Turbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
Pith reviewed 2026-05-23 07:11 UTC · model grok-4.3
The pith
Dilated rendering and dual-error densification speed up 3D Gaussian fitting for high-resolution radiance fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that dilated rendering of only a subset of pixels, combined with a convergence-aware budget control mechanism and densification guided by both positional and appearance errors, accelerates the optimization of 3D Gaussian Splatting while preserving or improving rendering fidelity for high-resolution inputs.
What carries the argument
Dilated rendering technique that renders only a subset of pixels, along with convergence-aware budget control and dual positional-appearance error signals for densification.
If this is right
- Optimization completes faster than prior 3DGS methods.
- 4K-resolution scenes can be fitted quickly.
- Novel view rendering quality stays the same or improves.
- Densification avoids gradient vanishing through combined error signals.
- Better balance between adding and optimizing Gaussians increases efficiency.
Where Pith is reading between the lines
- The pixel subset approach could extend to other radiance field methods like NeRF variants.
- Hardware acceleration might compound the speed gains in practical deployments.
- Applying it to dynamic or very large scenes could show if context loss occurs in complex environments.
Load-bearing premise
The assumption that rendering only a dilated subset of pixels combined with dual positional-appearance error signals for densification will guide optimization to the same or better final model quality without introducing artifacts or missing scene details across varied inputs.
What would settle it
A comparison on benchmark datasets where the accelerated method produces lower PSNR or visible artifacts on test views compared to standard full-pixel 3DGS training.
Figures







read the original abstract
Novel-view synthesis plays a crucial role in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent approaches, such as 3D Gaussian Splatting (3DGS), have emerged as state-of-the-art solutions, offering high-quality novel view synthesis in real time. However, training 3DGS models remains slow, particularly for high-resolution images, often requiring hours to fit a scene with 200 views. In this work, we aim to accelerate the fitting process by reducing computational overhead and improving learning efficiency. Specifically, we introduce a dilated rendering technique that renders only a subset of pixels instead of the full image, significantly reducing computational costs. To enhance learning efficiency, we develop a convergence-aware budget control mechanism that balances the addition of new Gaussians with the optimization of existing ones. Additionally, to improve densification efficiency and prevent gradient vanishing, we incorporate both positional and appearance errors to improve the effectiveness of densification. With these improvements, we achieve fast 4K-resolution fitting while maintaining, or even improving, novel view rendering quality. Extensive experiments demonstrate that our method achieves significantly faster optimization than existing approaches while preserving high rendering fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Turbo-GS to accelerate 3D Gaussian Splatting (3DGS) training for novel-view synthesis. It introduces dilated rendering (rendering only a subset of pixels), a convergence-aware budget control mechanism to balance Gaussian addition and optimization, and dual positional-appearance error signals for densification to avoid gradient vanishing. The central claim is that these changes enable fast 4K-resolution fitting while maintaining or improving rendering quality, with significantly faster optimization than existing methods across extensive experiments.
Significance. If the empirical results hold, the work would be significant for practical high-resolution radiance field applications in mixed reality and robotics by addressing the hours-long training bottleneck of 3DGS. The modifications target computational overhead and densification efficiency directly. Credit is due for focusing on engineering improvements that could scale 3DGS to 4K without new primitives or architectures.
major comments (2)
- [Abstract] Abstract: The central performance claim (fast 4K fitting with maintained or improved quality and significantly faster optimization) is stated without any quantitative results, error bars, ablation details, dataset descriptions, or baseline comparisons, preventing evaluation of whether the claim holds.
- [Abstract] The claim that dilated rendering plus dual-error densification recovers all visible high-frequency detail (fine textures, specular highlights, thin structures) rests on the unverified assumption that the chosen pixel subset and error signals supply complete gradients; no direct evidence, ablation, or failure-case analysis is supplied to confirm completeness across scene types.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will revise accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (fast 4K fitting with maintained or improved quality and significantly faster optimization) is stated without any quantitative results, error bars, ablation details, dataset descriptions, or baseline comparisons, preventing evaluation of whether the claim holds.
