Image-to-Text for Medical Reports Using Adaptive Co-Attention and Triple-LSTM Module
Pith reviewed 2026-05-22 23:30 UTC · model grok-4.3
The pith
CA-TriNet uses adaptive co-attention and triple-LSTM to generate more accurate medical reports from images than existing models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its Co-Attention Triple-LSTM Network (CA-TriNet) successfully addresses the challenges of repetition and similarity in medical data by using a co-attention module that links vision and text transformers with an adaptive weight operator to amplify minor similarities, combined with a triple-LSTM module that refines sentences using targeted image objects, resulting in superior comprehensive performance on medical report generation tasks.
What carries the argument
Co-Attention module with adaptive weighting that links vision transformer to text transformer, and Triple-LSTM module that refines generated sentences based on image objects.
If this is right
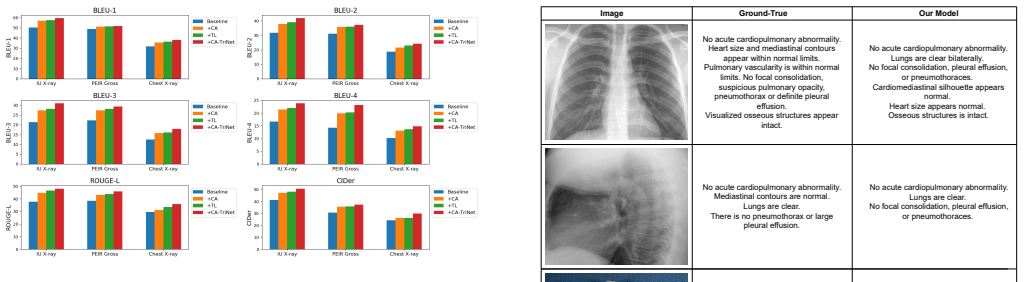
- Outperforms state-of-the-art models on comprehensive metrics across three public datasets.
- Surpasses some pre-trained large language models on specific metrics.
- Handles similar medical images better through adaptive weighting.
- Reduces overfitting tendencies common in medical report generation.
Where Pith is reading between the lines
- Such a model could be adapted for other image-to-text tasks involving repetitive data.
- Integration with larger language models might further improve results in clinical settings.
- Testing on private hospital datasets could reveal real-world applicability beyond public benchmarks.
Load-bearing premise
The co-attention module with adaptive weighting and the triple-LSTM successfully differentiate similar medical images and refine text without overfitting.
What would settle it
A direct comparison on the three public datasets showing that CA-TriNet does not achieve higher scores than current state-of-the-art models on the reported metrics would falsify the performance claim.
Figures


read the original abstract
Medical report generation requires specialized expertise that general large models often fail to accurately capture. Moreover, the inherent repetition and similarity in medical data make it difficult for models to extract meaningful features, resulting in a tendency to overfit. So in this paper, we propose a multimodal model, Co-Attention Triple-LSTM Network (CA-TriNet), a deep learning model that combines transformer architectures with a Multi-LSTM network. Its Co-Attention module synergistically links a vision transformer with a text transformer to better differentiate medical images with similarities, augmented by an adaptive weight operator to catch and amplify image labels with minor similarities. Furthermore, its Triple-LSTM module refines generated sentences using targeted image objects. Extensive evaluations over three public datasets have demonstrated that CA-TriNet outperforms state-of-the-art models in terms of comprehensive ability, even pre-trained large language models on some metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CA-TriNet, a multimodal architecture for medical report generation that integrates a vision transformer and text transformer via a co-attention module with adaptive weighting to differentiate similar images, plus a triple-LSTM module to refine generated text using targeted image objects. It claims that evaluations on three public datasets show the model outperforming state-of-the-art approaches, including some pre-trained large language models on select metrics.
Significance. If the reported empirical gains are reproducible and statistically robust, the work could advance automated medical report generation by mitigating overfitting on repetitive medical imagery, a persistent practical barrier; the combination of adaptive co-attention and multi-LSTM refinement offers a concrete architectural direction worth testing against current transformer baselines.
major comments (1)
- [Abstract] Abstract: the central claim that 'CA-TriNet outperforms state-of-the-art models in terms of comprehensive ability, even pre-trained large language models on some metrics' is asserted without any numerical results, tables, ablation studies, error bars, or statistical tests; this absence is load-bearing because the entire contribution rests on empirical superiority across three datasets.
minor comments (1)
- [Abstract] The abstract contains repetitive phrasing ('similarities' and 'similar medical images') that could be tightened for clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for quantitative support in the abstract. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'CA-TriNet outperforms state-of-the-art models in terms of comprehensive ability, even pre-trained large language models on some metrics' is asserted without any numerical results, tables, ablation studies, error bars, or statistical tests; this absence is load-bearing because the entire contribution rests on empirical superiority across three datasets.
