Static task mapping for heterogeneous systems based on series-parallel decompositions
Pith reviewed 2026-05-23 03:01 UTC · model grok-4.3
The pith
Task mapping for heterogeneous processors improves by decomposing application graphs into series-parallel trees and scoring assignments with a performance model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a new general task mapping principle based on graph decompositions and model-based evaluation that can find beneficial mappings regardless of the complexity of the scenario. We apply this principle to create a high-quality and reasonably efficient task mapping algorithm using series-parallel decompositions.
What carries the argument
A forest of series-parallel decomposition trees computed for general DAGs, which supports recursive subproblem mapping and model-based scoring of task-to-unit assignments.
If this is right
- Mappings achieve substantially higher makespan improvements than HEFT variations in complex environments.
- The algorithm executes orders of magnitude faster than genetic-algorithm or integer-linear-program mappers.
- Streaming aspects of FPGAs are incorporated into the mapping decisions.
- The method scales to applications with large task counts and dense dependency graphs.
Where Pith is reading between the lines
- The same decomposition principle could be adapted for incremental or dynamic remapping when new tasks arrive.
- Combining the fast decomposition step with a more expensive exact solver on the reduced subproblems might further improve solution quality.
- The approach may generalize to other graph classes if equivalent decomposition forests can be computed efficiently.
Load-bearing premise
The model used to score candidate mappings after decomposition accurately predicts real execution times on the target hardware.
What would settle it
Running the generated mappings on physical heterogeneous hardware and measuring whether the reported makespan gains over HEFT actually appear.
Figures




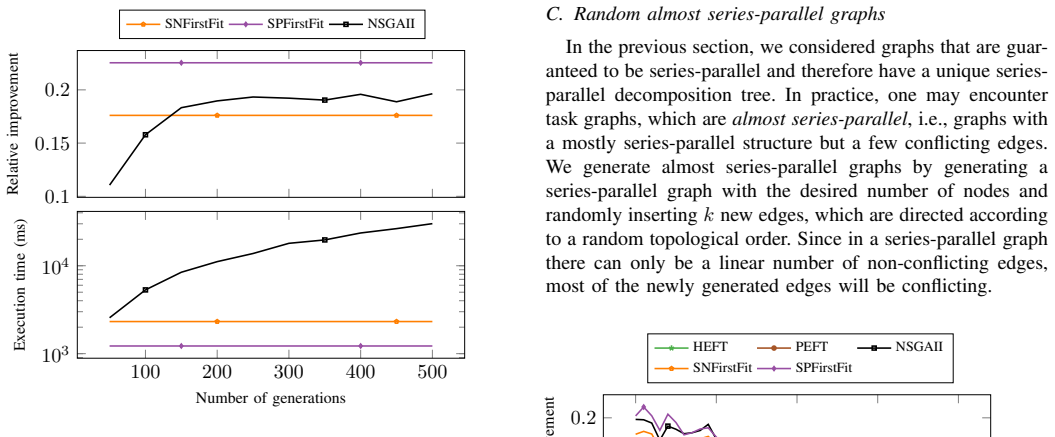

read the original abstract
Modern heterogeneous systems consist of many different processing units, such as CPUs, GPUs, FPGAs and AI units. A central problem in the design of applications in this environment is to find a beneficial mapping of tasks to processing units. While there are various approaches to task mapping, few can deal with high heterogeneity or applications with a high number of tasks and many dependencies. In addition, streaming aspects of FPGAs are generally not considered. We present a new general task mapping principle based on graph decompositions and model-based evaluation that can find beneficial mappings regardless of the complexity of the scenario. We apply this principle to create a high-quality and reasonably efficient task mapping algorithm using series-parallel decompositions. For this, we present a new algorithm to compute a forest of series-parallel decomposition trees for general DAGs. We compare our decomposition-based mapping algorithm with three mixed-integer linear programs, one genetic algorithm and two variations of the Heterogeneous Earliest Finish Time (HEFT) algorithm. We show that our approach can generate mappings that lead to substantially higher makespan improvements than the HEFT variations in complex environments while being orders of magnitude faster than a mapper based on genetic algorithms or integer linear programs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a task mapping principle for heterogeneous systems (CPUs, GPUs, FPGAs, AI units) that uses series-parallel decompositions of DAGs together with model-based makespan evaluation. It introduces an algorithm to compute a forest of series-parallel decomposition trees for general DAGs and presents a mapping algorithm based on this decomposition. The method is compared against three MILPs, one genetic algorithm, and two HEFT variants; the central claim is that it produces substantially higher makespan improvements than the HEFT variants in complex environments while running orders of magnitude faster than GA- or ILP-based mappers.
