Alternating Gradient-Type Algorithm for Bilevel Optimization with Inexact Lower-Level Solutions via Moreau Envelope-based Reformulation
Pith reviewed 2026-05-23 07:23 UTC · model grok-4.3
The pith
An alternating gradient algorithm converges to stationary points in bilevel optimization by allowing inexact lower-level solutions through a Moreau envelope reformulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The AGILS algorithm, obtained from a Moreau envelope reformulation of the bilevel problem, converges to stationary points without requiring exact lower-level solutions at every iteration; under the Kurdyka-Łojasiewicz property it also converges sequentially.
What carries the argument
The Moreau envelope-based reformulation that converts the bilevel problem into an alternating gradient scheme tolerant of inexact inner solves.
If this is right
- Bilevel hyperparameter tuning can be performed without solving the lower-level problem to high accuracy at each outer iteration.
- Convergence guarantees apply whenever the lower level satisfies the stated convexity and composite structure.
- Sequential convergence holds on problems obeying the Kurdyka-Łojasiewicz inequality.
- The method extends the class of bilevel solvers that remain practical when inner problems are themselves iterative.
Where Pith is reading between the lines
- The same reformulation idea might be tested on lower levels that are only weakly convex or satisfy error bounds short of full convexity.
- Runtime comparisons against exact inner-solve baselines would quantify the efficiency gain on larger regression models.
- The KL-based sequential convergence could be checked on problems whose objective is known to satisfy the property, such as certain quadratic or piecewise-linear cases.
Load-bearing premise
The lower-level problem must be a convex composite optimization model.
What would settle it
An instance of the bilevel problem whose lower level is convex composite, for which AGILS is run with the stated step-size rules and the iterates fail to approach any stationary point.
Figures

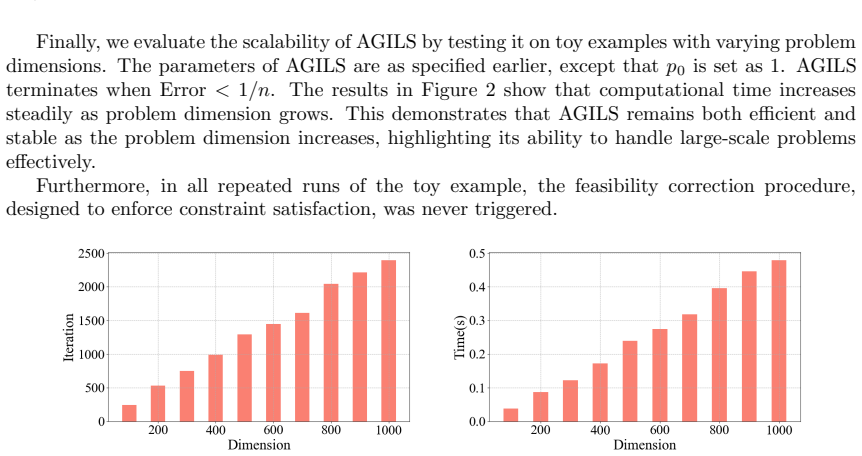
read the original abstract
In this paper, we study a class of bilevel optimization problems where the lower-level problem is a convex composite optimization model, which arises in various applications, including bilevel hyperparameter selection for regularized regression models. To solve these problems, we propose an Alternating Gradient-type algorithm with Inexact Lower-level Solutions (AGILS) based on a Moreau envelope-based reformulation of the bilevel optimization problem. The proposed algorithm does not require exact solutions of the lower-level problem at each iteration, improving computational efficiency. We prove the convergence of AGILS to stationary points and, under the Kurdyka-{\L}ojasiewicz (KL) property, establish its sequential convergence. Numerical experiments, including a toy example and a bilevel hyperparameter selection problem for the sparse group Lasso model, demonstrate the effectiveness of the proposed AGILS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Alternating Gradient-type algorithm with Inexact Lower-level Solutions (AGILS) for bilevel optimization problems in which the lower level is a convex composite optimization model. The approach relies on a Moreau envelope-based reformulation that permits inexact lower-level solves at each iteration. The authors prove convergence of the generated sequence to stationary points of the reformulated problem and establish sequential convergence under the Kurdyka-Łojasiewicz property. Numerical results on a toy example and on bilevel hyperparameter selection for the sparse group Lasso are presented to illustrate practical performance.
