Towards in-the-wild Egocentric 3D Hand-Object Pose Estimation
Pith reviewed 2026-06-30 06:01 UTC · model grok-4.3
The pith
A cross-attention transformer trained on new contact annotations estimates accurate 3D hand and object poses from egocentric video in the wild.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HOPformer jointly predicts bi-manual hand and object pose from single-view egocentric RGB by using a cross-attention decoder that conditions object features on hand priors, reaching 82.4 percent success on ARCTIC and doubling success rate on EPIC-Contact while reducing contact deviation by 75 percent.
What carries the argument
The cross-attention decoder in HOPformer that conditions object features on hand priors.
If this is right
- Single-pass joint prediction removes the need for separate hand and object networks.
- Contact supervision becomes usable for training models that must operate on monocular wild video.
- Performance gains on both lab and wild benchmarks indicate the architecture transfers across domains.
- Bi-manual interactions can be recovered without staged processing or post-processing.
Where Pith is reading between the lines
- The approach could support real-time hand tracking in AR headsets that record first-person video.
- Contact labels from the new dataset might be reusable to improve other interaction tasks such as grasp synthesis.
- If the conditioning mechanism proves stable, similar cross-attention patterns could be tested on full-body or multi-person scenes.
Load-bearing premise
The cross-attention decoder trained on EPIC-Contact annotations will generalize to arbitrary in-the-wild occlusions and contacts without explicit physics or multi-view constraints.
What would settle it
Measure whether success rate on a fresh collection of egocentric clips with unseen contact patterns and heavy occlusions falls back to levels of prior methods.
Figures

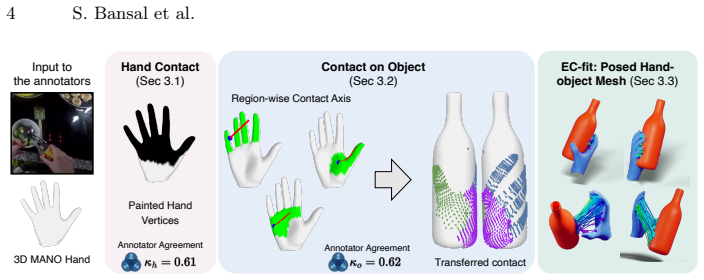













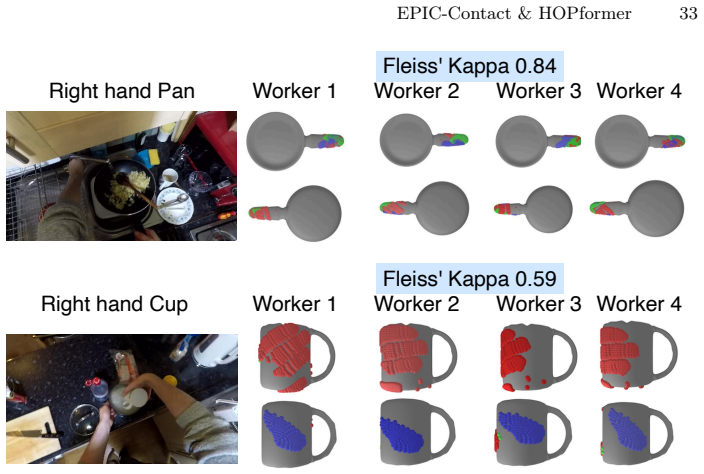
read the original abstract
Estimating accurate 3D hand-object pose from in-the-wild egocentric RGB remains challenging due to severe occlusions and ambiguous contact. Existing learning-based methods often struggle to generalise to in-the-wild scenes and are limited by the scarcity of supervision. We address these issues with two contributions. First, we introduce EPIC-Contact, an in-the-wild egocentric dataset of 2.3K clips (62.3K frames) with dense, bijective 3D hand-object contact correspondences and posed meshes. Second, we propose HOPformer, an end-to-end transformer that jointly predicts bi-manual hand and object pose in a single forward pass. A cross-attention decoder conditions object features on hand priors, producing robust pose estimation. We test HOPformer on the in-lab 3D dataset, ARCTIC, as well as our newly introduced EPIC-Contact dataset. HOPformer reaches 82.4% success rate on ARCTIC (+6.2 pts over current SOTA). On EPIC-Contact, it nearly doubles the success rate while reducing contact deviation by 75%. EPIC-Contact, HOPformer code and checkpoints are released: https://sid2697.github.io/epic-contact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EPIC-Contact, a new in-the-wild egocentric dataset of 2.3K clips (62.3K frames) annotated with dense bijective 3D hand-object contact correspondences and posed meshes, and proposes HOPformer, an end-to-end transformer architecture featuring a cross-attention decoder that conditions object features on hand priors for joint bi-manual hand and object pose prediction. It reports quantitative results on the in-lab ARCTIC benchmark (82.4% success rate, +6.2 pts over prior SOTA) and on the new EPIC-Contact dataset (nearly doubled success rate and 75% reduction in contact deviation), with public release of the dataset, code, and checkpoints.
