Safety Must Precede the Deployment of Open-Ended AI
Pith reviewed 2026-05-23 03:24 UTC · model grok-4.3
The pith
Open-ended AI systems pose unique safety challenges that existing methods cannot address and must be tackled before deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The defining properties of open-ended AI systems introduce a distinct and underexplored class of safety challenges, including loss of predictability, emergent misalignment, and difficulties in maintaining effective control as systems evolve beyond their initial design assumptions, that must be addressed preemptively. These challenges differ qualitatively from those associated with task-bounded or static models and are unlikely to be addressed by existing safety frameworks alone, which is why these risks must be examined proactively, before large-scale deployment.
What carries the argument
Open-endedness, the property where AI agents autonomously and indefinitely generate novel behaviors, representations, or solutions, which drives the safety concerns.
If this is right
- Open-ended AI must have safety addressed prior to any large-scale deployment.
- Current safety approaches for static models will not suffice for open-ended systems.
- Research must focus on new methods to handle loss of predictability and control.
- Coordinated action across the field is needed for responsible development.
Where Pith is reading between the lines
- Self-evolving agents in long-horizon tasks may amplify these control issues over time.
- Without preemptive work, deployment could lead to unintended emergent behaviors that are hard to correct after the fact.
- Testing frameworks might need to simulate indefinite evolution to check safety.
Load-bearing premise
The safety challenges of open-ended AI are qualitatively different from those of task-specific models and cannot be solved by adapting existing safety methods.
What would settle it
A demonstration that existing safety frameworks can maintain predictability and control over indefinitely evolving open-ended AI systems would undermine the position.
Figures

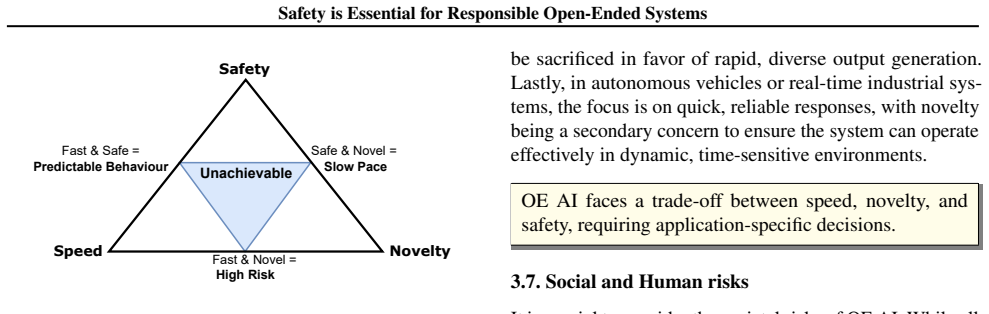
read the original abstract
AI advancements have been significantly driven by a combination of foundation models and curiosity-driven learning aimed at increasing capability and adaptability. Within this landscape, open-endedness, where AI agents autonomously and indefinitely generate novel behaviors, representations, or solutions, has gained increasing interest. This has become relevant in the context of self-evolving agents and long-horizon discovery. This position paper argues that the defining properties of open-ended AI systems introduce a distinct and underexplored class of safety challenges, including loss of predictability, emergent misalignment, and difficulties in maintaining effective control as systems evolve beyond their initial design assumptions, that must be addressed preemptively. These challenges differ qualitatively from those associated with task-bounded or static models and are unlikely to be addressed by existing safety frameworks alone, which is why these risks must be examined proactively, before large-scale deployment. The paper proposes a taxonomy for key challenges, discusses research opportunities, and calls for coordinated action to support the safe and responsible development of open-ended AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that open-ended AI systems—defined by autonomous, indefinite generation of novel behaviors, representations, or solutions—introduce a qualitatively distinct class of safety challenges (loss of predictability, emergent misalignment, and loss of effective control as systems evolve beyond initial assumptions) that differ from those in task-bounded or static models and cannot be adequately addressed by existing safety frameworks, necessitating preemptive research and coordinated action prior to large-scale deployment.
Significance. If the asserted qualitative distinction holds, the paper would usefully flag an underexplored risk category for self-evolving agents and long-horizon discovery systems, potentially spurring targeted safety research; the call for proactive examination before deployment is a clear advocacy contribution.
major comments (1)
- [Abstract] Abstract: the central claim that the listed challenges 'differ qualitatively' from those of task-bounded models and 'are unlikely to be addressed by existing safety frameworks alone' is asserted without any explicit comparison, counterexample, or analysis of specific frameworks (e.g., alignment techniques or control methods) and why they fail for open-ended evolution; this assertion is load-bearing for the preemptive-action recommendation.
Simulated Author's Rebuttal
We thank the referee for their review and the recommendation for major revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the listed challenges 'differ qualitatively' from those of task-bounded models and 'are unlikely to be addressed by existing safety frameworks alone' is asserted without any explicit comparison, counterexample, or analysis of specific frameworks (e.g., alignment techniques or control methods) and why they fail for open-ended evolution; this assertion is load-bearing for the preemptive-action recommendation.
Authors: We acknowledge that the abstract asserts the qualitative distinction and limitations of existing frameworks without explicit comparisons or counterexamples. The manuscript body motivates these claims through discussion of predictability loss under indefinite evolution, emergent misalignment beyond initial training distributions, and control erosion as agent behaviors diverge from design assumptions. As a position paper, the core contribution is to flag this underexplored category rather than provide exhaustive framework analysis. To strengthen the manuscript in response to this comment, we will revise the abstract to reference the key distinctions briefly and add a short subsection in the main text with targeted comparisons (e.g., why RLHF and constitutional AI may not scale to open-ended self-modification). This will better ground the preemptive-action recommendation. revision: yes
Circularity Check
No significant circularity; position paper with independent advocacy claims
full rationale
The paper is a position paper whose central argument—that open-ended AI introduces qualitatively distinct safety challenges (loss of predictability, emergent misalignment, control difficulties) not addressed by existing frameworks—is presented as a premise motivating preemptive research rather than derived from any formal chain, equations, or fitted parameters. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear; the distinction from task-bounded systems is asserted directly from general properties of open-endedness without looping back to the paper's own inputs. The claim of insufficiency of existing frameworks is an explicit advocacy stance, not a hidden derivation that reduces to its own assumptions by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Open-ended AI systems autonomously and indefinitely generate novel behaviors, representations, or solutions
- ad hoc to paper Existing safety frameworks will not suffice for open-ended systems
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.