions under which CRONOS converges to the global minimum of the convex reformulation
Reference graph
Works this paper leans on
-
[1]
Lower bounds for non-convex stochastic optimization
Yossi Arjevani, Yair Carmon, John C Duchi, Dylan J Foster, Nathan Srebro, and Blake Woodworth. Lower bounds for non-convex stochastic optimization. Mathematical Programming, 199 0 (1-2): 0 165--214, 2023
work page 2023
-
[2]
Blendenpik: Supercharging lapack's least-squares solver
Haim Avron, Petar Maymounkov, and Sivan Toledo. Blendenpik: Supercharging lapack's least-squares solver. SIAM Journal on Scientific Computing, 32 0 (3): 0 1217--1236, 2010
work page 2010
-
[3]
Sharp analysis of low-rank kernel matrix approximations
Francis Bach. Sharp analysis of low-rank kernel matrix approximations. In Conference on Learning Theory, pages 185--209. PMLR, 2013
work page 2013
-
[4]
Yatong Bai, Tanmay Gautam, and Somayeh Sojoudi. Efficient global optimization of two-layer relu networks: Quadratic-time algorithms and adversarial training. SIAM Journal on Mathematics of Data Science, 5 0 (2): 0 446--474, 2023
work page 2023
-
[5]
Yoshua Bengio, Nicolas Roux, Pascal Vincent, Olivier Delalleau, and Patrice Marcotte. Convex Neural Networks . Advances in Neural Information Processing Systems, 18, 2005
work page 2005
-
[6]
Training a 3-node neural network is np-complete
Avrim Blum and Ronald Rivest. Training a 3-node neural network is np-complete. Advances in Neural Information Processing Systems, 1, 1988
work page 1988
-
[7]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3: 0 1--122, 2011
work page 2011
-
[8]
JAX : composable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/google/jax
work page 2018
-
[9]
Pawe Budzianowski and Ivan Vuli \'c . Hello, it's gpt-2--how can i help you? towards the use of pretrained language models for task-oriented dialogue systems. arXiv preprint arXiv:1907.05774, 2019
-
[10]
On lazy training in differentiable programming
Lenaic Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable programming. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[11]
Learning-rate-free learning by d-adaptation
Aaron Defazio and Konstantin Mishchenko. Learning-rate-free learning by d-adaptation. In International Conference on Machine Learning, pages 7449--7479. PMLR, 2023
work page 2023
-
[12]
On the global and linear convergence of the generalized alternating direction method of multipliers
Wei Deng and Wotao Yin. On the global and linear convergence of the generalized alternating direction method of multipliers. Journal of Scientific Computing, 66: 0 889--916, 2016
work page 2016
-
[13]
Precise expressions for random projections: Low-rank approximation and randomized newton
Michal Derezinski, Feynman T Liang, Zhenyu Liao, and Michael W Mahoney. Precise expressions for random projections: Low-rank approximation and randomized newton. Advances in Neural Information Processing Systems, 33: 0 18272--18283, 2020
work page 2020
-
[14]
Newton-less: Sparsification without trade-offs for the sketched newton update
Michal Derezinski, Jonathan Lacotte, Mert Pilanci, and Michael W Mahoney. Newton-less: Sparsification without trade-offs for the sketched newton update. Advances in Neural Information Processing Systems, 34: 0 2835--2847, 2021
work page 2021
-
[15]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Genios: an (almost) second-order operator-splitting solver for large-scale convex optimization
Theo Diamandis, Zachary Frangella, Shipu Zhao, Bartolomeo Stellato, and Madeleine Udell. Genios: an (almost) second-order operator-splitting solver for large-scale convex optimization. arXiv preprint arXiv:2310.08333, 2023
-
[17]
On the numerical solution of heat conduction problems in two and three space variables
Jim Douglas and Henry H Rachford. On the numerical solution of heat conduction problems in two and three space variables. Transactions of the American Mathematical Society, 82 0 (2): 0 421--439, 1956
work page 1956
-
[18]
Jonathan Eckstein and Dimitri P Bertsekas. On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators. Mathematical programming, 55: 0 293--318, 1992
work page 1992
-
[19]
Randomized Nystr \"o m preconditioning
Zachary Frangella, Joel A Tropp, and Madeleine Udell. Randomized Nystr \"o m preconditioning. SIAM Journal on Matrix Analysis and Applications, 44 0 (2): 0 718--752, 2023 a
work page 2023
-
[20]
On the (linear) convergence of generalized newton inexact admm
Zachary Frangella, Shipu Zhao, Theo Diamandis, Bartolomeo Stellato, and Madeleine Udell. On the (linear) convergence of generalized newton inexact admm. arXiv preprint arXiv:2302.03863, 2023 b
-
[21]
Escaping from saddle points—online stochastic gradient for tensor decomposition
