Radar-Guided Polynomial Fitting for Metric Depth Estimation
Pith reviewed 2026-05-22 22:32 UTC · model grok-4.3
The pith
Radar data predicts polynomial coefficients to convert scaleless monocular depth into metric depth by correcting misalignments between local regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
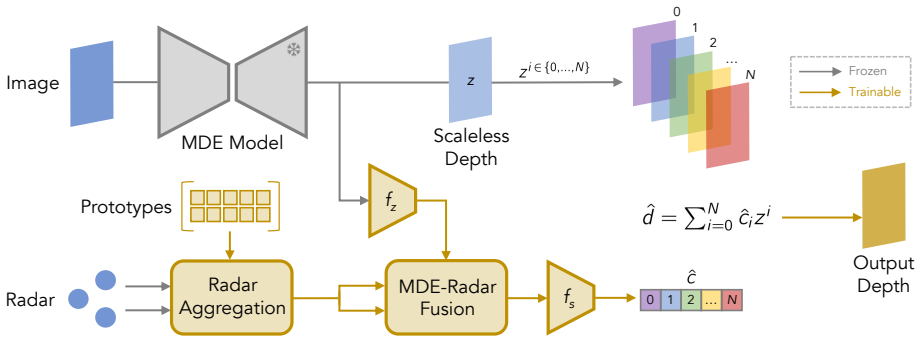
POLAR uses radar to predict polynomial coefficients that transform scaleless depth predictions from pretrained MDE models into metric depth maps, generalizing beyond affine transformations by allowing inflection points, while a novel training objective enforces local monotonicity via first-derivative regularization.
What carries the argument
Radar-guided polynomial fitting that predicts coefficients to adaptively adjust depth predictions non-uniformly across ranges while preserving structural consistency.
If this is right
- Metric depth can be obtained from any pretrained monocular model without retraining the model itself.
- The method runs with lower latency and computational cost than competing radar or fusion approaches.
- Performance gains of roughly 25 percent MAE and 33 percent RMSE appear on three standard datasets.
- The framework extends naturally to any sensor that supplies sparse but reliable depth cues for coefficient prediction.
Where Pith is reading between the lines
- The same polynomial-correction idea could be tested with lidar or stereo cues in place of radar to see whether the benefit is specific to radar sparsity patterns.
- If the number of inflection points is learned rather than fixed, the method might adapt automatically to scene complexity.
- Failure cases may appear in highly dynamic scenes where radar returns lag the image frame, suggesting a need for temporal consistency terms.
Load-bearing premise
Radar returns contain enough information to predict polynomial coefficients that realign multiple mis-scaled local depth regions without creating new inconsistencies.
What would settle it
A controlled test on scenes with four or more distinct objects where the polynomial-adjusted depth map violates local monotonicity or increases error relative to ground-truth metric depths despite the regularizer.
Figures






read the original abstract
We propose POLAR, a novel radar-guided depth estimation method that introduces polynomial fitting to efficiently transform scaleless depth predictions from pretrained monocular depth estimation (MDE) models into metric depth maps. Unlike existing approaches that rely on complex architectures or expensive sensors, our method is grounded in a fundamental insight: although MDE models often infer reasonable local depth structure within each object or local region, they may misalign these regions relative to one another, making a linear scale and shift (affine) transformation insufficient given three or more of these regions. To address this limitation, we use polynomial coefficients predicted from cheap, ubiquitous radar data to adaptively adjust predictions non-uniformly across depth ranges. In this way, POLAR generalizes beyond affine transformations and is able to correct such misalignments by introducing inflection points. Importantly, our polynomial fitting framework preserves structural consistency through a novel training objective that enforces local monotonicity via first-derivative regularization. POLAR achieves state-of-the-art performance across three datasets, outperforming existing methods by an average of 24.9% in MAE and 33.2% in RMSE, while also achieving state-of-the-art efficiency in terms of latency and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes POLAR, a radar-guided polynomial fitting method to convert scaleless depth predictions from pretrained monocular depth estimation models into metric depth maps. The key insight is that MDE models produce reasonable local structures but misalign multiple regions, requiring more than affine transformations; radar data is used to predict polynomial coefficients for non-uniform adjustments and inflection points, with a first-derivative regularization to enforce local monotonicity. The paper reports state-of-the-art results on three datasets with average gains of 24.9% in MAE and 33.2% in RMSE, plus efficiency advantages.
