Multiscale Analysis of Woven Composites Using Hierarchical Physically Recurrent Neural Networks
Pith reviewed 2026-05-23 00:54 UTC · model grok-4.3
The pith
Hierarchical physically recurrent neural networks avoid nonphysical predictions in multiscale woven composite modeling by embedding physics at both yarn and meso-to-macro scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adopting HPRNNs for both scale transitions can avoid nonphysical behavior often observed in predictions from pure data-driven recurrent neural networks and transformer networks. This results in better generalization under complex cyclic loading conditions.
What carries the argument
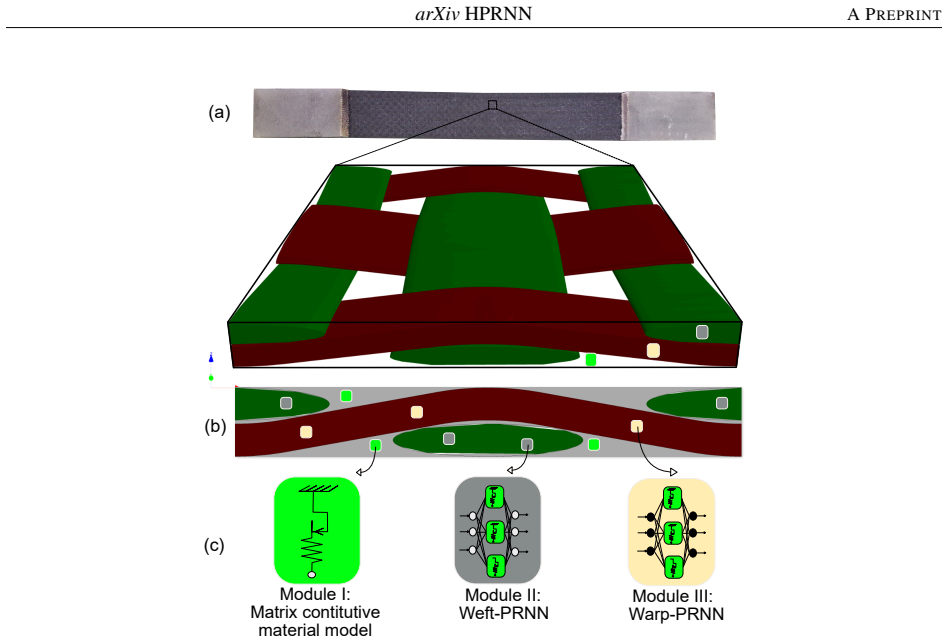
The Hierarchical Physically Recurrent Neural Network (HPRNN), in which PRNN surrogates capture yarn nonlinearity at the microscale and a second physics-encoded network integrates those surrogates with the matrix model at the meso-to-macro scale by embedding physical properties into the latent space.
If this is right
- Multiscale simulations of woven composites become computationally cheaper while retaining physical consistency at both scales.
- Predictions remain stable and physically admissible under repeated cyclic loading paths that expose weaknesses in purely data-driven surrogates.
- The framework supplies an explainable surrogate that can be inspected at the level of embedded physical quantities rather than opaque weights.
- The same hierarchical structure can be reused for different woven architectures once the yarn-level PRNNs are retrained.
Where Pith is reading between the lines
- The same two-level construction might be tested on other textile or braided composites whose yarns exhibit similar elasto-plastic nonlinearity.
- If the latent-space embedding proves robust, the method could reduce the volume of micromechanical data needed for new matrix-yarn combinations.
- Engineering workflows that require many load cycles, such as fatigue assessment, would become feasible at the structural scale without full-field micromechanics at every step.
Load-bearing premise
Embedding physical properties directly into the latent space of the meso-to-macro model will correctly integrate the trained yarn surrogates with the matrix constitutive model without introducing new inconsistencies or requiring extensive additional calibration.
What would settle it
A direct comparison showing that the HPRNN still produces nonphysical stress or strain values or fails to generalize under the same complex cyclic loading paths where pure data-driven networks already fail would falsify the central claim.
