Dual-Head Knowledge Distillation: Enhancing Logits Utilization with an Auxiliary Head
Pith reviewed 2026-05-23 17:21 UTC · model grok-4.3
The pith
Splitting the final classifier into two heads lets logit-level and probability-level losses both improve the backbone without conflicting in the head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When logit-level and probability-level losses are applied to the same linear classifier, their gradients contradict each other inside that classifier, causing its collapse and overall performance loss; the gradients show no such conflict inside the backbone. Dual-head knowledge distillation therefore partitions the linear classifier into two independent classification heads, each responsible for one loss, thereby preserving the beneficial effects of both losses on the backbone while eliminating the adverse influence on the classification head.
What carries the argument
Dual-head architecture that partitions the single linear classifier into two separate classification heads, one assigned to the logit-level loss and one to the probability-level loss.
If this is right
- The backbone receives additive benefits from both losses rather than a compromised compromise.
- The classification head remains stable and does not collapse under the combined training signal.
- Student accuracy exceeds that of either loss used in isolation or of standard probability-only distillation.
- The separation works for any pair of logit-level and probability-level distillation objectives.
Where Pith is reading between the lines
- The same head-separation idea may resolve gradient conflicts in other multi-loss training regimes beyond distillation.
- Neural-collapse analysis could be used to decide when architectural splits are needed rather than loss re-weighting.
- One could test whether more than two heads, or heads that are dynamically allocated, yield further gains on harder tasks.
Load-bearing premise
The observed performance drop from combining the two losses is caused by gradient contradictions inside the shared linear classifier, and separating the heads removes this conflict without creating new optimization or generalization problems.
What would settle it
Train a dual-head model on the same data and losses; if its accuracy is no higher than a single-head model that combines both losses, or if direct gradient computation on the head still shows contradiction after separation, the central claim is false.
Figures




read the original abstract
Traditional knowledge distillation focuses on aligning the student's predicted probabilities with both ground-truth labels and the teacher's predicted probabilities. However, the transition to predicted probabilities from logits would obscure certain indispensable information. To address this issue, it is intuitive to additionally introduce a logit-level loss function as a supplement to the widely used probability-level loss function, for exploiting the latent information of logits. Unfortunately, we empirically find that the amalgamation of the newly introduced logit-level loss and the previous probability-level loss will lead to performance degeneration, even trailing behind the performance of employing either loss in isolation. We attribute this phenomenon to the collapse of the classification head, which is verified by our theoretical analysis based on the neural collapse theory. Specifically, the gradients of the two loss functions exhibit contradictions in the linear classifier yet display no such conflict within the backbone. Drawing from the theoretical analysis, we propose a novel method called dual-head knowledge distillation, which partitions the linear classifier into two classification heads responsible for different losses, thereby preserving the beneficial effects of both losses on the backbone while eliminating adverse influences on the classification head. Extensive experiments validate that our method can effectively exploit the information inside the logits and achieve superior performance against state-of-the-art counterparts. Our code is available at: https://github.com/penghui-yang/DHKD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that combining logit-level and probability-level losses in knowledge distillation causes performance degeneration due to gradient contradictions within the linear classifier (but not the backbone), as derived from neural collapse theory. To resolve this, they introduce Dual-Head Knowledge Distillation (DHKD), which partitions the classifier into two heads (one per loss type) while sharing the backbone, thereby retaining beneficial effects on features while avoiding head collapse. Extensive experiments on standard benchmarks reportedly outperform SOTA KD methods, with code released.
Significance. If the result holds, the work offers a practical mechanism to better exploit logit information in KD without loss conflicts, backed by a neural-collapse-motivated analysis of gradient interactions. The public code release is a clear strength for reproducibility. This could inform multi-loss training designs in classification and distillation settings more broadly.
major comments (3)
- [Theoretical analysis section] Theoretical analysis section: The gradient-contradiction derivation assumes the neural collapse regime (collapsed within-class variability and equiangular class means) holds under simultaneous logit+probability losses on a single head. No NC metrics (e.g., NC1 within-class variability or NC2 class-mean angles) are reported for the combined-loss single-head case, which is required to confirm the claimed contradictions are the operative mechanism rather than other optimization effects.
- [§4 (method) and experiments] §4 (method) and experiments: The dual-head construction separates losses on the classifier but applies both heads' gradients to the shared backbone. The paper does not report whether this introduces new inconsistencies (e.g., conflicting feature demands between heads) or measure backbone gradient alignment before/after the split, which is load-bearing for the claim that separation fully isolates the problem.