Significance. If the result holds, the significance is that the work offers an efficient radar-based approach to metric depth estimation that generalizes beyond affine transformations via polynomials, which could impact real-time applications in computer vision and robotics by reducing reliance on expensive sensors or complex models. The derivative regularizer for preserving local monotonicity is a constructive element if shown to be effective.
major comments (2)
- [Abstract] Abstract: The abstract states performance numbers and a training objective but supplies no derivation details, dataset statistics, ablation results, or error analysis; therefore the math and data cannot be verified to support the claim as stated. This is load-bearing for the SOTA performance claim.
- [Abstract] Abstract: The assumption that radar returns are sufficient to predict polynomial coefficients that correctly realign multiple mis-scaled local depth regions without introducing new inconsistencies or violating the local monotonicity enforced by the derivative regularizer is presented as the core mechanism but provides no quantitative check on residual violations or generalization beyond the training radar distribution. This is load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, noting that the abstract serves as a high-level summary while detailed supporting material appears in the body of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance numbers and a training objective but supplies no derivation details, dataset statistics, ablation results, or error analysis; therefore the math and data cannot be verified to support the claim as stated. This is load-bearing for the SOTA performance claim.
Authors: Abstracts conventionally provide concise overviews of contributions and results rather than full derivations or statistics. The polynomial fitting formulation, first-derivative regularization objective, and associated math are derived in Section 3. Dataset statistics (including radar point densities and scene distributions) appear in Section 4.1. Ablation studies isolating the regularization term and polynomial degree are in Section 5.2, while error analysis and per-region breakdown are in Section 5.3. These sections contain the equations, tables, and figures needed to verify the reported 24.9% MAE and 33.2% RMSE gains. No changes to the abstract itself are required to maintain its brevity and standard format. revision: no
-
Referee: [Abstract] Abstract: The assumption that radar returns are sufficient to predict polynomial coefficients that correctly realign multiple mis-scaled local depth regions without introducing new inconsistencies or violating the local monotonicity enforced by the derivative regularizer is presented as the core mechanism but provides no quantitative check on residual violations or generalization beyond the training radar distribution. This is load-bearing for the central claim.
Authors: The manuscript validates the core mechanism through multiple quantitative checks. Section 5.1 reports end-to-end metric depth accuracy gains over affine baselines across three datasets, with qualitative examples showing correction of multi-region misalignments via polynomial inflection points. Table 3 ablates the first-derivative regularizer and shows measurable reduction in local depth inversions. Cross-dataset evaluation (Section 5.4) tests generalization under varying radar characteristics. While an explicit auxiliary metric for residual monotonicity violations on held-out radar distributions is not tabulated, the consistent SOTA performance and ablation results provide indirect but substantive support; we can add a targeted residual-violation table in revision if the referee deems it necessary. revision: partial
Circularity Check
No significant circularity; derivation uses external radar inputs for empirical gains
full rationale
The paper's core mechanism predicts polynomial coefficients from radar measurements to non-uniformly rescale monocular depth outputs, with performance evaluated empirically on three datasets. No equations, self-citations, or fitted parameters are shown in the provided text that reduce the claimed MAE/RMSE improvements or the polynomial transformation itself to quantities defined by the inputs or by construction. The regularizer and radar-to-coefficient mapping are presented as independent components relying on external sensor data rather than tautological redefinitions or renamings of known results.