Significance. If the stated convergence results hold, the work supplies a practical algorithmic framework for bilevel problems that avoids the computational cost of exact lower-level solves. The Moreau-envelope reformulation is a technically natural device for handling inexactness, and the KL-based sequential convergence result strengthens the analysis beyond mere stationarity. The hyperparameter-selection application is a relevant and timely test case.
minor comments (3)
- [§2.2] §2.2, Definition 2.3: the precise relationship between the original bilevel value function and the Moreau-envelope reformulation could be stated as a formal proposition rather than left implicit in the surrounding text.
- [Algorithm 1] Algorithm 1, line 8: the tolerance schedule for the inexact lower-level solver is described only verbally; an explicit rule (e.g., a summable sequence) would make the implementation unambiguous.
- [Table 1] Table 1: the reported CPU times do not indicate whether the lower-level solver tolerance was held fixed across methods or adapted; a short clarifying sentence would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper derives an alternating gradient-type algorithm (AGILS) from a Moreau-envelope reformulation of a bilevel problem whose lower level is a convex composite model, then proves convergence to stationary points (and sequential convergence under the KL property) via standard arguments on the reformulated problem. No step reduces by construction to a fitted input, self-definition, or load-bearing self-citation; the claims rest on forward mathematical analysis rather than renaming or circular re-use of the target result itself. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The lower-level problem is a convex composite optimization model.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose AGILS … based on a Moreau envelope-based reformulation … prove the convergence of AGILS to stationary points and, under the Kurdyka-Łojasiewicz (KL) property, establish its sequential convergence.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the lower-level problem is a convex composite optimization model … g(x,·) is proximal-friendly
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Optimality Conditions and Numerical Algorithms for a Class of Minimax Bilevel Optimization Problems
Optimality conditions are established for minimax bilevel problems via KKT reconstruction, and projected gradient multi-step ascent-descent algorithms are proposed that achieve ε-KKT solutions in O(ε^{-3} log(ε^{-1}))...
Reference graph
Works this paper leans on
-
[1]
Jan Harold Alcantara, Chieu Thanh Nguyen, Takayuki Okuno, Akiko Takeda, and Jein-Shan Chen. Unified smoothing approach for best hyperparameter selection problem using a bilevel optimization strategy.Mathematical Programming, pages 1–40, 2024
work page 2024
-
[2]
Solving bilevel programs with the KKT-approach
Gemayqzel Bouza Allende and Georg Still. Solving bilevel programs with the KKT-approach. Mathematical Programming, 138:309–332, 2013
work page 2013
-
[3]
H´ edy Attouch, J´ erˆ ome Bolte, Patrick Redont, and Antoine Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka- Lojasiewicz inequality.Mathematics of Operations Research, 35(2):438–457, 2010
work page 2010
-
[4]
Hedy Attouch, J´ erˆ ome Bolte, and Benar Fux Svaiter. Convergence of descent methods for semi-algebraic and tame problems: Proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods.Mathematical Programming, 137(1):91–129, 2013
work page 2013
-
[5]
Kuang Bai, Jane J Ye, and Shangzhi Zeng. Optimality conditions for bilevel programmes via Moreau envelope reformulation.Optimization, pages 1–35, 2024
work page 2024
-
[6]
Jonathan F Bard.Practical bilevel optimization: Algorithms and applications. Springer, New York, 1998
work page 1998
-
[7]
Amir Beck.First-order methods in optimization. SIAM, Philadelphia, 2017
work page 2017
-
[8]