Rong Ge, Furong Huang, Chi Jin, and Yang Yuan. Escaping from saddle points—online stochastic gradient for tensor decomposition. In Conference on Learning Theory, pages 797--842. PMLR, 2015
work page 2015
-
[22]
Linearized two-layers neural networks in high dimension
Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Linearized two-layers neural networks in high dimension. The Annals of Statistics, 49 0 (2): 0 1029--1054, 2021
work page 2021
-
[23]
Gene H Golub and Charles F Van Loan. Matrix Computations . Johns Hopkins University Press, 2013
work page 2013
-
[24]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. In International Conference on Machine Learning, pages 1842--1850. PMLR, 2018
work page 2018
-
[25]
Neural Tangent Kernel : Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Cl \'e ment Hongler. Neural Tangent Kernel : Convergence and generalization in neural networks. Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[26]
Convex relaxations of relu neural networks approximate global optima in polynomial time
Sungyoon Kim and Mert Pilanci. Convex relaxations of relu neural networks approximate global optima in polynomial time. In International Conference on Machine Learning, 2024
work page 2024
-
[27]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv e-prints, pages arXiv--1412, 2014
work page 2014
-
[28]
Convolutional deep belief networks on cifar-10
Alex Krizhevsky and Geoff Hinton. Convolutional deep belief networks on cifar-10. Unpublished manuscript, 40 0 (7): 0 1--9, 2010
work page 2010
-
[29]
Effective dimension adaptive sketching methods for faster regularized least-squares optimization
Jonathan Lacotte and Mert Pilanci. Effective dimension adaptive sketching methods for faster regularized least-squares optimization. Advances in Neural Information Processing Systems, 33: 0 19377--19387, 2020
work page 2020
-
[30]
Local convergence properties of douglas--rachford and alternating direction method of multipliers
Jingwei Liang, Jalal Fadili, and Gabriel Peyr \'e . Local convergence properties of douglas--rachford and alternating direction method of multipliers. Journal of Optimization Theory and Applications, 172: 0 874--913, 2017
work page 2017
-
[31]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Randomized algorithms for matrices and data
Michael W Mahoney et al. Randomized algorithms for matrices and data. Foundations and Trends in Machine Learning , 3 0 (2): 0 123--224, 2011
work page 2011
-
[33]
Randomized numerical linear algebra: Foundations and algorithms
Per-Gunnar Martinsson and Joel A Tropp. Randomized numerical linear algebra: Foundations and algorithms. Acta Numerica, 29: 0 403--572, 2020
work page 2020
-
[34]
Lsrn: A parallel iterative solver for strongly over-or underdetermined systems
Xiangrui Meng, Michael A Saunders, and Michael W Mahoney. Lsrn: A parallel iterative solver for strongly over-or underdetermined systems. SIAM Journal on Scientific Computing, 36 0 (2): 0 C95--C118, 2014
work page 2014
-
[35]
Aaron Mishkin, Arda Sahiner, and Mert Pilanci. Fast convex optimization for two-layer relu networks: Equivalent model classes and cone decompositions. In International Conference on Machine Learning, pages 15770--15816. PMLR, 2022
work page 2022
-
[36]
Gradient methods for minimizing composite functions
Yu Nesterov. Gradient methods for minimizing composite functions. Mathematical Programming, 140 0 (1): 0 125--161, 2013
work page 2013
-
[37]
Overhead mnist: A benchmark satellite dataset
David Noever and Samantha E Miller Noever. Overhead mnist: A benchmark satellite dataset. arXiv preprint arXiv:2102.04266, 2021
-
[38]
Stochastic alternating direction method of multipliers
Hua Ouyang, Niao He, Long Tran, and Alexander Gray. Stochastic alternating direction method of multipliers. In International Conference on Machine Learning, pages 80--88. PMLR, 2013
work page 2013
-
[39]
An accelerated linearized alternating direction method of multipliers
Yuyuan Ouyang, Yunmei Chen, Guanghui Lan, and Eduardo Pasiliao. An accelerated linearized alternating direction method of multipliers. SIAM Journal on Imaging Sciences, 8 0 (1): 0 644--681, 2015
work page 2015
-
[40]
Adaptive restart for accelerated gradient schemes
Brendan O’donoghue and Emmanuel Candes. Adaptive restart for accelerated gradient schemes. Foundations of Computational Mathematics , 15: 0 715--732, 2015
work page 2015
-
[41]
Conic optimization via operator splitting and homogeneous self-dual embedding
Brendan O’donoghue, Eric Chu, Neal Parikh, and Stephen Boyd. Conic optimization via operator splitting and homogeneous self-dual embedding. Journal of Optimization Theory and Applications, 169: 0 1042--1068, 2016