Axiom & Free-Parameter Ledger
free parameters (2)
- polynomial degree
- derivative regularization weight
axioms (2)
- domain assumption MDE models infer reasonable local depth structure but misalign regions relative to one another when three or more regions are present
- domain assumption Radar data can be used to predict polynomial coefficients that adaptively correct depth misalignments
Reference graph
Works this paper leans on
-
[1]
Richard E. Barlow, David J. Bartholomew, J. Martin Bremner, and H. D. Brunk.Statistical Inference Under Order Restric- tions: The Theory and Application of Isotonic Regression. John Wiley & Sons, New York, 1972. 7
work page 1972
-
[2]
Adabins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4009–4018, 2021. 14
work page 2021
-
[3]
Jiawang Bian, Zhichao Li, Naiyan Wang, Huangying Zhan, Chunhua Shen, Ming-Ming Cheng, and Ian Reid. Unsuper- vised scale-consistent depth and ego-motion learning from monocular video.Advances in neural information processing systems, 32, 2019. 2
work page 2019
-
[4]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, New York, 2006. 7
work page 2006
-
[5]
Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Mar- cel Santos, Yichao Zhou, Stephan R. Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second, 2024. 1, 2, 12, 15
work page 2024
-
[6]
nuScenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving.arXiv preprint arXiv:1903.11027, 2019. 13
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[7]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 2
work page 2021
-
[8]
Xien Chen, Rit Gangopadhyay, Michael Chu, Patrick Rim, Hyoungseob Park, and Alex Wong. Uncle: Benchmarking unsupervised continual learning for depth completion.arXiv preprint arXiv:2410.18074, 2024. 2
-
[9]
Vision transformer adapter for dense predictions,
Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions.arXiv preprint arXiv:2205.08534, 2022. 16
-
[10]
Yaqing Ding, Václav Vávra, Viktor Kocur, Jian Yang, Torsten Sattler, and Zuzana Kukelova. Fixing the scale and shift in monocular depth for camera pose estimation.arXiv preprint arXiv:2501.07742, 2025. 1, 3
-
[11]
An image is worth 16x16 words: Transform- ers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale. InInternational Conference on Learning Representations, 2021. 2
work page 2021
-
[12]
Angela H Eichelberger and Anne T McCartt. Toyota drivers’ experiences with dynamic radar cruise control, pre-collision system, and lane-keeping assist.Journal of safety research, 56:67–73, 2016. 1, 2
work page 2016
-
[13]
Vadim Ezhov, Hyoungseob Park, Zhaoyang Zhang, Rishi Upadhyay, Howard Zhang, Chethan Chinder Chandrappa, Achuta Kadambi, Yunhao Ba, Julie Dorsey, and Alex Wong. All-day depth completion. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE,
-
[14]
Abhishek Gupta, Alagan Anpalagan, Ling Guan, and Ahmed Shaharyar Khwaja. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues.Array, 10:100057, 2021. 1
work page 2021
-
[15]
4d millimeter- wave radar in autonomous driving: A survey.arXiv preprint arXiv:2306.04242, 2023
Zeyu Han, Jiahao Wang, Zikun Xu, Shuocheng Yang, Lei He, Shaobing Xu, Jianqiang Wang, and Keqiang Li. 4d millimeter- wave radar in autonomous driving: A survey.arXiv preprint arXiv:2306.04242, 2023. 1
-
[16]
Lukas Hoyer, Dengxin Dai, Qin Wang, Yuhua Chen, and Luc Van Gool. Improving semi-supervised and domain-adaptive semantic segmentation with self-supervised depth estimation. International Journal of Computer Vision, pages 1–27, 2023. 2
work page 2023
-
[17]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
-
[18]
Mu Hu, Shuling Wang, Bin Li, Shiyu Ning, Li Fan, and Xiao- jin Gong. Penet: Towards precise and efficient image guided depth completion.2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13656–13662, 2021. 2
work page 2021
-
[19]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos.arXiv preprint arXiv:2409.02095, 2024. 1, 3
-
[20]