Significance. If the reported gains hold under scrutiny, the work would provide a useful new resource and architecture for a practically relevant problem in egocentric vision. The explicit release of data, code, and checkpoints is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [§3.2] §3.2 (cross-attention decoder): the central claim that conditioning object features on hand priors via cross-attention yields robust in-the-wild estimation rests on the decoder implicitly learning contact physics and occlusion resolution from only the 2.3K EPIC-Contact clips; the manuscript provides no explicit contact loss, physics prior, or multi-view consistency term, and no ablation or attention-map analysis is described to show that the learned mechanism generalizes beyond the training distribution.
- [§4] §4 (quantitative results): the headline improvements (+6.2 pts on ARCTIC, doubled success rate and 75% lower contact deviation on EPIC-Contact) are load-bearing for the paper's contribution, yet the abstract and method description give no definition of the success-rate metric, no error bars, no statement of data splits or baseline re-implementation details, and no statistical significance test; these omissions prevent verification that the gains are not due to post-hoc choices.
minor comments (1)
- The phrase 'nearly doubles the success rate' in the abstract is imprecise; the exact percentages and absolute numbers should appear in the main results table or text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the cross-attention decoder and quantitative evaluation. We address each major comment below and will revise the manuscript to incorporate clarifications and additional analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (cross-attention decoder): the central claim that conditioning object features on hand priors via cross-attention yields robust in-the-wild estimation rests on the decoder implicitly learning contact physics and occlusion resolution from only the 2.3K EPIC-Contact clips; the manuscript provides no explicit contact loss, physics prior, or multi-view consistency term, and no ablation or attention-map analysis is described to show that the learned mechanism generalizes beyond the training distribution.
Authors: The architecture relies on end-to-end training with the dense bijective contact annotations provided in EPIC-Contact rather than an explicit contact or physics loss. This design choice allows the cross-attention to learn relevant dependencies for contact and occlusion handling. To directly address the request for evidence of the learned mechanism, we will add an ablation removing the cross-attention decoder and include attention-map visualizations in the revised manuscript. revision: yes
-
Referee: [§4] §4 (quantitative results): the headline improvements (+6.2 pts on ARCTIC, doubled success rate and 75% lower contact deviation on EPIC-Contact) are load-bearing for the paper's contribution, yet the abstract and method description give no definition of the success-rate metric, no error bars, no statement of data splits or baseline re-implementation details, and no statistical significance test; these omissions prevent verification that the gains are not due to post-hoc choices.