Significance. If the model-based scoring is shown to predict real execution times, the work would be significant for static scheduling in highly heterogeneous platforms that include streaming FPGA behavior, because it offers a scalable middle ground between fast but suboptimal heuristics and expensive exact or evolutionary methods.
major comments (2)
- [Abstract] Abstract and method description: the headline empirical claim (substantially higher makespan improvements vs. HEFT variants plus speed vs. GA/ILP) rests on model-based scoring of candidate mappings, yet the manuscript supplies no information on benchmark graphs, hardware models, number of runs, statistical tests, or validation of the performance model against measured execution times on target hardware that includes CPUs, GPUs, FPGAs and streaming effects.
- [Evaluation] Evaluation section: if the model omits contention, data-transfer variability, or FPGA pipeline behavior, the reported improvements are artifacts of the model rather than evidence for the mapping principle; no concrete validation data or cross-check against real hardware is described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in the experimental setup and model validation. We will revise the manuscript to address these points while preserving the core contribution of the series-parallel decomposition approach for task mapping.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the headline empirical claim (substantially higher makespan improvements vs. HEFT variants plus speed vs. GA/ILP) rests on model-based scoring of candidate mappings, yet the manuscript supplies no information on benchmark graphs, hardware models, number of runs, statistical tests, or validation of the performance model against measured execution times on target hardware that includes CPUs, GPUs, FPGAs and streaming effects.
Authors: We agree that the abstract and evaluation section would benefit from more explicit details on the experimental methodology. In the revised manuscript we will add a dedicated subsection describing the benchmark graph generation process, the parameterized hardware models for CPUs/GPUs/FPGAs (including data-transfer and streaming assumptions), the number of runs per configuration, and statistical tests used to compare makespans. We will also add a limitations paragraph noting that all results are model-based and that direct validation against measured execution times on physical heterogeneous platforms is outside the scope of the current simulation study. revision: yes
-
Referee: [Evaluation] Evaluation section: if the model omits contention, data-transfer variability, or FPGA pipeline behavior, the reported improvements are artifacts of the model rather than evidence for the mapping principle; no concrete validation data or cross-check against real hardware is described.
Authors: We acknowledge the concern. The performance model used for scoring mappings includes basic data-transfer costs but deliberately omits dynamic contention and detailed FPGA pipeline effects to remain tractable for static mapping; these assumptions are stated in the model section but will be made more prominent in the revised evaluation. The reported improvements are therefore relative to this model, which is standard practice when comparing mapping algorithms. We will revise the text to explicitly list omitted factors and their potential impact, and we will add a forward-looking statement on the desirability of future real-hardware cross-validation. revision: yes
- Providing concrete measured execution times or cross-checks against real heterogeneous hardware (including FPGAs with streaming behavior) for the reported mappings.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a task mapping algorithm using a new series-parallel decomposition forest algorithm for DAGs, followed by model-based scoring of candidate mappings. All reported performance claims (makespan improvements vs. HEFT variants, speed vs. GA/ILP) are obtained by direct comparison against independently implemented external algorithms. No equations, parameters, or uniqueness results are shown to reduce by construction to quantities fitted or defined inside the work itself; the model-based evaluator is an input to the mapping search rather than a self-referential output. No load-bearing self-citations appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task graphs are directed acyclic graphs (DAGs).