David Hunt, Shaocheng Luo, Amir Khazraei, Xiao Zhang, Spencer Hallyburton, Tingjun Chen, and Miroslav Pajic. Rad- cloud: Real-time high-resolution point cloud generation us- ing low-cost radars for aerial and ground vehicles. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 12269–12275. IEEE, 2024. 2
work page 2024
-
[21]
Hideo Iizuka, Toshiaki Watanabe, Kazuo Sato, and Kunitoshi Nishikawa. Millimeter-wave microstrip array antenna for automotive radars.IEICE transactions on communications, 86(9):2728–2738, 2003. 1
work page 2003
-
[22]
Sparse and dense data with cnns: Depth completion and semantic segmentation
Maximilian Jaritz, Raoul De Charette, Etienne Wirbel, Xavier Perrotton, and Fawzi Nashashibi. Sparse and dense data with cnns: Depth completion and semantic segmentation. In2018 International Conference on 3D Vision (3DV), pages 52–60. IEEE, 2018. 2
work page 2018
-
[23]
Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi-scale local planar guidance for monocular depth estimation.arXiv preprint arXiv:1907.10326, 2019. 14
-
[24]
A multi-scale guided cascade hourglass network for depth completion
Ang Li, Zejian Yuan, Yonggen Ling, Wanchao Chi, Sheng- hao Zhang, and Chong Zhang. A multi-scale guided cascade hourglass network for depth completion. In2020 IEEE Win- ter Conference on Applications of Computer Vision (WACV), pages 32–40, 2020. 2
work page 2020
-
[25]
Sparse beats dense: Rethinking supervision in radar-camera depth completion
Huadong Li, Minhao Jing, Wang Jin, Shichao Dong, Jiajun Liang, Haoqiang Fan, and Renhe Ji. Sparse beats dense: Rethinking supervision in radar-camera depth completion. In European Conference on Computer Vision, pages 127–143. Springer, 2024. 3, 7, 8, 14
work page 2024
-
[26]
Radarcam-depth: Radar-camera fusion for 9 depth estimation with learned metric scale
Han Li, Yukai Ma, Yaqing Gu, Kewei Hu, Yong Liu, and Xingxing Zuo. Radarcam-depth: Radar-camera fusion for 9 depth estimation with learned metric scale. In2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 10665–10672. IEEE, 2024. 2, 3, 4, 5, 7, 8, 13, 14
work page 2024
-
[27]
Depth estimation from monocular images and sparse radar data
Juan-Ting Lin, Dengxin Dai, and Luc Van Gool. Depth estimation from monocular images and sparse radar data. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10233–10240. IEEE, 2020. 3, 8, 14
work page 2020
-
[28]
Lin, Tao Cheng, Qianglong Zhong, Wending Zhou, and Huanhuan Yang
Yuan Qin. Lin, Tao Cheng, Qianglong Zhong, Wending Zhou, and Huanhuan Yang. Dynamic spatial propagation network for depth completion. InAAAI Conference on Artificial Intel- ligence, 2022. 2
work page 2022
-
[29]
Depth estimation from monocular images and sparse radar using deep ordinal regression network
Chen-Chou Lo and Patrick Vandewalle. Depth estimation from monocular images and sparse radar using deep ordinal regression network. In2021 IEEE International Conference on Image Processing (ICIP), pages 3343–3347. IEEE, 2021. 3, 14
work page 2021
-
[30]
Full-velocity radar returns by radar-camera fusion
Yunfei Long, Daniel Morris, Xiaoming Liu, Marcos Castro, Punarjay Chakravarty, and Praveen Narayanan. Full-velocity radar returns by radar-camera fusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16198–16207, 2021. 3, 14
work page 2021
-
[31]
Sparse-to-dense: Depth prediction from sparse depth samples and a single image
Fangchang Ma and Sertac Karaman. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In 2018 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 4796–4803, 2018. 2
work page 2018
-
[32]
Fangchang Ma, Guilherme Venturelli Cavalheiro, and Sertac Karaman. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera.2019 In- ternational Conference on Robotics and Automation (ICRA), pages 3288–3295, 2018. 2
work page 2019
-
[33]
Real- time navigation in 3d environments based on depth camera data
Daniel Maier, Armin Hornung, and Maren Bennewitz. Real- time navigation in 3d environments based on depth camera data. In2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), pages 692–697. IEEE,
work page 2012
-
[34]