Authors: We agree the abstract would be stronger with quantitative support. In revision we will add concise numerical highlights (e.g., training-time speed-ups and PSNR/SSIM on Mip-NeRF 360 and Tanks & Temples) together with the main baselines and a brief note on the ablation studies, while respecting the word limit. revision: yes
-
Referee: [Abstract] The claim that dilated rendering plus dual-error densification recovers all visible high-frequency detail (fine textures, specular highlights, thin structures) rests on the unverified assumption that the chosen pixel subset and error signals supply complete gradients; no direct evidence, ablation, or failure-case analysis is supplied to confirm completeness across scene types.
Authors: The manuscript already contains quantitative results (Section 4) and ablations (Section 4.3) showing that quality is preserved or improved, with visual examples of fine-detail recovery. We nevertheless accept that a more explicit discussion of gradient completeness and potential failure cases would be valuable; we will add a short analysis paragraph and, if space permits, a supplementary figure addressing this point. revision: partial
Circularity Check
No circularity: engineering modifications presented without self-referential derivations
full rationale
The paper proposes three algorithmic changes (dilated rendering of pixel subsets, convergence-aware budget control, and dual positional-appearance error for densification) to accelerate 3DGS fitting. These are described as independent engineering decisions whose correctness is asserted via experiments, not via any derivation chain, uniqueness theorem, or fitted parameter renamed as prediction. No equations, self-citations, or ansatzes are shown that reduce the claimed quality preservation to the inputs by construction. The reader's assessment of score 1.0 is consistent with the absence of load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We combine the guidance from both the position error and the appearance error... convergence-aware budget control... dilation-based rendering technique
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
power-law-based adaptive budget schedule... α = α_base + λ·tanh(ϵ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022. 1, 2, 5, 6, 7, 8, 3
work page 2022
-
[2]
Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 19457–19467, 2023. 3
work page 2024
-
[3]
Tensorf: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. InEuropean con- ference on computer vision, pages 333–350. Springer, 2022. 2
work page 2022
-
[4]
Lara: Efficient large-baseline radiance fields.ArXiv, abs/2407.04699, 2024
Anpei Chen, Haofei Xu, Stefano Esposito, Siyu Tang, and Andreas Geiger. Lara: Efficient large-baseline radiance fields.ArXiv, abs/2407.04699, 2024. 3
-
[5]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images.ArXiv, abs/2403.14627, 2024
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images.ArXiv, abs/2403.14627, 2024. 3
-
[6]
Qiyu Dai, Yan Zhu, Yiran Geng, Ciyu Ruan, Jiazhao Zhang, and He Wang. Graspnerf: Multiview-based 6-dof grasp detection for transparent and specular objects using gener- alizable nerf. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1757–1763. IEEE,
-
[7]
Nianchen Deng, Zhenyi He, Jiannan Ye, Budmonde Duinkharjav, Praneeth Chakravarthula, Xubo Yang, and Qi Sun. Fov-nerf: Foveated neural radiance fields for virtual reality.IEEE Transactions on Visualization and Computer Graphics, 28(11):3854–3864, 2022. 2
