Stabilizing the Splits through Minimax Decision Trees
Pith reviewed 2026-05-23 02:57 UTC · model grok-4.3
The pith
MinimaxSplit decision trees select splits by minimizing worst-case child risk rather than average risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MinimaxSplit decision trees select splits by minimizing the maximum within-child risk (squared error for regression, entropy for classification) rather than the average risk. Oracle inequalities are established that cover both regression and classification under mild marginal non-atomicity conditions on the covariate distributions. The bounds control the tree's global excess risk by local worst-case impurities and yield fast convergence rates compared to CART. The main method studied is the cyclic variant that deterministically cycles through coordinates, and the analysis extends to random-dimension forests that subsample coordinates per node.
What carries the argument
The minimax split criterion that selects the split minimizing the maximum child risk (squared error or entropy) instead of the average risk.
If this is right
- Oracle inequalities hold simultaneously for squared-error regression and entropy-based classification.
- Global excess risk is bounded above by local worst-case child impurities.
- Convergence rates are faster than the corresponding rates for CART trees.
- The cyclic variant cycles deterministically through coordinates at each node.
- Random-dimension forest variants subsample coordinates at each node while retaining the minimax split rule.
Where Pith is reading between the lines
- The same worst-case control might extend to other splitting criteria or to boosted tree ensembles.
- Structured spatial or temporal data may benefit from the deterministic cycling in the cyclic variant.
- High-dimensional settings with many irrelevant coordinates could see further gains from the random-dimension extension.
Load-bearing premise
The mild marginal non-atomicity conditions on the covariate distributions are required to establish the oracle inequalities.
What would settle it
A concrete counterexample showing that the oracle inequality fails on a covariate distribution containing atoms would falsify the central claim.
Figures









read the original abstract
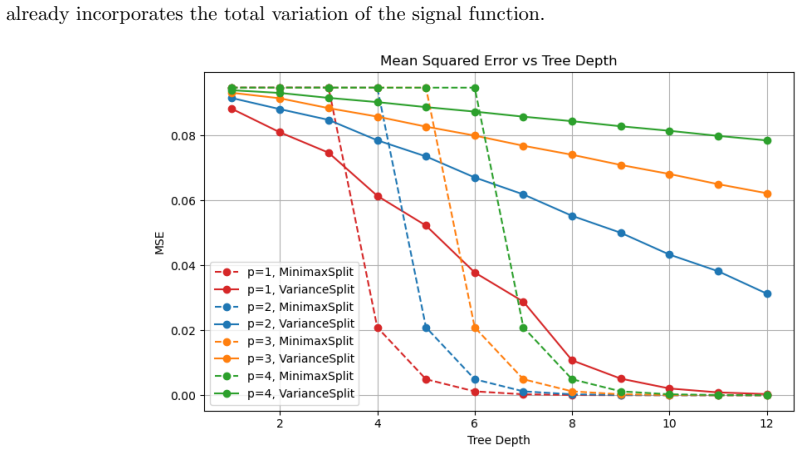
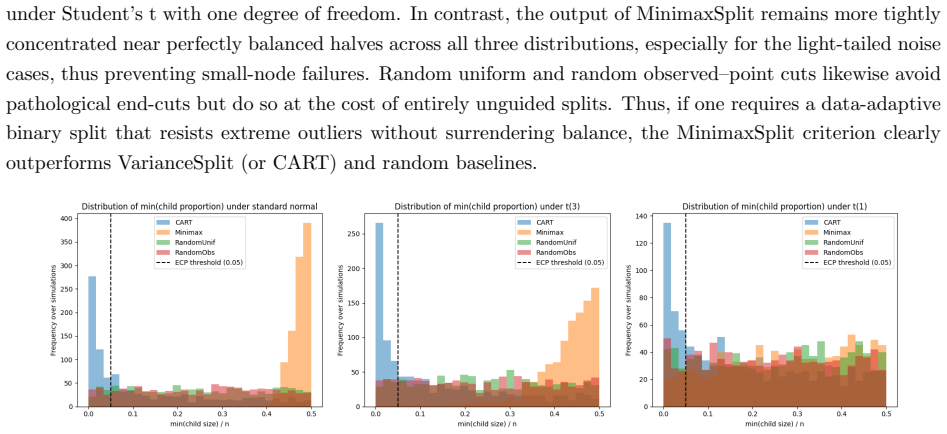
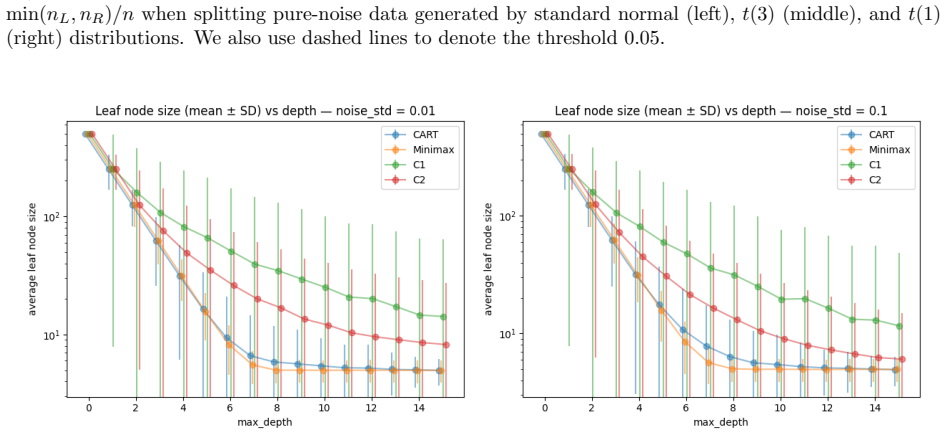
By revisiting the end-cut preference (ECP) phenomenon associated with a single CART (Breiman et al. (1984)), we introduce MinimaxSplit decision trees, a robust alternative to CART that selects splits by minimizing the worst-case child risk rather than the average risk. For regression, we minimize the maximum within-child squared error; for classification, we minimize the maximum child entropy, yielding a C4.5-compatible criterion. We also study a cyclic variant that deterministically cycles coordinates, leading to our main method of cyclic MinimaxSplit decision trees. We prove oracle inequalities that cover both regression and classification, under mild marginal non-atomicity conditions. The bounds control the tree's global excess risk by local worst-case impurities and yield fast convergence rates compared to CART. We extend the analysis to a random-dimension forest variant that subsamples coordinates per node. Empirically, (cyclic) MinimaxSplit trees and their forests improve over baselines