Kristin P Bennett, Gautam Kunapuli, Jing Hu, and Jong-Shi Pang.Bilevel optimization and machine learning. Springer, Berlin, 2008
work page 2008
-
[9]
James Bergstra, Daniel Yamins, and David Cox. Making a science of model search: Hyper- parameter optimization in hundreds of dimensions for vision architectures. InInternational Conference on Machine Learning, 2013
work page 2013
-
[10]
Implicit differentiation of Lasso-type models for hyperparameter optimization
Quentin Bertrand, Quentin Klopfenstein, Mathieu Blondel, Samuel Vaiter, Alexandre Gram- fort, and Joseph Salmon. Implicit differentiation of Lasso-type models for hyperparameter optimization. InInternational Conference on Machine Learning, 2020
work page 2020
-
[11]
J´ erˆ ome Bolte, Aris Daniilidis, and Adrian Lewis. The Lojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems.SIAM Journal on Optimization, 17(4):1205–1223, 2007
work page 2007
-
[12]
Clarke subgradients of stratifiable functions.SIAM Journal on Optimization, 18(2):556–572, 2007
J´ erˆ ome Bolte, Aris Daniilidis, Adrian Lewis, and Masahiro Shiota. Clarke subgradients of stratifiable functions.SIAM Journal on Optimization, 18(2):556–572, 2007
work page 2007
-
[13]
J´ erˆ ome Bolte, Aris Daniilidis, Olivier Ley, and Laurent Mazet. Characterizations of Lojasiewicz inequalities: Subgradient flows, talweg, convexity.Transactions of the Ameri- can Mathematical Society, 362(6):3319–3363, 2010
work page 2010
-
[14]
J´ erˆ ome Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimiza- tion for nonconvex and nonsmooth problems.Mathematical Programming, 146(1):459–494, 2014
work page 2014
-
[15]
J Fr´ ed´ eric Bonnans and Alexander Shapiro.Perturbation analysis of optimization problems. Springer, New York, 2013
work page 2013
-
[16]
Mark Cecchini, Joseph Ecker, Michael Kupferschmid, and Robert Leitch. Solving nonlin- ear principal-agent problems using bilevel programming.European Journal of Operational Research, 230(2):364–373, 2013
work page 2013
-
[17]
Closing the gap: Tighter analysis of alternat- ing stochastic gradient methods for bilevel problems
Tianyi Chen, Yuejiao Sun, and Wotao Yin. Closing the gap: Tighter analysis of alternat- ing stochastic gradient methods for bilevel problems. InAdvances in Neural Information Processing Systems, 2021. 30
work page 2021
-
[18]
An overview of bilevel optimization
Benoˆ ıt Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of Operations Research, 153:235–256, 2007
work page 2007
-
[19]
Isabelle Constantin and Michael Florian. Optimizing frequencies in a transit network: A nonlinear bi-level programming approach.International Transactions in Operational Research, 2(2):149–164, 1995
work page 1995
-
[20]
Stephan Dempe.Foundations of bilevel programming. Springer, New York, 2002
work page 2002
-
[21]
Stephan Dempe.Bilevel optimization: Advances and next challenges. Springer, Cham, 2020
work page 2020
-
[22]
Stephan Dempe and Alain B Zemkoho. The bilevel programming problem: Reformulations, constraint qualifications and optimality conditions.Mathematical Programming, 138:447–473, 2013
work page 2013
-
[23]
Dmitriy Drusvyatskiy and Adrian Lewis. Error bounds, quadratic growth, and linear conver- gence of proximal methods.Mathematics of Operations Research, 43(3):919–948, 2018
work page 2018
-
[24]
Dmitriy Drusvyatskiy and Courtney Paquette. Efficiency of minimizing compositions of convex functions and smooth maps.Mathematical Programming, 178(1):503–558, 2019
work page 2019
-
[25]
Francisco Facchinei and Jong-Shi Pang.Finite-dimensional variational inequalities and com- plementadrity problems. Springer, New York, 2007
work page 2007
-
[26]
Jean Feng and Noah Simon. Gradient-based regularization parameter selection for prob- lems with nonsmooth penalty functions.Journal of Computational and Graphical Statistics, 27(2):426–435, 2018
work page 2018
-
[27]
Andreas Fischer, Alain B Zemkoho, and Shenglong Zhou. Semismooth Newton-type method for bilevel optimization: Global convergence and extensive numerical experiments.Optimiza- tion Methods & Software, 37(5):1770–1804, 2022