Dong-Hee Paek, Seung-Hyun Kong, and Kevin Tirta Wijaya. K-radar: 4d radar object detection for autonomous driving in various weather conditions.Advances in Neural Information Processing Systems, 35:3819–3829, 2022. 2
work page 2022
-
[35]
Andras Palffy, Ewoud Pool, Srimannarayana Baratam, Julian F. P. Kooij, and Dariu M. Gavrila. Multi-class road user detection with 3+1d radar in the view-of-delft dataset.IEEE Robotics and Automation Letters, 7(2):4961–4968, 2022. 14
work page 2022
-
[36]
Non-local spatial propagation network for depth completion
Jinsun Park, Kyungdon Joo, Zhe Hu, Chi Liu, and In So Kweon. Non-local spatial propagation network for depth completion. InEuropean Conference on Computer Vision,
-
[37]
P3depth: Monocular depth estimation with a piecewise planarity prior
Vaishakh Patil, Christos Sakaridis, Alexander Liniger, and Luc Van Gool. P3depth: Monocular depth estimation with a piecewise planarity prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1610–1621, 2022. 14
work page 2022
-
[38]
UniDepthV2: Universal monocular metric depth estimation made simpler, 2025
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. UniDepthV2: Universal monocular metric depth estimation made simpler, 2025. 1, 2, 12, 15
work page 2025
-
[39]
On the uncertainty of self-supervised monocular depth estimation
Matteo Poggi, Filippo Aleotti, Fabio Tosi, and Stefano Mat- toccia. On the uncertainty of self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3227–3237,
-
[40]
A survey on lidar scanning mechanisms.Electronics, 9(5):741, 2020
Thinal Raj, Fazida Hanim Hashim, Aqilah Baseri Huddin, Mohd Faisal Ibrahim, and Aini Hussain. A survey on lidar scanning mechanisms.Electronics, 9(5):741, 2020. 1, 2
work page 2020
-
[41]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020. 2
work page 2020
-
[42]
Vi- sion transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 1, 12, 15
work page 2021
-
[43]
Guide- former: Transformers for image guided depth completion
Kyeongha Rho, Jinsung Ha, and Youngjung Kim. Guide- former: Transformers for image guided depth completion. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6240–6249, 2022. 2
work page 2022
-
[44]
Patrick Rim, Hyoungseob Park, S Gangopadhyay, Ziyao Zeng, Younjoon Chung, and Alex Wong. Protodepth: Unsupervised continual depth completion with prototypes.arXiv preprint arXiv:2503.12745, 2025. 2
-
[45]
Depth estimation from camera image and mmwave radar point cloud
Akash Deep Singh, Yunhao Ba, Ankur Sarker, Howard Zhang, Achuta Kadambi, Stefano Soatto, Mani Srivastava, and Alex Wong. Depth estimation from camera image and mmwave radar point cloud. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9275–9285, 2023. 2, 3, 4, 5, 7, 8, 14
work page 2023
-
[46]
Minsoo Song, Seokjae Lim, and Wonjun Kim. Monocular depth estimation using laplacian pyramid-based depth resid- uals.IEEE transactions on circuits and systems for video technology, 31(11):4381–4393, 2021. 14
work page 2021
-
[47]
Xiaogang Song, Haoyue Hu, Li Liang, Weiwei Shi, Guo Xie, Xiaofeng Lu, and Xinhong Hei. Unsupervised monocular estimation of depth and visual odometry uusing attention and depth-pose consistency loss.IEEE Transactions on Multime- dia, 2023. 2
work page 2023
-
[48]
Arvind Srivastav and Soumyajit Mandal. Radars for au- tonomous driving: A review of deep learning methods and challenges.IEEE Access, 11:97147–97168, 2023. 2
work page 2023
-
[49]
Cafnet: A confidence-driven framework for radar camera depth estimation
Huawei Sun, Hao Feng, Julius Ott, Lorenzo Servadei, and Robert Wille. Cafnet: A confidence-driven framework for radar camera depth estimation. In2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 2734–2740. IEEE, 2024. 3, 14
work page 2024
-
[50]
Get-up: Geometric-aware depth estimation with radar points upsampling
Huawei Sun, Zixu Wang, Hao Feng, Julius Ott, Lorenzo Servadei, and Robert Wille. Get-up: Geometric-aware depth estimation with radar points upsampling. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), pages 1850–1860, 2025. 3, 7, 8, 14