Authors: We agree that the abstract would be strengthened by including key numerical results to support the performance claim. The full manuscript contains the requested elements (tables, ablations, and comparisons on three datasets), but the abstract itself does not. We will revise the abstract to add specific metrics demonstrating outperformance over SOTA models and select pre-trained LLMs. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical model (CA-TriNet) with co-attention and triple-LSTM components and reports outperformance on three public datasets. No equations, derivations, fitted parameters, or self-citations appear in the provided text that could reduce any claimed result to its inputs by construction. The central claim rests on external evaluation rather than any self-referential step.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Co-Attention module synergistically links a vision transformer with a text transformer... adaptive weight operator... Triple-LSTM module refines generated sentences
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive evaluations over three public datasets have demonstrated that CA-TriNet outperforms state-of-the-art models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
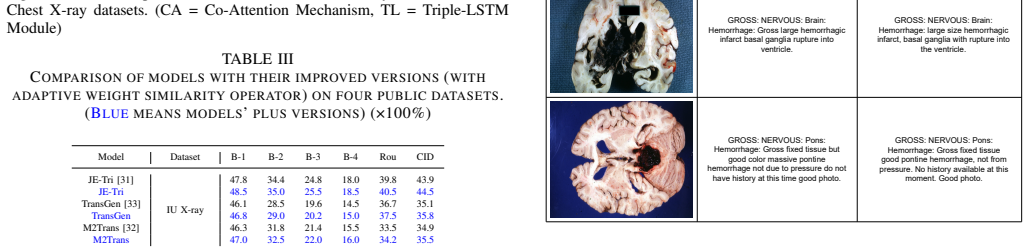
Heart size and mediastinal contours appear within normal limits
Hongjian Zhou, Fenglin Liu, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S Chen, Peilin Zhou, Junling Liu, et al., “A No acute cardiopulmonary abnormality. Heart size and mediastinal contours appear within normal limits. Pulmonary vascularity is within normal limits. No focal consolidation, suspicious pulmonary opacity, pneumothorax or defini...
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al., “Capabilities of gemini models in medicine,” arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee, “Visual instruction tuning,” Advances in neural information processing systems (NIPS), vol. 36, 2024
work page 2024
-
[6]
HuatuoGPT, towards taming language model to be a doctor,
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhang Zhiyi, Qingying Xiao, Xiang Wan, Benyou Wang, and Haizhou Li, “HuatuoGPT, towards taming language model to be a doctor,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, Dec. 2023, pp. 10859–10885, Association for ...
work page 2023
-
[7]
Dynamic data sampler for cross-language transfer learning in large language models,
Yudong Li, Yuhao Feng, Wen Zhou, Zhe Zhao, Linlin Shen, Cheng Hou, and Xianxu Hou, “Dynamic data sampler for cross-language transfer learning in large language models,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11291–11295
work page 2024
-
[8]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Guangyi Liu, Yinghong Liao, Fuyu Wang, Bin Zhang, Lu Zhang, Xiaodan Liang, Xiang Wan, Shaolin Li, Zhen Li, Shuixing Zhang, and Shuguang Cui, “Medical-vlbert: Medical visual language bert for covid- 19 ct report generation with alternate learning,” IEEE Transactions on Neural Networks and Learning Systems , vol. 32, no. 9, pp. 3786–3797, 2021
work page 2021
-
[10]
Attention enhanced network with semantic inspector for medical image report generation,
Yihan Lin, Qian Tang, Hao Wang, Cheng Huang, Ekong Favour, Xiangxiang Wang, Xiao Feng, and Yongbin Yu, “Attention enhanced network with semantic inspector for medical image report generation,” in 2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI), 2023, pp. 242–249
work page 2023
-
[11]
On the automatic generation of medical imaging reports,
Baoyu Jing, Pengtao Xie, and Eric Xing, “On the automatic generation of medical imaging reports,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018, vol. 1, pp. 2577– 2586
work page 2018
-
[12]
Jonathan Giezendanner, Rohit Mukherjee, Matthew Purri, Mitchell Thomas, Max Mauerman, A.K.M. Saiful Islam, and Beth Tellman, “Inferring the past: A combined cnn-lstm deep learning framework to fuse satellites for historical inundation mapping,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2023...