on structured heterogeneous data such as EEG amplitude regression over fixed time horizons and image denoising, framed as non-parametric regression on spatial coordinates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MinimaxSplit decision trees that select splits by minimizing the worst-case child impurity (maximum within-child squared error for regression; maximum child entropy for classification) rather than the average impurity used in CART, to address the end-cut preference phenomenon. A cyclic variant that deterministically cycles through coordinates is presented as the main method, along with a random-dimension forest extension. Oracle inequalities are claimed for both regression and classification tasks under mild marginal non-atomicity conditions on the covariates; these bounds relate the tree's global excess risk to local worst-case impurities and are asserted to yield faster convergence rates than CART. Empirical results on EEG amplitude regression and image denoising (framed as spatial regression) are reported to show improvements over baselines.
Significance. If the oracle inequalities hold with the stated rates under the invoked conditions, the work would supply a theoretically grounded splitting criterion that stabilizes tree construction while retaining interpretability, with potential applicability to heterogeneous structured data. The combination of minimax criterion, cyclic coordinate handling, and forest extension, together with the claimed oracle bounds, would distinguish it from standard CART analyses.
major comments (2)
- [Abstract] Abstract (oracle inequalities paragraph): the claimed oracle inequalities for regression and classification rest on 'mild marginal non-atomicity conditions' whose precise statement (e.g., absolute continuity of marginals, absence of atoms of positive probability, or uniform density lower bounds) is not supplied. Without this, it is impossible to verify necessity, check satisfaction on the EEG/image examples, or confirm that the proof technique does not collapse when the conditions fail; this is load-bearing for the central theoretical claim.
- [Abstract] Abstract (bounds paragraph): the statement that the bounds 'control the tree's global excess risk by local worst-case impurities' requires an explicit inequality (with constants and remainder terms) to assess whether the control is tight enough to deliver the asserted faster rates relative to CART; the current phrasing leaves the quantitative relationship between local minimax impurity and global excess risk unstated.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The points raised concern the level of detail in the abstract regarding the non-atomicity conditions and the quantitative form of the oracle inequalities. We address each comment below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (oracle inequalities paragraph): the claimed oracle inequalities for regression and classification rest on 'mild marginal non-atomicity conditions' whose precise statement (e.g., absolute continuity of marginals, absence of atoms of positive probability, or uniform density lower bounds) is not supplied. Without this, it is impossible to verify necessity, check satisfaction on the EEG/image examples, or confirm that the proof technique does not collapse when the conditions fail; this is load-bearing for the central theoretical claim.