- [Experiments section, main results table] Experiments section, main results table: Performance gains are shown versus baselines, but without ablations that isolate the auxiliary head's contribution from other implementation choices (e.g., loss weighting, head initialization), it is difficult to attribute gains specifically to elimination of the claimed classifier contradictions.
minor comments (2)
- [Notation] Notation for the two loss functions (logit-level vs. probability-level) should be defined once and used consistently; current usage mixes symbols across sections.
- [Figures] Figure captions for the dual-head diagram could explicitly label which head receives which loss to improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the revisions that will be incorporated to strengthen the theoretical validation and experimental analysis.
read point-by-point responses
-
Referee: Theoretical analysis section: The gradient-contradiction derivation assumes the neural collapse regime (collapsed within-class variability and equiangular class means) holds under simultaneous logit+probability losses on a single head. No NC metrics (e.g., NC1 within-class variability or NC2 class-mean angles) are reported for the combined-loss single-head case, which is required to confirm the claimed contradictions are the operative mechanism rather than other optimization effects.
Authors: We appreciate this observation. The derivation is performed under the standard neural collapse assumptions to isolate the source of gradient contradictions. To empirically confirm that the NC regime is active in the single-head combined-loss setting and that the contradictions are the operative mechanism, we will compute and report NC1 and NC2 metrics for this case in the revised manuscript. revision: yes
-
Referee: §4 (method) and experiments: The dual-head construction separates losses on the classifier but applies both heads' gradients to the shared backbone. The paper does not report whether this introduces new inconsistencies (e.g., conflicting feature demands between heads) or measure backbone gradient alignment before/after the split, which is load-bearing for the claim that separation fully isolates the problem.
Authors: We thank the referee for highlighting this aspect. Our analysis shows no gradient contradictions within the backbone, and the observed performance gains are consistent with the absence of new detrimental inconsistencies. To provide direct supporting evidence, we will add measurements of backbone gradient alignment (e.g., cosine similarity between gradients from each head) before and after the split in the revised version. revision: yes
-
Referee: Experiments section, main results table: Performance gains are shown versus baselines, but without ablations that isolate the auxiliary head's contribution from other implementation choices (e.g., loss weighting, head initialization), it is difficult to attribute gains specifically to elimination of the claimed classifier contradictions.
Authors: We agree that targeted ablations are necessary to isolate the contribution of the dual-head design. In the revised manuscript we will add ablation experiments that vary auxiliary-head initialization and loss-weighting hyperparameters, thereby demonstrating that the gains arise primarily from resolving the classifier-level contradictions rather than from ancillary implementation details. revision: yes
Circularity Check
No circularity: theoretical analysis and method proposal are independent of inputs
full rationale
The paper derives the dual-head method from an original gradient-contradiction analysis under neural collapse assumptions applied to combined logit and probability losses. This analysis is presented directly in the manuscript (not reduced to prior self-citations or fitted parameters) and leads to a separable-head architecture whose performance is then tested empirically on standard benchmarks. No self-definitional equations, fitted-input predictions, or load-bearing self-citation chains appear in the derivation. External neural-collapse references are independent prior work and do not create circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural collapse theory explains the observed gradient contradictions between logit-level and probability-level losses within the linear classifier.