work page 2023
-
[14]
Learning to read chest x-rays: Recurrent neural cascade model for automated image annotation,
Hoo-Chang Shin, Kirk Roberts, Le Lu, Dina Demner-Fushman, Jianhua Yao, and Ronald M Summers, “Learning to read chest x-rays: Recurrent neural cascade model for automated image annotation,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2497–2506
work page 2016
-
[15]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” 2017
work page 2017
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale,
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in International Conference on Learning Representations (ICLR) , 2020
work page 2020
-
[17]
Are pre-trained convolutions better than pre- trained transformers?,
Yi Tay, Mostafa Dehghani, Jai Gupta, Dara Bahri, Vamsi Aribandi, Zhen Qin, and Donald Metzler, “Are pre-trained convolutions better than pre- trained transformers?,” 2022
work page 2022
-
[18]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie, “A convnet for the 2020s,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 11966–11976
work page 2022
-
[19]
Cheng Huang, Junhao Shen, Beichen Hu, Mohammad Haqqani, Tsen- gdar Lee, Karanjit Kooner, Ning Zhang, and Jia Zhang, Semantic and Visual Attention-Driven Multi-LSTM Network for Automated Clinical Report Generation, pp. 233–248, 08 2024
work page 2024
-
[20]
A survey on biomedical image captioning,
John Pavlopoulos, Vasiliki Kougia, and Ion Androutsopoulos, “A survey on biomedical image captioning,” in Proceedings of the second workshop on shortcomings in vision and language , 2019, pp. 26–36
work page 2019
-
[21]
Semantic and visual enrichment hierarchical network for medical image report generation,
Qian Tang, Yongbin Yu, Xiao Feng, and Chenhui Peng, “Semantic and visual enrichment hierarchical network for medical image report generation,” in 2022 Asia Conference on Algorithms, Computing and Machine Learning (CACML) , 2022, pp. 738–743
work page 2022
-
[22]
Show and tell: A neural image caption generator,
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan, “Show and tell: A neural image caption generator,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3156–3164
work page 2015
-
[23]
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, and Yoshua Bengio, “Show, At- tend and Tell: Neural Image Caption Generation with Visual Attention,” Apr. 2016, arXiv:1502.03044 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
Jeff Donahue, Lisa Anne Hendricks, Marcus Rohrbach, Subhashini Venugopalan, Sergio Guadarrama, Kate Saenko, and Trevor Darrell, “Long-term Recurrent Convolutional Networks for Visual Recognition and Description,” May 2016, arXiv:1411.4389 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Latent relationship mining of glaucoma biomarkers: a tri-lstm based deep learning,
Cheng Huang, Junhao Shen, Qiuyu Luo, Karanjit Kooner, Tsengdar Lee, Yishen Liu, and Jia Zhang, “Latent relationship mining of glaucoma biomarkers: a tri-lstm based deep learning,” arXiv preprint arXiv:2408.15555, 2024
-
[26]
Meshed-Memory Transformer for Image Captioning,
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cuc- chiara, “Meshed-Memory Transformer for Image Captioning,” Mar. 2020, arXiv:1912.08226 [cs]
-
[27]
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang, “Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering,” Mar. 2018, arXiv:1707.07998 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Auxiliary signal-guided knowledge encoder-decoder for medical report generation,
Mingjie Li, Rui Liu, Fuyu Wang, Xiaojun Chang, and Xiaodan Liang, “Auxiliary signal-guided knowledge encoder-decoder for medical report generation,” World Wide Web, vol. 26, no. 1, pp. 253–270, Jan. 2023
work page 2023
-
[29]
Gener- ating Radiology Reports via Memory-driven Transformer,
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan, “Gener- ating Radiology Reports via Memory-driven Transformer,” Apr. 2022, arXiv:2010.16056 [cs]
-
[30]
Contrastive Attention for Automatic Chest X-ray Report Generation,
Fenglin Liu, Changchang Yin, Xian Wu, Shen Ge, Yuexian Zou, Ping Zhang, Yuexian Zou, and Xu Sun, “Contrastive Attention for Automatic Chest X-ray Report Generation,” Apr. 2023, arXiv:2106.06965 [cs]
-
[31]
Joint embedding of deep visual and semantic features for medical image report generation,