Authors: We agree that the abstract would benefit from a concise statement of the conditions. Section 2.2 of the manuscript defines them explicitly as: the marginal distribution of each covariate is non-atomic, i.e., P(X_j = x) = 0 for every coordinate j and every x. This is weaker than absolute continuity or density lower bounds and is the minimal assumption used in the proofs to guarantee that splits exist with positive probability mass on both children. The EEG amplitude and image coordinate data consist of continuous measurements and therefore satisfy the condition; we will add a sentence in the empirical section confirming this. We will revise the abstract to read: 'under the mild assumption that the marginal distributions of the covariates are non-atomic.' revision: yes
-
Referee: [Abstract] Abstract (bounds paragraph): the statement that the bounds 'control the tree's global excess risk by local worst-case impurities' requires an explicit inequality (with constants and remainder terms) to assess whether the control is tight enough to deliver the asserted faster rates relative to CART; the current phrasing leaves the quantitative relationship between local minimax impurity and global excess risk unstated.
Authors: The explicit inequalities appear in Theorems 3.1 (regression) and 4.2 (classification). For regression they take the form R(hat f) - R(f*) <= C * (sum over leaves of the minimax child impurity) + o(1) as n -> infinity, where C depends only on tree depth; an analogous bound holds for classification with entropy. The non-atomicity ensures the o(1) term vanishes at the stated rate, which is faster than the corresponding CART bounds because the minimax criterion directly controls the worst-case child impurity rather than an average. We will revise the abstract to include a high-level version of this relation, e.g., 'with global excess risk bounded by a multiple of the sum of local minimax impurities plus a vanishing remainder.' revision: yes
Circularity Check
No significant circularity; oracle inequalities derived independently from new minimax criterion
full rationale
The paper defines the MinimaxSplit criterion (max within-child squared error for regression; max child entropy for classification) independently of the target excess-risk quantity. Oracle inequalities are proved from this definition under external marginal non-atomicity assumptions, without any reduction of the bounds to fitted parameters, self-citations, or renaming of known results. The derivation chain is self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild marginal non-atomicity conditions
Forward citations
Cited by 2 Pith papers
-
The maximum-entropy median-martingale
The maximum-entropy median-martingale walk on [0,1] has the arcsine distribution as its stationary distribution, with a proof connecting it to classical arcsine laws for Brownian motion.
-
The maximum-entropy median-martingale
The maximum-entropy median-martingale on [0,1] has the arcsine distribution as its stationary distribution, with a proof linking it to two classical arcsine laws for Brownian motion, plus a generalization of martingal...
Reference graph
Works this paper leans on
-
[1]
Matias D Cattaneo, Jason M Klusowski, and Peter M Tian. On the pointwise behavior of recursive parti- tioning and its implications for heterogeneous causal effect estimation.arXiv preprint arXiv:2211.10805,
-
[2]
PhD thesis. Hengrui Luo and Matthew T Pratola. Sharded Bayesian additive regression trees.arXiv preprint arXiv:2306.00361,
-
[3]
Efficient decision trees for tensor regressions.arXiv preprint arXiv:2408.01926,
Hengrui Luo, Akira Horiguchi, and Li Ma. Efficient decision trees for tensor regressions.arXiv preprint arXiv:2408.01926,
-
[4]
A On partition-based martingale approximations In this section, we develop the framework of partition-based martingale approximations and show that a number of constructions feature exponential convergence rates. These problems are of their own interest (see the end of Appendix A.1) and have implications in the regression tree setting. The main takeaway i...
work page 1953
-
[5]
sizes” ofU1 {U∈I} on the two sets. The “size
UnlessUis a constant, there are different partition-based martingale approximations depending on the distribution ofU. Our goal in this section is to identify a few partition-based martingale approximations that efficiently approximateU, where the construction algorithm is universal. The efficiency criterion is given by the decay of the MSEE[(U−M k)2]. Th...
work page 1970
-
[6]
and Markovian walks (Grama et al., 2018). Note that in our setting,Yis a sum of martingale differences, but whose variance is bounded, and hence one cannot apply the martingale CLT or its convergence rates. In the next two sections, we discuss two types of results:uniformrates for boundedU(Appendix A.2) and non-uniformrates (Appendix A.3) where the asympt...