invented entities (1)
-
Auxiliary classification head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rich Caruana. 1997. Multitask Learning. Machine Learning (1997)
work page 1997
-
[2]
Defang Chen, Jian-Ping Mei, Hailin Zhang, Can Wang, Yan Feng, and Chun Chen
-
[3]
In Proceedings of the Conference on Computer Vision and Pattern Recognition
Knowledge distillation with the reused teacher classifier. In Proceedings of the Conference on Computer Vision and Pattern Recognition
-
[4]
Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. 2021. Distilling Knowledge via Knowledge Review. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2021
-
[5]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Ima- geNet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2009
-
[6]
Cong Fang, Hangfeng He, Qi Long, and Weijie J Su. 2021. Exploring deep neu- ral networks via layer-peeled model: Minority collapse in imbalanced training. Proceedings of the National Academy of Sciences (2021)
work page 2021
-
[7]
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. 2021. YOLOX: Exceeding YOLO Series in 2021. arXiv preprint arXiv:2107.08430 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Ziyao Guo, Haonan Yan, Hui Li, and Xiaodong Lin. 2023. Class attention transfer based knowledge distillation. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2023
-
[9]
Gunshi Gupta, Karmesh Yadav, and Liam Paull. 2020. Look-ahead meta learning for continual learning. In Advances in Neural Information Processing Systems
work page 2020
-
[10]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2016
-
[11]
Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, and Jin Young Choi. 2019. A comprehensive overhaul of feature distillation. In Proceedings of the International Conference on Computer Vision
work page 2019
-
[12]
Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. 2015. Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Tao Huang, Shan You, Fei Wang, Chen Qian, and Chang Xu. 2022. Knowledge distillation from a stronger teacher. In Advances in Neural Information Processing Systems
work page 2022
-
[14]
Wenlong Ji, Yiping Lu, Yiliang Zhang, Zhun Deng, and Weijie J Su. 2022. An unconstrained layer-peeled perspective on neural collapse. In Proceedings of the International Conference on Learning Representations
work page 2022
-
[15]
Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. Multi-task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2018
-
[16]
Jangho Kim, SeongUk Park, and Nojun Kwak. 2018. Paraphrasing complex net- work: Network compression via factor transfer. InAdvances in Neural Information Processing Systems
work page 2018
-
[17]
Taehyeon Kim, Jaehoon Oh, NakYil Kim, Sangwook Cho, and Se-Young Yun
-
[18]
In Proceedings of the International Joint Conference on Artificial Intelligence
Comparing kullback-leibler divergence and mean squared error loss in knowledge distillation. In Proceedings of the International Joint Conference on Artificial Intelligence
-
[19]
Animesh Koratana, Daniel Kang, Peter Bailis, and Matei Zaharia. 2019. Lit: Learned intermediate representation training for model compression. In Proceed- ings of the International Conference on Machine Learning
work page 2019
-
[20]
Alex Krizhevsky and Geoffrey Hinton. 2009. Learning multiple layers of features from tiny images. (2009)
work page 2009
-
[21]
Lujun Li. 2022. Self-regulated feature learning via teacher-free feature distillation. In Proceedings of the European Conference on Computer Vision
work page 2022
-
[22]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Fo- cal Loss for Dense Object Detection. InProceedings of the International Conference on Computer Vision
work page 2017
-
[23]
Xiaolong Liu, Lujun Li, Chao Li, and Anbang Yao. 2023. NORM: Knowledge Distil- lation via N-to-One Representation Matching. In Proceedings of the International Conference on Learning Representations
work page 2023
-
[24]
Jianfeng Lu and Stefan Steinerberger. 2022. Neural collapse under cross-entropy loss. Applied and Computational Harmonic Analysis (2022)
work page 2022
-
[25]
Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. 2018. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision
work page 2018
-
[26]
Roy Miles and Krystian Mikolajczyk. 2024. Understanding the role of the projector in knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence
work page 2024
-
[27]
Vardan Papyan, XY Han, and David L Donoho. 2020. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences (2020)
work page 2020
-
[28]
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. 2019. Relational Knowledge Distillation. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2019
-
[29]
Nikolaos Passalis and Anastasios Tefas. 2018. Learning Deep Representations with Probabilistic Knowledge Transfer. In Proceedings of the European Conference on Computer Vision
work page 2018
-
[30]