Yan Yang, Jun Yu, Jian Zhang, Weidong Han, Hanliang Jiang, and Qingming Huang, “Joint embedding of deep visual and semantic features for medical image report generation,” IEEE Transactions on Multimedia, vol. 25, pp. 167–178, 2023
work page 2023
-
[32]
Meshed-memory transformer for image captioning,
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara, “Meshed-memory transformer for image captioning,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10575–10584
work page 2020
-
[33]
Radiology report generation for rare diseases via few-shot transformer,
Xing Jia, Yun Xiong, Jiawei Zhang, Yao Zhang, Blackley Suzanne, Yangyong Zhu, and Chunlei Tang, “Radiology report generation for rare diseases via few-shot transformer,” in 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2021, pp. 1347– 1352
work page 2021
-
[34]
R2gengpt: Radiology report generation with frozen llms,
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou, “R2gengpt: Radiology report generation with frozen llms,” Meta-Radiology, vol. 1, no. 3, pp. 100033, 2023
work page 2023
-
[35]
Xiao Wang, Yuehang Li, Fuling Wang, Shiao Wang, Chuanfu Li, and Bo Jiang, “R2gencsr: Retrieving context samples for large lan- guage model based x-ray medical report generation,” arXiv preprint arXiv:2408.09743, 2024
-
[36]
Convit: Improving vision transformers with soft convolutional inductive biases,
St ´ephane d’Ascoli, Hugo Touvron, Matthew Leavitt, Ari Morcos, Giulio Biroli, and Levent Sagun, “Convit: Improving vision transformers with soft convolutional inductive biases,” in Proceedings of the 38th International Conference on Machine Learning (ICML), 2021, pp. 2286– 2296
work page 2021
-
[37]
Captionnet: A tailor-made recurrent neural network for generating image descriptions,
Longyu Yang, Hanli Wang, Pengjie Tang, and Qinyu Li, “Captionnet: A tailor-made recurrent neural network for generating image descriptions,” IEEE Transactions on Multimedia , vol. 23, pp. 835–845, 2021
work page 2021
-
[38]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Alistair EW Johnson, Tom J Pollard, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, and Steven Horng, “Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs,” arXiv preprint arXiv:1901.07042, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[39]
Bleu: a method for automatic evaluation of machine translation,
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceed- ings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
work page 2002
-
[40]
Chin-Yew Lin and Franz Josef Och, “Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics,” in Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04) , 2004, pp. 605–612
work page 2004
-
[41]
Cider: Consensus-based image description evaluation,
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh, “Cider: Consensus-based image description evaluation,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2015, pp. 4566–4575
work page 2015
-
[42]
Imagenet: A large-scale hierarchical image database,
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei- Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition , 2009, pp. 248–255
work page 2009
-
[43]
Adam: A method for stochastic optimization,
Diederik Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations (ICLR), San Diega, CA, USA, 2015
work page 2015
-
[44]
Exploring and Distilling Posterior and Prior Knowledge for Radiology Report Generation,
Fenglin Liu, Xian Wu, Shen Ge, Wei Fan, and Yuexian Zou, “Exploring and Distilling Posterior and Prior Knowledge for Radiology Report Generation,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Nashville, TN, USA, 2021, pp. 13748– 13757, IEEE
work page 2021
-
[45]
Automated radiographic report generation purely on transformer: A multicriteria supervised approach,
Zhanyu Wang, Hongwei Han, Lei Wang, Xiu Li, and Luping Zhou, “Automated radiographic report generation purely on transformer: A multicriteria supervised approach,” IEEE Transactions on Medical Imaging, vol. 41, no. 10, pp. 2803–2813, 2022
work page 2022
-
[46]
Bootstrapping large language models for radiology report generation,
Chang Liu, Yuanhe Tian, Weidong Chen, Yan Song, and Yongdong Zhang, “Bootstrapping large language models for radiology report generation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024, vol. 38, pp. 18635–18643
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.