Normalized Matching Transformer
Pith reviewed 2026-05-22 22:00 UTC · model grok-4.3
The pith
Enforcing unit-norm embeddings at every Transformer layer improves keypoint matching accuracy and training speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
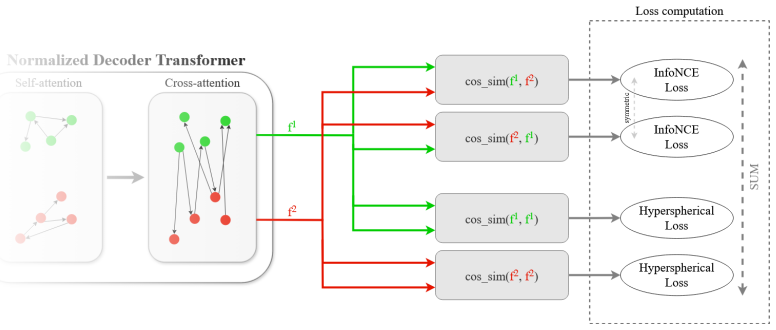
The Normalized Matching Transformer reaches new state-of-the-art performance on PascalVOC and SPair-71k by applying hyperspherical normalization throughout the Transformer: unit-norm embeddings are enforced at every layer and the network is trained with a combined InfoNCE and hyperspherical uniformity loss, yielding more discriminative keypoint representations at all depths rather than only at the output.
What carries the argument
hyperspherical normalization strategy that enforces unit-norm embeddings at every Transformer layer and trains with combined InfoNCE and hyperspherical uniformity loss
If this is right
- Matching and non-matching features remain well separated at every Transformer layer, not only at the final output.
- Training converges in at least 1.7 times fewer epochs than the cited baselines.
- The method outperforms BBGM, ASAR, COMMON, and GMTR by 5.1 percent on PascalVOC and 2.2 percent on SPair-71k.
- The same normalization and loss combination works with a simple overall architecture.
Where Pith is reading between the lines
- The same per-layer normalization approach could be tested on other dense prediction or correspondence tasks.
- Measuring embedding quality directly at intermediate layers would provide stronger evidence than end-task accuracy alone.
- The technique might transfer to other vision Transformers that currently train without explicit hyperspherical constraints.
Load-bearing premise
That enforcing unit-norm embeddings at every layer plus the combined losses produces more discriminative representations than standard training.
What would settle it
An ablation that removes per-layer normalization or the hyperspherical uniformity loss and measures whether matching accuracy on PascalVOC or SPair-71k drops.
Figures



read the original abstract
We introduce the Normalized Matching Transformer (NMT), a deep learning approach for efficient and accurate sparse semantic keypoint matching between image pairs. NMT consists of a strong visual backbone, geometric feature refinement via SplineCNN, followed by a normalized Transformer for computing matching features. Central to NMT is our hyperspherical normalization strategy: we enforce unit-norm embeddings at every Transformer layer and train with a combined contrastive InfoNCE and hyperspherical uniformity loss to yield more discriminative keypoint representations. This novel architecture/loss combination encourages close alignment of matching image features and large distances between non-matching ones not only at the output level, but for each layer. Despite its architectural simplicity, NMT sets a new state-of-the-art performance on PascalVOC and SPair-71k, outperforming BBGM, ASAR, COMMON and GMTR by 5.1% and 2.2%, respectively, while converging in at least 1.7x fewer epochs compared to other state-of-the-art baselines. These results underscore the power of combining pervasive normalization with hyperspherical learning for matching tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Normalized Matching Transformer (NMT) for sparse semantic keypoint matching. It consists of a visual backbone, SplineCNN-based geometric refinement, and a Transformer that enforces unit-norm embeddings at every layer, trained with a combined InfoNCE contrastive loss and hyperspherical uniformity loss. The central claim is that this per-layer normalization produces more discriminative keypoint representations, yielding new state-of-the-art accuracy on PascalVOC (5.1% above BBGM/ASAR/COMMON/GMTR) and SPair-71k (2.2% above the same baselines) while converging in at least 1.7x fewer epochs.
Significance. If the performance gains hold under controlled conditions, the work would provide evidence that pervasive hyperspherical normalization combined with uniformity losses can improve both accuracy and training speed in Transformer-based geometric matching, with potential implications for other correspondence and feature-learning tasks in computer vision.
major comments (3)
- [Abstract] Abstract: the reported 5.1% and 2.2% improvements on PascalVOC and SPair-71k are given without error bars, multiple-run statistics, or any ablation that removes the per-layer unit-norm constraint while retaining the same loss and architecture; this absence directly undermines the claim that the normalization strategy is responsible for the gains rather than other unisolated factors.