Figures
















read the original abstract
Multiscale homogenization of woven composites requires detailed micromechanical evaluations, leading to high computational costs. Data-driven surrogate models based on neural networks address this challenge but often suffer from big data requirements, limited interpretability, and poor extrapolation capabilities. This study introduces a Hierarchical Physically Recurrent Neural Network (HPRNN) employing two levels of surrogate modeling. First, Physically Recurrent Neural Networks (PRNNs) are trained to capture the nonlinear elasto-plastic behavior of warp and weft yarns using micromechanical data. In a second scale transition, a physics-encoded meso-to-macroscale model integrates these yarn surrogates with the matrix constitutive model, embedding physical properties directly into the latent space. Adopting HPRNNs for both scale transitions can avoid nonphysical behavior often observed in predictions from pure data-driven recurrent neural networks and transformer networks. This results in better generalization under complex cyclic loading conditions. The framework offers a computationally efficient and explainable solution for multiscale modeling of woven composites.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Hierarchical Physically Recurrent Neural Network (HPRNN) framework for multiscale homogenization of woven composites. It employs Physically Recurrent Neural Networks (PRNNs) trained on micromechanical data to surrogate the nonlinear elasto-plastic response of warp and weft yarns, followed by a second-scale physics-encoded meso-to-macro model that integrates the yarn surrogates with the matrix constitutive law by embedding physical properties directly into the latent space. The central claim is that this hierarchical physics-informed approach avoids nonphysical behavior typical of pure data-driven RNNs and transformers, yielding improved generalization under complex cyclic loading while remaining computationally efficient and explainable.
Significance. If the quantitative validation and consistency proofs hold, the work would supply a scalable surrogate that reduces the cost of detailed micromechanical evaluations in composite analysis while preserving physical consistency across scales. The explicit embedding of physical properties into the latent space, if shown to enforce thermodynamic admissibility or interface equilibrium without extra calibration, would be a concrete strength over purely data-driven alternatives.
major comments (2)
- [Abstract] Abstract (paragraph on second scale transition): the claim that embedding physical properties directly into the latent space 'correctly integrates the trained yarn surrogates with the matrix constitutive model without introducing new inconsistencies' is load-bearing for the central claim, yet the description supplies neither the explicit loss terms, invariance constraints, nor thermodynamic admissibility conditions used in the embedding; without these it is impossible to determine whether the coupling reduces to quantities already fitted in the two-stage training.
- [Abstract] Abstract: the assertion of 'better generalization under complex cyclic loading conditions' and avoidance of nonphysical behavior is presented without any reported error metrics, error bars, baseline comparisons (e.g., against standard RNNs or FE^{2}), or specific validation cases on cyclic histories, which prevents assessment of whether the data support the central claim.
minor comments (1)
- The abstract refers to an 'explainable solution' but does not indicate which architectural features (e.g., latent-space interpretability or physics constraints) are intended to deliver this property.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on second scale transition): the claim that embedding physical properties directly into the latent space 'correctly integrates the trained yarn surrogates with the matrix constitutive model without introducing new inconsistencies' is load-bearing for the central claim, yet the description supplies neither the explicit loss terms, invariance constraints, nor thermodynamic admissibility conditions used in the embedding; without these it is impossible to determine whether the coupling reduces to quantities already fitted in the two-stage training.
Authors: We agree that the abstract is too concise on this point. The explicit loss terms, invariance constraints, and thermodynamic admissibility conditions are detailed in Section 3.2 of the manuscript (physics-encoded meso-to-macro model), where physical properties are embedded via additional penalty terms in the training objective that enforce interface equilibrium and constitutive consistency beyond the two-stage fitting. To address the concern, we will revise the abstract to briefly reference these elements and the relevant section. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'better generalization under complex cyclic loading conditions' and avoidance of nonphysical behavior is presented without any reported error metrics, error bars, baseline comparisons (e.g., against standard RNNs or FE^{2}), or specific validation cases on cyclic histories, which prevents assessment of whether the data support the central claim.