work page 2025
-
[51]
Bilateral propagation network for depth completion
Jie Tang, Fei-Peng Tian, Boshi An, Jian Li, and Ping Tan. Bilateral propagation network for depth completion. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9763–9772, 2024. 14 10
work page 2024
-
[52]
Massimiliano Viola, Kevin Qu, Nando Metzger, Bingxin Ke, Alexander Becker, Konrad Schindler, and Anton Obukhov. Marigold-dc: Zero-shot monocular depth completion with guided diffusion.arXiv preprint arXiv:2412.13389, 2024. 1, 2, 3
-
[53]
Plug-and-Play: Improve Depth Estimation via Sparse Data Propagation
Tsun-Hsuan Wang, Fu-En Wang, Juan-Ting Lin, Yi-Hsuan Tsai, Wei-Chen Chiu, and Min Sun. Plug-and-play: Improve depth estimation via sparse data propagation.arXiv preprint arXiv:1812.08350, 2018. 14
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
Tacodepth: Towards efficient radar-camera depth estimation with one-stage fusion
Yiran Wang, Jiaqi Li, Chaoyi Hong, Ruibo Li, Liusheng Sun, Xiao Song, Zhe Wang, Zhiguo Cao, and Guosheng Lin. Tacodepth: Towards efficient radar-camera depth estimation with one-stage fusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10523–10533,
-
[55]
Alex Wong, Xiaohan Fei, Stephanie Tsuei, and Stefano Soatto. Unsupervised depth completion from visual inertial odome- try.IEEE Robotics and Automation Letters, 5(2):1899–1906,
work page 1906
-
[56]
Chao Xia, Chenfeng Xu, Patrick Rim, Mingyu Ding, Nan- ning Zheng, Kurt Keutzer, Masayoshi Tomizuka, and Wei Zhan. Quadric representations for lidar odometry, mapping and localization.IEEE Robotics and Automation Letters, 8 (8):5023–5030, 2023. 14
work page 2023
-
[57]
Zheyuan Xu, Hongche Yin, and Jian Yao. Deformable spatial propagation networks for depth completion.2020 IEEE In- ternational Conference on Image Processing (ICIP), pages 913–917, 2020. 2
work page 2020
-
[58]
Rignet: Repetitive image guided network for depth completion
Zhiqiang Yan, Kun Wang, Xiang Li, Zhenyu Zhang, Baobei Xu, Jun Li, and Jian Yang. Rignet: Repetitive image guided network for depth completion. InEuropean Conference on Computer Vision, 2021. 2
work page 2021
-
[59]
Depth anything v2.Advances in Neural Information Processing Systems, 37: 21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37: 21875–21911, 2024. 1, 2, 12, 14, 15
work page 2024
-
[60]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaix- uan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9043–9053, 2023. 1, 3
work page 2023
-
[61]
Yifan Yu, Shaohui Liu, Rémi Pautrat, Marc Pollefeys, and Viktor Larsson. Relative pose estimation through affine corrections of monocular depth priors.arXiv preprint arXiv:2501.05446, 2025
-
[62]
Ziyao Zeng, Yangchao Wu, Hyoungseob Park, Daniel Wang, Fengyu Yang, Stefano Soatto, Dong Lao, Byung-Woo Hong, and Alex Wong. Rsa: Resolving scale ambiguities in monocu- lar depth estimators through language descriptions.Advances in neural information processing systems, 37:112684–112705,
-
[63]
Completionformer: Depth completion with convolutions and vision transformers
Youmin Zhang, Xianda Guo, Matteo Poggi, Zheng Zhu, Guan Huang, and Stefano Mattoccia. Completionformer: Depth completion with convolutions and vision transformers. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18527–18536, 2023. 2
work page 2023
-
[64]
To- wards better generalization: Joint depth-pose learning without posenet
Wang Zhao, Shaohui Liu, Yezhi Shu, and Yong-Jin Liu. To- wards better generalization: Joint depth-pose learning without posenet. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9151–9161,
-
[65]
2 11 Radar-Guided Polynomial Fitting for Metric Depth Estimation Supplementary Material nuScenes Method MAE RMSE DPT [42] 5188.2 6884.5 UniDepth [38] 2129.8 4887.7 Depth Anything [59] 2404.9 4851.1 Depth Pro [5] 3835.0 6600.3 RadarCam-Depth w/ DPT 1689.7 3948.0 RadarCam-Depth w/ UniDepth 1872.0 4321.2 RadarCam-Depth w/ Depth Anything 1953.6 5107.8 RadarCa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.