- [Experiments] The manuscript supplies no layer-wise or intermediate metrics (nearest-neighbor retrieval accuracy, embedding uniformity statistics, or matching precision per Transformer layer) that would confirm the representations become more discriminative at each stage rather than only at the final output.
- [Experiments] No training details (optimizer, learning-rate schedule, batch size, or exact dataset splits) are provided, making it impossible to assess whether the faster convergence (1.7x fewer epochs) is reproducible or sensitive to implementation choices.
minor comments (1)
- The abstract and introduction would benefit from explicit statements of the exact evaluation protocol (e.g., PCK threshold, number of keypoints) used for the cited baselines to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and plan to incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 5.1% and 2.2% improvements on PascalVOC and SPair-71k are given without error bars, multiple-run statistics, or any ablation that removes the per-layer unit-norm constraint while retaining the same loss and architecture; this absence directly undermines the claim that the normalization strategy is responsible for the gains rather than other unisolated factors.
Authors: We agree that providing error bars from multiple runs and an ablation study would better isolate the effect of the per-layer normalization. In the revised manuscript, we will report results averaged over multiple random seeds with standard deviations for the performance metrics on both datasets. We will also include an ablation experiment that disables the per-layer unit-norm enforcement while keeping the InfoNCE and uniformity losses and the overall architecture fixed, to directly demonstrate the contribution of the normalization strategy. This will strengthen the evidence for our central claim. revision: yes
-
Referee: [Experiments] The manuscript supplies no layer-wise or intermediate metrics (nearest-neighbor retrieval accuracy, embedding uniformity statistics, or matching precision per Transformer layer) that would confirm the representations become more discriminative at each stage rather than only at the final output.
Authors: We acknowledge the value of layer-wise analysis to support the per-layer normalization benefit. The revised version will include additional experiments reporting nearest-neighbor retrieval accuracy, embedding uniformity (e.g., via hyperspherical uniformity loss values or pairwise distance statistics), and matching precision at each Transformer layer. This will provide evidence that discriminativeness improves progressively through the layers. revision: yes
-
Referee: [Experiments] No training details (optimizer, learning-rate schedule, batch size, or exact dataset splits) are provided, making it impossible to assess whether the faster convergence (1.7x fewer epochs) is reproducible or sensitive to implementation choices.
Authors: We apologize for not including these details in the initial submission. The revised manuscript will provide complete training specifications, including the optimizer (e.g., AdamW), learning rate schedule, batch size, number of epochs, and precise dataset splits for PascalVOC and SPair-71k. With these details, the faster convergence claim can be more readily verified and reproduced. revision: yes
Circularity Check
No circularity; empirical results on held-out benchmarks
full rationale
The paper presents an architecture (visual backbone + SplineCNN + normalized Transformer) and a training objective (per-layer unit-norm embeddings + combined InfoNCE + hyperspherical uniformity loss). Performance is reported as measured accuracy on the standard held-out test splits of PascalVOC and SPair-71k. These numbers are external to the model parameters and loss terms; they do not reduce by construction to any fitted quantity or self-citation inside the paper. No derivation, uniqueness theorem, or prediction is claimed that would be equivalent to its inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / Jcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
we enforce unit-norm embeddings at every Transformer layer and train with a combined contrastive InfoNCE and hyperspherical uniformity loss to yield more discriminative keypoint representations... normalize throughout in the normalized transformer
-
IndisputableMonolith/Foundation/BlackBodyRadiationDeep.leanoff_match_positive / Jcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
hyperspherical loss... penalizes whenever two different keypoints are aligned... applied after each normalized transformer layer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Network flows: theory, algorithms, and applications
Ravindra K Ahuja, Thomas L Magnanti, James B Orlin, et al. Network flows: theory, algorithms, and applications . Pren- tice hall Englewood Cliffs, NJ, 1993. 2
work page 1993
-
[2]
Florian Bernard, Daniel Cremers, and Johan Thunberg. Sparse quadratic optimisation over the stiefel manifold with application to permutation synchronisation. Advances in Neural Information Processing Systems , 34:25256–25266,
-
[3]
Poselets: Body part detectors trained using 3d human pose annotations