Authors: We agree the success-rate definition (percentage of frames where hand and object errors fall below fixed thresholds) should appear in the abstract and method section. Error bars, explicit data-split statements, baseline re-implementation notes, and a statistical significance test will be added to Section 4 and the tables. Reproducibility details are already in the released code and supplementary material. revision: yes
Circularity Check
No circularity: empirical results on external and new datasets
full rationale
The paper reports empirical success rates (82.4% on ARCTIC external benchmark; doubled success and 75% lower contact deviation on newly introduced EPIC-Contact) measured on test splits. No equations, derivations, or fitted parameters are shown that reduce these metrics to quantities defined or fitted on the same test data by construction. The cross-attention decoder is presented as a learned component trained on the new annotations, but the reported numbers are direct evaluations, not self-definitional or renamed fits. The work is self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling in the performance claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised learning assumptions hold: the provided 3D annotations are sufficiently accurate and representative for training a generalizable model.
Reference graph
Works this paper leans on
-
[1]
Abou Zeid, K.: JointTransformer: Winner of the HANDS’2023 ARCTIC Challenge @ ICCV (2023),https://github.com/kabouzeid/JointTransformer1, 2, 3, 11, 12, 26
2023
-
[2]
In: CVPR (2025) 1, 2, 3
Banerjee, P., Shkodrani, S., Moulon, P., Hampali, S., Han, S., Zhang, F., Zhang, L., Fountain, J., Miller, E., Basol, S., Newcombe, R., Wang, R., Engel, J.J., Hodan, T.: HOT3D: Hand and object tracking in 3D from egocentric multi-view videos. In: CVPR (2025) 1, 2, 3
2025
-
[3]
In: CVPR (2019) 2, 10
Boukhayma, A., Bem, R.d., Torr, P.H.: 3d hand shape and pose from images in the wild. In: CVPR (2019) 2, 10
2019
-
[4]
In: ECCV (2020) 3, 35
Brahmbhatt, S., Tang, C., Twigg, C.D., Kemp, C.C., Hays, J.: ContactPose: A dataset of grasps with object contact and hand pose. In: ECCV (2020) 3, 35
2020
-
[5]
In: ECCV (2018) 3
Cai, Y., Ge, L., Cai, J., Yuan, J.: Weakly-supervised 3D hand pose estimation from monocular RGB images. In: ECCV (2018) 3
2018
-
[6]
In: ICCV (2021) 1, 3
Cao, Z., Radosavovic, I., Kanazawa, A., Malik, J.: Reconstructing hand-object interactions in the wild. In: ICCV (2021) 1, 3
2021
-
[7]
In: ECCV (2020) 9
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-End Object Detection with Transformers. In: ECCV (2020) 9
2020
-
[8]
In: CVPR (2021) 1, 3
Chao,Y.W.,Yang,W.,Xiang, Y.,Molchanov,P.,Handa,A., Tremblay, J.,Narang, Y.S., Van Wyk, K., Iqbal, U., Birchfield, S., Kautz, J., Fox, D.: DexYCB: A bench- mark for capturing hand grasping of objects. In: CVPR (2021) 1, 3
2021
-
[9]
In: CVPR (2026) 3, 25
Chen, X., CHU, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J.W., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Malik, J.: SAM 3D: 3Dfy Anything in Images. In: CVPR (2026) 3, 25
2026
-
[10]
In: ICCV (2025) 3
Chen, Z., Potamias, R.A., Chen, S., Schmid, C.: HORT: Monocular hand-held objects reconstruction with transformers. In: ICCV (2025) 3
2025
-
[11]