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a new general task mapping principle based on graph decompositions and model-based evaluation... series-parallel decomposition trees for general DAGs
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
model-based cost function to evaluate the overall cost of the execution... linear time with respect to the number of edges
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
series-parallel graphs... decomposition tree... modular programming
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Evaluating Rapid Makespan Predictions for Heterogeneous Systems with Programmable Logic
Introduces an evaluation framework using abstract task graphs to collect real makespan data on CPU-GPU-FPGA systems and assesses the accuracy of existing analytical prediction methods while noting challenges from data...
Reference graph
Works this paper leans on
-
[1]
A survey of CPU-GPU heterogeneous computing techniques,
S. Mittal and J. S. Vetter, “A survey of CPU-GPU heterogeneous computing techniques,” ACM Comput. Surv. , vol. 47, no. 4, pp. 69:1–69:35, 2015. [Online]. Available: https://doi.org/10.1145/2788396
-
[2]
Task mapping in heterogeneous embedded systems for fast completion time,
H. Zhou and C. Liu, “Task mapping in heterogeneous embedded systems for fast completion time,” in 2014 International Conference on Embedded Software, EMSOFT 2014, New Delhi, India, October 12-17, 2014, T. Mitra and J. Reineke, Eds. ACM, 2014, pp. 22:1–22:10. [Online]. Available: https://doi.org/10.1145/2656045.2656074
-
[3]
A multi-stage hybrid approach for mapping applications on heterogeneous multi-core platforms,
A. Emeretlis, G. Theodoridis, P. Alefragis, and N. S. V oros, “A multi-stage hybrid approach for mapping applications on heterogeneous multi-core platforms,” in 30th IFIP/IEEE 30th International Conference on Very Large Scale Integration, VLSI-SoC 2022, Patras, Greece, October 3-5, 2022 . IEEE, 2022, pp. 1–6. [Online]. Available: https://doi.org/10.1109/V...
-
[4]
S. Mohammadi, L. Pourkarimi, F. Droop, N. D. Mecquenem, U. Leser, and K. Reinert, “A mathematical programming approach for resource allocation of data analysis workflows on heterogeneous clusters,” J. Supercomput., vol. 79, no. 17, pp. 19 019–19 048, 2023. [Online]. Available: https://doi.org/10.1007/s11227-023-05325-w
-
[5]
M. Wilhelm, H. Geppert, A. Drewes, and T. Pionteck, “A comprehensive modeling approach for the task mapping problem in heterogeneous systems with dataflow processing units,” Concurr. Comput. Pract. Exp., vol. 35, no. 25, 2023. [Online]. Available: https://doi.org/10.1002/cpe. 7909
work page doi:10.1002/cpe 2023
-
[6]
Performance-effective and low-complexity task scheduling for heterogeneous computing,
H. Topcuoglu, S. Hariri, and M. Wu, “Performance-effective and low-complexity task scheduling for heterogeneous computing,” IEEE Trans. Parallel Distributed Syst. , vol. 13, no. 3, pp. 260–274, 2002. [Online]. Available: https://doi.org/10.1109/71.993206
-
[7]
DAG scheduling using a lookahead variant of the heterogeneous earliest finish time algorithm,
L. F. Bittencourt, R. Sakellariou, and E. R. M. Madeira, “DAG scheduling using a lookahead variant of the heterogeneous earliest finish time algorithm,” inProceedings of the 18th Euromicro Conference on Parallel, Distributed and Network-based Processing, PDP 2010, Pisa, Italy, February 17-19, 2010 , M. Danelutto, J. Bourgeois, and T. Gross, Eds. IEEE Comp...