Lubomir Bourdev and Jitendra Malik. Poselets: Body part detectors trained using 3d human pose annotations. In 2009 IEEE 12th international conference on computer vi- sion, pages 1365–1372. IEEE, 2009. 6
work page 2009
-
[4]
Qaplib–a quadratic assignment problem library
Rainer E Burkard, Stefan E Karisch, and Franz Rendl. Qaplib–a quadratic assignment problem library. Journal of Global optimization, 10:391–403, 1997. 2
work page 1997
-
[5]
Iglovikov, Eugene Khved- chenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A
Alexander Buslaev, Vladimir I. Iglovikov, Eugene Khved- chenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A. Kalinin. Albumentations: Fast and flexible image augmen- tations. Information, 11(2), 2020. 5
work page 2020
-
[6]
Minsu Cho, Karteek Alahari, and Jean Ponce. Learning graphs to match. In Proceedings of the IEEE International Conference on Computer Vision, pages 25–32, 2013. 6
work page 2013
-
[7]
Approximation algo- rithms for three-dimensional assignment problems with tri- angle inequalities
Yves Crama and Frits CR Spieksma. Approximation algo- rithms for three-dimensional assignment problems with tri- angle inequalities. European Journal of Operational Re- search, 60(3):273–279, 1992. 2
work page 1992
-
[8]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information pro- cessing systems, 26, 2013. 2
work page 2013
-
[9]
The pascal visual object classes (voc) challenge
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88:303–338, 2010. 6
work page 2010
-
[10]
Splinecnn: Fast geometric deep learning with continuous b-spline kernels
Matthias Fey, Jan Eric Lenssen, Frank Weichert, and Hein- rich M ¨uller. Splinecnn: Fast geometric deep learning with continuous b-spline kernels. InProceedings of the IEEE con- ference on computer vision and pattern recognition , pages 869–877, 2018. 1, 2, 3
work page 2018
-
[11]
Matthias Fey, Jan E Lenssen, Christopher Morris, Jonathan Masci, and Nils M Kriege. Deep graph matching consensus. arXiv preprint arXiv:2001.09621, 2020. 3, 6, 7
-
[12]
Deep graph matching under quadratic con- straint
Quankai Gao, Fudong Wang, Nan Xue, Jin-Gang Yu, and Gui-Song Xia. Deep graph matching under quadratic con- straint. In Proceedings of the ieee/cvf conference on com- puter vision and pattern recognition , pages 5069–5078,
-
[13]
Gmtr: Graph matching transformers
Jinpei Guo, Shaofeng Zhang, Runzhong Wang, Chang Liu, and Junchi Yan. Gmtr: Graph matching transformers. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 6535–6539. IEEE, 2024. 1, 2, 3, 7, 8
work page 2024
-
[14]
A comparative study of graph matching algorithms in computer vision
Stefan Haller, Lorenz Feineis, Lisa Hutschenreiter, Florian Bernard, Carsten Rother, Dagmar Kainm ¨uller, Paul Swo- boda, and Bogdan Savchynskyy. A comparative study of graph matching algorithms in computer vision. In European Conference on Computer Vision , pages 636–653. Springer,
-
[15]
Fu- sion moves for graph matching
Lisa Hutschenreiter, Stefan Haller, Lorenz Feineis, Carsten Rother, Dagmar Kainm¨uller, and Bogdan Savchynskyy. Fu- sion moves for graph matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 6270–6279, 2021. 2
work page 2021
-
[16]
Glmnet: Graph learning- matching networks for feature matching
B Jiang, P Sun, J Tang, and B Luo. Glmnet: Graph learning- matching networks for feature matching. arxiv. arXiv preprint arXiv:1911.07681, 2019. 2, 6, 7
-
[17]
Unlocking the poten- tial of operations research for multi-graph matching
Max Kahl, Sebastian Stricker, Lisa Hutschenreiter, Florian Bernard, and Bogdan Savchynskyy. Unlocking the poten- tial of operations research for multi-graph matching. arXiv preprint arXiv:2406.18215, 2024. 2
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization. arXiv preprint arXiv:1412.6980, 2014. 5
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
The quadratic assignment problem
Eugene L Lawler. The quadratic assignment problem. Man- agement science, 9(4):586–599, 1963. 2
work page 1963
-
[20]
Graph matching with bi-level noisy correspondence
Yijie Lin, Mouxing Yang, Jun Yu, Peng Hu, Changqing Zhang, and Xi Peng. Graph matching with bi-level noisy correspondence. In Proceedings of the IEEE/CVF interna- tional conference on computer vision , pages 23362–23371,
-
[21]
Lightglue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17627–17638, 2023. 3
work page 2023
-
[22]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 1, 3, 5
work page 2021
-
[23]
ngpt: Normalized transformer with rep- resentation learning on the hypersphere
Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized transformer with rep- resentation learning on the hypersphere. arXiv preprint arXiv:2410.01131, 2024. 1, 2, 3, 4
-
[24]
Dgc-net: Dense ge- ometric correspondence network
Iaroslav Melekhov, Aleksei Tiulpin, Torsten Sattler, Marc Pollefeys, Esa Rahtu, and Juho Kannala. Dgc-net: Dense ge- ometric correspondence network. In 2019 IEEE Winter Con- ference on Applications of Computer Vision (WACV), pages 1034–1042. IEEE, 2019. 3
work page 2019
-
[25]
Hyper- spherical prototype networks