work page 2022
-
[28]
J¨ org Fliege, Andrey Tin, and Alain B Zemkoho. Gauss–Newton-type methods for bilevel optimization.Computational Optimization and Applications, 78(3):793–824, 2021
work page 2021
-
[29]
Bilevel programming for hyperparameter optimization and meta-learning
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. InInternational Conference on Machine Learning, 2018
work page 2018
-
[30]
Value function based difference-of-convex algorithm for bilevel hyperparameter selection problems
Lucy L Gao, Jane J Ye, Haian Yin, Shangzhi Zeng, and Jin Zhang. Value function based difference-of-convex algorithm for bilevel hyperparameter selection problems. InInternational Conference on Machine Learning, 2022
work page 2022
-
[31]
Lucy L. Gao, Jane J. Ye, Haian Yin, Shangzhi Zeng, and Jin Zhang. Moreau envelope based difference-of- weakly-convex reformulation and algorithm for bilevel programs.preprint, arXiv:2306.16761, 2024
-
[32]
John E Garen. Executive compensation and principal-agent theory.Journal of Political Economy, 102(6):1175–1199, 1994
work page 1994
-
[33]
On the iteration complexity of hypergradient computation
Riccardo Grazzi, Luca Franceschi, Massimiliano Pontil, and Saverio Salzo. On the iteration complexity of hypergradient computation. InInternational Conference on Machine Learning, 2020
work page 2020
-
[34]
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor- critic.SIAM Journal on Optimization, 33(1):147–180, 2023
work page 2023
-
[35]
Bilevel optimization: Convergence analysis and enhanced design
Kaiyi Ji, Junjie Yang, and Yingbin Liang. Bilevel optimization: Convergence analysis and enhanced design. InInternational Conference on Machine Learning, 2021. 31
work page 2021
-
[36]
Lateef O Jolaoso, Patrick Mehlitz, and Alain B Zemkoho. A fresh look at nonsmooth Levenberg–Marquardt methods with applications to bilevel optimization.Optimization, pages 1–48, 2024
work page 2024
-
[37]
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal- gradient methods under the polyak- lojasiewicz condition. InJoint European conference on machine learning and knowledge discovery in databases, pages 795–811. Springer, 2016
work page 2016
-
[38]
Gautam Kunapuli, Kristin P Bennett, Jing Hu, and Jong-Shi Pang. Classification model selection via bilevel programming.Optimization Methods & Software, 23(4):475–489, 2008
work page 2008
-
[39]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. A fully first-order method for stochastic bilevel optimization. InInternational Conference on Machine Learning, 2023
work page 2023
-
[40]
Bome! bilevel optimization made easy: A simple first-order approach
Bo Liu, Mao Ye, Stephen Wright, Peter Stone, and Qiang Liu. Bome! bilevel optimization made easy: A simple first-order approach. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[41]
Risheng Liu, Jiaxin Gao, Jin Zhang, Deyu Meng, and Zhouchen Lin. Investigating bi-level optimization for learning and vision from a unified perspective: A survey and beyond.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12):10045–10067, 2021
work page 2021
-
[42]
Risheng Liu, Zhu Liu, Wei Yao, Shangzhi Zeng, and Jin Zhang. Moreau envelope for noncon- vex bi-level optimization: A single-loop and Hessian-free solution strategy. InInternational Conference on Machine Learning, 2024
work page 2024
-
[43]
SLM: A smoothed first-order Lagrangian method for structured constrained nonconvex optimization
Songtao Lu. SLM: A smoothed first-order Lagrangian method for structured constrained nonconvex optimization. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[44]
Zhaosong Lu and Sanyou Mei. First-order penalty methods for bilevel optimization.SIAM Journal on Optimization, 34(2):1937–1969, 2024
work page 1937
-
[45]
Cambridge University Press, Cambridge, 1996