-
[8]
List scheduling algorithm for heterogeneous systems by an optimistic cost table,
H. Arabnejad and J. G. Barbosa, “List scheduling algorithm for heterogeneous systems by an optimistic cost table,” IEEE Trans. Parallel Distributed Syst. , vol. 25, no. 3, pp. 682–694, 2014. [Online]. Available: https://doi.org/10.1109/TPDS.2013.57
-
[9]
D. Sirisha and S. S. Prasad, “MPEFT: a makespan minimizing heuristic scheduling algorithm for workflows in heterogeneous computing systems,”CCF Trans. High Perform. Comput., vol. 5, no. 4, pp. 374–389,
-
[10]
Available: https://doi.org/10.1007/s42514-022-00116-w
[Online]. Available: https://doi.org/10.1007/s42514-022-00116-w
-
[11]
On benchmarking task scheduling algorithms for heterogeneous computing systems,
A. K. Maurya and A. K. Tripathi, “On benchmarking task scheduling algorithms for heterogeneous computing systems,” J. Supercomput., vol. 74, no. 7, pp. 3039–3070, 2018. [Online]. Available: https://doi.org/10.1007/s11227-018-2355-0
-
[12]
Mapping on multi/many-core systems: survey of current and emerging trends,
A. K. Singh, M. Shafique, A. Kumar, and J. Henkel, “Mapping on multi/many-core systems: survey of current and emerging trends,” inThe 50th Annual Design Automation Conference 2013, DAC ’13, Austin, TX, USA, May 29 - June 07, 2013 . ACM, 2013, pp. 1:1–1:10
work page 2013
-
[13]
Mapping techniques in multicore processors: current and future trends,
M. Gupta, L. Bhargava, and S. Indu, “Mapping techniques in multicore processors: current and future trends,” J. Supercomput. , vol. 77, no. 8, pp. 9308–9363, 2021. [Online]. Available: https: //doi.org/10.1007/s11227-021-03650-6
-
[14]
T. D. Braun, H. J. Siegel, N. Beck, L. B ¨ol¨oni, M. Maheswaran, A. I. Reuther, J. P. Robertson, M. D. Theys, B. Yao, D. A. Hensgen, and R. F. Freund, “A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems,” J. Parallel Distributed Comput. , vol. 61, no. 6, pp. 810–837,
-
[15]
Available: https://doi.org/10.1006/jpdc.2000.1714
[Online]. Available: https://doi.org/10.1006/jpdc.2000.1714
-
[16]
A fast elitist non- dominated sorting genetic algorithm for multi-objective optimisation: NSGA-II,
K. Deb, S. Agrawal, A. Pratap, and T. Meyarivan, “A fast elitist non- dominated sorting genetic algorithm for multi-objective optimisation: NSGA-II,” in Parallel Problem Solving from Nature - PPSN VI, 6th International Conference, Paris, France, September 18-20, 2000, Proceedings, ser. Lecture Notes in Computer Science, M. Schoenauer, K. Deb, G. Rudolph, ...
-
[17]
SPEA2: Improving the strength pareto evolutionary algorithm,
E. Zitzler, M. Laumanns, and L. Thiele, “SPEA2: Improving the strength pareto evolutionary algorithm,” TIK-Report, vol. 103, 07 2001. [Online]. Available: https://doi.org/10.3929/ethz-a-004284029
-
[18]
Methods for evaluating and covering the design space during early design development,
M. Gries, “Methods for evaluating and covering the design space during early design development,” Integr., vol. 38, no. 2, pp. 131–183,
-
[19]
Available: https://doi.org/10.1016/j.vlsi.2004.06.001
[Online]. Available: https://doi.org/10.1016/j.vlsi.2004.06.001
-
[20]
A survey of communication performance models for high- performance computing,
J. A. Rico-Gallego, J. C. D. Mart ´ın, R. R. Manumachu, and A. L. Lastovetsky, “A survey of communication performance models for high- performance computing,” ACM Comput. Surv., vol. 51, no. 6, pp. 126:1– 126:36, 2019. [Online]. Available: https://doi.org/10.1145/3284358
-
[21]
Why comparing system-level mpsoc mapping approaches is difficult: A case study,
A. Goens, R. Khasanov, J. Castrill ´on, S. Polstra, and A. D. Pimentel, “Why comparing system-level mpsoc mapping approaches is difficult: A case study,” in 10th IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip, MCSOC 2016, Lyon, France, September 21-23, 2016 . IEEE Computer Society, 2016, pp. 281–288. [Online]. Available: http...