Comanici, G., Bieber, E., Schaekermann, M., Sachdeva, N., et al.: Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv preprint arXiv:2507.06261 (2025) 6, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: CVPR (2025) 2, 4, 6, 32
Cseke, A., Tripathi, S., Dwivedi, S.K., Lakshmipathy, A., Chatterjee, A., Black, M.J., Tzionas, D.: PICO: Reconstructing 3D people in contact with objects. In: CVPR (2025) 2, 4, 6, 32
2025
-
[13]
In: IJCV (2022) 3
Damen, D., Doughty, H., Farinella, G.M., Furnari, A., Ma, J., Kazakos, E., Molti- santi, D., Munro, J., Perrett, T., Price, W., Wray, M.: Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. In: IJCV (2022) 3
2022
-
[14]
In: NeurIPS (2022) 6, 26
Darkhalil, A., Shan, D., Zhu, B., Ma, J., Kar, A., Higgins, R., Fidler, S., Fouhey, D., Damen, D.: EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations. In: NeurIPS (2022) 6, 26
2022
-
[15]
In: CVPR (2024) 3, 24
Fan, Z., Parelli, M., Kadoglou, M.E., Chen, X., Kocabas, M., Black, M.J., Hilliges, O.: Hold: Category-agnostic 3d reconstruction of interacting hands and objects from video. In: CVPR (2024) 3, 24
2024
-
[16]
In: CVPR (2023) 1, 2, 3, 10, 11, 12, 20, 21, 22, 26
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: ARCTIC: A dataset for dexterous bimanual hand-object manipulation. In: CVPR (2023) 1, 2, 3, 10, 11, 12, 20, 21, 22, 26
2023
-
[17]
In: CVPR (2018) 3, 35 EPIC-Contact & HOPformer 17
Garcia-Hernando, G., Yuan, S., Baek, S., Kim, T.K.: First-person hand action benchmark with rgb-d videos and 3d hand pose annotations. In: CVPR (2018) 3, 35 EPIC-Contact & HOPformer 17
2018
-
[18]
In: CVPR (2019) 3
Ge, L., Ren, Z., Li, Y., Xue, Z., Wang, Y., Cai, J., Yuan, J.: 3D hand shape and pose estimation from a single rgb image. In: CVPR (2019) 3
2019
-
[19]
In: CVPR (2021) 3
Grady, P., Tang, C., Twigg, C., Vo, M., Brahmbhatt, S., Kemp, C.: ContactOpt: Optimizing contact to improve grasps. In: CVPR (2021) 3
2021
-
[20]
In: CVPR (2023) 3
Guo, Z., Zhou, W., Wang, M., Li, L., Li, H.: HandNeRF: Neural radiance fields for animatable interacting hands. In: CVPR (2023) 3
2023
-
[21]
In: CVPR (2023) 3
Hampali, S., Hodan, T., Tran, L., Ma, L., Keskin, C., Lepetit, V.: In-hand 3d object scanning from an rgb sequence. In: CVPR (2023) 3
2023
-
[22]
In: CVPR (2020) 6, 35
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: Honnotate: A method for 3d annotation of hand and object poses. In: CVPR (2020) 6, 35
2020
-
[23]
In: arXiv preprint arXiv:2510.14874 (2025) 6
Han, G., Zhai, W., Yang, Y., Cao, Y., Zha, Z.J.: Touch: Text-guided con- trollable generation of free-form hand-object interactions. In: arXiv preprint arXiv:2510.14874 (2025) 6
-
[24]
In: CVPR (2020) 3
Hasson, Y., Tekin, B., Bogo, F., Laptev, I., Pollefeys, M., Schmid, C.: Leveraging Photometric Consistency Over Time for Sparsely Supervised Hand-Object Recon- struction. In: CVPR (2020) 3
2020
-
[25]
In: 3DV (2021) 1, 3, 20
Hasson, Y., Varol, G., Schmid, C., Laptev, I.: Towards unconstrained joint hand- object reconstruction from rgb videos. In: 3DV (2021) 1, 3, 20
2021
-
[26]
In: CVPR (2016) 3, 11
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016) 3, 11
2016
-
[27]
In: SIGGRAPH Asia (2022) 3
Huang, D., Ji, X., He, X., Sun, J., He, T., Shuai, Q., Ouyang, W., Zhou, X.: Reconstructing hand-held objects from monocular video. In: SIGGRAPH Asia (2022) 3