work page 2018
-
[7]
Proof.Let suppM 1 ={x, y}wherex < y. TakeM >sup{x, y}. Letτ + M be the first hitting time to {x:x⩾M},τ − M be the first hitting time to{x:x⩽−M}, andτ M = min{τ + M , τ − M }. It is straightforward to prove (see the proof of Lemma 5.6 of Zhang et al. (2024)) that for somer∈(0,1) andC >0, E[(U−M k)2]⩽E[1 {τM <∞}U2] +CM 2rk. Since the supports of{M k}k⩾0 cor...
work page 2024
-
[8]
(2024), and our proof of Theorem 19 follows a similar route
The case of the Simons martingale has been established by Zhang et al. (2024), and our proof of Theorem 19 follows a similar route. Since the 31 asymptotic constant is allowed to depend on the law ofU, the optimal non-uniform ratermight be smaller than the uniform ones (in Theorem 16). Recall from Appendix A.2 that the rates obtained in Theorem 16 are asy...
work page 2024
-
[9]
It follows from (36) that (35) holds for someu ∗ ∈[u 1, u2]
Therefore, the mapu7→P(U⩽u) is constant on [u 1, u2] and for eachu∈[u 1, u2], (E[U|U⩽u],E[U| U > u]) = (m a(pvar), mb(pvar)). It follows from (36) that (35) holds for someu ∗ ∈[u 1, u2]. Using the definition (34) andp var =P(U⩽u var), we haveu var = max u∈[u1,u2] u=u 2, which implies that P(U⩽u ∗) =P(U⩽u var). Therefore, in both cases, the desired claim i...
work page 2015
-
[10]
This shows (44) and thus proves (43)
It follows that E h ( √ δ Y− 1 +δ√ δ X)2 i ⩾E h√ δ Y− 1 +δ√ δ X i2 = (1 +δ) 2 δ E[X]2 ⩾ (1 +δ) 2 δ (inf suppX) 2 ⩾ (1 +δ) δ (sup suppX) 2 ⩾ 1 +δ δ E[X2]. This shows (44) and thus proves (43). Proof of Theorem 2.We divide the proof into three steps. Step I: reducing to an inequality involvingVar(Y).We claim that it suffices to prove E[(Y−M k)2]⩽inf g∈G (1 ...
work page 2024
-
[11]
Again we follow the arguments in the proof of Theorem 4.3 for CART of Klusowski and Tian (2024). By settingM= 2UwhereU= max|Y i|, the extra term of 8 3 2kM2 N e− k 6d + d n1/3 ⩽C 2kU2 N + 2kU2d N n1/3 is carried until (B.34) of Klusowski and Tian (2024). The term 2 kU2/Nis absorbed by the term U42k log(N d)/Ntherein. The other term 2 kU2d/(N n1/3) is carr...
work page 2024
-
[12]
Here, we use the notationξ n =O P(αn) if the sequence{ξ n/αn}is tight
It follows from standard arguments in van der Vaart and Wellner (2013) that the class{f1 R}R∈R is a Donsker class, so withm R =E P∗[f(X)|X∈R], we have sup R∈R |EPn[f(X)|X∈R]−m R|=O P(1/√n). Here, we use the notationξ n =O P(αn) if the sequence{ξ n/αn}is tight. Letg R(x) = (f(x)−m R)2 forR∈ R. The class {gR1 R}R∈R is also Donsker. ForR∈ R, letV R denote th...
work page 2013
-
[13]
Consider a rectangleR a,b = [a, b]×[−1,1]∈ Rwhere−1⩽a < b⩽1. Define R↑ a,b;u = [a, b]×[u,1], R ↓ a,b;u = [a, b]×[−1, u], u∈[−1,1]; R← a,b;u = [a, u]×[−1,1], R → a,b;u = [u, b]×[−1,1], u∈[a, b]. Also denote bym(p) =E[(M−1)1 {M⩾1} /M] whereM law ∼Bin(n, p). A standard computation (by first conditioning on the number of samples in the rectangle) yields that ...
work page 2008
-
[14]
It follows thata 0 = 2 and for eachk,a k+1 ⩾a k/2−C/ √n
of the rectangles at levelk. It follows thata 0 = 2 and for eachk,a k+1 ⩾a k/2−C/ √n. Solving this recursion yieldsa k ⩾2 1−k −2C/ √n for allk. In particular,a K ⩾2 1−K −2C/ √n⩾C/n 1/6. In summary, we have shown that ifn⩾C 064K, with high probability, the MinimaxSplit dimension is always along the first dimension for the firstKlevels of the tree. As a con...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.