-
[22]
Modeling task mapping for data-intensive applications in heterogeneous systems,
M. Wilhelm, H. Geppert, A. Drewes, and T. Pionteck, “Modeling task mapping for data-intensive applications in heterogeneous systems,” in Euro-Par 2022: Parallel Processing Workshops, Glasgow, UK, August 22-26, 2022 , ser. Lecture Notes in Computer Science, vol. 13835. Springer, 2022, pp. 145–157. [Online]. Available: https://doi.org/10.1007/978-3-031-31209-0 11
-
[23]
Topology of series-parallel networks,
R. J. Duffin, “Topology of series-parallel networks,” Journal of Mathe- matical Analysis and Applications , vol. 10, no. 2, pp. 303–318, 1965
work page 1965
-
[24]
Parallel recognition of series-parallel graphs,
D. Eppstein, “Parallel recognition of series-parallel graphs,” Inf. Comput., vol. 98, no. 1, pp. 41–55, 1992. [Online]. Available: https://doi.org/10.1016/0890-5401(92)90041-D
-
[25]
Y . Cai and R. Kazman, “Software design analysis and technical debt management based on design rule theory,” Inf. Softw. Technol. , vol. 164, p. 107322, 2023. [Online]. Available: https://doi.org/10.1016/j. infsof.2023.107322
work page doi:10.1016/j 2023
-
[26]
Maximum series-parallel subgraph,
G. C ˘alinescu, C. G. Fernandes, H. Kaul, and A. Zelikovsky, “Maximum series-parallel subgraph,” Algorithmica, vol. 63, no. 1-2, pp. 137–157,
-
[27]
Available: https://doi.org/10.1007/s00453-011-9523-4
[Online]. Available: https://doi.org/10.1007/s00453-011-9523-4
-
[28]
Gurobi Optimizer Reference Manual,
Gurobi Optimization, LLC, “Gurobi Optimizer Reference Manual,”
- [29]
-
[30]
Maximum number of generations as a stopping criterion considered harmful,
M. Ravber, S. Liu, M. Mernik, and M. Crepinsek, “Maximum number of generations as a stopping criterion considered harmful,” Appl. Soft Comput. , vol. 128, p. 109478, 2022. [Online]. Available: https://doi.org/10.1016/j.asoc.2022.109478
-
[31]
Wfcommons: A framework for enabling scientific workflow research and development,
T. Coleman, H. Casanova, L. Pottier, M. Kaushik, E. Deelman, and R. F. da Silva, “Wfcommons: A framework for enabling scientific workflow research and development,” Future Gener. Comput. Syst. , vol. 128, pp. 16–27, 2022. [Online]. Available: https://doi.org/10.1016/ j.future.2021.09.043
work page 2022
-
[32]
Montage: a grid-enabled engine for delivering custom science-grade mosaics on demand,
G. B. Berriman, E. Deelman, J. C. Good, J. C. Jacob, D. S. Katz, C. Kesselman, A. C. Laity, T. A. Prince, G. Singh, and M.-H. Su, “Montage: a grid-enabled engine for delivering custom science-grade mosaics on demand,” in Optimizing scientific return for astronomy through information technologies , vol. 5493, International Society for Optics and Photonics....
-
[33]
Characterizing and profiling scientific workflows,
G. Juve, A. L. Chervenak, E. Deelman, S. Bharathi, G. Mehta, and K. Vahi, “Characterizing and profiling scientific workflows,” Future Gener. Comput. Syst. , vol. 29, no. 3, pp. 682–692, 2013. [Online]. Available: https://doi.org/10.1016/j.future.2012.08.015
-
[34]
Benchmarking dag scheduling algorithms on scientific workflow instances,
O. Sukhoroslov and M. Gorokhovskii, “Benchmarking dag scheduling algorithms on scientific workflow instances,” inRussian Supercomputing Days. Springer, 2023, pp. 3–20. [Online]. Available: https://doi.org/ 10.1007/978-3-031-49435-2 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.