2022
-
[28]
In: ECCV (2018) 3
Iqbal, U., Molchanov, P., Gall, T., Kautz, J.: Hand pose estimation via latent 2.5D heatmap regression. In: ECCV (2018) 3
2018
-
[29]
In: ICCV (2021) 3, 33, 35
Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reasoning for human grasps generation. In: ICCV (2021) 3, 33, 35
2021
-
[30]
In: ECCV (2020) 3
Jin, S., Xu, L., Xu, J., Wang, C., Liu, W., Qian, C., Ouyang, W., Luo, P.: Whole- body human pose estimation in the wild. In: ECCV (2020) 3
2020
-
[31]
In: CVPR (2018) 10
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end Recovery of Hu- man Shape and Pose. In: CVPR (2018) 10
2018
-
[32]
In: ICCV (2021) 10
Kocabas, M., Huang, C.H.P., Hilliges, O., Black, M.J.: PARE: Part attention re- gressor for 3D human body estimation. In: ICCV (2021) 10
2021
-
[33]
In: CVPR (2020) 2
Kulon, D., Guler, R.A., Kokkinos, I., Bronstein, M.M., Zafeiriou, S.: Weakly- supervised mesh-convolutional hand reconstruction in the wild. In: CVPR (2020) 2
2020
-
[34]
In: BMVC (2019) 2
Kulon, D., Wang, H., Güler, R.A., Bronstein, M.M., Zafeiriou, S.: Single Image 3D Hand Reconstruction with Mesh Convolutions. In: BMVC (2019) 2
2019
-
[35]
In: ICCV (2021) 1, 2, 3
Kwon, T., Tekin, B., Stühmer, J., Bogo, F., Pollefeys, M.: H2O: Two Hands Ma- nipulating Objects for First Person Interaction Recognition. In: ICCV (2021) 1, 2, 3
2021
-
[36]
In: ACM Trans- actions on Graphics (2023) 5
Lakshmipathy, A.S., Feng, N., Lee, Y.X., Mahler, M., Pollard, N.: Contact Edit: Artist Tools for Intuitive Modeling of Hand-Object Interactions. In: ACM Trans- actions on Graphics (2023) 5
2023
-
[37]
In: CVPR (2023) 3
Lee, J., Sung, M., Choi, H., Kim, T.: Im2hands: Learning attentive implicit repre- sentation of interacting two-hand shapes. In: CVPR (2023) 3
2023
-
[38]
In: CVPR (2022) 3
Li, M., An, L., Zhang, H., Wu, L., Chen, F., Yu, T., Liu, Y.: Interacting attention graph for single image two-hand reconstruction. In: CVPR (2022) 3
2022
-
[39]
In: CVPR (2021) 3 18 S
Lin, K., Wang, L., Liu, Z.: End-to-end human pose and mesh reconstruction with transformers. In: CVPR (2021) 3 18 S. Bansal et al
2021
-
[40]
In: CVPR (2024) 3
Liu, R., Ohkawa, T., Zhang, M., Sato, Y.: Single-to-dual-view adaptation for ego- centric 3d hand pose estimation. In: CVPR (2024) 3
2024
-
[41]
In: CVPR (2022) 1, 2, 3
Liu, Y., Liu, Y., Jiang, C., Lyu, K., Wan, W., Shen, H., Liang, B., Fu, Z., Wang, H., Yi, L.: HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction. In: CVPR (2022) 1, 2, 3
2022
-
[42]
In: ICLR (2019) 10
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019) 10
2019
-
[43]
In: ECCV (2020) 3
Moon, G., Yu, S.I., Wen, H., Shiratori, T., Lee, K.M.: InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image. In: ECCV (2020) 3
2020
-
[44]
In: CVPR (2018) 3
Mueller, F., Bernard, F., Sotnychenko, O., Mehta, D., Sridhar, S., Casas, D., Theobalt, C.: GANerated hands for real-time 3D hand tracking from monocular RGB. In: CVPR (2018) 3
2018
-
[45]
In: IJCV (2023) 3
Ohkawa, T., Furuta, R., Sato, Y.: Efficient annotation and learning for 3d hand pose estimation: A survey. In: IJCV (2023) 3
2023
-
[46]
TMLR (2024) 3, 10, 11, 21
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning Robust Visual Feat...