Alexandre Rame, Corentin Dancette, and Matthieu Cord. 2022. Fishr: Invariant Gradient Variances for Out-of-Distribution Generalization. In Proceedings of the International Conference on Machine Learning
work page 2022
-
[31]
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. 2015. Fitnets: Hints for Thin Deep Nets. In Proceedings of the International Conference on Learning Representations
work page 2015
-
[32]
Ismail Elezi Roy Miles and Jiankang Deng. 2024. VKD: Improving Knowledge Distillation using Orthogonal Projections. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2024
-
[33]
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang- Chieh Chen. 2018. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2018
-
[34]
Karen Simonyan and Andrew Zisserman. 2015. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations
work page 2015
-
[35]
Yonglong Tian, Dilip Krishnan, and Phillip Isola. 2019. Contrastive Represen- tation Distillation. In Proceedings of the International Conference on Learning Representations
work page 2019
-
[36]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research (2008)
work page 2008
- [37]
-
[38]
Stephan Wojtowytsch Weinan E. 2022. On the emergence of simplex symmetry in the final and penultimate layers of neural network classifiers. In Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference . KDD ’25, August 3–7, 2025, Toronto, ON, Canada Penghui Yang, Chen-Chen Zong, Sheng-Jun Huang, Lei Feng, and Bo An
work page 2022
-
[39]
Yue Wu, Yinpeng Chen, Lu Yuan, Zicheng Liu, Lijuan Wang, Hongzhi Li, and Yun Fu. 2020. Rethinking Classification and Localization for Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2020
-
[40]
Penghui Yang, Ming-Kun Xie, Chen-Chen Zong, Lei Feng, Gang Niu, Masashi Sugiyama, and Sheng-Jun Huang. 2023. Multi-Label Knowledge Distillation. In Proceedings of the International Conference on Computer Vision
work page 2023
-
[41]
Yibo Yang, Shixiang Chen, Xiangtai Li, Liang Xie, Zhouchen Lin, and Dacheng Tao. 2022. Inducing Neural Collapse in Imbalanced Learning: Do We Really Need a Learnable Classifier at the End of Deep Neural Network?. InAdvances in Neural Information Processing Systems
work page 2022
-
[42]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient surgery for multi-task learning. In Advances in Neural Information Processing Systems
work page 2020
-
[43]
Sergey Zagoruyko and Nikos Komodakis. 2016. Wide Residual Networks. In Proceedings of the British Machine Vision Conference
work page 2016
-
[44]
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. 2018. Shufflenet: An ex- tremely efficient convolutional neural network for mobile devices. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2018
-
[45]
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. 2018. Deep Mutual Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2018
-
[46]
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. 2022. Decoupled Knowledge Distillation. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2022
-
[47]
Kaixiang Zheng and En-Hui Yang. 2024. Knowledge Distillation Based on Trans- formed Teacher Matching. InProceedings of the International Conference on Learn- ing Representations
work page 2024
-
[48]
Qingping Zheng, Jiankang Deng, Zheng Zhu, Ying Li, and Stefanos Zafeiriou. 2022. Decoupled Multi-task Learning with Cyclical Self-regulation for Face Parsing. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2022
-
[49]
Boyan Zhou, Quan Cui, Xiu-Shen Wei, and Zhao-Min Chen. 2020. BBN: Bilateral- branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition
work page 2020
-
[50]
Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. 2023. Prompt- aligned gradient for prompt tuning. In Proceedings of the International Conference on Computer Vision
work page 2023
-
[51]
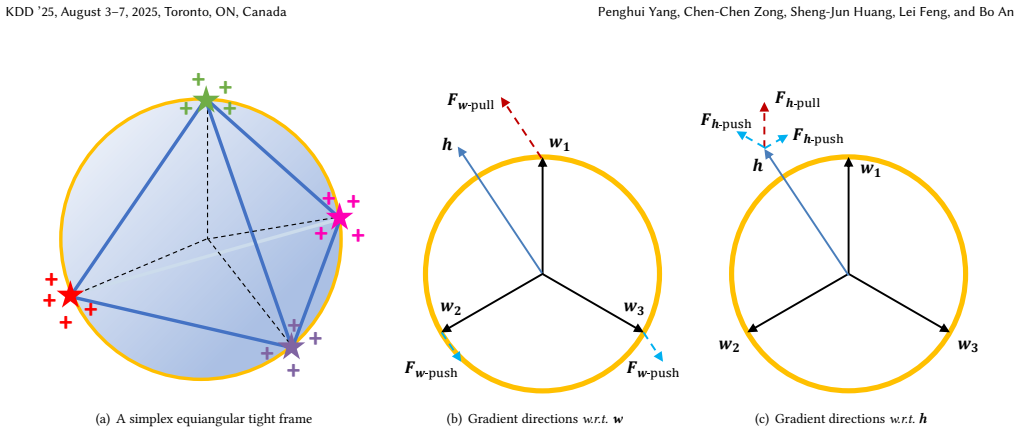
Zhihui Zhu, Tianyu Ding, Jinxin Zhou, Xiao Li, Chong You, Jeremias Sulam, and Qing Qu. 2021. A geometric analysis of neural collapse with unconstrained features. In Advances in Neural Information Processing Systems . A Dual Head is the Only Way As mentioned in Section 3.1, we have tried many other methods before introducing the auxiliary head, including d...
work page 2021
-
[52]
CIFAR-100 covers100 categories
and ImageNet [4]. CIFAR-100 covers100 categories. It contains 50,000 images in the train set and 10,000 images in the test set. ImageNet covers 1,000 categories of images. It contains 1.28 million images in the train set and 50,000 images in the test set. CIFAR-100: Teachers and students are trained for 240 epochs with SGD, and the batch size is 64. The l...
-
[53]
Therefore, the only adjustable hyperparameter is 𝛼. Table 11 illustrates the performance of DHKD as the value of 𝛼 changes among 0.2, 0.5, 1, 2, 5 on CIFAR-100. From the table, it can be observed that the performance of DHKD is not very sensitive to the parameter 𝛼. I The Performance of “dual head + vanilla KD” In this section, we conduct the experiments ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.