work page 2016
-
[42]
Mert Pilanci and Tolga Ergen. Neural networks are convex regularizers: Exact polynomial-time convex optimization formulations for two-layer networks. In International Conference on Machine Learning, pages 7695--7705. PMLR, 2020
work page 2020
-
[43]
Newton sketch: A near linear-time optimization algorithm with linear-quadratic convergence
Mert Pilanci and Martin J Wainwright. Newton sketch: A near linear-time optimization algorithm with linear-quadratic convergence. SIAM Journal on Optimization, 27 0 (1): 0 205--245, 2017
work page 2017
-
[44]
Weighted sums of Random Kitchen Sinks : Replacing minimization with randomization in learning
Ali Rahimi and Benjamin Recht. Weighted sums of Random Kitchen Sinks : Replacing minimization with randomization in learning. Advances in Neural Information Processing Systems, 21, 2008
work page 2008
-
[45]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In International conference on machine learning, pages 5389--5400. PMLR, 2019
work page 2019
-
[46]
Scaling laws for deep learning
Jonathan S Rosenfeld. Scaling laws for deep learning. arXiv preprint arXiv:2108.07686, 2021
-
[47]
Jaxbind: Bind any function to jax
Jakob Roth, Martin Reinecke, and Gordian Edenhofer. Jaxbind: Bind any function to jax. arXiv preprint arXiv:2403.08847, 2024
-
[48]
Large-scale convex optimization: algorithms & analyses via monotone operators
Ernest K Ryu and Wotao Yin. Large-scale convex optimization: algorithms & analyses via monotone operators. Cambridge University Press, 2022
work page 2022
-
[49]
Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball
Othmane Sebbouh, Robert M Gower, and Aaron Defazio. Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball. In Conference on Learning Theory, pages 3935--3971. PMLR, 2021
work page 2021
-
[50]
Osqp: An operator splitting solver for quadratic programs
Bartolomeo Stellato, Goran Banjac, Paul Goulart, Alberto Bemporad, and Stephen Boyd. Osqp: An operator splitting solver for quadratic programs. Mathematical Programming Computation, 12 0 (4): 0 637--672, 2020
work page 2020
-
[51]
Fixed-rank approximation of a positive-semidefinite matrix from streaming data
Joel A Tropp, Alp Yurtsever, Madeleine Udell, and Volkan Cevher. Fixed-rank approximation of a positive-semidefinite matrix from streaming data. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[52]
Streaming low-rank matrix approximation with an application to scientific simulation
Joel A Tropp, Alp Yurtsever, Madeleine Udell, and Volkan Cevher. Streaming low-rank matrix approximation with an application to scientific simulation. SIAM Journal on Scientific Computing, 41 0 (4): 0 A2430--A2463, 2019
work page 2019
-
[53]
Madeleine Udell and Alex Townsend. Why are big data matrices approximately low rank? SIAM Journal on Mathematics of Data Science, 1 0 (1): 0 144--160, 2019
work page 2019
-
[54]
High-dimensional Statistics: A non-asymptotic viewpoint, volume 48
Martin J Wainwright. High-dimensional Statistics: A non-asymptotic viewpoint, volume 48. Cambridge University Press, 2019
work page 2019
-
[55]
Sketching as a tool for numerical linear algebra
David P Woodruff et al. Sketching as a tool for numerical linear algebra. Foundations and Trends in Theoretical Computer Science , 10 0 (1--2): 0 1--157, 2014
work page 2014
-
[56]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[57]
Adahessian: An adaptive second order optimizer for machine learning
Zhewei Yao, Amir Gholami, Sheng Shen, Mustafa Mustafa, Kurt Keutzer, and Michael Mahoney. Adahessian: An adaptive second order optimizer for machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10665--10673, 2021
work page 2021
-
[58]
Model selection and estimation in regression with grouped variables
Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society Series B: Statistical Methodology, 68 0 (1): 0 49--67, 2006
work page 2006
-
[59]
Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. Discerning the linear convergence of admm for structured convex optimization through the lens of variational analysis. The Journal of Machine Learning Research, 21 0 (1): 0 3182--3256, 2020
work page 2020
-
[60]
Adaptive methods for nonconvex optimization
Manzil Zaheer, Sashank Reddi, Devendra Sachan, Satyen Kale, and Sanjiv Kumar. Adaptive methods for nonconvex optimization. Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[61]
Nysadmm: faster composite convex optimization via low-rank approximation
Shipu Zhao, Zachary Frangella, and Madeleine Udell. Nysadmm: faster composite convex optimization via low-rank approximation. In International Conference on Machine Learning, pages 26824--26840. PMLR, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.