2024
-
[47]
In: arXiv preprint arXiv:2211.13225 (2022) 1, 3
Patel, A., Wang, A., Radosavovic, I., Malik, J.: Learning to imitate object inter- actions from internet videos. In: arXiv preprint arXiv:2211.13225 (2022) 1, 3
-
[48]
In: CVPR (2024) 2, 3
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing Hands in 3D with Transformers. In: CVPR (2024) 2, 3
2024
-
[49]
In: CVPR (2025) 2, 3, 5, 6, 7, 10, 21, 26, 32, 35
Potamias, R.A., Zhang, J., Deng, J., Zafeiriou, S.: Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. In: CVPR (2025) 2, 3, 5, 6, 7, 10, 21, 26, 32, 35
2025
-
[50]
In: ECCV (2024) 2, 3
Prakash, A., Chang, M., Jin, M., Tu, R., Gupta, S.: 3d reconstruction of objects in hands without real world 3d supervision. In: ECCV (2024) 2, 3
2024
-
[51]
In: ICCV (2015) 3, 35
Rogez, G., Supancic, J.S., Ramanan, D.: Understanding everyday hands in action from rgb-d images. In: ICCV (2015) 3, 35
2015
-
[52]
In: ACM Transactions on Graphics (2017) 5, 8, 28
Romero, J., Tzionas, D., Black, M.J.: Embodied Hands: Modeling and Capturing Hands and Bodies Together. In: ACM Transactions on Graphics (2017) 5, 8, 28
2017
-
[53]
In: ICCVW (2021) 2
Rong, Y., Shiratori, T., Joo, H.: Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration. In: ICCVW (2021) 2
2021
-
[54]
In: CVPR (2017) 3
Simon, T., Joo, H., Matthews, I., Sheikh, Y.: Hand keypoint detection in single images using multiview bootstrapping. In: CVPR (2017) 3
2017
-
[55]
In: ECCV (2020) 2
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: GRAB: A dataset of whole- body human grasping of objects. In: ECCV (2020) 2
2020
-
[56]
In: CVPR (2019) 3
Tekin, B., Bogo, F., Pollefeys, M.: H+O: Unified egocentric recognition of 3D hand-object poses and interactions. In: CVPR (2019) 3
2019
-
[57]
In: ICCV (2023) 2, 4, 5, 6, 30, 32
Tripathi, S., Chatterjee, A., Passy, J.C., Yi, H., Tzionas, D., Black, M.J.: DECO: Dense estimation of 3D human-scene contact in the wild. In: ICCV (2023) 2, 4, 5, 6, 30, 32
2023
-
[58]
In: CVPR (2022) 3
Tse, T., Kim, K., Leonardis, A., Chang, H.: Collaborative learning for hand and object reconstruction with attention-guided graph convolution. In: CVPR (2022) 3
2022
-
[59]
In: CVPR (2022) 3 EPIC-Contact & HOPformer 19
Yang, L., Li, K., Zhan, X., Lv, J., Xu, W., Li, J., Lu, C.: Artiboost: Boosting articulated 3d hand-object pose estimation via online exploration and synthesis. In: CVPR (2022) 3 EPIC-Contact & HOPformer 19
2022
-
[60]
In: CVPR (2022) 1, 2, 3
Yang, L., Li, K., Zhan, X., Wu, F., Xu, A., Liu, L., Lu, C.: Oakink: A large-scale knowledge repository for understanding hand-object interaction. In: CVPR (2022) 1, 2, 3
2022
-
[61]
In: ICCV (2021) 3
Yang,L.,Zhan,X.,Li,K.,Xu,W.,Li,J.,Lu,C.:CPF:Learningacontactpotential field to model the hand-object interaction. In: ICCV (2021) 3
2021
-
[62]
In: CVPR (2024) 4
Yang, Y., Zhai, W., Luo, H., Cao, Y., Zha, Z.J.: LEMON: Learning 3D Human- Object Interaction Relation from 2D Images. In: CVPR (2024) 4