work page 2022
-
[8]
Sankeerth Durvasula, Adrian Zhao, Fan Chen, Ruofan Liang, Pawan Kumar Sanjaya, and Nandita Vijaykumar. Distwar: Fast differentiable rendering on raster-based ren- dering pipelines.ArXiv, abs/2401.05345, 2023. 3
-
[9]
Lightgaus- sian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps,
Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, De- jia Xu, and Zhangyang Wang. Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps. ArXiv, abs/2311.17245, 2023. 3
-
[10]
Instantsplat: Un- bounded sparse-view pose-free gaussian splatting in 40 sec- onds
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, B. Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, and Yue Wang. Instantsplat: Unbounded sparse-view pose-free gaus- sian splatting in 40 seconds.ArXiv, abs/2403.20309, 2024. 3
-
[11]
Instantsplat: Unbounded sparse-view pose-free gaus- sian splatting in 40 seconds, 2024
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, and Yue Wang. Instantsplat: Unbounded sparse-view pose-free gaus- sian splatting in 40 seconds, 2024. 2
work page 2024
-
[12]
Guangchi Fang and Bing Wang. Mini-splatting: Represent- ing scenes with a constrained number of gaussians.Euro- pean Conference on Computer Vision, 2024. 3, 7, 8, 2
work page 2024
-
[13]
Guofeng Feng, Siyan Chen, Rong Fu, Zimu Liao, Yi Wang, Tao Liu, Zhiling Pei, Hengjie Li, Xingcheng Zhang, and Bo Dai. Flashgs: Efficient 3d gaussian splatting for large-scale and high-resolution rendering.ArXiv, abs/2408.07967, 2024. 3
-
[14]
Evaluating alternatives to sfm point cloud ini- tialization for gaussian splatting
Yalda Foroutan, Daniel Rebain, Kwang Moo Yi, and Andrea Tagliasacchi. Evaluating alternatives to sfm point cloud ini- tialization for gaussian splatting. 2024. 3
work page 2024
-
[15]
Plenoxels: Radiance fields without neural networks
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5501–5510, 2022. 2, 3, 8
work page 2022
-
[16]
Sharath Girish, Kamal Gupta, and Abhinav Shrivastava. Ea- gles: Efficient accelerated 3d gaussians with lightweight en- codings.European Conference on Computer Vision, 2024. 2, 3, 7, 8
work page 2024
-
[17]
Antoine Gu’edon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5354–5363, 2023. 3
work page 2024
-
[18]
Antoine Gu ´edon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5354–5363, 2024. 2
work page 2024
-
[19]
Peter Hedman, Julien Philip, True Price, Jan-Michael Frahm, George Drettakis, and Gabriel Brostow. Deep blending for free-viewpoint image-based rendering.ACM Transactions on Graphics (ToG), 37(6):1–15, 2018. 6, 8, 1, 2, 3
work page 2018
-
[20]
3dgs-lm: Faster gaussian-splatting opti- mization with levenberg-marquardt.ArXiv, abs/2409.12892,
Lukas H ¨ollein, Aljavz Bovzivc, Michael Zollhofer, and Matthias Nießner. 3dgs-lm: Faster gaussian-splatting opti- mization with levenberg-marquardt.ArXiv, abs/2409.12892,
-
[21]
2d gaussian splatting for geometrically ac- curate radiance fields.ArXiv, abs/2403.17888, 2024
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields.ArXiv, abs/2403.17888, 2024. 3
-
[22]
Relaxing accurate initialization constraint for 3d gaussian splatting.ArXiv, abs/2403.09413, 2024
Jaewoo Jung, Jisang Han, Honggyu An, Jiwon Kang, Seonghoon Park, and Seungryong Kim. Relaxing accurate initialization constraint for 3d gaussian splatting.ArXiv, abs/2403.09413, 2024. 3
-
[23]
Relu fields: The little non-linearity that could.ACM SIGGRAPH 2022 Conference Proceedings,