Authors: The quantitative results supporting these claims, including error metrics with error bars, baseline comparisons against standard RNNs and FE^{2}, and specific cyclic loading validation cases, are reported in Sections 5 and 6 with accompanying figures. The abstract provides a high-level summary of these findings. We will revise the abstract to include key quantitative indicators (e.g., relative errors under cyclic histories) to better substantiate the claim. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract describes a two-stage process: PRNNs are trained directly on micromechanical data to surrogate yarn behavior, followed by a separate physics-encoded meso-to-macro model that integrates the surrogates with the matrix law via latent-space embedding. No equations, loss terms, or self-citations are supplied that would reduce the claimed generalization or avoidance of nonphysical behavior to a fitted quantity by construction. The physics embedding is presented as an independent modeling choice rather than a tautology or renamed input. This leaves the central claim self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Micromechanical simulations provide sufficient and representative data for training PRNNs on warp and weft yarn elasto-plastic behavior.
- ad hoc to paper Embedding physical properties into the latent space of the meso-to-macro model preserves physical consistency across scale transitions.
invented entities (1)
-
Hierarchical Physically Recurrent Neural Network (HPRNN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A review on data-driven constitutive laws for solids
Jan Niklas Fuhg, Govinda Anantha Padmanabha, Nikolaos Bouklas, Bahador Bahmani, WaiChing Sun, Nikolaos N Vlassis, Moritz Flaschel, Pietro Carrara, and Laura De Lorenzis. A review on data-driven constitutive laws for solids. arXiv preprint arXiv:2405.03658,
-
[2]
Improving bayesian networks multifidelity surrogate construction with basis adaptation
Xiaoshu Zeng, Gianluca Geraci, Alex Gorodetsky, John Jakeman, Michael S Eldred, and Roger G Ghanem. Improving bayesian networks multifidelity surrogate construction with basis adaptation. In AIAA Scitech 2023 F orum, page 0917,
work page 2023
-
[3]
Physics-informed neural networks and extensions
Maziar Raissi, Paris Perdikaris, Nazanin Ahmadi, and George Em Karniadakis. Physics-informed neural networks and extensions. arXiv preprint arXiv:2408.16806,
-
[4]
Shahed Rezaei, Ahmad Moeineddin, and Ali Harandi. Learning solution of nonlinear constitutive material models using physics-informed neural networks: Comm-pinn. arXiv preprint arXiv:2304.06044,
-
[5]
Hard encoding of physics for learning spatiotemporal dynamics
Chengping Rao, Hao Sun, and Yang Liu. Hard encoding of physics for learning spatiotemporal dynamics. arXiv preprint arXiv:2105.00557,
-
[6]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Epi-ckans: Elasto-plasticity informed kolmogorov-arnold networks using chebyshev polynomials
Farinaz Mostajeran and Salah A Faroughi. Epi-ckans: Elasto-plasticity informed kolmogorov-arnold networks using chebyshev polynomials. arXiv preprint arXiv:2410.10897,
-
[8]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks. arXiv preprint arXiv:2404.19756, 2024b. Salah A Faroughi, Nikhil M Pawar, Celio Fernandes, Maziar Raissi, Subasish Das, Nima K Kalantari, and Seyed Kourosh Mahjour. Physics-guided, physics-informed, and ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
doi:https://doi.org/10.1016/j.cma.2016.10.022
ISSN 0045-7825. doi:https://doi.org/10.1016/j.cma.2016.10.022. MM Shokrieh, R Ghasemi, and R Mosalmani. A general micromechanical model to predict elastic and strength properties of balanced plain weave fabric composites. Journal of Composite Materials, 51(20):2863–2878,
-
[10]
Wei Lu, Rachel K Luu, and Markus J Buehler. Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities. arXiv preprint arXiv:2409.03444,
-
[11]
https://www.e-xstream.com/products/digimat/tools?fe=1
Digimat-FE. https://www.e-xstream.com/products/digimat/tools?fe=1. accessed: 24.10.2016. Jeff Bezanson, Alan Edelman, Stefan Karpinski, and Viral B Shah. Julia: A fresh approach to numerical computing. SIAM review, 59(1):65–98,
work page 2016
-
[12]
URL https://doi.org/10.1137/141000671. Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.