2024
-
[63]
In: NeurIPS (2024) 4
Yang, Y., Zhai, W., Wang, C., Yu, C., Cao, Y., Zha, Z.J.: EgoChoir: Capturing 3D Human-Object Interaction Regions from Egocentric Views. In: NeurIPS (2024) 4
2024
-
[64]
arXiv preprint arXiv:2501.08329 (2025) 3
Ye, Y., Feng, Y., Taheri, O., Feng, H., Tulsiani, S., Black, M.J.: Predicting 4d hand trajectory from monocular videos. arXiv preprint arXiv:2501.08329 (2025) 3
-
[65]
In: CVPR (2024) 3, 24, 35
Ye, Y., Gupta, A., Kitani, K., Tulsiani, S.: G-hop: Generative hand-object prior for interaction reconstruction and grasp synthesis. In: CVPR (2024) 3, 24, 35
2024
-
[66]
In: CVPR (2022) 3
Ye, Y., Gupta, A., Tulsiani, S.: What’s in your hands? 3d reconstruction of generic objects in hands. In: CVPR (2022) 3
2022
-
[67]
In: ICCV (2023) 3
Ye, Y., Hebbar, P., Gupta, A., Tulsiani, S.: Diffusion-guided reconstruction of everyday hand-object interaction clips. In: ICCV (2023) 3
2023
-
[68]
In: ICCV (2025) 3
Yu, Z., Xu, W., Xie, P., Li, Y., Anthony, B.W., Zhang, Z., Lu, C.: Dynamic re- construction of hand-object interaction with distributed force-aware contact rep- resentation. In: ICCV (2025) 3
2025
-
[69]
In: CVPR (2022) 10
Zhai, X., Kolesnikov, A., Houlsby, N., Beyer, L.: Scaling vision transformers. In: CVPR (2022) 10
2022
-
[70]
In: CVPR (2025) 3
Zhang, J., Deng, J., Ma, C., Potamias, R.A.: Hawor: World-space hand motion reconstruction from egocentric videos. In: CVPR (2025) 3
2025
-
[71]
In: ICCV (2019) 10
Zhang, X., Li, Q., Mo, H., Zhang, W., Zheng, W.: End-to-end hand mesh recovery from a monocular rgb image. In: ICCV (2019) 10
2019
-
[72]
In: CVPR (2019) 8, 10
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the Continuity of Rotation Representations in Neural Networks. In: CVPR (2019) 8, 10
2019
-
[73]
In: CVPRW (2026) 6
Zhu, Z., Bansal, S., Tripathi, S., Damen, D.: Reconstructing Objects along Hand Interaction Timelines in Egocentric Video. In: CVPRW (2026) 6
2026
-
[74]
In: arXiv (2024) 3, 4, 6, 7, 10, 20, 26
Zhu, Z., Damen, D.: Get a grip: Reconstructing hand-object stable grasps in ego- centric videos. In: arXiv (2024) 3, 4, 6, 7, 10, 20, 26
2024
-
[75]
stable grasp
Zimmermann, C., Ceylan, D., Yang, J., Russell, B., Argus, M., Brox, T.: Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In: ECCV (2019) 3 20 S. Bansal et al. Appendix This appendix provides supplementary information for the main paper. Sec- tion 7 provides additional details on HOPformer including the compute, met...
2019
-
[76]
diameter
Synthesise and Finalise: Combine the visual information with common knowledge about typical bowl sizes to produce the most plausible final es- timates for both required dimensions. 7. Convert and Format: Ensure both final estimates are in metres and format them into the specified JSON struc- ture. Prompt for Can(two degrees-of-scale): You are an expert AI...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.