Pascal Mettes, Elise Van der Pol, and Cees Snoek. Hyper- spherical prototype networks. Advances in neural informa- tion processing systems, 32, 2019. 1, 2, 5
work page 2019
-
[26]
Spair-71k: A large-scale benchmark for semantic correspon- dence
Juhong Min, Jongmin Lee, Jean Ponce, and Minsu Cho. Spair-71k: A large-scale benchmark for semantic correspon- dence. arXiv preprint arXiv:1908.10543, 2019. 6, 7
-
[27]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018. 1, 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Solving the multi-way matching problem by permutation synchroniza- tion
Deepti Pachauri, Risi Kondor, and Vikas Singh. Solving the multi-way matching problem by permutation synchroniza- tion. Advances in neural information processing systems , 26, 2013. 2
work page 2013
-
[29]
Layoutgmn: Neural graph match- ing for structural layout similarity
Akshay Gadi Patil, Manyi Li, Matthew Fisher, Manolis Savva, and Hao Zhang. Layoutgmn: Neural graph match- ing for structural layout similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11048–11057, 2021. 7
work page 2021
-
[30]
Appearance and structure aware robust deep visual graph matching: Attack, defense and beyond
Qibing Ren, Qingquan Bao, Runzhong Wang, and Junchi Yan. Appearance and structure aware robust deep visual graph matching: Attack, defense and beyond. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15263–15272, 2022. 1, 2, 3, 5, 7, 8
work page 2022
-
[31]
Deep graph match- ing via blackbox differentiation of combinatorial solvers
Michal Rol ´ınek, Paul Swoboda, Dominik Zietlow, Anselm Paulus, V´ıt Musil, and Georg Martius. Deep graph match- ing via blackbox differentiation of combinatorial solvers. In Computer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16, pages 407–424. Springer, 2020. 1, 2, 3, 5, 6, 7, 8
work page 2020
-
[32]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 3
work page 2020
-
[33]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition , pages 8922–8931, 2021. 3
work page 2021
-
[35]
A study of la- grangean decompositions and dual ascent solvers for graph matching
Paul Swoboda, Carsten Rother, Hassan Abu Alhaija, Dag- mar Kainmuller, and Bogdan Savchynskyy. A study of la- grangean decompositions and dual ascent solvers for graph matching. In Proceedings of the IEEE conference on com- puter vision and pattern recognition , pages 1607–1616,
-
[36]
A convex relaxation for multi-graph matching
Paul Swoboda, Ashkan Mokarian, Christian Theobalt, Flo- rian Bernard, et al. A convex relaxation for multi-graph matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11156– 11165, 2019. 2
work page 2019
-
[37]
A dual decomposition approach to feature correspon- dence
Lorenzo Torresani, Vladimir Kolmogorov, and Carsten Rother. A dual decomposition approach to feature correspon- dence. IEEE transactions on pattern analysis and machine intelligence, 35(2):259–271, 2012. 1, 2
work page 2012
-
[38]
A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017. 4
work page 2017
-
[39]
Differentiation of blackbox combinatorial solvers,
Marin Vlastelica, Anselm Paulus, V ´ıt Musil, Georg Martius, and Michal Rol´ınek. Differentiation of blackbox combinato- rial solvers. arXiv preprint arXiv:1912.02175, 2019. 2 9
-
[40]
Learning combinatorial embedding networks for deep graph matching
Runzhong Wang, Junchi Yan, and Xiaokang Yang. Learning combinatorial embedding networks for deep graph matching. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3056–3065, 2019. 2, 6, 7
work page 2019
-
[41]
Runzhong Wang, Junchi Yan, and Xiaokang Yang. Neural graph matching network: Learning lawler’s quadratic assign- ment problem with extension to hypergraph and multiple- graph matching. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5261–5279, 2021. 2, 7
work page 2021
-
[42]
Learning deep graph matching with channel-independent embedding and hungarian attention
Tianshu Yu, Runzhong Wang, Junchi Yan, and Baoxin Li. Learning deep graph matching with channel-independent embedding and hungarian attention. In International con- ference on learning representations, 2019. 2, 6, 7
work page 2019
-
[43]
Cutmix: Regu- larization strategy to train strong classifiers with localizable features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regu- larization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international con- ference on computer vision, pages 6023–6032, 2019. 5
work page 2019
-
[44]
Deep learning of graph matching
Andrei Zanfir and Cristian Sminchisescu. Deep learning of graph matching. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2684–2693,
-
[45]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimiza- tion. arXiv preprint arXiv:1710.09412, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Deep graphical feature learn- ing for the feature matching problem
Zhen Zhang and Wee Sun Lee. Deep graphical feature learn- ing for the feature matching problem. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 5087–5096, 2019. 2
work page 2019
-
[47]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In Proceed- ings of the AAAI conference on artificial intelligence , pages 13001–13008, 2020. 5 10
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.