Zhi-Quan Luo, Jong-Shi Pang, and Daniel Ralph.Mathematical programs with equilibrium constraints. Cambridge University Press, Cambridge, 1996
work page 1996
-
[46]
Bilevel programming in traffic planning: Models, methods and challenge
Athanasios Migdalas. Bilevel programming in traffic planning: Models, methods and challenge. Journal of Global Optimization, 7:381–405, 1995
work page 1995
-
[47]
James A Mirrlees. The theory of moral hazard and unobservable behaviour: Part I.Review of Economic Studies, 66(1):3–21, 1999
work page 1999
-
[48]
Boris S Mordukhovich, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. A globally convergent proximal Newton-type method in nonsmooth convex optimization.Mathematical Program- ming, 198(1):899–936, 2023
work page 2023
-
[49]
Boris Sholimovich Mordukhovich.Variational analysis and applications. Springer, Cham, 2018
work page 2018
-
[50]
Approximate convex functions.Journal of Nonlinear and Convex Analysis, 1(2):155–176, 2000
Huynh V Ngai, Dinh T Luc, and M Th´ era. Approximate convex functions.Journal of Nonlinear and Convex Analysis, 1(2):155–176, 2000
work page 2000
-
[51]
Evgeni Alekseevich Nurminskii. The quasigradient method for the solving of the nonlinear programming problems.Cybernetics and Systems Analysis, 9(1):145–150, 1973
work page 1973
-
[52]
Takayuki Okuno, Akiko Takeda, Akihiro Kawana, and Motokazu Watanabe. Onℓ p- hyperparameter learning via bilevel nonsmooth optimization.Journal of Machine Learning Research, 22(245):1–47, 2021
work page 2021
-
[53]
Jiˇ r´ ı Outrata. On the numerical solution of a class of Stackelberg problems.Zeitschrift f¨ ur Operations Research, 34:255–277, 1990. 32
work page 1990
-
[54]
Jiri Outrata, Michal Kocvara, and Jochem Zowe.Nonsmooth approach to optimization prob- lems with equilibrium constraints: Theory, applications and numerical results. Springer, New York, 1998
work page 1998
-
[55]
On penalty-based bilevel gradient descent method
Han Shen and Tianyi Chen. On penalty-based bilevel gradient descent method. InInterna- tional Conference on Machine Learning, 2023
work page 2023
-
[56]
Noah Simon, Jerome Friedman, Trevor Hastie, and Robert Tibshirani. A sparse-group Lasso. Journal of Computational and Graphical Statistics, 22(2):231–245, 2013
work page 2013
-
[57]
Heinrich Von Stackelberg.Market structure and equilibrium. Springer, Berlin, 2010
work page 2010
-
[58]
Andreas W¨ achter and Lorenz T Biegler. On the implementation of an interior-point fil- ter line-search algorithm for large-scale nonlinear programming.Mathematical programming, 106(1):25–57, 2006
work page 2006
-
[59]
Xianfu Wang and Ziyuan Wang. Calculus rules of the generalized concave Kurdyka– Lojasiewicz property.Journal of Optimization Theory and Applications, 197(3):839–854, 2023
work page 2023
-
[60]
Wei Yao, Haian Yin, Shangzhi Zeng, and Jin Zhang. Overcoming lower-level constraints in bilevel optimization: A novel approach with regularized gap functions.preprint, arXiv:2406.01992, 2024
-
[61]
Wei Yao, Chengming Yu, Shangzhi Zeng, and Jin Zhang. Constrained bi-level optimization: Proximal Lagrangian value function approach and Hessian-free algorithm. InInternational Conference on Learning Representations, 2024
work page 2024
-
[62]
Jane J Ye, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. Difference of convex algorithms for bilevel programs with applications in hyperparameter selection.Mathematical Programming, 198(2):1583–1616, 2023
work page 2023
-
[63]
Optimality conditions for bilevel programming problems.Optimization, 33(1):9–27, 1995
Jane J Ye and DL Zhu. Optimality conditions for bilevel programming problems.Optimization, 33(1):9–27, 1995
work page 1995
-
[64]
Yihua Zhang, Prashant Khanduri, Ioannis Tsaknakis, Yuguang Yao, Mingyi Hong, and Sijia Liu. An introduction to bilevel optimization: Foundations and applications in signal process- ing and machine learning.IEEE Signal Processing Magazine, 41(1):38–59, 2024. 33
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.