Animesh Karnewar, Tobias Ritschel, Oliver Wang, and Niloy Jyoti Mitra. Relu fields: The little non-linearity that could.ACM SIGGRAPH 2022 Conference Proceedings,
work page 2022
-
[24]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[25]
A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Trans
Bernhard Kerbl, Andr’eas Meuleman, Georgios Kopanas, Michael Wimmer, Alexandre Lanvin, and George Drettakis. A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Trans. Graph., 43:62:1– 62:15, 2024. 3
work page 2024
-
[26]
3d gaussian splatting as markov chain monte carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Jeff Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splatting as markov chain monte carlo.ArXiv, abs/2404.09591, 2024. 3
-
[27]
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36 (4):1–13, 2017. 1, 2, 3
work page 2017
-
[28]
Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184, 2024
Zhengyang Liang, Hao He, Ceyuan Yang, and Bo Dai. Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184, 2024. 5
-
[29]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024. 2, 3, 4, 5, 6, 7, 8
work page 2024
-
[30]
Taming 3dgs: High-quality radiance fields with limited re- sources
Mallick and Goel, Bernhard Kerbl, Francisco Vicente Car- rasco, Markus Steinberger, and Fernando De La Torre. Taming 3dgs: High-quality radiance fields with limited re- sources. InSIGGRAPH Asia 2024 Conference Papers, 2024. 2, 3, 4, 6, 7, 8
work page 2024
-
[31]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf. Communications of the ACM, 65:99 – 106, 2020. 1, 2, 3
work page 2020
-
[32]
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM Transactions on Graphics (TOG), 41:1 – 15, 2022. 3
work page 2022
-
[33]
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 2, 8
work page 2022
-
[34]
K. L. Navaneet, Kossar Pourahmadi Meibodi, Soroush Ab- basi Koohpayegani, and Hamed Pirsiavash. Compgs: Smaller and faster gaussian splatting with vector quantiza- tion. 2023. 3
work page 2023
-
[35]
Coherentgs: Sparse novel view synthesis with coherent 3d gaussians.ArXiv, abs/2403.19495, 2024
Avinash Paliwal, Wei Ye, Jinhui Xiong, Dmytro Kotovenko, Rakesh Ranjan, Vikas Chandra, and Nima Khademi Kalan- tari. Coherentgs: Sparse novel view synthesis with coherent 3d gaussians.ArXiv, abs/2403.19495, 2024. 3
-
[36]
Panagiotis Papantonakis, Georgios Kopanas, Bernhard Kerbl, Alexandre Lanvin, and George Drettakis. Reducing the memory footprint of 3d gaussian splatting.Proceedings of the ACM on Computer Graphics and Interactive Tech- niques, 7:1 – 17, 2024. 3
work page 2024
-
[37]
Kerui Ren, Lihan Jiang, Tao Lu, Mulin Yu, Linning Xu, Zhangkai Ni, and Bo Dai. Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians.arXiv preprint arXiv:2403.17898, 2024. 3
-
[38]
Pixelwise View Selection for Un- structured Multi-View Stereo
Johannes Lutz Sch ¨onberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise View Selection for Un- structured Multi-View Stereo. InEuropean Conference on Computer Vision (ECCV), 2016. 2
work page 2016
-
[39]
Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5449–5459,
work page 2022
-
[40]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
work page 2004
-
[41]
Grid-guided neural radiance fields for large urban scenes
Linning Xu, Yuanbo Xiangli, Sida Peng, Xingang Pan, Nanxuan Zhao, Christian Theobalt, Bo Dai, and Dahua Lin. Grid-guided neural radiance fields for large urban scenes. 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 8296–8306, 2023. 3
work page 2023
-
[42]
Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, and Ulrich Neumann. Point-nerf: Point- based neural radiance fields.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5428–5438, 2022. 3
work page 2022
-
[43]
Bakedsdf: Meshing neural sdfs for real- time view synthesis
Lior Yariv, Peter Hedman, Christian Reiser, Dor Verbin, Pratul P Srinivasan, Richard Szeliski, Jonathan T Barron, and Ben Mildenhall. Bakedsdf: Meshing neural sdfs for real- time view synthesis. InACM SIGGRAPH 2023 Conference Proceedings, pages 1–9, 2023. 2
work page 2023
-
[44]
gsplat: An open-source library for gaussian splatting.ArXiv, abs/2409.06765, 2024
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jef- frey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting.ArXiv, abs/2409.06765, 2024. 3
-
[45]
Plenoctrees for real-time rendering of neural radiance fields
Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5752– 5761, 2021. 2
work page 2021
-
[46]
Gsdf: 3dgs meets sdf for improved rendering and reconstruction.ArXiv, abs/2403.16964, 2024
Mulin Yu, Tao Lu, Linning Xu, Lihan Jiang, Yuanbo Xiangli, and Bo Dai. Gsdf: 3dgs meets sdf for improved rendering and reconstruction.ArXiv, abs/2403.16964, 2024. 3
-
[47]
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splat- ting.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19447–19456, 2023. 3, 8, 2
work page 2024
-
[48]
Gnfactor: Multi-task real robot learning with generalizable neural feature fields
Yanjie Ze, Ge Yan, Yueh-Hua Wu, Annabella Macaluso, Yuying Ge, Jianglong Ye, Nicklas Hansen, Li Erran Li, and Xiaolong Wang. Gnfactor: Multi-task real robot learning with generalizable neural feature fields. InConference on Robot Learning, pages 284–301. PMLR, 2023. 2
work page 2023
-
[49]
Gs-lrm: Large reconstruction model for 3d gaussian splatting.ArXiv, abs/2404.19702, 2024
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting.ArXiv, abs/2404.19702, 2024. 3
-
[50]
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large recon- struction model for 3d gaussian splatting.European Confer- ence on Computer Vision, 2024. 2
work page 2024
-
[51]
The unreasonable effectiveness of 10 deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of 10 deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 6
work page 2018
-
[52]
Long-lrm: Long- sequence large reconstruction model for wide-coverage gaussian splats, 2024
Chen Ziwen, Hao Tan, Kai Zhang, Sai Bi, Fujun Luan, Yi- cong Hong, Li Fuxin, and Zexiang Xu. Long-lrm: Long- sequence large reconstruction model for wide-coverage gaussian splats, 2024. 2 11 Turbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields Supplementary Material
work page 2024
-
[53]
Implementation Details 7.1. More Implementation Details For all the dataset with a resolution below 4K, we train it for10kiterations. The maximum budget is set to300kor 500kfor low resolution dataset,700kfor 4K and higher res- olution dataset. The batched training is activated in the last 50 iterations, with a batch size of 4. We calculate the aver- age l...
-
[54]
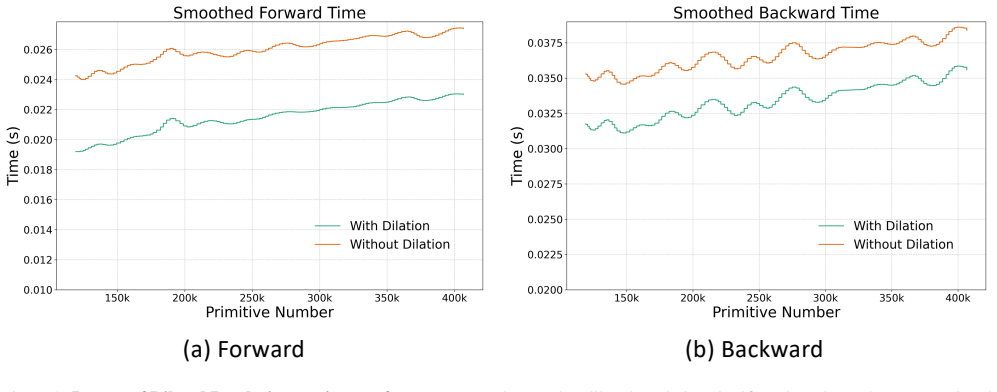
More Experiments and Results Per-scene ResultsHere we list the error metrics used in our evaluation in Sec.4 across all considered methods and scenes, as shown in Tab 5- 8.drjohnson-playroom[19] belongs to the deep blending dataset;train-truckcome from the Tanks and Temple [27] dataset;bicycle-boonsai are from MipNeRF360 [1]. Dilated RenderingThe effectiv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.